
RNN和LSTM的几个问题探讨
每次提到RNN最先遇到的问题肯定是梯度消失和梯度爆炸,那么什么是梯度消失和梯度爆炸?RNN中为什么会出现这个问题呢?梯度消失和梯度爆炸是深度学习模型,特别是在训练递归神经网络(RNN)和深度前馈神经网络时可能遇到的两个主要问题。这两个问题都源于神经网络中梯度的连乘效应。梯度消失和梯度爆炸是RNN在反向传播过程中常见的问题,RNN的反向传播是通过时间的反向传播”(Backpropagation Th
1、RNN为什么容易梯度消失和梯度爆炸?
每次提到RNN最先遇到的问题肯定是梯度消失和梯度爆炸,那么什么是梯度消失和梯度爆炸?RNN中为什么会出现这个问题呢?
梯度消失和梯度爆炸是深度学习模型,特别是在训练递归神经网络(RNN)和深度前馈神经网络时可能遇到的两个主要问题。这两个问题都源于神经网络中梯度的连乘效应。
梯度消失(Vanishing Gradients)
在反向传播过程中,每个层的梯度是前一层梯度和当前层激活函数梯度的乘积。如果激活函数的导数小于1(如Sigmoid或Tanh函数),在多层网络中连乘后,梯度值可能会指数级下降,导致深层网络的权重更新非常缓慢,几乎停止学习。这种现象称为梯度消失。梯度爆炸(Exploding Gradients)
与梯度消失相反,如果网络中的梯度值在反向传播过程中指数级增长,那么就会发生梯度爆炸。这通常是由于权重的初始化过大或者网络架构设计不当导致的。梯度爆炸会导致网络权重的大幅更新,从而使得学习过程变得不稳定,网络无法收敛。
梯度消失和梯度爆炸是RNN在反向传播过程中常见的问题,RNN的反向传播是通过时间的反向传播”(Backpropagation Through Time,BPTT),其运行流程与一般的反向传播大有不同。在不同类型NLP任务会有不同的输出层结构、会有不同的标签输出方式。例如,在对词语/样本进行预测的任务中(情感分类、词性标注、时间序列等任务),RNN会在每个时间步都输出词语对应的相应预测标签;但是,在对句子进行预测的任务中(例如,生成式任务、seq2seq的任务、或以句子为单位进行标注、分类的任务),RNN很可能只会在最后一个时间步输出句子相对应的预测标签。输出标签的方式不同,反向传播的流程自然会有所区别。
假设现在我们有一个最为简单的RNN,需要完成针对每个词语的情感分类任务。该RNN由输入层、一个隐藏层和一个输出层构成,全部层都没有截距项,总共循环ttt个时间步。该网络的输入数据为XXX,输出的预测标签为y^\hat{y}y^,真实标签为yyy,激活函数为σ\sigmaσ,输入层与隐藏层之间的权重矩阵为WxhW_{xh}Wxh,隐藏层与输出层之间的权重矩阵为WhyW_{hy}Why,隐藏层与隐藏层之间的权重为WhhW_{hh}Whh,损失函数为L(y^,y)L(\hat{y},y)L(y^,y),t时刻的损失函数我们简写为LtL_tLt。此时,在时间步t上,这个RNN的正向传播过程可以展示如下:
ht=σ(WxhXt+Whhht−1)=σ(WxhXt+Whhσ(WxhXt−1+Whhht−2))y^t=WhyhtLt=L(y^t,yt) \begin{align*} \mathbf{h}_{t} &= \sigma(\mathbf{W}_{xh} \mathbf{X}_{t} + \mathbf{W}_{hh} \color{red}{\mathbf{h}_{t-1}}) \\ & = \sigma(\mathbf{W}_{xh} \mathbf{X}_t + \mathbf{W}_{hh} \color{red}{\sigma(\mathbf{W}_{xh} \mathbf{X}_{t-1} + \mathbf{W}_{hh} \mathbf{h}_{t-2})}) \\ \\ \mathbf{\hat{y}}_{t} &= \mathbf{W}_{hy} \mathbf{h}_{t} \\ \\ L_{t} &= L(\mathbf{\hat{y}}_{t},\mathbf{y}_{t}) \end{align*} hty^tLt=σ(WxhXt+Whhht−1)=σ(WxhXt+Whhσ(WxhXt−1+Whhht−2))=Whyht=L(y^t,yt)
不难发现,RNN中存在至少三个权重矩阵需要迭代:输入层与隐藏层之间的权重矩阵WxhW_{xh}Wxh,隐藏层与输出层之间的权重矩阵WhyW_{hy}Why,隐藏层与隐藏层之间的权重WhhW_{hh}Whh。当完成正向传播后,我们需要在反向传播过程中对以上三个权重求解梯度、并迭代权重,以WhhW_{hh}Whh为例——
时间步t,我们需要求解的其中一个梯度为:
3.1)∂Lt∂Whh \begin{align*} 3.1)\frac{\partial L_{t}}{\partial W_{hh}}\\ \\ \end{align*} 3.1)∂Whh∂Lt
根据之前的数学流程,LtL_{t}Lt可以展开展示为:
Lt=L(y^t,yt)=L(Whyht,yt)=L(Whyσ(WxhXt+Whhht−1),yt) \begin{align*} L_{t} &= L(\mathbf{\hat{y}}_{t}, \mathbf{y}_{t}) \\ \\ &=L(\mathbf{W}_{hy} \mathbf{h}_{t}, \mathbf{y}_{t}) \\ \\ &=L(\mathbf{W}_{hy} \sigma(\mathbf{W}_{xh} \mathbf{X}_{t} + \mathbf{W}_{hh} \mathbf{h}_{t-1}), \mathbf{y}_{t}) \end{align*} Lt=L(y^t,yt)=L(Whyht,yt)=L(Whyσ(WxhXt+Whhht−1),yt)
可见,LtL_{t}Lt是以y^t\hat{y}_{t}y^t为自变量的函数,y^t\hat{y}_{t}y^t是以WhyW_{hy}Why和hth_{t}ht为自变量的函数,hth_{t}ht又是以WxhW_{xh}Wxh和WhhW_{hh}Whh为自变量的函数,因此要求解上面三个梯度,其实是需要对复合函数进行求导。根据链式法则规则,如果y = f(u)并且u = g(x),那y直接对x求导的公式则可写成:
dydx=dydu⋅dudx \frac{dy}{dx} = \frac{dy}{du} \cdot \frac{du}{dx} dxdy=dudy⋅dxdu
因此根据链式法则,我们有:
1)∂Lt∂Why=∂Lt∂y^t∗∂y^t∂Why1)\frac{\partial L_{t}}{\partial W_{hy}} = \frac{\partial L_{t}}{\partial \hat{y}_{t}} * \frac{\partial \hat{y}_{t}}{\partial W_{hy}} 1)∂Why∂Lt=∂y^t∂Lt∗∂Why∂y^t
2) ∂Lt∂Wxh=∂Lt∂y^t∗∂y^t∂ht∗∂ht∂Wxh2) \ \frac{\partial L_{t}}{\partial W_{xh}} = \frac{\partial L_{t}}{\partial \hat{y}_{t}} * \frac{\partial \hat{y}_{t}}{\partial h_{t}} * \frac{\partial h_{t}}{\partial W_{xh}} 2) ∂Wxh∂Lt=∂y^t∂Lt∗∂ht∂y^t∗∂Wxh∂ht
3)∂Lt∂Whh=∂Lt∂y^t∗∂y^t∂ht∗∂ht∂Whh3)\frac{\partial L_{t}}{\partial W_{hh}} = \frac{\partial L_{t}}{\partial \hat{y}_{t}} * \frac{\partial \hat{y}_{t}}{\partial h_{t}} * \frac{\partial h_{t}}{\partial W_{hh}}3)∂Whh∂Lt=∂y^t∂Lt∗∂ht∂y^t∗∂Whh∂ht
好了,到这里为止循环神经网络的反向传播过程都与普通深度神经网络类似,但有的小伙伴可能已经注意到了,上面的公式2和3中存在一个关键问题,那就是hth_tht作为一个复合函数,不止能以WxhW_{xh}Wxh和WhhW_{hh}Whh为自变量,还能以上层的隐藏状态ht−1h_{t-1}ht−1作为自变量,而ht−1h_{t-1}ht−1本身又是以WxhW_{xh}Wxh和WhhW_{hh}Whh为自变量的函数:
Lt=L(y^t,yt)=L(Whyht,yt)=L(Whyσ(WxhXt+Whhht−1),yt)=L(Whyσ(WxhXt+Whhσ(WxhXt+Whhht−2),yt) \begin{align*} L_{t} &= L(\mathbf{\hat{y}}_{t}, \mathbf{y}_{t}) \\ \\ &=L(\mathbf{W}_{hy} \mathbf{h}_{t}, \mathbf{y}_{t}) \\ \\ &= L(\mathbf{W}_{hy} \sigma(\mathbf{W}_{xh} \mathbf{X}_{t} + \mathbf{W}_{hh} \color{red}{\mathbf{h}_{t-1}}), \mathbf{y}_{t}) \\ \\ &= L(\mathbf{W}_{hy} \sigma(\mathbf{W}_{xh} \mathbf{X}_{t} + \mathbf{W}_{hh} \color{red}{\sigma(\mathbf{W}_{xh} \mathbf{X}_{t} + \mathbf{W}_{hh} \mathbf{h}_{t-2})},\mathbf{y}_{t}) \end{align*} Lt=L(y^t,yt)=L(Whyht,yt)=L(Whyσ(WxhXt+Whhht−1),yt)=L(Whyσ(WxhXt+Whhσ(WxhXt+Whhht−2),yt)
此时你发现了吗?在求解LtL_{t}Lt对WhhW_{hh}Whh的导数时,不止可以求解上面所写的式子3,还可以继续对嵌套函数求解得到下面的梯度3——
3.2) ∂Lt∂Whh=∂Lt∂y^t∗∂y^t∂ht∗∂ht∂ht−1∗∂ht−1∂Whh \begin{align*} \color{red}{3.2)} \ \frac{\partial L_{t}}{\partial W_{hh}} &= \frac{\partial L_{t}}{\partial \hat{y}_{t}} * \frac{\partial \hat{y}_{t}}{\partial h_{t}} * \frac{\partial h_{t}}{\partial h_{t-1}} * \frac{\partial h_{t-1}}{\partial W_{hh}} \\ \\ \end{align*} 3.2) ∂Whh∂Lt=∂y^t∂Lt∗∂ht∂y^t∗∂ht−1∂ht∗∂Whh∂ht−1
甚至,我们还可以将ht−1h_{t-1}ht−1继续拆解为σ(WxhXt−1+Whhht−2)\sigma(\mathbf{W}_{xh} \mathbf{X}_{t-1} + \mathbf{W}_{hh} \mathbf{h}_{t-2})σ(WxhXt−1+Whhht−2),还可以将ht−2h_{t-2}ht−2继续拆解为σ(WxhXt−2+Whhht−3)\sigma(\mathbf{W}_{xh} \mathbf{X}_{t-2} + \mathbf{W}_{hh} \mathbf{h}_{t-3})σ(WxhXt−2+Whhht−3),我们可以将嵌套函数无止尽地拆解下去,直到拆到h1=σ(WxhX1+Whhh0)\mathbf{h}_1 = \sigma(\mathbf{W}_{xh} \mathbf{X}_1 + \mathbf{W}_{hh} \mathbf{h}_0)h1=σ(WxhX1+Whhh0)为止。在这个过程中,只要拆解足够多,我们可以从LtL_{t}Lt求解出t个针对和WhhW_{hh}Whh的导数。因此惊人的事实是,在时间步t上,我们可以计算t个用于迭代WxhW_{xh}Wxh和WhhW_{hh}Whh的梯度!
当我们将损失函数一直拆解到最后一层,且假设激活函数为恒等函数(为了简化数学流程)——
Lt=L(y^t,yt)=L(Whyht,yt)=L(Why(WxhXt+Whhht−1),yt)=L(Why(WxhXt+Whh(WxhXt−1+Whhht−2)),yt)⋮=L(Why(WxhXt+Whh(WxhXt−1+⋯+Whh(WxhX1+Whhh0))...),yt) \begin{align*} L_{t} &= L(\mathbf{\hat{y}}_{t}, \mathbf{y}_{t}) \\ \\ &=L(\mathbf{W}_{hy} \mathbf{h}_{t}, \mathbf{y}_{t}) \\ \\ &=L(\mathbf{W}_{hy} (\mathbf{W}_{xh} \mathbf{X}_{t} + \mathbf{W}_{hh} \mathbf{h}_{t-1}), \mathbf{y}_{t}) \\ \\ &=L(\mathbf{W}_{hy} (\mathbf{W}_{xh} \mathbf{X}_{t} + \mathbf{W}_{hh} (\mathbf{W}_{xh} \mathbf{X}_{t-1} + \mathbf{W}_{hh} \mathbf{h}_{t-2})), \mathbf{y}_{t}) \\ \\ & \vdots \\ \\ &=L(\mathbf{W}_{hy} (\mathbf{W}_{xh} \mathbf{X}_{t} + \mathbf{W}_{hh} (\mathbf{W}_{xh} \mathbf{X}_{t-1} + \dots + \mathbf{W}_{hh} (\mathbf{W}_{xh} \mathbf{X}_{1} + \mathbf{W}_{hh} \mathbf{h}_{0}))...), \mathbf{y}_{t}) \end{align*} Lt=L(y^t,yt)=L(Whyht,yt)=L(Why(WxhXt+Whhht−1),yt)=L(Why(WxhXt+Whh(WxhXt−1+Whhht−2)),yt)⋮=L(Why(WxhXt+Whh(WxhXt−1+⋯+Whh(WxhX1+Whhh0))...),yt)
在这个彻底拆解后的公式上,我们可以求解出嵌套了t层的WhhW_{hh}Whh的梯度(如公式3.t):
3.t) ∂Lt∂Whh=∂Lt∂y^t∗∂y^t∂ht∗∂ht∂ht−1∗∂ht−1∂ht−2∗ ... ∗∂h2∂h1∗∂h1∂Whh \begin{align*} {3.t)} \ \frac{\partial L_{t}}{\partial W_{hh}} &= \frac{\partial L_{t}}{\partial \hat{y}_{t}} * \frac{\partial \hat{y}_{t}}{\partial h_{t}} * \frac{\partial h_{t}}{\partial h_{t-1}} * \frac{\partial h_{t-1}}{\partial h_{t-2}} * \ \ ... \ \ * \frac{\partial h_2}{\partial h_1} * \frac{\partial h_1}{\partial W_{hh}} \\ \\ \end{align*} 3.t) ∂Whh∂Lt=∂y^t∂Lt∗∂ht∂y^t∗∂ht−1∂ht∗∂ht−2∂ht−1∗ ... ∗∂h1∂h2∗∂Whh∂h1
此时在这个公式中,许多偏导数的求解就变得非常简单,例如:
∵y^t=Whyht, ∴∂y^t∂ht=Why∵ht=WxhXt+Whhht−1, ∴∂ht∂ht−1=Whh∵ht−1=WxhXt−1+Whhht−2, ∴∂ht−1∂ht−2=Whh⋮∵h2=WxhX2+Whhh1, ∴∂h2∂h1=Whh∵h1=WxhX1+Whhh0, ∴∂h1∂Whh=h0 \begin{align*} &\because {\hat{y}}_{t} = W_{hy} h_{t},\ \ \therefore \frac{\partial \hat{y}_{t}}{\partial h_{t}} = {W}_{hy} \\ \\ &\because {h}_{t} = {W}_{xh} {X}_{t} + {W}_{hh} {h}_{t-1}, \ \ \therefore \frac{\partial h_{t}}{\partial h_{t-1}} = {W}_{hh} \\ \\ &\because {h}_{t-1} = {W}_{xh} {X}_{t-1} + {W}_{hh} {h}_{t-2}, \ \ \therefore \frac{\partial h_{t-1}}{\partial h_{t-2}} = {W}_{hh} \\ \\ & \vdots \\ \\ &\because {h}_2 = {W}_{xh} {X}_{2} + {W}_{hh} {h}_{1}, \ \ \therefore \frac{\partial h_2}{\partial h_1} = {W}_{hh} \\ \\ &\because {h}_1 = {W}_{xh} {X}_{1} + {W}_{hh} {h}_{0}, \ \ \therefore \frac{\partial h_1}{\partial {W}_{hh}} = {h}_{0} \end{align*} ∵y^t=Whyht, ∴∂ht∂y^t=Why∵ht=WxhXt+Whhht−1, ∴∂ht−1∂ht=Whh∵ht−1=WxhXt−1+Whhht−2, ∴∂ht−2∂ht−1=Whh⋮∵h2=WxhX2+Whhh1, ∴∂h1∂h2=Whh∵h1=WxhX1+Whhh0, ∴∂Whh∂h1=h0
所以最终的梯度表达式为:
3.t) ∂Lt∂Whh=∂Lt∂y^t∗∂y^t∂ht∗∂ht∂ht−1∗∂ht−1∂ht−2∗ ... ∗∂h2∂h1∗∂h1∂Whh=∂Lt∂y^t∗Why∗Whh∗Whh∗ ... ∗Whh∗h0=∂Lt∂y^t∗Why∗(Whh)t−1∗h0 \begin{align*} {3.t)} \ \frac{\partial L_{t}}{\partial W_{hh}} &= \frac{\partial L_{t}}{\partial \hat{y}_{t}} * \frac{\partial \hat{y}_{t}}{\partial h_{t}} * \frac{\partial h_{t}}{\partial h_{t-1}} * \frac{\partial h_{t-1}}{\partial h_{t-2}} * \ \ ... \ \ * \frac{\partial h_2}{\partial h_1} * \frac{\partial h_1}{\partial W_{hh}} \\ \\ &= \frac{\partial L_{t}}{\partial \hat{y}_{t}} * W_{hy} * W_{hh} * W_{hh} * \ \ ... \ \ * W_{hh} * h_0 \\ \\ &= \frac{\partial L_{t}}{\partial \hat{y}_{t}} * W_{hy} * (W_{hh})^{t-1}* h_0 \\ \\ \end{align*} 3.t) ∂Whh∂Lt=∂y^t∂Lt∗∂ht∂y^t∗∂ht−1∂ht∗∂ht−2∂ht−1∗ ... ∗∂h1∂h2∗∂Whh∂h1=∂y^t∂Lt∗Why∗Whh∗Whh∗ ... ∗Whh∗h0=∂y^t∂Lt∗Why∗(Whh)t−1∗h0
不难发现,在这个梯度表达式中出现了(Whh)t−1(W_{hh})^{t-1}(Whh)t−1这样的高次项,这就是循环神经网络非常容易梯度爆炸和梯度消失的根源所在——假设WhhW_{hh}Whh是一个小于1的值,那(Whh)t−1(W_{hh})^{t-1}(Whh)t−1将会非常接近于0,从而导致梯度消失;假设WhhW_{hh}Whh大于1,那(Whh)t−1(W_{hh})^{t-1}(Whh)t−1将会接近无穷大,从而引发梯度爆炸,其中梯度消失发生的可能性又远远高于梯度爆炸。
在深度神经网络中,在应用链式法则后,我们也会面临复合函数梯度连乘的问题,但由于普通神经网络中并不存在“权值共享”的现象,因此每个偏导数的表达式求解出的值大多是不一致的,在连乘的时候有的偏导数值较大、有的偏导数值较小,相比之下就不那么容易发生梯度爆炸或梯度消失问题的问题。
2、LSTM能够解决梯度消失和梯度爆炸问题吗?
来简单梳理一下LSTM的数学流程——
遗忘门:ft=σ(Wxf⋅xt+Whf⋅ht−1)f_t = \sigma(W_{xf} \cdot x_t + W_{hf} \cdot h_{t-1})ft=σ(Wxf⋅xt+Whf⋅ht−1)
输入门:it=σ(Wxi⋅xt+Whi⋅ht−1)i_t = \sigma(W_{xi} \cdot x_t + W_{hi} \cdot h_{t-1})it=σ(Wxi⋅xt+Whi⋅ht−1)
潜在细胞状态:C~t=tanh(Wxc⋅xt+Whc⋅ht−1)\tilde{C}_t = \tanh(W_{xc} \cdot x_t + W_{hc} \cdot h_{t-1})C~t=tanh(Wxc⋅xt+Whc⋅ht−1)
细胞状态更新:Ct=ft⋅Ct−1+it⋅C~tC_t = f_t \cdot C_{t-1} + i_t \cdot \tilde{C}_tCt=ft⋅Ct−1+it⋅C~t
输出门:ot=σ(Wxo⋅xt+Who⋅ht−1)o_t = \sigma(W_{xo} \cdot x_t + W_{ho} \cdot h_{t-1})ot=σ(Wxo⋅xt+Who⋅ht−1)
当下时刻输出:ht=ot⋅tanh(Ct)h_t = o_t \cdot \tanh(C_t)ht=ot⋅tanh(Ct)
LSTM在反向传播中的梯度求解链路可以被可视化为:
假设我们现在计算∂Lt∂Whf\frac{\partial L_{t}}{\partial W_{hf}}∂Whf∂Lt,则有——
3.t) ∂Lt∂Whf=∂Lt∂y^t∗∂y^t∂ht∗∂ht∂Ct∗∂Ct∂ft∗∂ft∂ht−1∗∂ht−1∂Ct−1 ... ∗∂f1∂Whf=∂Lt∂y^t∂y^t∂ht∗∂ht∂Ct∗[∂Ct∂Ct−1∗∂Ct−1∂Ct−2 ... ∗∂C2∂C1]∗∂C1∂f1∗∂f1∂whf=∂Lt∂y^t∂y^t∂ht∗∂ht∂Ct∗[ft∗ft−1∗ft−2...∗f1]∗∂C1∂f1∗∂f1∂whf \begin{align*} {3.t)} \ \frac{\partial L_{t}}{\partial W_{hf}} &= \frac{\partial L_{t}}{\partial \hat{y}_{t}} * \frac{\partial \hat{y}_{t}}{\partial h_{t}} * \frac{\partial h_{t}}{\partial C_{t}} * \frac{\partial C_{t}}{\partial f_{t}} * \frac{\partial f_{t}}{\partial h_{t-1}}* \frac{\partial h_{t-1}}{\partial C_{t-1}}\ \ ... \ \ * \frac{\partial f_1}{\partial W_{hf}} \\ \\ &= \frac{\partial L_{t}}{\partial \hat{y}_{t}} \frac{\partial \hat{y}_{t}}{\partial h_{t}} * \frac{\partial h_{t}}{\partial C_{t}} * [ \frac{\partial C_t}{\partial C_{t-1}} * \frac{\partial C_{t-1}}{\partial C_{t-2}} \ \ ... \ \ * \frac{\partial C_2}{\partial C_{1}}] * \frac{\partial C_1}{\partial f_1} * \frac{\partial f_1}{\partial w_{hf}} \\ \\ &= \frac{\partial L_{t}}{\partial \hat{y}_{t}} \frac{\partial \hat{y}_{t}}{\partial h_{t}} * \frac{\partial h_{t}}{\partial C_{t}} * [f_t * f_{t-1} * f_{t-2} ... * f_1] * \frac{\partial C_1}{\partial f_1} * \frac{\partial f_1}{\partial w_{hf}} \\ \\ \end{align*} 3.t) ∂Whf∂Lt=∂y^t∂Lt∗∂ht∂y^t∗∂Ct∂ht∗∂ft∂Ct∗∂ht−1∂ft∗∂Ct−1∂ht−1 ... ∗∂Whf∂f1=∂y^t∂Lt∂ht∂y^t∗∂Ct∂ht∗[∂Ct−1∂Ct∗∂Ct−2∂Ct−1 ... ∗∂C1∂C2]∗∂f1∂C1∗∂whf∂f1=∂y^t∂Lt∂ht∂y^t∗∂Ct∂ht∗[ft∗ft−1∗ft−2...∗f1]∗∂f1∂C1∗∂whf∂f1
通过避开共享权重的相乘,LSTM将循环网络梯度爆炸和梯度消失的危险性降低到了一般神经网络的水平。由于ftf_tft在0~1之间,因此就意味着梯度爆炸的风险将会很小,至于会不会梯度消失,取决于ftf_tft是否接近于1。如果当下时刻的长期记忆比较依赖于历史信息,那么ftf_tft就会接近于1,这时候历史的梯度信息也正好不容易消失;如果ftf_tft很接近于0,那么就说明当下的长期记忆不依赖于历史信息,这时候就算梯度消失也无妨了。
ftf_tft在0~1之间这个特性决定了它梯度爆炸的风险很小,同时ftf_tft表明了模型对历史信息的依赖性,也正好是历史梯度的保留程度,两者相互自洽,所以LSTM也能较好地缓解梯度消失问题。因此,LSTM同时较好地缓解了梯度消失/爆炸问题。
【有趣的小事实】
在今天看来,梯度消失和梯度爆炸是阻碍RNN能够被正常训练的关键问题,但在1990年代,算力和数据都十分缺乏、神经网络层数往往较浅、在研究中所需的迭代次数很少,序列长度也较短,因此RNN的梯度消失和梯度爆炸问题并没有这么显著。相对的,当时大量的研究(包括LSTM)都围绕着两个更加显著、更加直观的问题展开,其中一个问题是权重冲突(Weight Conflict),另一个问题是长短期信息冲突(Long-Short Term Information Conflict)。所以当我们追溯LSTM的结构与解决梯度消失、梯度爆炸问题有任何关联的时候,其实是无法找到其中的关联的。
3、LSTM中为什么CtC_tCt可以获得长期记忆
我们来看下公式
遗忘门:ft=σ(Wxf⋅xt+Whf⋅ht−1)f_t = \sigma(W_{xf} \cdot x_t + W_{hf} \cdot h_{t-1})ft=σ(Wxf⋅xt+Whf⋅ht−1)
输入门:it=σ(Wxi⋅xt+Whi⋅ht−1)i_t = \sigma(W_{xi} \cdot x_t + W_{hi} \cdot h_{t-1})it=σ(Wxi⋅xt+Whi⋅ht−1)
潜在细胞状态:C~t=tanh(Wxc⋅xt+Whc⋅ht−1)\tilde{C}_t = \tanh(W_{xc} \cdot x_t + W_{hc} \cdot h_{t-1})C~t=tanh(Wxc⋅xt+Whc⋅ht−1)
细胞状态更新:Ct=ft⋅Ct−1+it⋅C~tC_t = f_t \cdot C_{t-1} + i_t \cdot \tilde{C}_tCt=ft⋅Ct−1+it⋅C~t
输出门:ot=σ(Wxo⋅xt+Who⋅ht−1)o_t = \sigma(W_{xo} \cdot x_t + W_{ho} \cdot h_{t-1})ot=σ(Wxo⋅xt+Who⋅ht−1)
当下时刻输出:ht=ot⋅tanh(Ct)h_t = o_t \cdot \tanh(C_t)ht=ot⋅tanh(Ct)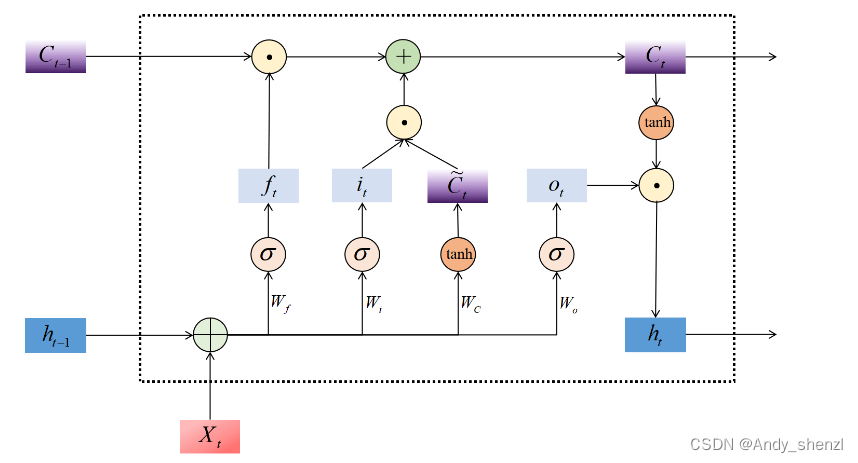
对于负责长期记忆的CtC_tCt,
Ct=ft⋅Ct−1+it⋅C~tC_t = f_t \cdot C_{t-1} + i_t \cdot \tilde{C}_tCt=ft⋅Ct−1+it⋅C~t
我们可以发现CtC_tCt是根据Ct−1C_{t-1}Ct−1计算而来,Ct−1C_{t-1}Ct−1同样也是来自于上一个记忆细胞Ct−2C_{t-2}Ct−2,也就是这个细胞时在整个时间步上持续迭代的所以会记住长期的信息
而对于负责短期记忆的ht=ot⋅tanh(Ct)h_t = o_t \cdot \tanh(C_t)ht=ot⋅tanh(Ct)
在hth_tht的计算中并没有来自于ht−1h_{t-1}ht−1的信息,所以是无法记住长期信息的

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 29
29 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)