
如何训练自己的数据集之——电力设备缺陷检测数据集通过训练的输电线路缺陷数据集权重 训练识别检测绝缘子、绝缘子掉串、绝缘子破损、绝缘子闪络、防震锤、防震锤缺陷、鸟巢
电力缺陷检测数据集和训练好的模型】共7972多张,2.6G,yolo格式(图片和标注好的txt文件),已划分为训练集,验证集,测试集,比例为7:2:1。可以直接用于模型训练。训练好的模型为yolov5l模型,可直接提供权重文件和生成的所有数据图,利用权重文件可直接进行测试。绝缘子、绝缘子掉串、绝缘子破损、绝缘子闪络、防震锤、防震锤缺陷、鸟巢
 电力缺陷检测数据集和训练好的模型 共7972多张,2.6G,yolo格式(图片和标注好的txt文件),已划分为训练集,验证集,测试集,比例为7:2:1。可以直接用于模型训练。 训练好的模型为yolov5l模型,可直接提供权重文件和生成的所有数据图,利用权重文件可直接进行测试。绝缘子、绝缘子掉串、绝缘子破损、绝缘子闪络、防震锤、防震锤缺陷、鸟巢
电力缺陷检测数据集和训练好的模型 共7972多张,2.6G,yolo格式(图片和标注好的txt文件),已划分为训练集,验证集,测试集,比例为7:2:1。可以直接用于模型训练。 训练好的模型为yolov5l模型,可直接提供权重文件和生成的所有数据图,利用权重文件可直接进行测试。绝缘子、绝缘子掉串、绝缘子破损、绝缘子闪络、防震锤、防震锤缺陷、鸟巢
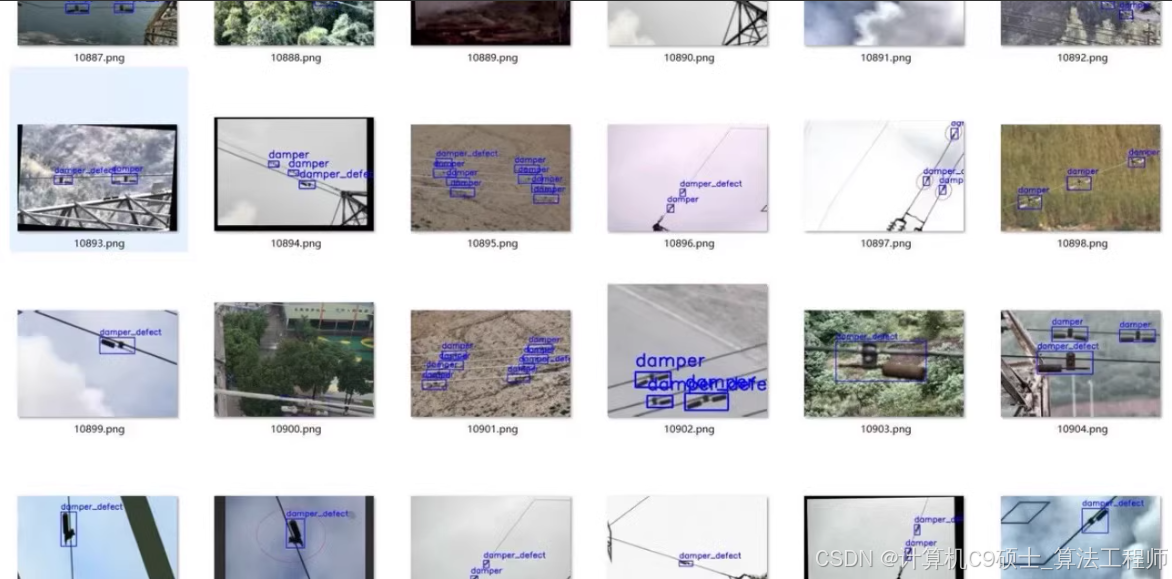
标注:insulator, insulator_stringdrop, insulator_breakage, insulator_flashover, damper, damper_defect, nest

电力缺陷检测数据集介绍
数据集概述
该数据集专注于电力设施中的缺陷检测,特别是针对绝缘子及其相关部件的常见缺陷。数据集包含7972张图片,总大小约为2.6GB,并且已经按照7:2:1的比例划分为训练集、验证集和测试集。数据集中的标注文件为YOLO格式的.txt文件,可以直接用于模型训练。
数据集特点
- 大容量数据集:包含大量的图片,有助于训练更加鲁棒的模型。
- 多类别标签:数据集涵盖了电力设施中常见的多种缺陷类型,有助于模型学习和识别复杂的缺陷模式。
- 明确的数据划分:数据集按照标准的比例划分为训练集、验证集和测试集,便于模型训练和性能评估。
- 适用性强:YOLO格式的标注文件方便使用YOLO框架进行训练,减少了数据预处理的工作量。
数据集内容
- 图像文件:共有7972张JPG/PNG格式的图像文件。
- 标注文件:每张图像都配有YOLO格式的
.txt标注文件。
数据集结构示例
假设数据集的根目录为 power_defects_dataset,其结构可能如下所示:
power_defects_dataset/
├── images/
│ ├── train/
│ │ ├── train_image_0001.jpg
│ │ ├── train_image_0002.jpg
│ │ └── ...
│ ├── val/
│ │ ├── val_image_0001.jpg
│ │ ├── val_image_0002.jpg
│ │ └── ...
│ ├── test/
│ │ ├── test_image_0001.jpg
│ │ ├── test_image_0002.jpg
│ │ └── ...
├── labels_yolo/
│ ├── train/
│ │ ├── train_image_0001.txt
│ │ ├── train_image_0002.txt
│ │ └── ...
│ ├── val/
│ │ ├── val_image_0001.txt
│ │ ├── val_image_0002.txt
│ │ └── ...
│ ├── test/
│ │ ├── test_image_0001.txt
│ │ ├── test_image_0002.txt
│ │ └── ...
└── data.yaml # 数据集配置文件数据集配置文件 data.yaml
创建一个data.yaml文件来描述您的数据集。这里假设数据集被放置在一个名为power_defects_dataset的目录中,且包含images和labels子目录。
# data.yaml 文件
train: ../power_defects_dataset/images/train/
val: ../power_defects_dataset/images/val/
test: ../power_defects_dataset/images/test/
nc: 7 # number of classes
names: ['insulator', 'insulator_stringdrop', 'insulator_breakage', 'insulator_flashover', 'damper', 'damper_defect', 'nest'] # class names关键训练代码
安装YOLOv5
如果您还没有安装YOLOv5,请按照官方文档执行以下命令:
git clone https://github.com/ultralytics/yolov5.git # clone repo
cd yolov5
pip install -r requirements.txt # install dependencies使用YOLOv5命令行训练
使用以下命令开始训练模型:
cd yolov5
python train.py --img 640 --batch 16 --epochs 300 --data ../power_defects_dataset/data.yaml --weights yolov5l.pt --cache自定义训练脚本
如果需要更详细的控制,可以编写一个Python脚本来执行训练过程。以下是一个简单的脚本示例:
import torch
from utils.datasets import LoadImagesAndLabels # 导入数据加载器
from models.experimental import attempt_load # 导入模型加载器
from utils.torch_utils import select_device # 导入选用设备的函数
from utils.general import check_dataset # 导入检查数据集的函数
def main():
device = select_device('') # 选择设备,自动选择GPU/CPU
data_yaml = '../power_defects_dataset/data.yaml'
train_images_folder = '../power_defects_dataset/images/train/'
train_labels_folder = '../power_defects_dataset/labels_yolo/train/'
val_images_folder = '../power_defects_dataset/images/val/'
val_labels_folder = '../power_defects_dataset/labels_yolo/val/'
# 加载数据集
train_set = LoadImagesAndLabels(train_images_folder, train_labels_folder)
val_set = LoadImagesAndLabels(val_images_folder, val_labels_folder)
# 创建数据加载器
train_loader = torch.utils.data.DataLoader(train_set, batch_size=16, shuffle=True, num_workers=4)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=16, shuffle=False, num_workers=4)
# 加载预训练模型
model = attempt_load('yolov5l.pt', map_location=device) # 加载预训练权重
model.to(device)
# 设置损失函数和优化器
criterion = torch.nn.BCEWithLogitsLoss() # 适用于多标签分类
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练循环
epochs = 300
for epoch in range(epochs):
model.train()
for images, targets, _, _ in train_loader:
images = images.to(device)
targets = [t.to(device) for t in targets]
# 前向传播
outputs = model(images)
# 计算损失
loss = criterion(outputs, targets)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item()}')
torch.save(model.state_dict(), 'trained_model.pt')
print('Training complete.')
if __name__ == '__main__':
main()注意事项
- 确保
data.yaml文件中的路径是正确的,并且数据集的结构与上面描述的一致。 - 调整批量大小、学习率、迭代次数等超参数以适应您的计算资源和任务需求。
- 如果数据集很大,您可能需要更多的计算资源和时间来完成训练。
- 这个脚本仅作为一个起点,您可能需要根据实际情况做进一步的修改。
测试模型
在训练完成后,您可以通过以下命令测试模型的性能:
python detect.py --weights runs/train/exp/weights/best.pt --img 640 --conf 0.4 --source ../power_defects_dataset/images/test/使用预训练模型进行测试
如果您已经有了训练好的模型权重文件,可以直接使用它来进行测试。假设权重文件名为best.pt,可以使用以下命令:
python detect.py --weights best.pt --img 640 --conf 0.4 --source ../power_defects_dataset/images/test/总结
这个示例展示了如何使用YOLOv5框架训练一个基于电力缺陷检测的数据集。您可以根据自己的需求调整脚本中的参数和逻辑。通过使用这个数据集和相应的训练代码,您可以有效地训练出一个能够在多种条件下识别电力设施中各种缺陷的模型。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)