
机器学习系列(15)_KNN(K近邻)算法
文章目录一、KNN1、K值的判断与选取2、缺失值差填补3、KNN填充和模型评估4、RESSION一、KNNKNN最邻近分类算法的实现原理:为了判断未知样本的类别,以所有已知类别的样本作为参照,计算未知样本与所有已知样本的距离,从中选取与未知样本距离最近的K个已知样本,根据少数服从多数的投票法则(majority-voting),将未知样本与K个最邻近样本中所属类别占比较多的归为一类。KNN属于懒惰
注:考试可能考的链接
1、KNN机器学习分类结果测试分析
2、TP、TN、FP、FN超级详细解析
3、机器学习之分类<朴素贝叶斯>
4、sklearn中的KNN
KNN
KNN最邻近分类算法的实现原理:为了判断未知样本的类别,以所有已知类别的样本作为参照,计算未知样本与所有已知样本的距离,从中选取与未知样本距离最近的K个已知样本,根据少数服从多数的投票法则(majority-voting),将未知样本与K个最邻近样本中所属类别占比较多的归为一类。
KNN属于懒惰学习,没有前期训练过程,而是在程序开始运行时,把数据加载到内存后,直接开始进行分类。
KNN分类算法的计算过程:
【1】计算待分类点与已知点之间的类别
【2】按照距离递增次序排序
【3】选取与待分类点距离最小的K个点
【4】确定前k个点所在类别的出现次数
【5】返回前k个点出现次数最高的类别作为待分类点的预测分类
KNN用来回归:
要预测的点的值通过求与它距离最近的K个点的值的平均值得到,这里的“距离最近"可以是欧氏距离,也可以是其他距离,具体的效果依数据而定,思路一样。如下图,x轴是一个特征,y是该特征得到的值,红色点是已知点,要预测第一个点的位置,则计算离它最近的三个点(黄色线框里的三个红点)的平均值,得出第一个绿色点,依次类推,就得到了绿色的线,可以看出,这样预测的值明显比直线准。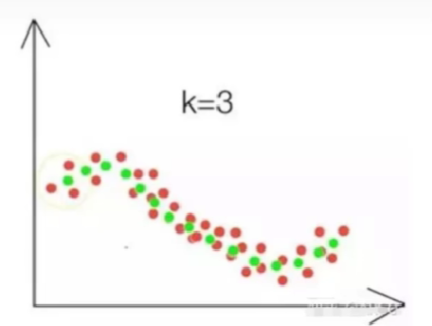
1、K值的判断与选取
导入库:
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
from subprocess import check_output
导入数据:
data = pd.read_csv('column_2C_weka.csv')
参数解释:
显示绘图的主题,风格与类别:
print(plt.style.available)
plt.style.use('ggplot')
绘制多子图:
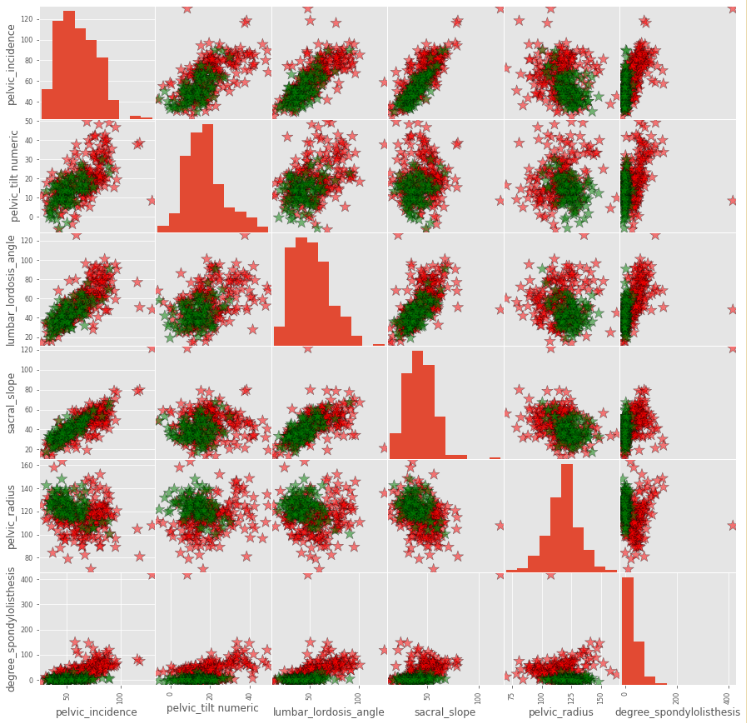
color_list = ['red' if i=='Abnormal' else 'green' for i in data.loc[:,'class']]
pd.plotting.scatter_matrix(data.loc[:, data.columns != 'class'],
c=color_list,
figsize= [15,15],
diagonal='hist',
alpha=0.5,
s = 200,
marker = '*',
edgecolor= "black")
plt.show()
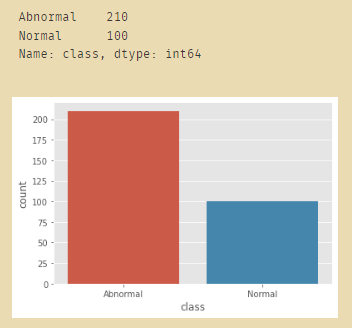
绘制正常与不正常的柱形图比例:
sns.countplot(x="class", data=data)
data.loc[:,'class'].value_counts()
计算KNN的精确度:
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.3,random_state = 1)
knn = KNeighborsClassifier(n_neighbors = 3)
x,y = data.loc[:,data.columns != 'class'], data.loc[:,'class'] #将特征和标签进行分割
knn.fit(x_train,y_train)
prediction = knn.predict(x_test)
print('With KNN (K=3) accuracy is: ',knn.score(x_test,y_test))

from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 3)
x,y = data.loc[:,data.columns != 'class'], data.loc[:,'class']
knn.fit(x,y)
prediction = knn.predict(x)
print('Prediction: {}'.format(prediction))

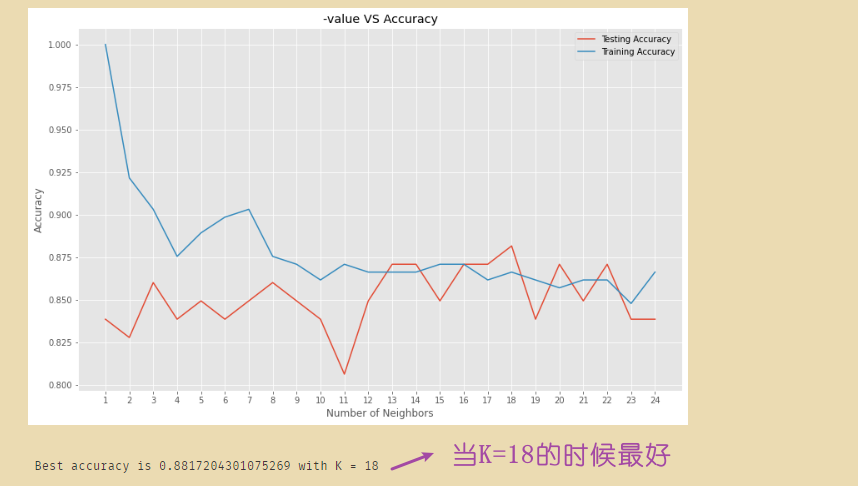
通过学习曲线寻找精确度最高的K值:
neig = np.arange(1, 25)
train_accuracy = []
test_accuracy = []
# Loop over different values of k
for i, k in enumerate(neig):
# k from 1 to 25(exclude)
knn = KNeighborsClassifier(n_neighbors=k)
# Fit with knn
knn.fit(x_train,y_train)
#train accuracy
train_accuracy.append(knn.score(x_train, y_train))
# test accuracy
test_accuracy.append(knn.score(x_test, y_test))
# Plot
plt.figure(figsize=[13,8])
plt.plot(neig, test_accuracy, label = 'Testing Accuracy')
plt.plot(neig, train_accuracy, label = 'Training Accuracy')
plt.legend()
plt.title('-value VS Accuracy')
plt.xlabel('Number of Neighbors')
plt.ylabel('Accuracy')
plt.xticks(neig)
plt.savefig('graph.png')
plt.show()
print("Best accuracy is {} with K = {}".format(np.max(test_accuracy),1+test_accuracy.index(np.max(test_accuracy))))
2、缺失值差填补
import pandas as pd
dataframe=pd.read_csv("horse-colic.csv",header=None,na_values='?')
na_values='?'表示将数据当中的 ?变成NAN值
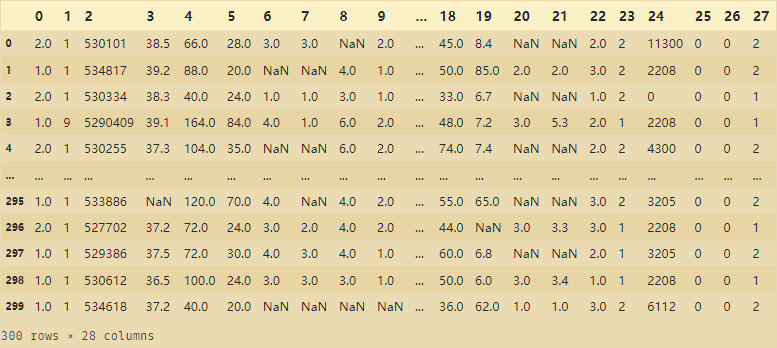
查找缺失值占比:
for i in range(dataframe.shape[1]):
# count number of rows with missing values
n_miss = dataframe[[i]].isnull().sum()
perc = n_miss / dataframe.shape[0] * 100
print('> %d, Missing: %d (%.1f%%)' % (i, n_miss, perc))
通过拟合填充数据:
from numpy import isnan
from pandas import read_csv
from sklearn.impute import KNNImputer
data = dataframe.values
ix = [i for i in range(data.shape[1]) if i != 23]
X, y = data[:, ix], data[:, 23]
# print total missing
print('Missing: %d' % sum(isnan(X).flatten()))
# define imputer
imputer = KNNImputer()
# fit on the dataset
imputer.fit(X)
# transform the dataset
Xtrans = imputer.transform(X)
# print total missing
print('Missing: %d' % sum(isnan(Xtrans).flatten()))
填充完成,缺失值为0:
3、KNN填充和模型评估
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import KNNImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
data = dataframe.values
ix = [i for i in range(data.shape[1]) if i != 23]
X, y = data[:, ix], data[:, 23]
# define modeling pipeline(管道过滤)
model = RandomForestClassifier()
imputer = KNNImputer()
pipeline = Pipeline(steps=[('i', imputer), ('m', model)])
# define model evaluation
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluate model
scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores)))
平均正确率:
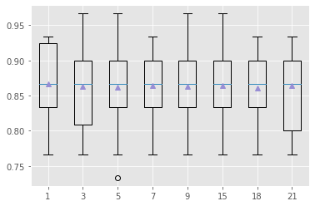
#不同k值的学习曲线
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import KNNImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from matplotlib import pyplot
# split into input and output elements
data = dataframe.values
ix = [i for i in range(data.shape[1]) if i != 23]
X, y = data[:, ix], data[:, 23]
# evaluate each strategy on the dataset
results = list()
strategies = [str(i) for i in [1,3,5,7,9,15,18,21]]
for s in strategies:
# create the modeling pipeline(管道过滤) 直接创建随机森林管道
pipeline = Pipeline(steps=[('i', KNNImputer(n_neighbors=int(s))), ('m', RandomForestClassifier())])
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# store results
results.append(scores)
print('>%s %.3f (%.3f)' % (s, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=strategies, showmeans=True)
pyplot.show()

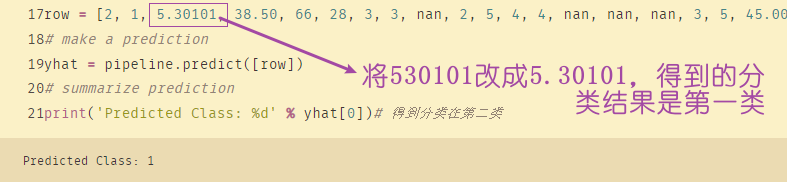
下面的row是随机构造出来的一组数据,用来检验训练的数据集:
row = [2, 1, 530101, 38.50, 66, 28, 3, 3, nan, 2, 5, 4, 4, nan, nan, nan, 3, 5, 45.00, 8.40, nan, nan, 2, 11300, 00000, 00000, 2]
from numpy import nan
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import KNNImputer
from sklearn.pipeline import Pipeline
# split into input and output elements
data = dataframe.values
ix = [i for i in range(data.shape[1]) if i != 23]
X, y = data[:, ix], data[:, 23]
# create the modeling pipeline
pipeline = Pipeline(steps=[('i', KNNImputer(n_neighbors=21)), ('m', RandomForestClassifier())])
# fit the model
pipeline.fit(X, y)
# define new data(把新的数据当成测试集放入原数据)
row = [2, 1, 530101, 38.50, 66, 28, 3, 3, nan, 2, 5, 4, 4, nan, nan, nan, 3, 5, 45.00, 8.40, nan, nan, 2, 11300, 00000, 00000, 2]
# make a prediction
yhat = pipeline.predict([row])
# summarize prediction
print('Predicted Class: %d' % yhat[0])# 得到分类在第二类
将刚刚随机构造的数据进行分类,得到的结果是第二类
4、RESSION
回归数据监督学习,分为线性回归和逻辑回归。
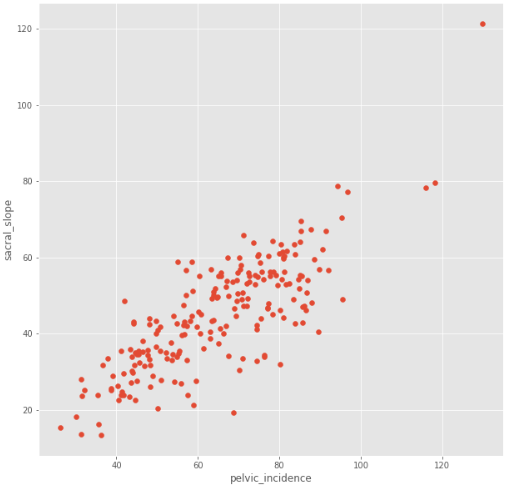
data = pd.read_csv('column_2C_weka.csv')
data1 = data[data['class'] =='Abnormal']
x = np.array(data1.loc[:,'pelvic_incidence']).reshape(-1,1)
y = np.array(data1.loc[:,'sacral_slope']).reshape(-1,1)
# Scatter
plt.figure(figsize=[10,10])
plt.scatter(x=x,y=y)
plt.xlabel('pelvic_incidence')
plt.ylabel('sacral_slope')
plt.show()
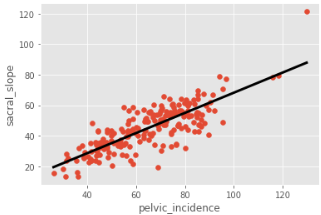
# LinearRegression线性回归
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
# Predict space 预测空间
predict_space = np.linspace(min(x), max(x)).reshape(-1,1)
# Fit 拟合训练
reg.fit(x,y)
# Predict 预测
predicted = reg.predict(predict_space)
# R^2
print('R^2 score: ',reg.score(x, y))
# Plot regression line and scatter 绘制回归线和散点图
plt.plot(predict_space, predicted, color='black', linewidth=3)
plt.scatter(x=x,y=y)
plt.xlabel('pelvic_incidence')
plt.ylabel('sacral_slope')
plt.show()
# 使用交叉验证
# CV
from sklearn.model_selection import cross_val_score
reg = LinearRegression()
k = 5
cv_result = cross_val_score(reg,x,y,cv=k) # uses R^2 as score
print('CV Scores: ',cv_result)
print('CV scores average: ',np.sum(cv_result)/k)

5、KNN统计维度
统计KNN模型分类结果,统计维度为TP、TN、FP、FN
TP(True Proper):被模型预测为好瓜的好瓜(是真正的好瓜,而且也被模型预测为好瓜)
TN(True False):被模型预测为坏瓜的坏瓜(是真正的坏瓜,而且也被模型预测为坏瓜)
FP:被模型预测为好瓜的坏瓜(瓜是真正的坏瓜,但是被模型预测为了好瓜)
FN:被模型预测为坏瓜的好瓜(瓜是真正的好瓜,但是被模型预测为了坏瓜)
- 准确率ACC:表示所有预测标签正确的数量占比(可以理解为KNN模型的检出率),计算公式为:ACC = (TP + TN)/(TP + TN + FP + FN)
- 精确率PRE:表示所有实际为真(恶意)的数量在预测为真(恶意)的占比(可以理解为KNN模型对检测的恶意样本的结果可信度),计算公式为:PRE = TP/(TP + FP)
- 召回率REC:表示所有预测为真(恶意)的数量在实际为真(恶意)的占比(可以理解为KNN模型对恶意样本的检出覆盖能力),计算公式为:REC = TP/(TP + FN)
6、距离度量选择
样本空间中两个点之间的距离度量表示的是两个样本点之间的相似程度:距离越小,表示相似程度越高;相反,距离越大,相似程度越低。
dataset = [[2.7810836,2.550537003,0],
[1.465489372,2.362125076,0],
[3.396561688,4.400293529,0],
[1.38807019,1.850220317,0],
[3.06407232,3.005305973,0],
[7.627531214,2.759262235,1],
[5.332441248,2.088626775,1],
[6.922596716,1.77106367,1],
[8.675418651,-0.242068655,1],
[7.673756466,3.508563011,1]]
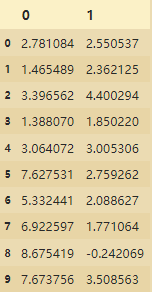
import pandas as pd
pd.DataFrame(dataset).iloc[:,0:-1]
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(1)
colors=np.random.rand(10)
x=pd.DataFrame(dataset).iloc[:,0]
y=pd.DataFrame(dataset).iloc[:,1]
area=(20*np.random.rand(10))**2 #圆圈的面积大小
plt.scatter(x,y,s=area,c=colors,alpha=0.8)
plt.show()
下面的球的面积大小是通过s=area进行控制的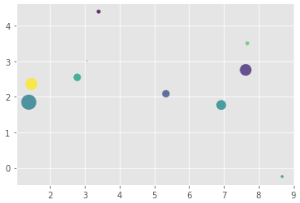
from math import sqrt
# 计算两个向量之间的欧式距离
def euclidean_distance(row1, row2):
distance = 0.0
for i in range(len(row1)-1):
distance += (row1[i] - row2[i])**2
return sqrt(distance)
# 测试欧式距离函数
dataset = [[2.7810836,2.550537003,0],
[1.465489372,2.362125076,0],
[3.396561688,4.400293529,0],
[1.38807019,1.850220317,0],
[3.06407232,3.005305973,0],
[7.627531214,2.759262235,1],
[5.332441248,2.088626775,1],
[6.922596716,1.77106367,1],
[8.675418651,-0.242068655,1],
[7.673756466,3.508563011,1]]
row0 = dataset[0]
for row in dataset:
distance = euclidean_distance(row0, row)
print(distance)
#结果得到第一个点与其他点的距离
这里计算的是dataset当中的每一个点与第一个点之间的距离的差值。这个过程使用的就是欧式距离。euclidean_distance——自定义函数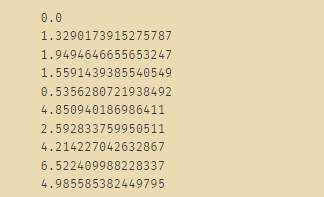
获取邻居(自定义函数):
def get_neighbors(train, test_row, num_neighbors):
distances = list()
for train_row in train:
dist = euclidean_distance(test_row, train_row)
distances.append((train_row, dist))
distances.sort(key=lambda tup: tup[1])
neighbors = list()
for i in range(num_neighbors):
neighbors.append(distances[i][0])
return neighbors
dataset = [[2.7810836,2.550537003,0],
[1.465489372,2.362125076,0],
[3.396561688,4.400293529,0],
[1.38807019,1.850220317,0],
[3.06407232,3.005305973,0],
[7.627531214,2.759262235,1],
[5.332441248,2.088626775,1],
[6.922596716,1.77106367,1],
[8.675418651,-0.242068655,1],
[7.673756466,3.508563011,1]]
neighbors=get_neighbors(dataset,dataset[3],3)
for neighbors in neighbors:
print(neighbors)
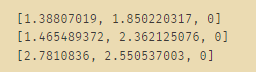
分类判断:
#分类判断
def predict_classification(train, test_row, num_neighbors):
neighbors = get_neighbors(train, test_row, num_neighbors)
output_values = [row[-1] for row in neighbors]
prediction = max(set(output_values), key=output_values.count)
return prediction
dataset = [[2.7810836,2.550537003,0],
[1.465489372,2.362125076,0],
[3.396561688,4.400293529,0],
[1.38807019,1.850220317,0],
[3.06407232,3.005305973,0],
[7.627531214,2.759262235,1],
[5.332441248,2.088626775,1],
[6.922596716,1.77106367,1],
[8.675418651,-0.242068655,1],
[7.673756466,3.508563011,1]]
prediction = predict_classification(dataset, dataset[1], 3)
print('Expected %d, Got %d.' % (dataset[0][-1], prediction))
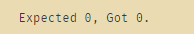

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)