
RNN之GRU
LSTM 具有更长的记忆能力, 在大部分序列任务上面都取得了比基础的 RNN 模型更好的性能表现,LSTM 不容易出现梯度弥散现象。 但是 LSTM 结构相对较复杂, 计算代价较高,模型参数量较大。一、GRU原理研究发现, 遗忘门是 LSTM 中最重要的门控, 甚至发现只有遗忘门的网络在多个基准数据集上面优于标准 LSTM 网络。 在简化版 LSTM中,门控循环网络(Gated Recurrent
LSTM 具有更长的记忆能力, 在大部分序列任务上面都取得了比基础的 RNN 模型更好的性能表现,LSTM 不容易出现梯度弥散现象。 但是 LSTM 结构相对较复杂, 计算代价较高,模型参数量较大。
一、GRU原理
研究发现, 遗忘门是 LSTM 中最重要的门控, 甚至发现只有遗忘门的网络在多个基准数据集上面优于标准 LSTM 网络。 在简化版 LSTM中,门控循环网络(Gated Recurrent Unit,简称 GRU)是应用最广泛的 RNN 变种之一。 GRU把内部状态向量和输出向量合并,统一为状态向量 , 门控数量也减少到 2 个:复位门(Reset Gate)和更新门(Update Gate)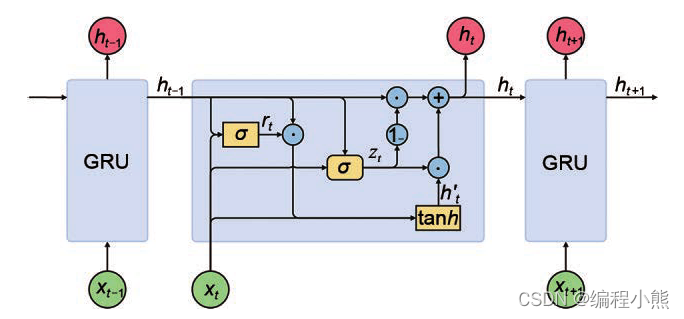
1.复位门
复位门用于控制上一个时间戳的状态进入GRU的量。
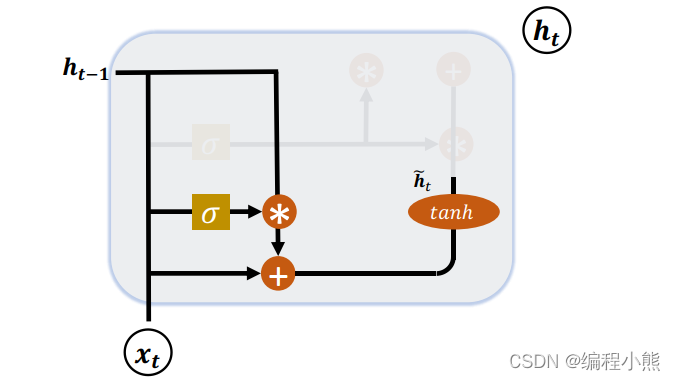
门控向量由当前时间戳输入
和上一个时间戳状态
变化得到的,关系:
。门控向量
只控制状态
,而不会控制输入
:
。当
= 0时, 新输入
全部来自于输入
, 不接受
,此时相当于复位
。当
= 1时,
和输入
共同产生新输
2.更新门
更新门用控制上一时间戳状态 和新输
对新状态向量
的影响程度。 更新门控向量
由
得到。
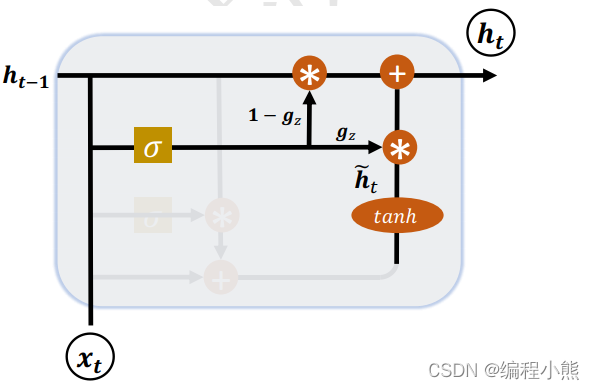
用于控制新输入
信号,
用于控制上一时间状态
信号:
和
对
的更新量处于相互竞争、此消彼长的状态。 当更新门
= 0时,
全部来自上一时间戳状态
; 当更新门
= 1时,
全部来自新输
二、GRU实现
1.GRUCell
GRUCell和SimpleRNNCell、LSTMCell使用一样,创建 GRU Cell 对象,并在时间轴上循环展开运算。它需要维护的初始化状态向量只有一个(单层)
x = tf.random.normal([2, 80, 100])
# 初始化状态向量, GRU 只有一个
h = [tf.zeros([2, 64])]
cell = layers.GRUCell(64) # 新建 GRU Cell,向量长度为 64
# 在时间戳维度上解开,循环通过 cell
for xt in tf.unstack(x, axis=1):
out, h = cell(xt, h)2.GRU
通过 layers.GRU 类可以方便通过 Sequential 容器可以堆叠多层 GRU 层的网络,并且不行维护初始化状态向量
net = keras.Sequential([
layers.GRU(64, return_sequences=True),
layers.GRU(64)
])
out = net(x)

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)