
小米大模型岗面试,被问爆了......
由 1 节~5 节可知,获取当前 token 对应的 logit,仅Attention计算过程中,K 和 V 需要用到之前 token 的信息,其余计算各个 token 对应的向量都是独立的。在推理过程中,当前序列中,除最后一个 token 外,前面所有 token 的 KV Cache 在历史迭代中已经计算过。因此,我们可以预先分配一块显存,将这些已计算的 KV Cache 缓存起来,供下一个
截至目前,KV Cache 已成为大语言模型(LLM)推理的核心组件,几乎可以说是推理过程中的基石。
尽管各个平台已有大量关于 KV Cache 的相关文章,但读完后,很多内容往往缺乏对以下几个关键问题的深入剖析:
-
为什么可以使用
KV Cache? -
KV Cache 究竟节省了那些计算?
-
KV Cache 的引入对后续 LLM 推理优化有何影响?
因此,基于个人的理解,我写下了这篇文章,旨在从更全面的角度探讨 KV Cache 的作用与应用。
如果你在阅读过程中有新的见解,欢迎留言交流;如果发现文中有不准确的地方,也请不吝指正。
01
KV Cache 原理
这里从 LLM 的整个端到端推理过程出发,分析其计算优化的思路,进而引出 KV Cache 在这一过程中的优化作用,而不是先行介绍 KV Cache 的定义。
通过对推理流程中的关键环节进行剖析,我们能够更好地理解 KV Cache 如何在节省计算、提高效率方面发挥作用。
对 LLM 基础架构不了解的可以参考我之前写的这篇文章:琳琅阿木:图文详解LLM inference:LLM模型架构详解
https://zhuanlan.zhihu.com/p/14413262175回顾 LLM 的推理过程:输入一个预设的 prompt,将其传入模型,进行计算,最终得到 shape 为(batch_size, seq_len, vocab_size)的 logits,选用 sequence 中最后一个 token 的 logit 做采样,得到首字。
随后进入自回归阶段,模型依次利用前一步生成的 token,计算得到 logit,采样得到下一个 token,直至完成整个序列的生成。
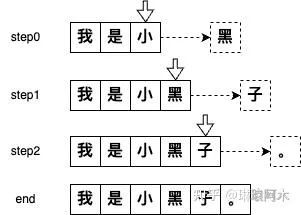
图1
无论是首字还是后续的 token,在预测下一个 token 时,模型都仅使用当前已知序列中的最后一个 token 的 logit 进行采样。
尽管在生成下一个 token 时,采样仅基于当前已知序列中最后一个 token 的 logit,但实际上,模型在计算 logits 时,会综合考虑整个已知序列的信息,以确保生成的 token 具有连贯性和一致性。
而这个过程就是通过 Attention 计算来实现。
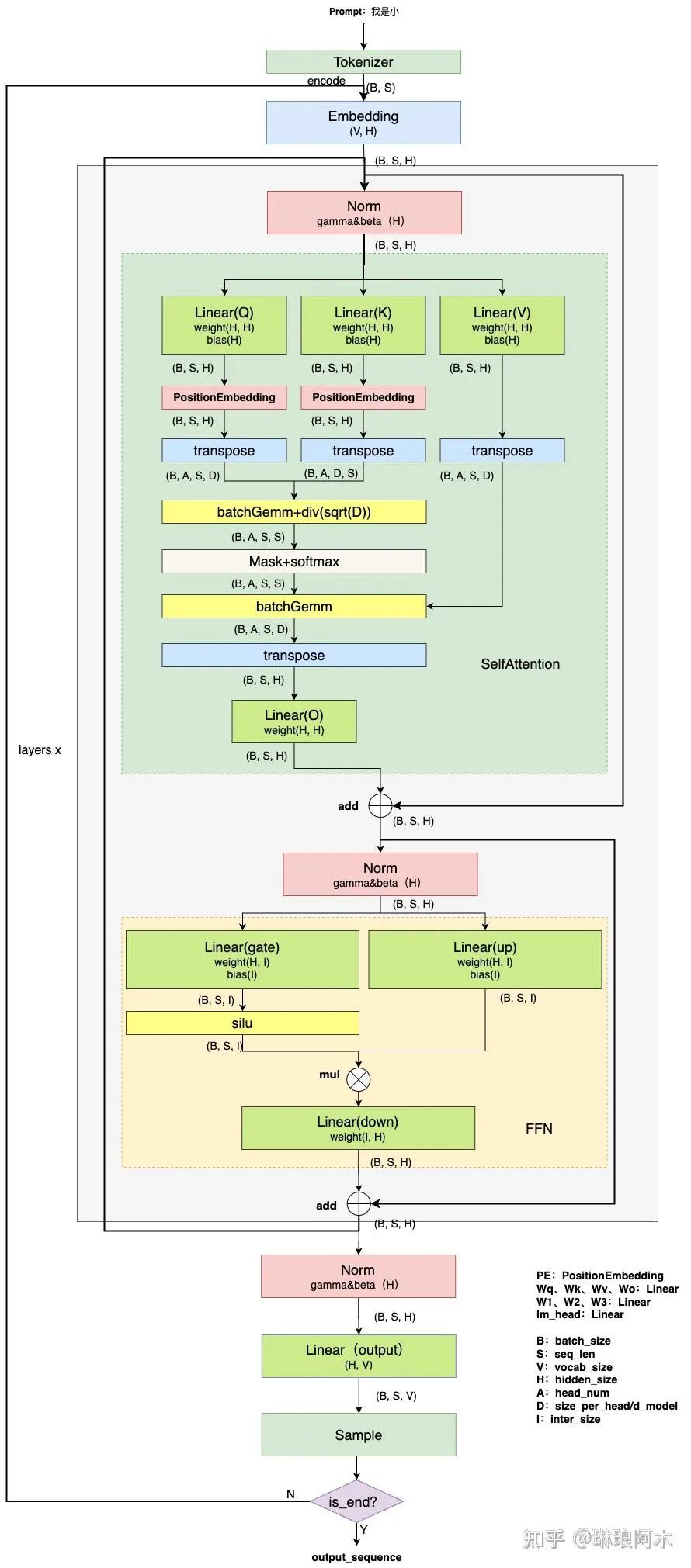
图2:LLM inference流程(详细版)
再次回到这张详细的流程图,从后往前进行分析。已知在当前步骤下需要预测下一个 token,那么我们所需的是当前 token(即已知序列中的最后一个 token)对应的 logit。这个 logit 用于采样下一个 token。
(1)Linear 分析
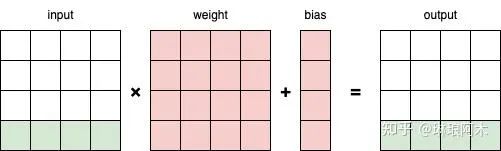
图3:Linear计算过程
上图为 Linear 的计算过程,很容易发现,对于输出的每一行,只和输入的最后一行有关。
(2)Norm 分析
这里直接看 RMSNorm 的源码:
https://github.com/meta-llama/llama/blob/main/llama/model.py#L34核心计算过程为:x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
可以看出,Norm 计算对每个 token 对应的向量进行归一化,因此,得到最后一个 token 对应的输出时,不会受到之前 token 的影响,二者互相独立。
(3)FFN 分析
FFN 计算过程本质就是两个(或 3 个)Linear。因此,可以很容易得出结论:最后一个 token 对应的输出与其他 token 的输入无关。
(4)Attention 分析
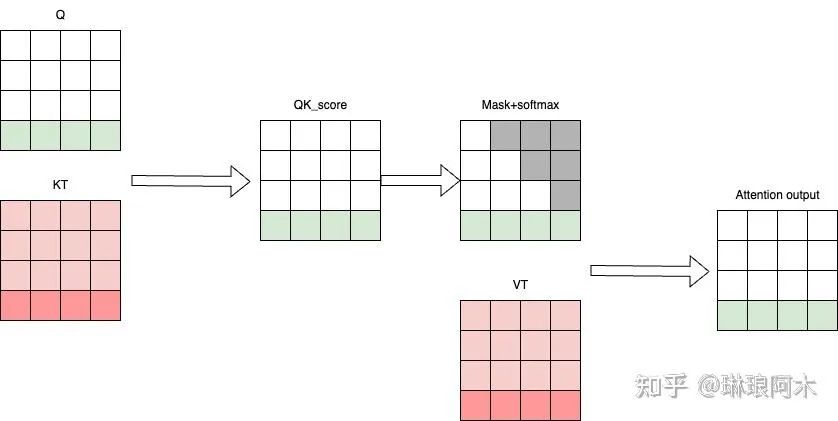
图4:Attention计算图解
从上图可以看出,要得到最终所需的 Attention output(绿色部分,即最后一个 token 对应的输出),我们需要最后一个 token 对应的 Q 和当前所有 token 对应 K 和 V。
(5)Embedding 分析
Embedding 过程本身是根据每一个 token,去找 token 对应的向量,本身各个 token 之间就是独立的。
(6)总结
由 1 节~5 节可知,获取当前 token 对应的 logit,仅 Attention 计算过程中,K 和 V 需要用到之前 token 的信息,其余计算各个 token 对应的向量都是独立的。
在推理过程中,当前序列中,除最后一个 token 外,前面所有 token 的 KV Cache 在历史迭代中已经计算过。
因此,我们可以预先分配一块显存,将这些已计算的 KV Cache 缓存起来,供下一个 step 使用。
02
杂谈
到这里可以试着回答下下面几个问题:
-
为什么可以使用 KV Cache?
-
KV Cache 节省了 Self-Attention 层中哪部分的计算?
-
KV Cache 对 MLP 层的计算量有影响吗?
-
KV Cache 对 block 间的数据传输量有影响吗?
不知道大家在阅读或者在盘整个流程时有没有产生过这样的疑惑,既然计算最后一个 token 用不到,那计算 Q,以及 FFN 这些计算,能否只算最后一个?
答案是不能,因为有多个 layer,当前 layer 计算 K 和 V 需要依赖上一层的输出,FFN 这些只计算最后一个 token,会导致下一层的 K 和 V 不对,进而影响最终结果。
那哪一些计算可以化简呢?
03
计算量分析
现在对图 2 进行修改,将带 KV Cache 的场景添加进来,LLM 推理过程分解为 Prefill 和 Decoding 两个阶段;
Prefill 阶段:发生在计算第一个 token(首字)时,此时 Cache 为空,需要计算所有 token 的 Key 和 Value,并将其缓存。由于涉及大量的 GEMM 计算,推理速度较慢。
Decoding 阶段:发生在计算第二个 token 以及后续所有 token,直到结束。
这时 Cache 中有之前 token 的 key 和 value 值,每轮计算可以从 Cache 中读取历史 token 的 key 和 value,只需计算当前 token 对应的 key 和 value,并写入 Cache。
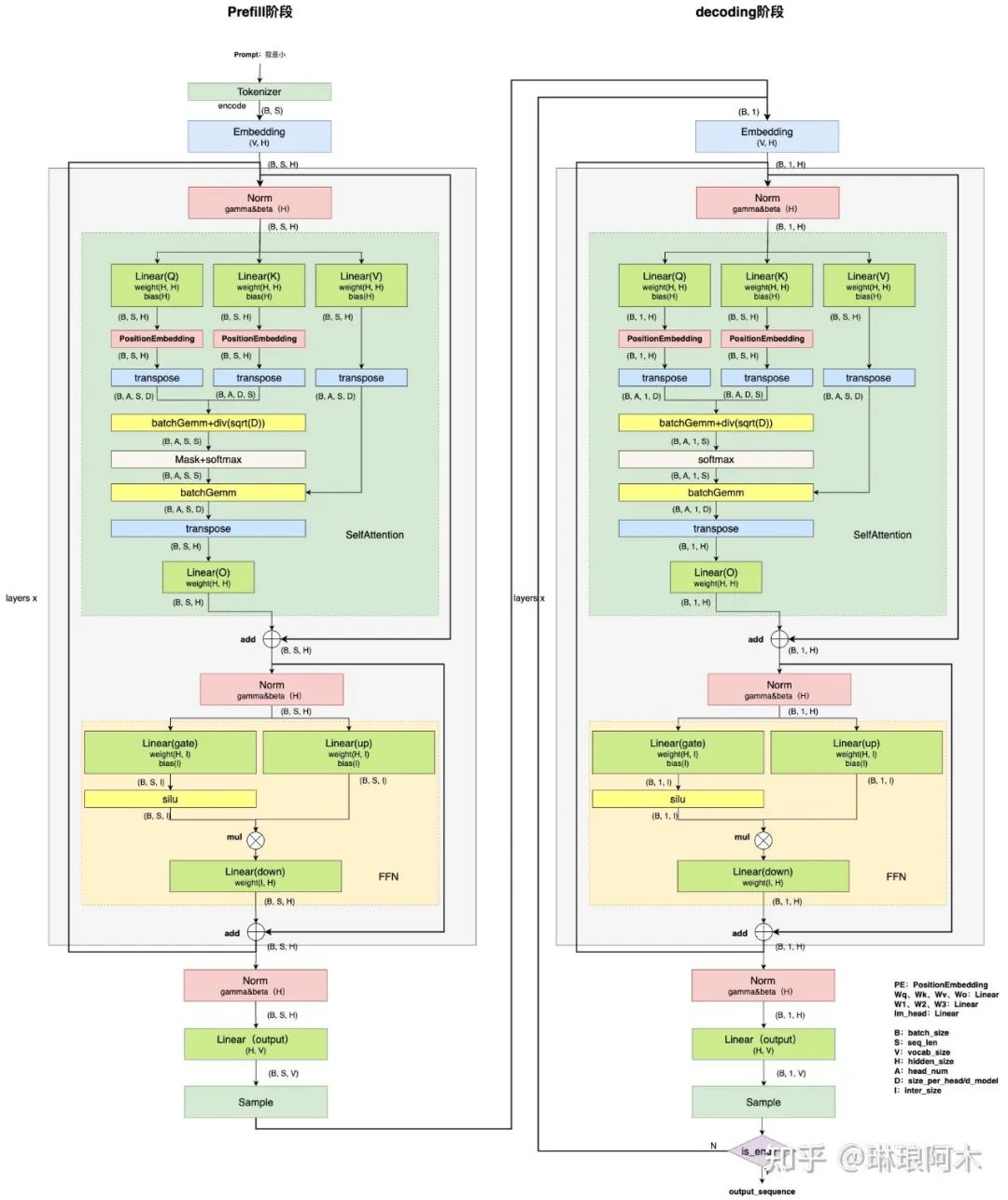
图5:LLM inference流程(KVCache)
假设序列长度为 S。
(1)Attention 计算量分析
输入变换和线性投影:从图 5 易知,Q 的计算由 GEMM 变为 GEMV, K 和 V 由于 Cache 的存在,也只用计算最后一个 token 对应 K 和 V,计算由 GEMM 变为 GEMV,最后的线性投影部分同理,计算量为原来的 1/S。
注意力得分:从图 5 可知,由于当前 Q 的长度为 1,因此计算 Score 和 Attention Output 的过程也由 GEMM 变为 GEMV,计算量为原来的 1/S。计算复杂度由 O(S²)降为 O(S)。
softmax:从图 5 可知,softmax 过程输入数据量是原来的 1/S,易知计算量为原来的 1/S。
其他:位置编码过程和 transpose 过程涉及计算量不多,div 过程易知计算量为原来的 1/S。
综上,使用 KV Cache 后,Attention 过程计算量整体降低为原来的 1/S,在序列比较长时,计算复杂度由 O(S²)降为 O(S)。
(2)Linear 和 FFN 计算量分析
FFN 过程和最后一个 Linear 都是线性过程,计算量和输入数据的量成正比关系。由图 5 易知,输入数据变为原来的 1/S,可得计算量为原来的 1/S。
综上所述,使用 KV Cache 能够显著减少非首字阶段的模型计算量。在每一步推理中,仅需要计算新增的 token 与先前序列的关联,而不是重新计算整个序列的所有注意力。这使得模型的整体计算复杂度从 O(S²)降至 O(S) 。
随着序列长度的不断增加,这种优化能够有效降低推理的时间和资源消耗,尤其是在处理长序列或高并发场景时表现尤为突出。
04
后记
KV Cache 的引入将大语言模型的推理过程自然地划分为 Prefill 和 Decoding 两个阶段。
由于 KV Cache 的存在,Decoding 阶段的计算量大幅降低,这两个阶段也因此呈现出截然不同的计算特点:
Prefill 阶段:以计算密集型(compute-bound)为主。该阶段需要对整个输入序列执行完整的 Transformer 计算,涉及大量矩阵乘法和注意力操作,计算复杂度较高。
Decoding 阶段:以内存密集型(memory-bound)为主。由于 KV Cache 的加入,Decoding 阶段只需对新增的 token 与缓存内容进行增量计算,计算量显著降低,但频繁的内存访问和更新使其更加依赖内存带宽。
这些阶段的不同特性催生了针对性优化策略。
Prefill 阶段优化:
-
Prefix Cache:对常用的前缀序列提前缓存其计算结果,避免重复计算,提高效率。
-
Chunked Prefill:将长序列分块处理,优化内存占用和并行计算效率。
Decoding 阶段优化:
-
Flash Decoding:通过高效的内存布局和缓存管理策略,减少内存访问延迟并提高显存利用率。
总结来看,针对不同阶段优化的设计思路,充分利用了计算和内存之间的权衡,进一步提升了大模型推理的性能和资源利用率。
这份《AI产品经理学习资料包》已经上传CSDN,还有完整版的大模型 AI 学习资料,朋友们如果需要可以在文末CSDN官方认证二维码免费领取【保证100%免费】
资料包: CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享

AI产品经理,0基础小白入门指南
作为一个零基础小白,如何做到真正的入局AI产品?
什么才叫真正的入局?
是否懂 AI、是否懂产品经理,是否具备利用大模型去开发应用能力,是否能够对大模型进行调优,将会是决定自己职业前景的重要参数。
你是否遇到这些问题:
1、传统产品经理
不懂Al无法对AI产品做出判断,和技术沟通丧失话语权
不了解 AI产品经理的工作流程、重点
2、互联网业务负责人/运营
对AI焦虑,又不知道怎么落地到业务中想做定制化AI产品并落地创收缺乏实战指导
3、大学生/小白
就业难,不懂技术不知如何从事AI产品经理想要进入AI赛道,缺乏职业发展规划,感觉遥不可及
为了帮助开发者打破壁垒,快速了解AI产品经理核心技术原理,学习相关AI产品经理,及大模型技术。从原理出发真正入局AI产品经理。
这里整理了一些AI产品经理学习资料包给大家
📖AI产品经理经典面试八股文
📖大模型RAG经验面试题
📖大模型LLMS面试宝典
📖大模型典型示范应用案例集99个
📖AI产品经理入门书籍
📖生成式AI商业落地白皮书
🔥作为AI产品经理,不仅要懂行业发展方向,也要懂AI技术,可以帮助大家:
✅深入了解大语言模型商业应用,快速掌握AI产品技能
✅掌握AI算法原理与未来趋势,提升多模态AI领域工作能力
✅实战案例与技巧分享,避免产品开发弯路
这份《AI产品经理学习资料包》已经上传CSDN,还有完整版的大模型 AI 学习资料,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
资料包: CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享免费领取【保证100%免费】🆓

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 32
32 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)