
SparrowRecSys电影推荐系统项目(二)特征工程
SparrowRecSys电影推荐系统项目(二)特征工程前言一、特征工程是什么?二、推荐系统常用特征1.用户行为数据2.用户关系数据3.属性、标签类数据4.内容类数据5.场景信息(上下文信息)总结前言推荐系统中用户信息、物品信息、场景信息非常庞杂,如何在冗余的数据中提取到对最终的推荐效果起到决定作用的信息是算法工程师需要去考虑的,这也就是特征工程的魅力。一、特征工程是什么?特征定义:特征是对某个行
SparrowRecSys电影推荐系统项目(二)特征工程
前言
推荐系统中用户信息、物品信息、场景信息非常庞杂,如何在冗余的数据中提取到对最终的推荐效果起到决定作用的信息是算法工程师需要去考虑的,这也就是特征工程的魅力。
一、特征工程是什么?
特征定义:特征是对某个行为过程相关信息的抽象表达。信息必须得表达为数学形式才可以输入到机器学习模型中。
电影推荐系统常见的影响因素转化为特征: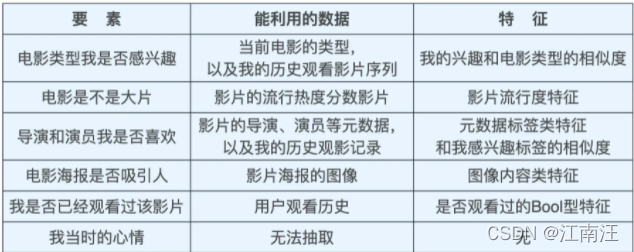
二、推荐系统常用特征
常见的推荐场景:电商推荐、视频推荐、新闻推荐、音乐推荐
1.用户行为数据
用户的潜在兴趣、用户对物品的真实评价都包含在用户的行为历史中。
用户行为包括:显性反馈行为、隐性反馈行为。
显性反馈行为意味着用户主动有意识的给与商品或视频进行评价。显性反馈行为收集难度大,大多数用户都不会主动给与评价。
隐形反馈行为意味着用户可能对商品感兴趣。
2.用户关系数据
用户行为数据是人与物之间的“连接”日志,用户关系数据是人与人之间连接的记录。
用户A、用户B为宿舍舍友,用户A喜欢看宠物视频,用户B由于和用户A在同一个社交网络中,因此用户B也会被推荐少量宠物视频。
3.属性、标签类数据
属性、标签类数据比较直接,比较显式,可以直接利用,本质上都是直接描述用户、物品信息的特征。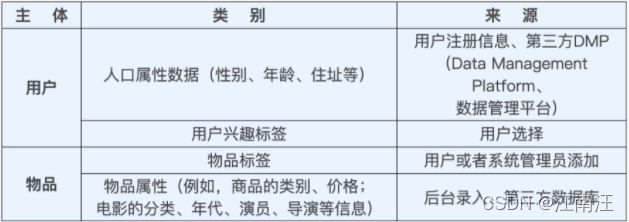
在注册app时app会让用户输入自己的一些信息,比如性别、年龄、兴趣标签。从已知的信息推荐给用户是大多数社交app都会采取的措施。
注:推荐系统中的属性、标签类数据,一般通过Multi-Hot编码方式将其转换成特征向量。
4.内容类数据
内容类数据可以看做是属性标签类型特征的延伸,内容型数据往往是一大段文字、图片、视频。这些内容型数据要通过自然语言处理、计算机视觉等技术提取关键内容特征,再输入推荐系统。
5.场景信息(上下文信息)
场景信息描述推荐行为产生场景的信息。最常用的上下文信息是“时间”和通过GPS、IP地址获得的“地点”信息。根据推荐场景的不同,还包括“当前所处推荐页面”、“季节”、“月份”、“是否节假日”、“天气”等。在场景信息中更多利用时间、地点、推荐页面等这些易获取的特征。
三、特征工程
原始的特征无法直接提供给推荐模型使用,推荐模型本质上是一个函数,输入为数字型的向量。同时工业界的数据量级别非常大,需要使用大数据平台Spark或者Flink进行实时处理。
项目实战:利用spark做特征工程
1.使用One-Hot向量编码处理特征
两类特征**:类别型特征、数值型特征**
对于电影推荐系统,类别特征有电影风格(恐怖、喜剧、文艺等风格),ID、标签、用户观看过电影ID、用户性别等。
数值型特征有用户的年龄、收入、电影播放时长、点击量、点击率等。
Raw sample:movieId、title、genres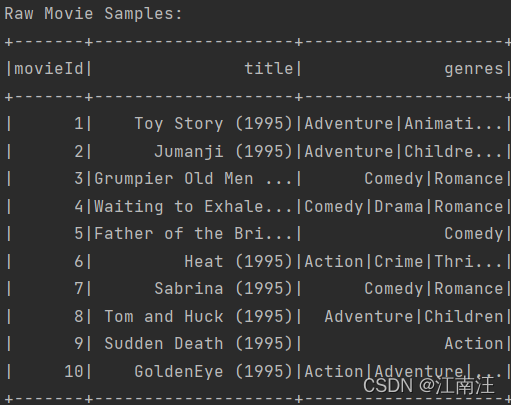
movieId生成One-Hot向量:
def oneHotEncoderExample(movieSamples):
#新增moveIdNumber列,withColumn函数添加了movIdNumber列
samplesWithIdNumber = movieSamples.withColumn("movieIdNumber", F.col("movieId").cast(IntegerType()))
#定义一个encoder,将数值转化为one-hot向量
encoder = OneHotEncoder(inputCol="movieIdNumber", outputCol='movieIdVector', dropLast=False)
#将sample作为encoder输入,将movieIdNumber转化为movieIdVector
oneHotEncoderSamples = encoder.transform(samplesWithIdNumber)
#打印最终样本数据结构
oneHotEncoderSamples.printSchema()
#打印前10条样本查看结果
oneHotEncoderSamples.show(10)
前10条oneHotEncoderSamples: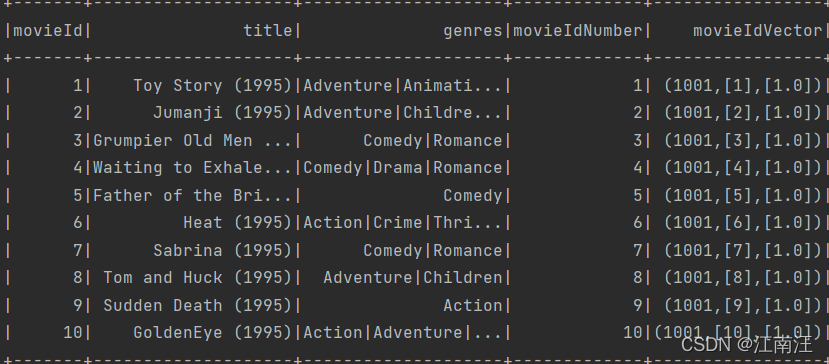
movieIdVector:稀疏向量表示vector,(1001,[1],[1.0])代表1001维,索引[1],值[1.0]]
稀疏向量是什么?
2.使用Multi-Hot向量编码处理特征
Multi-Hot编码将多个特征属性编码到一个特征中。
栗子:
某用户是否对产品1、产品2、产品3感兴趣,感兴趣为1,不感兴趣为0。
用户A对产品1和产品3感兴趣,用户B只对产品2感兴趣,则用户A和用户B的Multi-Hot向量为:
#用户A
[1,0,1]
#用户B
[0,1,0]
电影推荐系统中电影风格多种,电影可能会有多个电影风格标签,需要将电影对应多种风格编码到一个向量内。
比如movieId=7的电影所属电影风格为:Comedy、Romance.怎么把电影对应的不同电影风格编码到特征向量内呢?
genres生成Multii-Hot特征向量
def array2vec(genreIndexes, indexSize):
#对电影风格索引进行排序
genreIndexes.sort()
#fill_list=[1.0,1.0,1.0,...]
fill_list = [1.0 for _ in range(len(genreIndexes))]
#example:[19,(1,3,4,6),[1.0,1.0,1.0,1.0]]
return Vectors.sparse(indexSize, genreIndexes, fill_list)
def multiHotEncoderExample(movieSamples):
#raw example中dataframe中genres数据有分隔符|
samplesWithGenre = movieSamples.select("movieId", "title", explode(
split(F.col("genres"), "\\|").cast(ArrayType(StringType()))).alias('genre'))
#genre->genreIndex,生成数字索引
genreIndexer = StringIndexer(inputCol="genre", outputCol="genreIndex")
StringIndexerModel = genreIndexer.fit(samplesWithGenre)
genreIndexSamples = StringIndexerModel.transform(samplesWithGenre).withColumn("genreIndexInt",
F.col("genreIndex").cast(IntegerType()))
indexSize = genreIndexSamples.agg(max(F.col("genreIndexInt"))).head()[0] + 1
processedSamples = genreIndexSamples.groupBy('movieId').agg(
F.collect_list('genreIndexInt').alias('genreIndexes')).withColumn("indexSize", F.lit(indexSize))
finalSample = processedSamples.withColumn("vector",
udf(array2vec, VectorUDT())(F.col("genreIndexes"), F.col("indexSize")))
finalSample.printSchema()
finalSample.show(10)
函数 groupby、withColumn、fit、transform、agg、
前10条finalSample: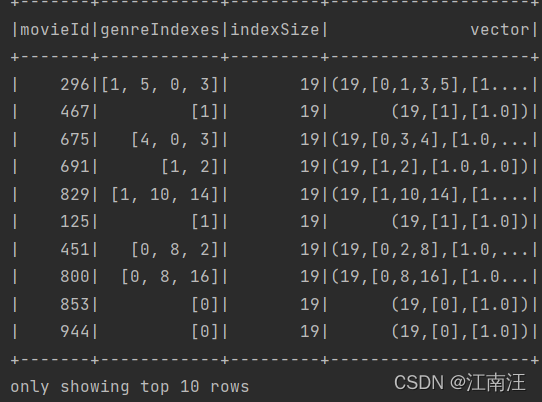
vector是用稀疏向量表示,(19,[1,2],[1.0,1.0])为19维,向量索引1和2的位置值为1,其余索引的值均为0.
3.使用分桶和归一化处理数值特征
数值特征往往特征大小分布不同,比如特征1的取值范围在0-10000,特征2的取值范围在0-5,将特征1和特征2送入模型中学习效果较差。因此需要将连续型数值进行归一化、离散型数值进行分桶。
Spark中归一化有以下几种:Normalizer、StandardScaler、RobustScaler、MinMaxScaler.
Normalizer:按行处理,即对每个样本进行正则化,Nomalization采用p范数,大多数采用L2范数。
StandardScaler:按列处理,即对特征列进行处理,数据标准化:(xi-u)/v(u为均值,v为方差),经过处理数据会服从均值为0,方差为1的正态分布即标准正态分布。
RobustScaler:按列处理,(xi-median)/IQR【median为样本中位数,IQR是样本的四分位距,根据第1个四分位数和第3个四分位数之间的范围来缩放数据】
MinMaxScaler:按列处理,(xi-min)/(max-min),数值会收敛到[0,1]之间,数据xi按照最小值中心化后,再按照极差(最大值-最小值)缩放。
分桶:离散型数值分布太过分散,难以捕捉特征的内在分布,将原始数值分到不同数值分布的桶。
对于电影推荐系统连续型数值为平均评分avgrating,离散型数值为电影评分次数ratingcount.分桶方法采用QuantileDiscretizer,分成100个桶。
def ratingFeatures(ratingSamples):
ratingSamples.printSchema()
ratingSamples.show()
# calculate average movie rating score and rating count
movieFeatures = ratingSamples.groupBy('movieId').agg(F.count(F.lit(1)).alias('ratingCount'),
F.avg("rating").alias("avgRating"),
F.variance('rating').alias('ratingVar')) \
.withColumn('avgRatingVec', udf(lambda x: Vectors.dense(x), VectorUDT())('avgRating'))
movieFeatures.show(10)
# bucketing
ratingCountDiscretizer = QuantileDiscretizer(numBuckets=100, inputCol="ratingCount", outputCol="ratingCountBucket")
# Normalization
ratingScaler = MinMaxScaler(inputCol="avgRatingVec", outputCol="scaleAvgRating")
pipelineStage = [ratingCountDiscretizer, ratingScaler]
featurePipeline = Pipeline(stages=pipelineStage)
movieProcessedFeatures = featurePipeline.fit(movieFeatures).transform(movieFeatures)
movieProcessedFeatures.show(10)
moviefeatures: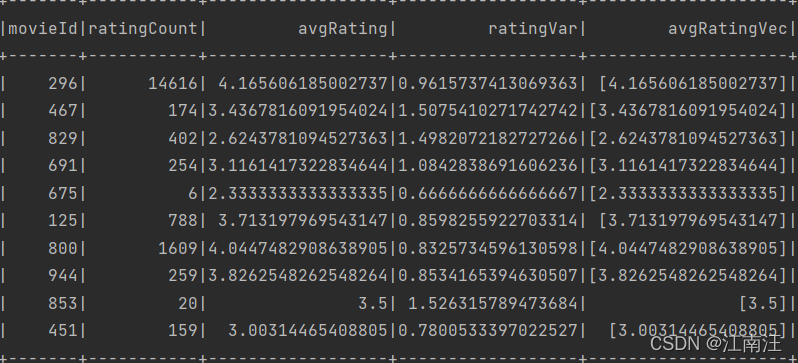
movieProcessedFeatures: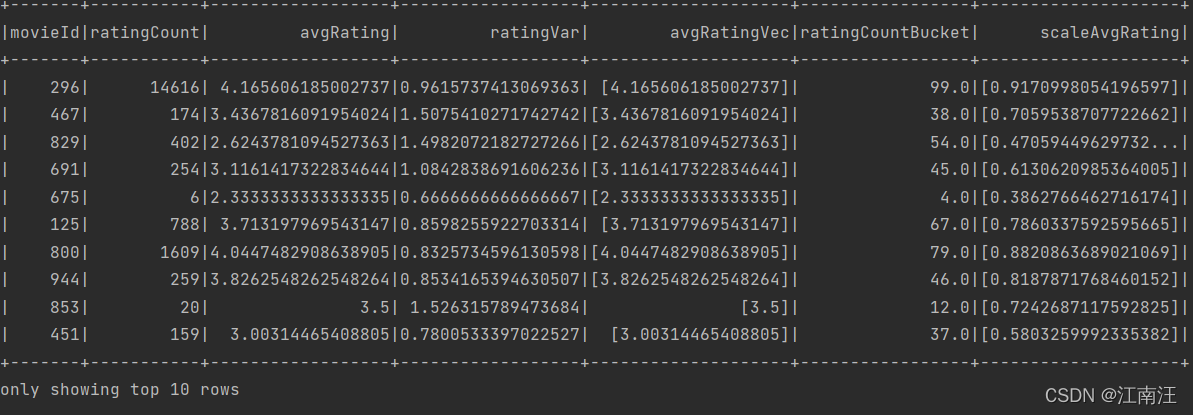
avgRating->avgRatingVec->scaleAvgRating,先将电影平均评分生成向量再经过MinMaxScaler归一化得到scaleAvgRating。
4.Embedding
Embedding定义:Embedding就是一个数值向量表示一个对象的方法。
Embedding为什么是处理稀疏特征好的利器?
首先深度学习结构特点不利于稀疏特征向量的处理,Embedding方法可以将稀疏向量转化为稠密向量。
Embedding不仅是一种处理稀疏特征的方法,也是融合大量基本特征,生成高阶特征向量的有效手段。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)