
百度飞桨常规赛------遥感影像地块分割实战(四月第九名)
常规赛:遥感影像地块分割实战文章目录常规赛:遥感影像地块分割实战赛题介绍数据说明赛题任务训练数据集提交内容及格式提交示例第一步 环境配置第二步 解压数据集数据预处理读取语义 分割任务数据集模型训练继续训练(可选)模型评估模型预测小结比赛页面传送门: 常规赛:遥感影像地块分割欢迎参加 飞桨领航团实战速成营赛题介绍本赛题由 2020 CCF BDCI 遥感影像地块分割 初赛赛题改编而来。遥感影像地块分
常规赛:遥感影像地块分割实战
本人项目源码传送门
https://aistudio.baidu.com/aistudio/projectdetail/1809354
文章目录
比赛页面传送门: 常规赛:遥感影像地块分割
欢迎参加 飞桨领航团实战速成营
赛题介绍
本赛题由 2020 CCF BDCI 遥感影像地块分割 初赛赛题改编而来。遥感影像地块分割, 旨在对遥感影像进行像素级内容解析,对遥感影像中感兴趣的类别进行提取和分类,在城乡规划、防汛救灾等领域具有很高的实用价值,在工业界也受到了广泛关注。现有的遥感影像地块分割数据处理方法局限于特定的场景和特定的数据来源,且精度无法满足需求。因此在实际应用中,仍然大量依赖于人工处理,需要消耗大量的人力、物力、财力。本赛题旨在衡量遥感影像地块分割模型在多个类别(如建筑、道路、林地等)上的效果,利用人工智能技术,对多来源、多场景的异构遥感影像数据进行充分挖掘,打造高效、实用的算法,提高遥感影像的分析提取能力。 赛题任务 本赛题旨在对遥感影像进行像素级内容解析,并对遥感影像中感兴趣的类别进行提取和分类,以衡量遥感影像地块分割模型在多个类别(如建筑、道路、林地等)上的效果。
数据说明
本赛题提供了多个地区已脱敏的遥感影像数据,各参赛选手可以基于这些数据构建自己的地块分割模型。
赛题任务
本赛题旨在对遥感影像进行像素级内容解析,并对遥感影像中感兴趣的类别进行提取和分类,以衡量遥感影像地块分割模型在多个类别(如建筑、道路、林地等)上的效果。
训练数据集
样例图片及其标注如下图所示:
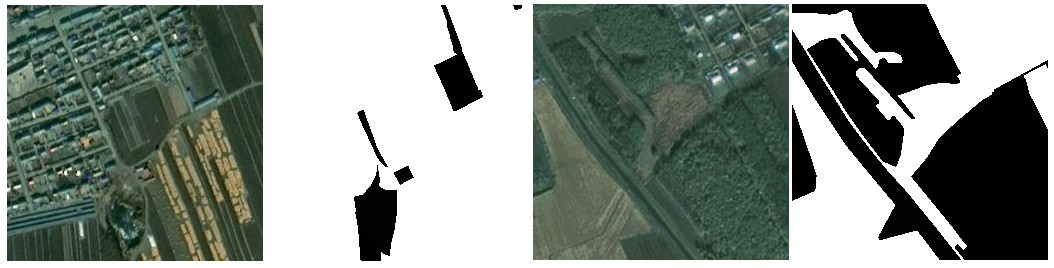
训练数据集文件名称:train_and_label.zip
包含2个子文件,分别为:训练数据集(原始图片)文件、训练数据集(标注图片)文件,详细介绍如下:
训练数据集(原始图片)文件名称:img_train
包含66,653张分辨率为2m/pixel,尺寸为256 * 256的JPG图片,每张图片的名称形如T000123.jpg。
训练数据集(标注图片)文件名称:lab_train
包含66,653张分辨率为2m/pixel,尺寸为256 * 256的PNG图片,每张图片的名称形如T000123.png。
备注: 全部PNG图片共包括4种分类,像素值分别为0、1、2、3。此外,像素值255为未标注区域,表示对应区域的所属类别并不确定,在评测中也不会考虑这部分区域。
测试数据集
测试数据集文件名称:img_test.zip,详细介绍如下:
包含4,609张分辨率为2m/pixel,尺寸为256 * 256的JPG图片,文件名称形如123.jpg。
提交内容及格式
- 以zip压缩包形式提交结果文件,文件命名为 result.zip;
- zip压缩包中的图片格式必须为单通道PNG;
- PNG文件数需要与测试数据集中的文件数相同,且zip压缩包文件名需要与测试数据集中的文件名一一对应;
- 单通道PNG图片中的像素值必须介于0~3之间,像素值不能为255。如果存在未标注区域,评测系统会自动忽略对应区域的提交结果。
提交示例
提交文件命名为:result.zip,zip文件的组织方式如下所示:
主目录
├── 1.png #每个结果文件命名为:测试数据集图片名称+.png
├── 2.png
├── 3.png
├── …
备注: 主目录中必须包含与测试数据集相同数目、名称相对应的单通道PNG图片,且每张单通道PNG图片中的像素值必须介于0~3之间,像素值不能为255。

第一步 环境配置
!pip install paddlex -i https://mirror.baidu.com/pypi/simple
!pip install imgaug -i https://mirror.baidu.com/pypi/simple
# 设置使用0号GPU卡(如无GPU,执行此代码后仍然会使用CPU训练模型)
import matplotlib
import os
import paddlex as pdx
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import numpy as np
from paddlex.seg import transforms
import imgaug.augmenters as iaa
from tqdm import tqdm
import cv2
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
def convert_to_list(value, n, name, dtype=np.int):
第二步 解压数据集
解压数据集并读取信息
!unzip -q data/data77571/train_and_label.zip
!unzip -q data/data77571/img_test.zip
!rm -rf __MACOSX
import numpy as np
datas = []
image_base = 'img_train' # 训练集原图路径
annos_base = 'lab_train' # 训练集标签路径
# 读取原图文件名
ids_ = [v.split('.')[0] for v in os.listdir(image_base)]
# 将训练集的图像集和标签路径写入datas中
for id_ in ids_:
img_pt0 = os.path.join(image_base, '{}.jpg'.format(id_))
img_pt1 = os.path.join(annos_base, '{}.png'.format(id_))
datas.append((img_pt0.replace('/home/aistudio', ''), img_pt1.replace('/home/aistudio', '')))
if os.path.exists(img_pt0) and os.path.exists(img_pt1):
pass
else:
raise "path invalid!"
# 打印datas的长度和具体存储例子
print('total:', len(datas))
print(datas[0][0])
print(datas[0][1])
print(datas[0][:])
total: 66652
img_train/T007604.jpg
lab_train/T007604.png
('img_train/T007604.jpg', 'lab_train/T007604.png')
import numpy as np
# 四类标签,这里用处不大,比赛评测是以0、1、2、3类来对比评测的
labels = ['0', '1', '2', '3']
# 将labels写入标签文件
with open('labels.txt', 'w') as f:
for v in labels:
f.write(v+'\n')
# 随机打乱datas
np.random.seed(5)
np.random.shuffle(datas)
# 验证集与训练集的划分,0.10表示10%为训练集,90%为训练集
split_num = int(0.10*len(datas))
# 划分训练集和验证集
train_data = datas[:-split_num]
valid_data = datas[-split_num:]
# 写入训练集list
with open('train_list.txt', 'w') as f:
for img, lbl in train_data:
f.write(img + ' ' + lbl + '\n')
# 写入验证集list
with open('valid_list.txt', 'w') as f:
for img, lbl in valid_data:
f.write(img + ' ' + lbl + '\n')
# 打印训练集和测试集大小
print('train:', len(train_data))
print('valid:', len(valid_data))
train: 59987
valid: 6665
数据预处理
from paddlex.seg import transforms
import imgaug.augmenters as iaa
# 定义训练和验证时的transforms
train_transforms = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.Resize(target_size=300),
transforms.RandomPaddingCrop(crop_size=256),
transforms.RandomBlur(prob=0.1),
transforms.RandomRotate(rotate_range=15),
# transforms.RandomDistort(brightness_range=0.5),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.Resize(256),
transforms.Normalize()
])
读取语义 分割任务数据集
data_dir = './'
# 定义训练和验证数据集
train_dataset = pdx.datasets.SegDataset(
data_dir=data_dir, # 数据集路径
file_list='train_list.txt', # 训练集图片文件list路径
label_list='labels.txt', # 训练集标签文件list路径
transforms=train_transforms, # train_transforms
shuffle=True) # 数据集是否打乱
eval_dataset = pdx.datasets.SegDataset(
data_dir=data_dir, # 数据集路径
file_list='valid_list.txt', # 验证集图片文件list路径
label_list='labels.txt', # 验证集标签文件list路径
transforms=eval_transforms) # eval_transforms
2021-05-24 09:47:22 [INFO] 59987 samples in file train_list.txt
2021-05-24 09:47:22 [INFO] 6665 samples in file valid_list.txt
模型训练
运行时长: 1天8小时10分钟43秒259毫秒
利用paddlex.seg.DeepLabv3p 构建 DeepLabv3p分割器。
import paddle
# 分割类别数
num_classes = len(train_dataset.labels)
# 构建DeepLabv3p分割器
model = pdx.seg.DeepLabv3p(
num_classes=num_classes, backbone='Xception65', use_bce_loss=False
)
visualdl = paddle.callbacks.VisualDL(log_dir='visualdl_log')
# 模型训练
model.train(
num_epochs=100, # 训练迭代轮数
train_dataset=train_dataset, # 训练集读取
train_batch_size=32, # 训练时批处理图片数
eval_dataset=eval_dataset, # 验证集读取
learning_rate=0.01, # 学习率
save_interval_epochs=4, # 保存模型间隔轮次
save_dir='output', # 模型保存路径
log_interval_steps=1000, # 日志打印间隔
pretrain_weights='output/best_model',
use_vdl=True) #加载预训练模型

继续训练(可选)
主要是怕运行过程中蹦了,不想从头再来
model = pdx.load_model(./output/epoch_100)
# 模型训练
model.train(
num_epochs=100, # 训练迭代轮数
train_dataset=train_dataset, # 训练集读取
train_batch_size=32, # 训练时批处理图片数
eval_dataset=eval_dataset, # 验证集读取
learning_rate=0.01, # 学习率
save_interval_epochs=4, # 保存模型间隔轮次
save_dir='output', # 模型保存路径
log_interval_steps=1000, # 日志打印间隔
pretrain_weights='output/best_model',
use_vdl=True) #加载预训练模型
模型评估
# 加载模型
model = pdx.load_model('./output/best_model')
# 模型评估
model.evaluate(eval_dataset, batch_size=16, epoch_id=None, return_details=False)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:298: UserWarning: /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlex/cv/nets/xception.py:316
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
2021-05-25 18:09:00 [INFO] Model[DeepLabv3p] loaded.
2021-05-25 18:09:00 [INFO] Start to evaluating(total_samples=6665, total_steps=417)...
100%|██████████| 417/417 [00:47<00:00, 8.83it/s]
OrderedDict([('miou', 0.6151651914567804),
('category_iou',
array([0.61855467, 0.76549378, 0.60033287, 0.47627945])),
('oacc', 0.7767960595081118),
('category_acc',
array([0.78364765, 0.84085465, 0.73642031, 0.67315414])),
('kappa', 0.6934252160032077),
('category_F1-score',
array([0.76432966, 0.86717245, 0.75026 , 0.64524294]))])
模型预测
from tqdm import tqdm
import cv2
test_base = 'img_testA/' # 测试集路径
out_base = 'result/' # 预测结果保存路径
# 是否存在结果保存路径,如不存在,则创建该路径
if not os.path.exists(out_base):
os.makedirs(out_base)
# 模型预测并保存预测图片
for im in tqdm(os.listdir(test_base)):
if not im.endswith('.jpg'):
continue
pt = test_base + im
result = model.predict(pt)
cv2.imwrite(out_base+im.replace('jpg', 'png'), result['label_map'])
100%|██████████| 4608/4608 [01:19<00:00, 57.66it/s]
小结
项目离MIoU高分还差很远。
具体的话可以再改进一下两点
1.数据预处理部分,加入更好的数据增强方案。
例如将本实验得到的结果数据0-3都扩大一定的倍数
(不放大全是黑图,人眼难以辨别)
查看一下图片显示那些存在明显的问题,人为去看一些有哪些通病,再去进行适当的预处理。
2.选用更合理的训练的轮次和其他等等训练参数。
3.当然,查阅了前面高分大佬的作品,也可以直接采用paddle的OCRNET进行预测,效果会比本项目好一些。
我在AI Studio上获得黄金等级,点亮7个徽章,来互关呀~
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/643467

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)