
No Pose, No Problem: Surprisingly Simple 3DGaussian Splats From Sparse Unposed Images 论文解读
该论文提出一种NoPoSplat的前馈模型,用于在没有姿态情况下的稀疏多视图图像中构建三维场景。相较于以往需要将精确的相机姿态作为输入不同,NoPoSplat直接从一个局部摄像机的坐标(标准空间)中预测高斯基元,消除姿态估计及其相关误差的需求。
目录
一、概述

该论文提出一种NoPoSplat的前馈模型,用于在没有姿态情况下的稀疏多视图图像中构建三维场景。相较于以往需要将精确的相机姿态作为输入不同,NoPoSplat直接从一个局部摄像机的坐标(标准空间)中预测高斯基元,消除姿态估计及其相关误差的需求。
(1)提出了前馈网络NoPoSplat,从无姿态情况下的稀疏视角输入,重构了参数化的3DGS场景,并只使用光度损失进行训练。
(2)研究了高斯重构中尺度模糊的问题,并通过引入相机固有参数作为输入来解决这个问题。
(3)设计了两阶段管道来估计准确的相对相机姿态以用来进行高斯场重构。
(4)在NVS和相机姿态估计任务中展现出显著性能,并且可以用于wild data。
二、相关工作
1、可推广的三维重建和新视角生成
NeRF和3DGS显著应用于3D重建工作和新视角合成中,然而他们都需要密集的图片和数十分钟的单场景优化,这使得在实际应用中存在限制。
近期考虑的可推广的三维重建和新视角生成,是利用稀疏图片作为输入,一般用于具体的任务的backbones,或者利用几何信息来优化场景重建。比如MVSNeRF和MuRF都通过构建成本体积来聚合多视图信息,PixelSplat通过引入外极线几何来优化深度估计。但这写几何信息都需要依赖于相机姿态输入,以及输入图像中有效的摄像机姿态重叠。
而我们的网络只是一个VIT进行编码,没有引入其他的几何先验,可以做到pose-free的基础上,更effective的大相机baseline场景重建。
2、无姿态3D场景重建
对于经典的NeRF和3DGS方法需要输入图像精确的相机姿态,而相机姿态的来源来自于SfM(如COLMAP)中通过复杂的过程算出的。
近期通过结合摄像机姿态和神经场表示,但还是限制相机姿态在一个很小的motion中。另外也有一些方法可以不输入摄像机姿态,但是需要输入规定的输入图像或视频序列。
在可推广的稀疏视图生成工作中,考虑过使用双视图姿态估计方法,但存在无文本区域或图像缺少足够重叠部分会出现完全噪声化。另外还有一种解决方法是通过先估计相机姿态,在构建场景表示的方法,但由于第一阶段计算的姿态存在一定噪声,存在一定偏差,导致后续的场景重建效果不佳。
而我们的方法考虑直接从双视角的图像输入,通过标准空间计算3DGS基元,避免了潜在的噪声,再通过直接融合两视角来获得新视角的合成和姿态估计。
另外解释了Splatt3R存在的问题,由于高度依赖于MASt3R工作,而MASt3R工作不容易顺利合并不同视图的场景,另外也需要GT深度,来进行标注存在限制。
三、NoPoSplat
NoPoSplat包括四个部分:ViT编码解码架构,相机内参转嵌入模块,3DGS预测头,相机姿态估计和新视角生成模块。
![]()
1、相机内参嵌入模块
为了解决3D重建过程中的尺度歧义问题,NoPoSplat设计了三种不同的相机内参嵌入方法。
全局内参嵌入-加和:将相机内参K输入到一个线性层,得到一个全局特征,然后将该特征广播到ViT的图像特征之后。
全局内参嵌入-拼接:将得到的全局特征作为一个额外的内参token,与所有图像的token进行拼接。
密集内参嵌入:对输入图像的每个像素,我们可以得到相机光线方向
,这些每像素的相机射线使用球面谐波转换为更高维的特征,并与RGB图像连接作为网络输入。需要注意的是,像素级嵌入可以可以看做类似plucker射线嵌入的简化,但不需要相机外参。
2、ViT编码解码架构
首先ViT编码器的输入,由图片进行unpatch后得到一个token,并且与相机的内参token进行拼接,并经过线性层作为输入。
之后编码器部分对于不同视图使用共享权重的方法,获得的特征经过解码器对于所有每一个视角,在注意力层使用交叉注意力进行交互,促进多视图的信息融合。
3、3DGS预测头
高斯预测头分为两个阶段,均使用DPT结构,第一个预测头利用解码器的输出特征,来生成高斯中心位置。第二个预测头利用解码器的输出特征和RGB图像输入,RGB图像的输入有效的保证了纹理信息,最终输出其他高斯特征
。
4、相机姿态估计和新视角生成模块
正则高斯空间
直接在一个标准坐标系中输出不同视图的高斯分布,在论文中我们设定第一个输入视图作为全局参考坐标系,第一输入视图相机姿态设为,其中
作为旋转矩阵或者单位矩阵,0是零平移向量,其他所有视图都转换到该规范空间中的高斯基元
。
通过这种方式,可以在同一规范空间内融合不同视图,并且消除相机姿势外参的需要,实现无姿态情况下的姿态估计。
5、损失函数
训练NoPoSplat主干网络:MSE+0.05的LPIPS损失
计算位姿估计:首先通过PnP和RANSAC方法计算出规范空间中的高斯核中心在世界坐标系下的精确位置,这一步只需要毫秒级计算。之后冻结高斯参数,并优化从初始姿态到当前姿态的每一个光度损失和SSIM的结构部分。
三维场景重建:当只有两个输入视图进行三维重建时一定是模糊的,但是该论文冻结高斯分布,优化目标摄像机的姿态,并且使目标视图得到的渲染图像与GT真实图像紧密匹配。
四、实验
1、新视角生成对比实验
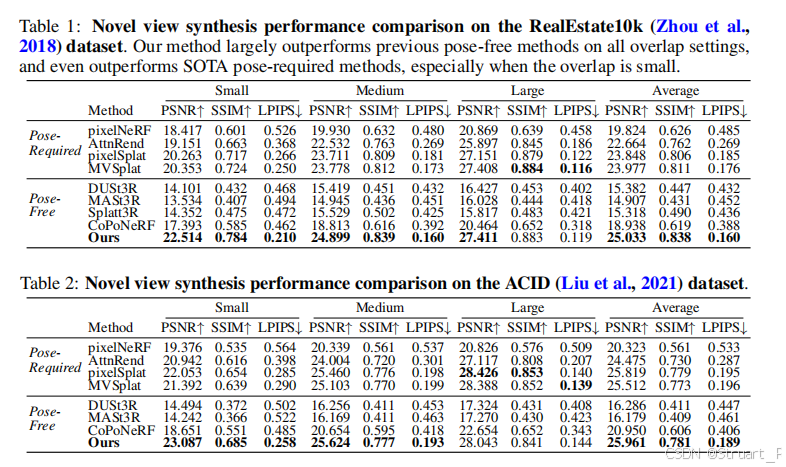
在RealEstate10k和ACID数据上基于Pose-Required和Pose-free两类模型进行实验,显示出我们模型在Pose-free上是遥遥领先的性能。
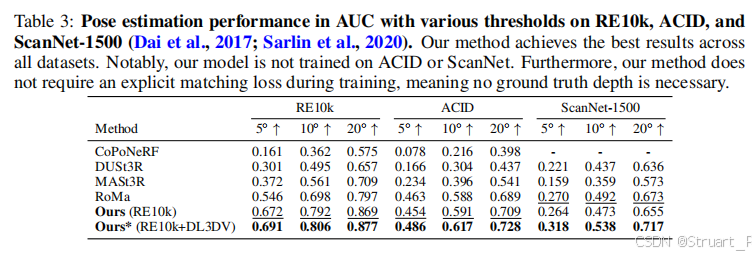
2、位姿估计
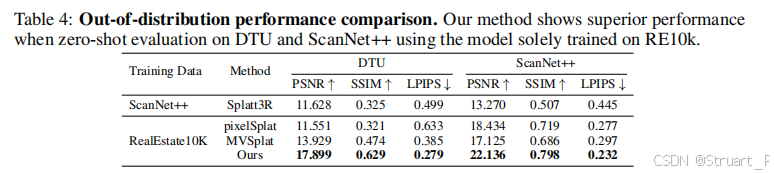
3、零样本评估
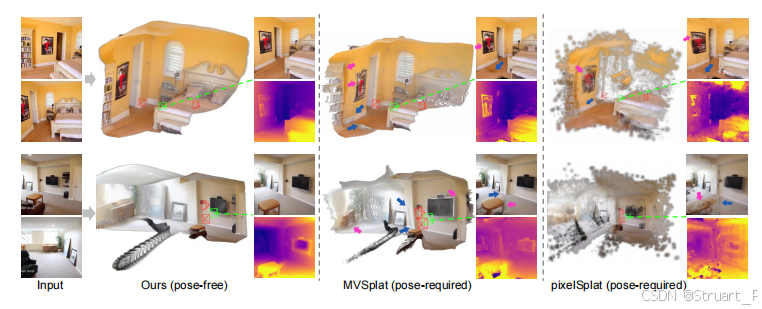
4、3DGS渲染对比
5、交叉数据集生成

6、不同场景
a是移动端的野生场景生成,b是针对于SORA文本生成视频后对于视频进行再剪切多视角图片来渲染场景的效果。


GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 21
21 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)