
基于python的中国气象局气象数据采集,可以作为数据集使用
db = pymysql.connect(host='localhost', user='root', password='root', port=3306, db='中国气象局')函数中,使用lxml库对网页内容进行解析。通过XPath路径选取相应的数据,并保存到变量中。库连接到MySQL数据库,并使用游标对象执行SQL语句,将数据插入到"天气数据"表格中。函数创建了一个名为"天气数据"的表格,
采集网站:
http://weather.cma.cn/web/weather/54161.html
使用技术:pymysql
requests
lxml
etree
实现:
通过爬取中国气象局网站上的天气数据,并将数据存储到MySQL数据库中。
首先,通过cun()函数创建了一个名为"天气数据"的表格,并定义了表格的各个列及其数据类型。
接下来,html_text()函数通过发送HTTP请求获取每个城市的天气页面内容。使用requests.get()方法发送GET请求,并指定了请求头部信息。
然后,在jiexi()函数中,使用lxml库对网页内容进行解析。通过XPath路径选取相应的数据,并保存到变量中。最后,使用pymysql库连接到MySQL数据库,并使用游标对象执行SQL语句,将数据插入到"天气数据"表格中。
在主函数main()中,定义了一个包含城市和对应URL的字典dic_。遍历字典中的每个键值对,分别调用html_text()函数获取网页内容,再调用jiexi()函数解析并存储数据。
最后,调用cun()函数创建数据库表格,并调用main()函数执行爬取和存储操作。
主要代码:
#读取每一页的代码
def html_text(my_list1):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
}
res = requests.get("http://weather.cma.cn"+my_list1, headers=headers).content
print(res)
return res
#解析数据,采集数据
def jiexi(tx,city):
db = pymysql.connect(host='localhost', user='root', password='root', port=3306, db='中国气象局')
cur = db.cursor()
soup = etree.HTML(tx)
dw = soup.xpath('/html/body/div[1]/div[2]/div[1]/div[1]/div[2]/div')
list0=[]
for i in dw:
list1=[]
riqi = i.xpath('./div[1]/text()[1]')[0] + i.xpath('./div[1]/text()[2]')[0]
tianqi = i.xpath('./div[3]/text()')[0]
fengxiang = i.xpath('./div[4]/text()')[0]
fengli = i.xpath('./div[5]/text()')[0]
max_1 = i.xpath('./div[6]/div/div[1]/text()')[0]
min_1 = i.xpath('./div[6]/div/div[2]/text()')[0]
n_tianqi = i.xpath('./div[8]/text()')[0]
n_fengxiang = i.xpath('./div[9]/text()')[0]
n_fengli = i.xpath('./div[10]/text()')[0]
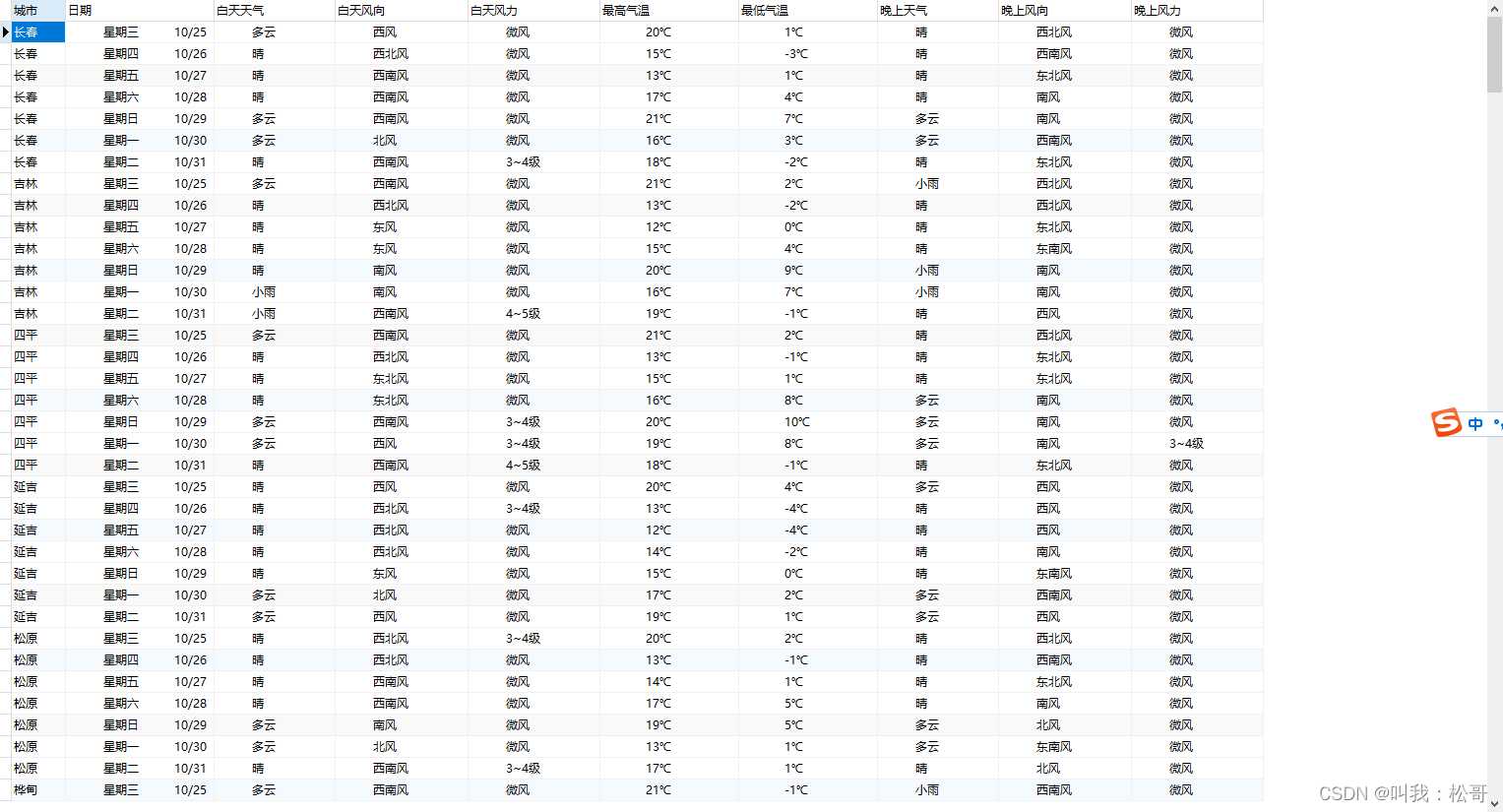
采集结果:

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)