
Sora爆火,多模态大模型背后的存算思考
近日,随着OpenAI推出Sora,人工智能从文本到文本、文本到图片的生成模式,进阶到文生视频。其文本到视频的模型能够生成长达一分钟的视频,在保持视觉质量的同时并严格遵循用户的提示,使得“扔进一本小说,生成一部电影”的想法成为现实。OpenAI将这一创新描述为构建“物理世界的通用模拟器”,这不仅是一项技术突破,也是人工智能领域探索的又一里程碑。本文主要内容如下:(1)Sora展示(2)多模态数据存
近日,随着OpenAI推出Sora,人工智能从文本到文本、文本到图片的生成模式,进阶到文生视频。其文本到视频的模型能够生成长达一分钟的视频,在保持视觉质量的同时并严格遵循用户的提示,使得“扔进一本小说,生成一部电影”的想法成为现实。OpenAI将这一创新描述为构建“物理世界的通用模拟器”,这不仅是一项技术突破,也是人工智能领域探索的又一里程碑。
本文主要内容如下:
(1)Sora展示
(2)多模态数据存储
(3)多模态下的算力
(4)存储一体的趋势
1、Sora展示
本页所有视频均由Sora直接生成,未经修改
1、提示词:两艘海盗船在一杯咖啡中航行时相互争斗的逼真特写视频。
2 提示词:一窝金毛猎犬小狗在雪地里玩耍。他们的头从雪中探出头来,身上覆盖着雪。
3 提示词:一个时髦的女人走在东京的街道上,到处都是温暖的霓虹灯和生动的城市标志。她穿着黑色皮夹克、红色长裙、黑色靴子,拿着一个黑色钱包。她戴着太阳镜,涂着红色的口红。她走起路来自信而随意。街道是潮湿和反光的,创造了一个彩色灯光的镜子效果。许多行人走来走去。
4、提示词:几只巨大的长毛猛犸象穿过一片白雪覆盖的草地,它们长长的毛茸茸的皮毛在风中轻拂,远处白雪覆盖的树木和戏剧性的雪山,午后的光线与缕缕的云和远处的太阳创造了温暖的光芒,低相机的视角是惊人的,捕捉到了美丽的摄影,景深的大型毛茸茸的哺乳动物。
5、提示词:这是一部电影预告片,讲述了30岁的太空人戴着红色羊毛针织摩托车头盔的冒险经历,蓝天,盐沙漠,电影风格,用35毫米胶片拍摄,色彩鲜艳。
官网链接:https://openai.com/sora





为了展示自身实力,OpenAI还在官网上直接放出了48个Sora生成且未经修改的视频。这些视频时长不等,8-60秒,画面质量符合提示词,效果炸裂。感兴趣的朋友可以去官网查看。
2、多模态数据存储
以Sora的数据采集阶段为例,训练文本到视频的生成系统需要大量带有对应文字说明的视频。Sora的技术报告中提到,他们采用了在DALL-E 3中引入的重新标注技术应用于对视频语言的理解,仅在数据标注阶段就需要采用约10亿级数据量来对单一模型进行多达50万余次的训练,在此过程中产生的图文对数据量轻松达到PB级。面对复杂的多模态数据存储与管理挑战,单一协议的存储解决方案显然已无法满足现阶段的需求。因此,能够高效处理AIGC数据采集阶段的结构化与非结构化数据的存储解决方案,是当前存储厂商共同寻求的解决之道。
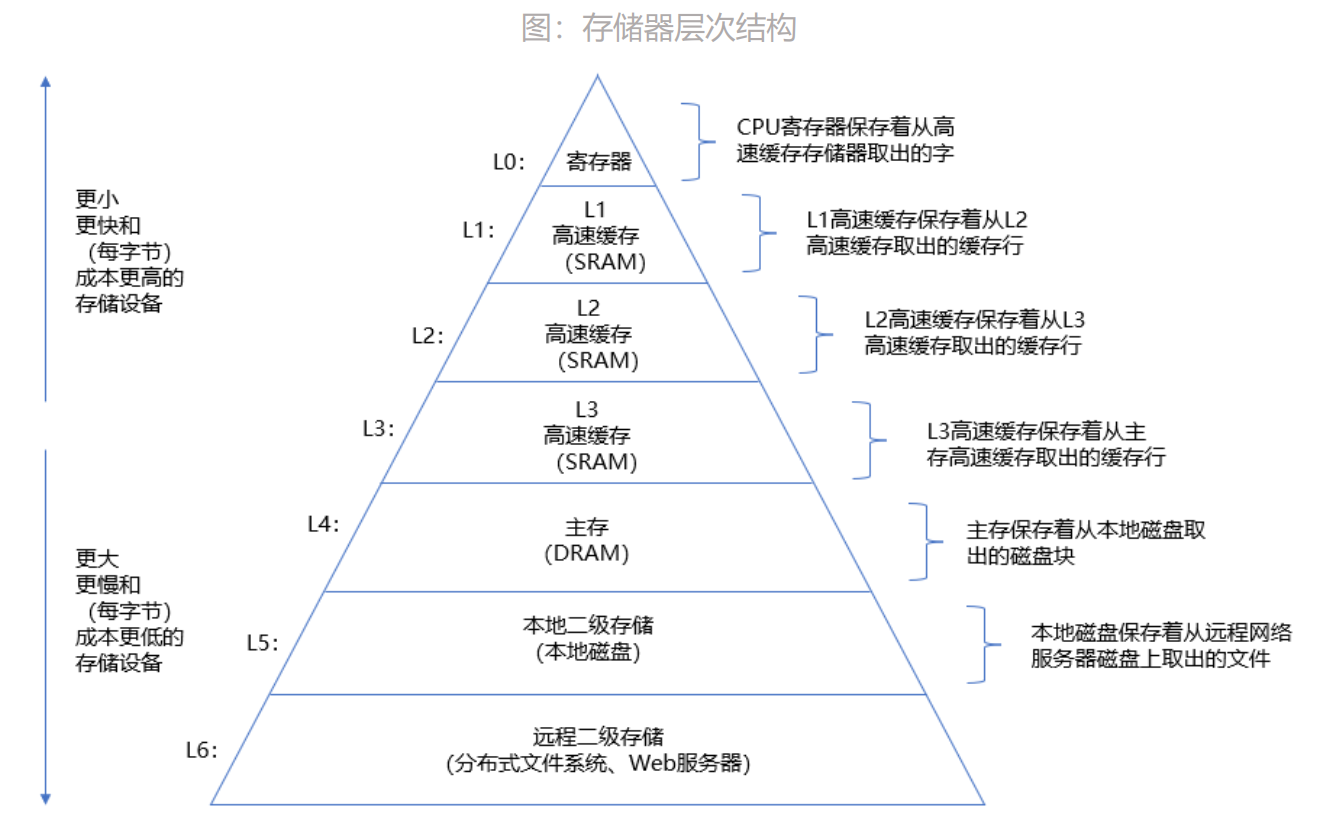
2.1 多层次存储
DRAM和Flash分属不同的存储器层次, 经常在下游应用中搭配使用。 处理器从内存中读取数据, 而内存从闪存中加载数据。 DRAM属于易失性存储器, 使用电容存储, 必须隔一段时间刷新, 一旦停止刷新存储的信息就会丢失。 而Flash属于非易失性的存储, 在断电后不会丢失数据, 是在ROM的基础上演进而来。 DRAM读写速度比Flash快、 成本高、 功耗较大、 寿命长、 结构简单集成度高, Flash的优势在于容量大、 成本低。
2.2 分布式融合存储方案
在数据类型不一致、数据量巨大的情况下,为了保证多模态大模型更高效地训练,一套能够提供多种服务与协议的存储集群是极佳的选择。分布式融合存储设计恰好解决了生成式AI数据采集阶段的这一问题,即一个存储池内支持文本、图片、音频、视频等多类型数据存储,一套存储实现多模态场景应用;应用间无需数据迁移,实现真正的数据实时共享,空间节省75%以上,且集群支持最多扩展至10240个节点。融合存储设计解决了大语言模型在数据采集阶段数据维度多、小文件数量多的问题,实现了对多元数据的高效存储和科学管理。

摘自: “浪潮存储”公众号
2.3 高带宽内存HBM
目前,HBM产品以HBM(第一代)、HBM2(第二代)、HBM2E(第三代)、HBM3(第四代)、HBM3E(第五代)的顺序开发,最新的HBM3E是HBM3的扩展版本。
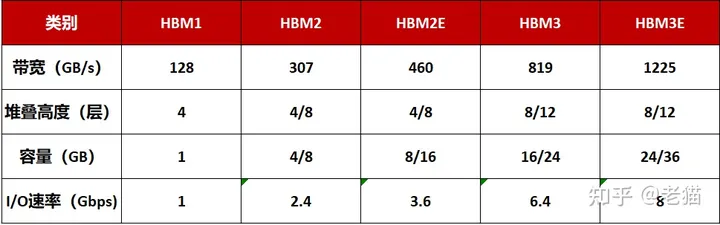
HBM每一次更新迭代都会伴随着处理速度的提高。引脚(Pin)数据传输速率为1Gbps的第一代HBM,发展到其第五产品HBM3E,速率则提高到了8Gbps,即每秒可以处理1.225TB的数据。也就是说,下载一部长达163分钟的全高清(Full-HD)电影(1TB)只需不到1秒钟的时间。
当然,存储器的容量也在不断加大:HBM2E的最大容量为16GB,目前,三星正在利用其第四代基于EUV光刻机的10nm制程(14nm)节点来制造24GB容量的HBM3芯片,此外8层、12层堆叠可在HBM3E上实现36GB(业界最大)的容量,比HBM3高出50%。
随着AI大模型、智能驾驶等新技术的崛起,人们对高带宽的内存的需求越来越多。
首先,AI服务器的需求会在近两年爆增,如今在市场上已经出现了快速的增长。AI服务器可以在短时间内处理大量数据,GPU可以让数据处理量和传输速率的大幅提升,让AI服务器对带宽提出了更高的要求,而HBM基本是AI服务器的标配。
3、多模态下的算力
根据财联社和OpenAI数据, ChatGPT浪潮下算力缺口巨大,根据OpenAI数据,模型计算量增长速度远超人工智能硬件算力增长速度, 存在万倍差距。尤其是多模态大模型的运算规模的增长,带动了对AI训练芯片单点算力提升的需求, 并对数据传输速度提出了更高的要求。根据智东西数据,过去五年,大模型发展呈现指数级别,部分大模型已达万亿级别, 因此对算力需求也随之攀升。
对于多模态大模型来说,算力的重要性主要体现在以下几个方面:
-
训练速度:多模态大模型的训练通常需要大量的数据和计算资源。拥有更强的算力可以加快模型的训练速度,从而更快地得到满意的模型效果。
-
模型规模:随着模型规模的增大,其能够捕捉和表示的信息也越多,但同时所需的算力也呈指数级增长。因此,强大的算力是支撑更大规模模型训练和推理的关键。
-
复杂任务的处理:多模态大模型通常用于处理复杂的任务,如跨模态检索、视觉问答等。这些任务需要模型具备强大的特征提取和融合能力,而这离不开算力的支持。
-
实时性和效率:对于某些需要实时响应的应用场景,如自动驾驶、智能客服等,算力决定了模型能否在有限的时间内完成推理并给出结果。
为了提升多模态大模型的算力,通常会采用以下方法:
-
使用高性能硬件:如GPU、TPU等专用加速器,这些硬件可以并行处理大量的计算任务,从而大幅提升算力。
-
分布式训练:通过将模型和数据分布到多个计算节点上进行训练,可以显著加快训练速度并减少单个节点的计算压力。
-
优化算法和模型结构:通过改进训练算法和模型结构,可以在不增加硬件投入的情况下提升算力利用率和模型性能。
同时,数据质量、模型设计、任务复杂性等因素同样会影响模型的最终性能。因此,在实际应用中需要综合考虑各种因素来优化模型的训练和推理过程。
4、存储一体的趋势
算力发展速度远超存储,存储带宽限制计算系统的速度,在过去二十年,处理器性能以每年大约55%的速度提升,内存性能的提升速度每年只有10%左右。因此,目前的存储速度严重滞后于处理器的计算速度。能耗方面, 从处理单元外的存储器提取所需的时间往往是运算时间的成百上千,因此能效非常低;“存储墙”成为加速学习时代下的一代挑战,原因是数据在计算单元和存储单元的频繁移动。
存储墙、带宽墙和功耗墙成为首要限制关键,在传统计算机架构中,存储与计算分离,存储单元服务于计算单元,因此会考虑两者优先级;如今由于海量数据和AI加速时代来临,不得不考虑以最佳的配合方式为数据采集、传输、处理服务,然而存储墙、 带宽墙和功耗墙成为首要挑战,虽然多核并行加速技术也能提升算力,但在后摩尔时代,存储带宽制约了计算系统的有效带宽,芯片算力增长步履维艰。
存算一体(Computing in Memory) 是在存储器中嵌入计算能力, 以新的运算架构进行二维和三维矩阵乘法/加法运算。 存算一体技术直接利用存储器进行数据处理或计算, 从而把数据存储与计算融合在同一个芯片的同一片区之中, 可以彻底消除冯诺依曼计算架构瓶颈。 存算一体的优势是打破存储墙,消除不必要的数据搬移延迟和功耗, 并使用存储单元提升算力, 成百上千倍的提高计算效率, 降低成本。
存算一体有Flash、 SRAM、 DRAM等成熟存储介质, 同时ReRAM、 MRAM等新型存储介质也在快速发展。 根据存储介质的不同, 存内计算芯片可分为基于传统存储器和基于新型非易失性存储器两种。 传统存储器包括SRAM, DRAM和Flash等;新型非易失性存储器包括ReRAM, PCM, FeFET, MRAM等。 其中, 距离产业化较近的是基于NOR Flash和基于SRAM的存内计算芯片。
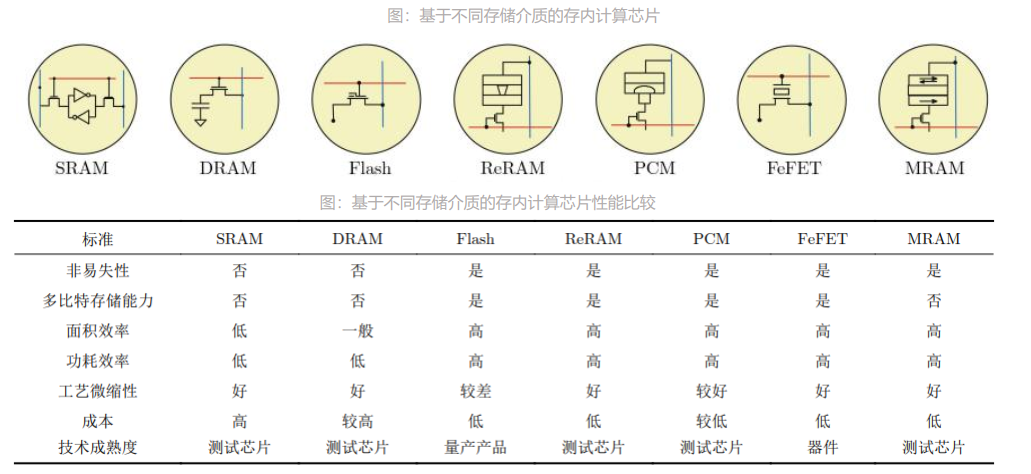
存算一体需求旺盛,有望推动下一阶段的人工智能发展,原因是我们认为现在存算一体主要AI的算力需求、并行计算、神经网络计算等; 大模型兴起,存算一体适用于从云至端各类计算, 端测方面, 人工智能更在意及时响应,即“输入”即“输出”,目前存算一体已经可以完成高精度计算; 云端方面,随着大模型的横空出世,参数方面已经达到上亿级别,存算一体有望成为新一代算力因素; 存算一体适用于人工智能各个场景,如穿戴设备、移动终端、智能驾驶、数据中心等。 我们认为存算一体为下一代技术趋势并有望广泛应用于人工智能神经网络相关应用、感存算一体,多模态的人工智能计算、类脑计算等场景。
参考资料
1. 电子与信息学报《存内计算芯片研究进展及应用》
2. 一文读懂:GPU最强"辅助"HBM到底是什么? - 知乎
3.中航证券《存储专题系列一:新应用发轫,存力升级大势所趋》
4.华金证券《“走进芯时代:HBM迭代,3D混合键合成设备材料发力点”》
5. "浪潮存储"公众号Sora爆火,多模态大模型背后的存储思考
6. 华西证券《ChatGPT:存算一体,算力的下一极》
CSDN首个存内计算开发者社区来了,基于各界产学研存内技术研究,涵盖最丰富的存内计算内容,以存内技术为核心,史无前例的技术开源内容,囊括云/边/端侧商业化应用解析以及AI时代新技术趋势洞察等, 邀请业内大咖定期举办存内workshop,实战演练体验前沿架构;从理论到实践,做为最佳窗口,存内计算让你触手可及。
传送门:https://bbs.csdn.net/forums/computinginmemory?category=10003;
首个存内计算开发者社区,现0门槛新人加入,发文享积分兑超值礼品;
存内计算先锋/大使在社区投稿,可获得双倍积分,以及社区精选流量推送;


GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)