
SimpleRNN Model
one to one 模型one to one 模型指输入是一个 vector ,对应的,输出是一个 vector 结果的模型,如逻辑回归模型,如预测房价,输入房屋面积,就可以得到一个预测的房价。全连接神经网络和卷积神经网络也是这种类型的模型。比如在对图片进行分类的时候,输入一张图片,输出一个概率值。这种模型有一定的局限性:它会将输入当作一个整体固定的输入大小固定的输出大小如何对时序数据建模?由于
one to one 模型
one to one 模型指输入是一个 vector ,对应的,输出是一个 vector 结果的模型,如逻辑回归模型,如预测房价,输入房屋面积,就可以得到一个预测的房价。全连接神经网络和卷积神经网络也是这种类型的模型。比如在对图片进行分类的时候,输入一张图片,输出一个概率值。
这种模型有一定的局限性:
- 它会将输入当作一个整体
- 固定的输入大小
- 固定的输出大小
如何对时序数据建模?
由于这些局限性,在时序类数据建模中不适用,比如人在读一篇文章的时候不是将一篇文章作为整体塞入大脑,而是一个字一个字的读,而且输入和输出长度也不固定,如将中文翻译成英文,输入五个字,输出可能有六个单词,这种情况下 one to one 模型不再适用,而要用到 many to many 或者 many to one 模型。
many to many 或者 many to one 模型
many to many 模型的特点如下所示,主要可用于文本和语音等时序数据中的建模。最经典的应用场景就是机器翻译,将中午的 3 个字翻译成英文的 10 个单词。
- 输入是一个长度不固定的 vector sequence
- 输出是一个长度不固定的 vector sequence
many to one 模型的特点如下所示,也可用于文本和语音等时序数据中的建模。最经典的应用场景就是文本情感倾向,判断一篇文章的情感是积极还是消极的。
- 输入是一个长度不固定的 vector sequence
- 输出是一个的 vector
而 RNN 就是这样的模型。
SimpleRNN Model
SimpleRNN 模型图如下所示:
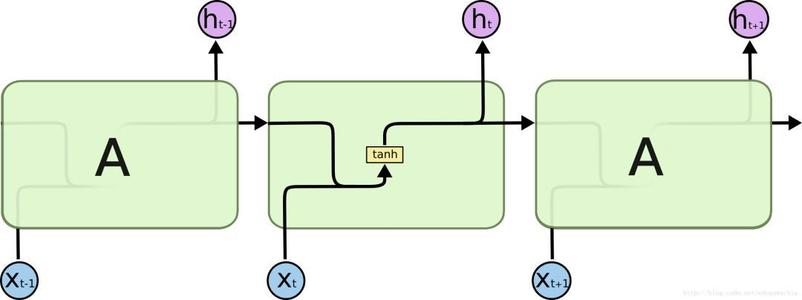
SimpleRNN 模型可以简化为如下公式:
ht = tanh(A * concat(ht-1,xt))
- ht-1 是上一个时间步输出的状态特征
- xt 是当前时间步的输入向量
- A 是权重参数,需要经过训练数据学习
- tanh 是双曲正切函数,可以将输入转化为一个 -1 到 1 的范围内大小的输出ht 是当前时间步输出的状态特征
- concat 是一个拼接函数,将 ht-1 和 xt 进行拼接
所以 ht 依赖于 ht-1 、A 和 xt 。ht 提取了 xt、xt-1 … x0 所有输入的特征,并集合于一身。
【注意】看上面的结构图,输入的时序数据的每个时间步虽然都要各自经过 SimpleRNN 的处理,但是要明白,处理这些不同时间步的 SimpleRNN 是同一个,换句话说 A 都是同一个。
要训练的参数大小
上面的 A 就是需要训练的权重参数,通过公式我们可以看出来需要的参数大小为:
shape(h) * [shape(h)+shape(x)]
如果算上偏移量 b ,那么总参数大小为:
shape(h) * [shape(h)+shape(x)] + shape(h)
更加完整的 RNN
上面介绍的是一种简化版,如果要看复杂的完整的公式,如图所示
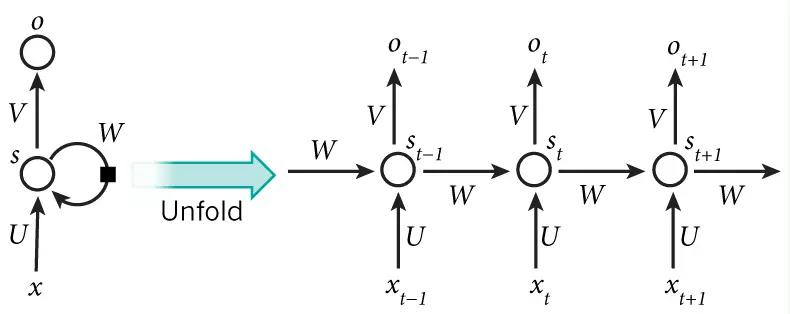
与上面的简化版本类似,x 是输入,s 是隐层输出,o 是输出层结果,W 是上一个时刻的隐藏层值作为这一次的输入的权重,U 是输入到隐藏层的权重矩阵,V 是隐层到输出层的权重矩阵。
我们可以看出 St 依赖于 St-1 、W 、U 和 xt ,此时的隐层输出公式如下,f 是激活函数,一般用到的是 tanh ,b 是偏置参数,可以有也可以没有,其他可以使用:
St = f(U * xt + W * St-1 + b)
最后的输出为公式如下,g 为激活函数,一般是softmax ,b 是偏置参数,可以有也可以没有:
Ot = g(V * St + b)
【注意】
- 所有时刻的 W , U , V 在每个时刻都是相等的,权重都是共享的,同时可以大大减少参数数量
- 隐藏状态可以理解为: U 对当前时刻的输入进行总结要记忆某些有用的信息,W 对上一时刻的隐层输出进行过滤忘记某些无用的信息,这两部分进行相加得到的就是当前时刻的隐层输出
为什么需要 tanh ?
假如去掉 tanh 函数,SimpleRNN 公式则变成了:
ht = A * concat(ht-1,xt)
假如现在 100 个输入, x0 = x1 = … = x100 = 0,那么 h100 = Ah99 = A2h98 = … = A100h0 。
如果当 A 中的最大值小于 1 ,那么 A100 则是一个极其接近于 0 的矩阵,则经过计算 h100 几乎也是个接近于 0 的向量,这是不可取的。
如果当 A 中的最小值大于 1 ,那么 A100 则是一个极其大的的矩阵,则经过计算 h100 几乎也是个极其大的向量,这也是不可取的。
而现在有 tanh 函数,每次对结果做一次 normalization ,让 h 中的所有值恢复到 -1 到 1 的范围之间的大小,避免经过计算发生数值极限爆炸或者数值极限缩小的情况。
SimpleRNN Model 的缺陷
假如我们现在有几个单词序列输入,要预测最后一个单词,如下所示,再经过大量的数据训练,是可以准确预测正确的结果 mat 单词。
input:the cat sat on the
predict: mat
而如果我们现在这句话有 100 个单词,要预测下一个单词所需的 h100 向量,按道理说要预测的单词与这 100 个单词都有关系,只要 x1 到 x100 中的任意一个输入发生变化,预测的结果都会发生变化,但是实际上我们将 h100 对靠前的输入如 x1 或者 x2 进行求导是一个近似于 0 的数,这说明改变靠前的输入对预测结果几乎没有影响。换句话说此时的 h100 已经忘记了靠前的输入是什么,这种老年痴呆般的毛病是一个严重的问题,一般被称为“梯度消失”现象。
举例说明这个问题,如果我们上一段中有内容表述
我从出生就生活在中国
下一段的某句话需要填空
我擅长说的语言是___
正确的答案应该是“汉语”,而不是因为上下文距离太远你忘记了之前表述的内容从而预测错误的“英语”之类的。
下面两句话可以总结 SimpleRNN 的优缺点:
- SimpleRNN is good at short-term dependence.
- SimpleRNN is bad at long-term dependence.
提升 RNN 效果的技巧一——多层 RNN
现在我们只是介绍了一层 RNN ,我们可以用多层 RNN ,如图所示
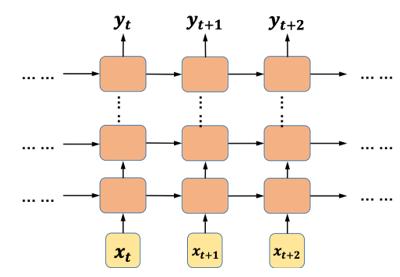
可以看出来最下面的第一层 RNN 接收 xt 的输入,之后每个时刻的隐层输出有两份拷贝,一份输入到下一时刻,另一份又作为输入,输进了第二层 RNN ,类推一直输入到最上面的 RNN ,最上面一层 RNN 输出的各个时刻隐层输出是最终的结果。
LSTM 是一种特殊的 RNN ,类似的可以将上图所有的 RNN 换成 LSTM ,即可得到多层的 LSTM ,原理类似。
能用多层就不要用单层。
提升 RNN 效果的技巧二——双向 RNN
因为对于计算机来说,理解一句话可以是从左往右,也可以是从右往左,而且两个方向的语义信息会更加丰富,所以一般双向的 RNN 总是比单向的效果好,尽管从右往左顺序的语义人类不容易理解。这样我们构造两个 RNN ,一个 RNN 捕捉正向的语义,另一个 RNN 捕捉反向的语义。
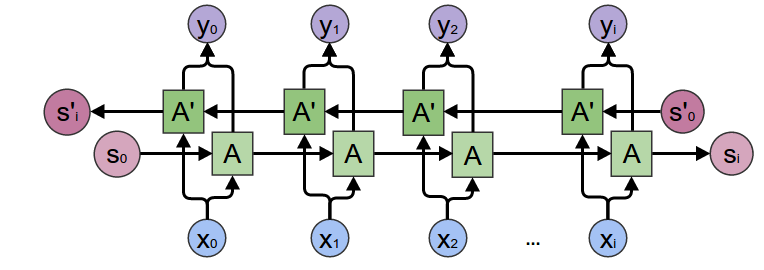
可以看到 xt 时刻的正向隐层输出和反向隐层输出进行拼接,得到了当前时刻的隐层输出 yt 。Sl 是正向积累了整个输入的最终的特征向量,S’l 是反向积累了整个输入的最终的特征向量。
LSTM 是一种特殊的 RNN ,类似的可以将上图所有的 RNN 换成 LSTM ,即可得到双向的 LSTM ,原理类似。
能用双向就不要用单向。
提升 RNN 效果的技巧三——预训练 Embedding
一般我们找大量的与任务数据相近的数据,不管是什么模型都可以,用这个模型来进行我们的任务训练,最后只保留 Embedding 层即可,然后在 Embedding 层之上搭建我们自己的网络。理想情况可以大大避免过拟合现象。因为在没有预训练的时候,往往都是因为 Embedding 层的参数太大导致过拟合。
SimpleRNN Model 的应用
尽管 SimpleRNN 存在长依赖问题,但是也不能掩盖其在应用中的巨大成功,RNN 在语音识别、语言建模、翻译,图像字幕等各种问题上取得了巨大成功,具体可以看这篇文章《The Unreasonable Effectiveness of Recurrent Neural Networks》
解决 SimpleRNN Model 缺陷的办法
下篇文章介绍 LSTM
案例
这是我之前写的一篇文章,其中有一个预测单词的小例子,只为展现原理,觉得不错的可以跳过去留赞,https://juejin.cn/post/6949412624215834638

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)