
【深度学习系列】MNIST手写数字识别--PyTorch版
摘要:本文介绍了一个基于PyTorch的MNIST手写数字识别项目。使用包含7万张28×28灰度图像的经典数据集,构建了包含卷积层、ReLU激活、池化层和Dropout的CNN模型。通过Adadelta优化器和学习率调度器进行训练,最终测试准确率达到99.26%。文章详细解析了数据处理、网络结构和训练流程,并分析了模型在模糊数字上的识别困难。该项目作为深度学习入门实践,完整代码已开源,适合初学者学
一、数据集介绍
MNIST(Mixed National Institute of Standards and Technology)是一个经典的图像分类数据集,包含 70000张 手写数字图像,其中:
训练集:60000张
测试集:10000张
图像尺寸:28×28灰度图
标签范围:0~9,共10类数字
MNIST 是深度学习入门最常用的数据集,适用于图像分类、特征提取、模型调试等任务。
二、网络结构
卷积神经网络(CNN)结构: 通过卷积层提取图像局部特征; ReLU 增加非线性; 最大池化(MaxPool) 降低空间维度; Dropout 防止过拟合; 全连接层实现特征整合和分类; 最后使用 LogSoftmax 输出 10 类别的概率(对数形式)。相关概念见【深度学习系列】从模型到训练,逐步掌握深度学习核心术语和原理_深度学习做ai预测和分类小白入门csdn-CSDN博客
损失函数: 使用 F.nll_loss(负对数似然损失)+ log_softmax。 或者可以直接用 nn.CrossEntropyLoss(),代替两者。
优化器和调度器: 使用 Adadelta 优化器。 学习率逐轮调整:StepLR 每训练一轮后,学习率乘以 gamma=0.7。
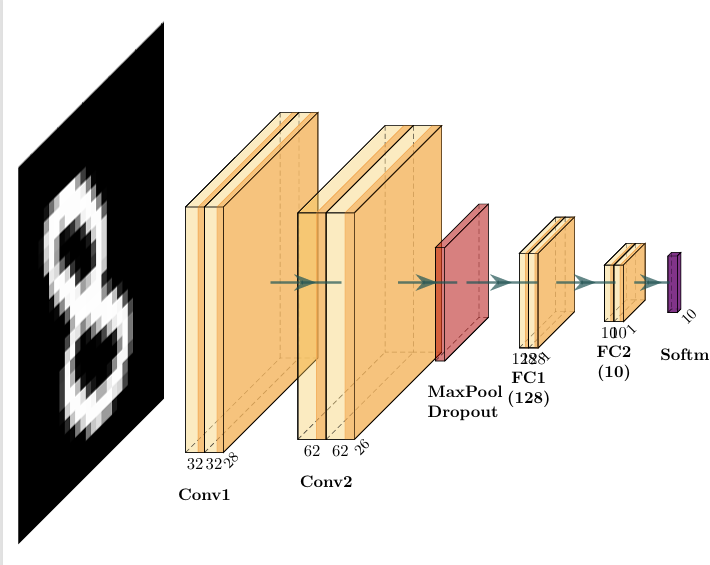
三、代码实现步骤与网络结构
1. 导入库和设置环境
import argparse # 命令行参数解析模块
import torch # PyTorch 的核心模块,用于创建张量(tensor)、调用 GPU 运算、自动求导等
import torch.nn as nn # PyTorch 的 神经网络模块(neural network),包括各种层(如 Linear, Conv2d, ReLU)、损失函数(如 CrossEntropyLoss)等
import torch.nn.functional as F
import torch.optim as optim # PyTorch 的 优化器模块,用来更新模型参数,比如 SGD、Adam、RMSprop 等
from torchvision import datasets,transforms # 为图像任务准备的数据和预处理模块,如转张量、归一化、裁剪、旋转等
from torch.optim.lr_scheduler import StepLR # 导入学习率调度器(Learning Rate Scheduler),用于训练过程中自动调整学习率
2. 构建CNN模型
2.1 初始化与定义模块:
输入图片尺寸是 28x28,单通道(灰度图),即28*28*1。
卷积层conv1中的参数:1是输入通道数,32是输出通道数(即卷积核个数,产生32张特征图,决定输出图像的通道数),卷积核大小是 3x3,步长 stride = 1,通过公式:
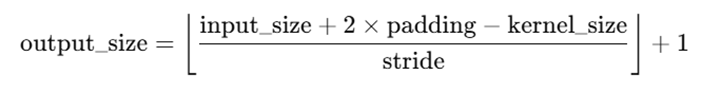
可以计算出该层的输出图像的尺寸是:output_size = (input_size - kernel_size) / stride + 1 = (28 - 3)/1 + 1 = 26。所以输出尺寸是26*26*32。
同理卷积层conv2卷积之后输出24*24*62。
而dropout层作用是随机将神经元失活,防止过拟合。
def __init__(self):
super(Net,self).__init__()
#输入形状:(batch_size, 1, 28, 28) 输出形状:(batch_size, 32, 26, 26)
self.conv1=nn.Conv2d(1,32,3,1)
# 输入形状:(batch_size, 32, 26, 26) 输出形状:(batch_size, 62, 24, 24)
self.conv2=nn.Conv2d(32,62,3,1)
self.dropout1=nn.Dropout(0.25) # 训练时随机将25%的神经元“置零”
self.dropout2=nn.Dropout(0.5)
# 输入形状:batch_size x 8928,8928是展开之后的
self.fc1=nn.Linear(8928,128)
self.fc2=nn.Linear(128,10)2.2 前向计算
代码里我详细注释了每一步的输入和输出变化,可以看看模型是怎么一步步从输入到最终输出的。
对于网络训练过程的输入和输出的尺度变化如下图:

def forward(self,x):
# 使用 32 个 3x3 卷积核进行卷积,步长 1,padding=0
# 输入尺寸:(batch_size, 1, 28, 28) 输出尺寸:(batch_size, 32, 26, 26)
x=self.conv1(x)
# ReLU 激活函数,把负数变成 0,增加非线性 输入/输出尺寸:不变
x=F.relu(x)
# 62个 3x3 卷积核,步长为1
# 输入尺寸:(batch_size, 32, 26, 26) 输出尺寸:(batch_size, 62, 24, 24)
x=self.conv2(x)
# 输入/输出尺寸:不变
x=F.relu(x)
# 2x2 的最大池化操作,步长默认为2
x=F.max_pool2d(x,2) # 输入尺寸:(batch_size, 62, 24, 24) 输出尺寸:(batch_size, 62, 12, 12)
x=self.dropout1(x)
# 将除了 batch 维度以外的所有维度拉平,准备送入全连接层,1 表示从第1维(也就是跳过 batch)开始展平
x=torch.flatten(x,1) #输入尺寸:(batch_size, 62, 12, 12) 输出尺寸:(batch_size, 62*12*12) = (batch_size, 8928)
# 全连接层,输入8928个特征,输出128个特征
x=self.fc1(x) #输入尺寸:(batch_size, 8928) 输出尺寸:(batch_size, 128)
x=F.relu(x)
x=self.dropout2(x) # 防止过拟合,随机将一半的神经元输出设为0(训练时)
x=self.fc2(x) # 把128个特征变成10个类别的 logits
# 对每一行(样本)做 softmax 后再取对数,用于配合 nn.NLLLoss() 作为损失函数
# dim=1 表示在“每一行”上做 softmax 操作,即对每个样本的类别得分归一化成概率
output=F.log_softmax(x,dim=1) # 输入尺寸:(batch_size, 10) 输出尺寸:(batch_size, 10)(每个样本的10类 log 概率)
return output3. 模型训练与测试
def train(args,model,device,train_loader,optimizer,epoch):
# 是用来将模型设置为“训练模式”(train mode), 让模型中的某些层(比如 Dropout 和 BatchNorm)工作在训练时的行为
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data,target=data.to(device),target.to(device)
optimizer.zero_grad()
output=model(data)
loss=F.nll_loss(output,target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval ==0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if args.dry_run:
break测试:
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
# .item() 把单个张量转换成 Python float,才能加到 test_loss 里
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
# dim=1 表示按行找最大值(即每个样本在 10 个类别中谁最大)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))4. 数据加载运行与可视化
4.1 数据下载与加载
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset1 = datasets.MNIST('../data', train=True, download=True,
transform=transform)
dataset2 = datasets.MNIST('../data', train=False,
transform=transform)
train_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
4.2 使用GPU
train_kwargs = {'batch_size': args.batch_size}
test_kwargs = {'batch_size': args.test_batch_size}
if use_cuda:
cuda_kwargs = {
'num_workers': 1,
'pin_memory': True,
'shuffle': True
}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
use_cuda = not args.no_accel and torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")4.3 其他配置设置
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=14, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-accel', action='store_true',
help='disables accelerator')
parser.add_argument('--dry-run', action='store_true',
help='quickly check a single pass')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true',
help='For Saving the current Model')
args = parser.parse_args()
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()四、实验结果
训练10轮后,模型准确率在 99.26% ,对于简单数字识别任务表现优秀。
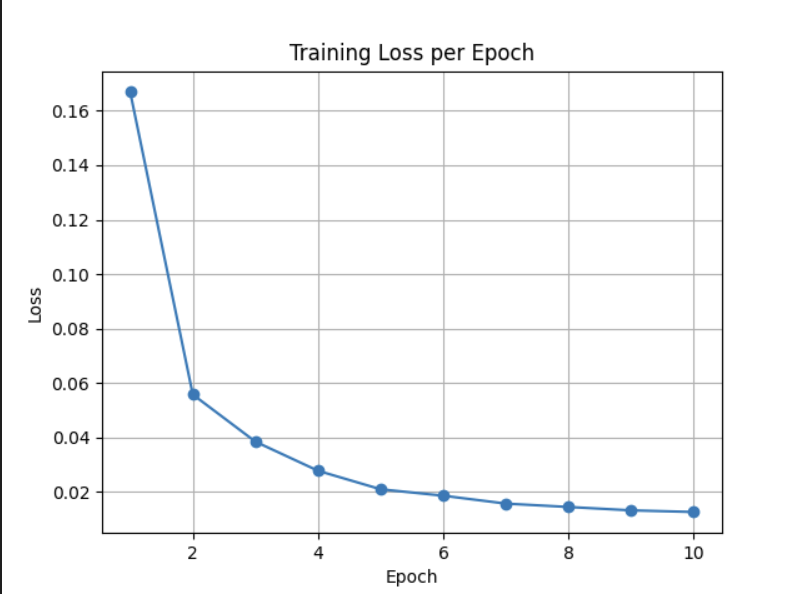
训练损失快速下降,模型收敛良好,无明显震荡或过早停止,训练阶段表现优秀。
如下图,对识别正确的和识别错误的图像打印几个查看,不难发现,识别正确的的数字都具备明显的识别度且数字完整。而识别错误的数字,一类是手写数字模糊性高,迷惑性强,即使是人眼也不轻易判断出来,比如下面的5识别成3;另一类是特征不明显或者部分丢失,但人眼还是可以识别出,比如下图的8,2,但机器识别就错误识别成2和7。针对这个特征模糊/部分缺失的问题,怎么改进呢?希望有大佬评论区指点一二。

本实验完整代码如下:https://github.com/lovesuger/Handwriting-recognition-mnist.git中的mainnew.py文件。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 40
40 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)