
河南大学机器学习与数据挖掘——第五章 神经网络
输入数据通过网络的每一层,每层的神经元计算其加权输入的总和,然后通过激活函数生成输出,传递到下一层。在(0.1)范围内随机初始化网格中所有连接权和阈值,到输出层产生结果,计算输出层神经元误差,传到隐藏层,计算隐藏层神经元误差,然后更新连接权和阈值,重复此过程直至达到停止条件,输出连接权和阈值确定的多层前馈神经网络。神经元模型:神经元接收到来自n个其他神经元传递过来的输入信号,这些输入信号通过带权
第五章 神经网络
-
神经元模型:神经元接收到来自n个其他神经元传递过来的输入信号,这些输入信号通过带权重的连接进行传递,神经元接收到的总输入值与神经元的阈值进行比较,然后通过“激活函数”处理以产生神经元的输出
-
感知机与多层网络
-
感知机由两层神经元组成,输入层和输出层,输入层接受外界信号,输出层输出结果。只有一层功能神经元,学习能力有限。
-
感知机能容易地实现与或非,不能实现异或运算
-
-
要解决非线性可分问题,要考虑使用多层神经网络。
一般分为输入层,隐藏层,输出层
隐藏层和输出层都是拥有激活函数的功能神经元
-
权重个数(考了计算)
(输入层+输出层)*隐藏层
-
参数个数(考了计算)
(输入层+输出层)*隐藏层+隐藏层+输出层
-
-
逆向误差传播算法BP
BP是一个迭代学习算法,BP算法基于梯度下降的策略。
BP算法学习能力较强,容易产生过拟合。
措施:
1.早停:将数据集分成训练集和验证集,训练集用来计算梯度、更新连接权和阈值,验证集用来估计误差,若训练集误差降低但验证集误差升高,则停止训练,同时返回具有最小验证集误差的连接权和阈值。
2.提高正则化参数:在误差目标函数中增加一个用语描述网络复杂度的部分。
-
BP算法的过程(考试考了简答题)
在(0.1)范围内随机初始化网格中所有连接权和阈值,到输出层产生结果,计算输出层神经元误差,传到隐藏层,计算隐藏层神经元误差,然后更新连接权和阈值,重复此过程直至达到停止条件,输出连接权和阈值确定的多层前馈神经网络。
测试题
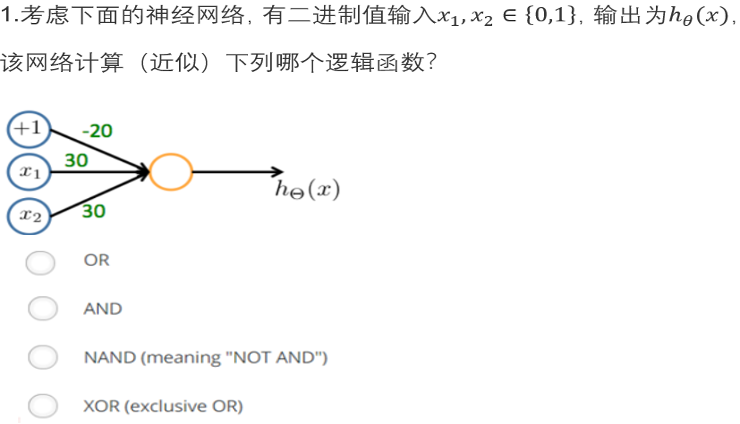
OR
2.下面的描述是否正确?在前面的括号中填True/False。
( False )(1)一个两层(一个输入层,一个输出层;没有隐含层)的神经网络可以表示XOR函数。
( True )(2)在神经网络中,如果每层都是用sigmoid函数作为激活函数,那么隐藏层神经单元的激活值在(0,1)范围内。
( True )(3)如果神经网络在训练集上过拟合,一种合理的解决方法是提高正则化参数λ的值。
( True )(4)假设正确地实现了反向传播算法,并且使用梯度下降来训练一个神经网络。如果把J(θ)作为迭代次数的函数,并且发现它是递增的而不是递减的。一个可能的原因是,学习速率太大了。
( True )(5)如果使用梯度下降来训练一个神经网络,一个合理的“调试”步骤以确保它的工作是将J(θ)作为迭代次数的函数,并确保在每次迭代之后它正在减少(或者至少不是增加)。
( False )(6)假定我们使用学习率为α的梯度下降。对于对数几率回归和线性回归,J(θ)是一个凸优化问题,因此我们不会选一个太大的学习率。然而对于神经网络,J(θ)可能是非凸的,因此选择一个非常大的α可以加速收敛。
3. M-P神经元模型中,神经元接收来自其他神经元传递过来的输入信号,这些输入信号通过______突触_________进行传递,神经元接收到的总输入值与__阈值_____进行比较,然后通过________激活函数_______处理以产生神经元的输出。
4.误差逆传播算法(BP算法)基于_________梯度下降__________策略,以目标的负梯度方向对参数进行调整。
5.假定一个单隐层的前馈神经网络,拥有m个输入神经元,n个输出神经元、q个隐层神经元,那么该神经网络中需要确定的连接权重参数有多少个? (会考)
m*q+q*n
6.常用来缓解BP网络的过拟合的策略有什么?
正则化:在损失函数中添加正则项
早停:当验证集上的性能开始下降时停止训练。
dropout:随机丢弃一部分神经元的输出,减少神经元之间关系。
数据增强:生成新的训练样本来增加数据集的大小
7. 请简述感知机模型,感知机的学习策略与学习算法。
感知机模型是一种二分类的线性分类模型,包括输入层、计算层和输出层。学习策略是试图找到一个能够将不同类别的数据分开的超平面。学习算法基于误分类的迭代过程,每次迭代中,对于被错误分类的样本,感知机更新权重减少误分类的数量。
8. 误差逆传播(error BackPropagation,简称BP)算法是神经网络学习算法,简述使用BP算法训练多层前馈神经网络的工作过程。(背一下会考)
输入数据通过网络的每一层,每层的神经元计算其加权输入的总和,然后通过激活函数生成输出,传递到下一层。随后网络的最后一层输出与真实标签比较,计算损失函数的值。损失函数的梯度从输出层开始反向传播到网络的每一层,计算每层每个权重参数的梯度。之后使用梯度下降法或其他优化算法,根据计算出的梯度更新网络中的权重和偏置。重复上述过程,直到达到停止条件。
9.简述标准BP算法与累积BP算法的区别。
标准BP算法在每次迭代中,网络只使用一个训练样本来计算梯度,并更新权重。这意味着每次权重更新只考虑了一个样本的信息。而累积BP算法在每次迭代中使用整个训练集或一个较大的数据批次来计算梯度,并更新权重,有助于避免局部最小值,但需要更多的计算资源和内存。
10.课后习题5.4。
学习率决定每一轮迭代的更新周长,如果学习率太大则容易振荡无法收敛,而学习率太小则导致模型收敛速度过慢。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)