
Python实时数据处理栈:PySpark + Kafka流处理引擎构建
随着Flink等新一代引擎崛起,PySpark+Kafka架构持续进化。2023年Databricks推出,实现流批一体新范式。但核心原则不变:“实时数据系统的价值不在于速度本身,而在于决策链路的闭环效率”无论架构如何演进,掌握分布式系统核心原理、理解数据流动的本质,才是工程师应对技术洪流的终极铠甲。终极挑战:设计支持动态规则更新的实时风控系统架构参考答案规则存储在Redis/配置中心Spark
引言:数据洪流时代的生存法则
当每秒百万级的交易数据席卷而来,当用户行为轨迹以毫秒级刷新,传统批处理架构在实时性悬崖边摇摇欲坠。某电商巨头曾因延迟10分钟的风险拦截,单日损失超$2M——实时数据流处理已成为数字企业的生死线。
本文将深入解剖基于Python的实时处理黄金组合:Kafka(分布式消息队列) 与 PySpark(分布式计算引擎) 的化学反应。通过工业级代码示例与底层原理解析,构建坚如磐石的处理流水线。
验证题目:请说明传统批处理架构在实时场景中的三大缺陷
答案:1. 高延迟(分钟级至小时级)2. 资源利用率波动大 3. 无法响应动态事件
实时数据处理的核心价值:
- 快速响应:实时处理用户行为数据,快速做出决策。
- 提升用户体验:根据用户的实时行为,提供个性化服务。
- 优化业务流程:通过实时数据分析,优化业务流程和资源配置。
第一章 Kafka:数据世界的中央神经系统
1.1 消息引擎核心设计哲学
Kafka采用发布-订阅模式解耦生产消费,其分布式提交日志架构使数据持久化能力突破传统MQ瓶颈。核心组件:
-
Producer:数据发射器(如用户行为采集SDK)
-
Consumer:数据处理器(如Spark消费集群)
-
Broker:消息存储节点集群
-
Topic:逻辑数据通道(如order_events)
# 导入Kafka生产者模块 from confluent_kafka import Producer # 导入JSON处理模块(原代码缺失此导入) import json # 配置Kafka集群连接参数(多个broker用逗号分隔) conf = {'bootstrap.servers': 'kafka1:9092,kafka2:9092'} # 创建Kafka生产者实例 producer = Producer(conf) # 定义消息投递结果回调函数 def delivery_report(err, msg): """处理消息发送后的回调结果""" # 如果发送失败则打印错误 if err is not None: print(f'Message delivery failed: {err}') # 发送成功时打印消息元数据 else: print(f'Message delivered to: ' f'topic={msg.topic()} ' f'partition={msg.partition()} ' f'offset={msg.offset()}') # 构造用户事件数据(Python字典格式) user_event = { 'user_id': 101, 'action': 'payment', 'amount': 299.9 } # 使用生产者发送消息到指定主题 producer.produce( topic='user_events', # 目标Kafka主题名称 key=str(user_event['user_id']), # 设置消息键(按用户ID分区) value=json.dumps(user_event), # 将字典转为JSON字符串 callback=delivery_report # 指定投递结果回调函数 ) # 可选:在发送后立即轮询事件队列(处理回调) # 确保在flush前处理已发送消息的回调 producer.poll(0) # 强制刷新生产者缓冲区,确保所有消息完成传输 # 会阻塞直到所有消息得到broker确认或超时 producer.flush() # 注意:实际生产环境通常不会每条消息都flush # 可考虑批量发送或定时刷新以提高吞吐量
1.2 高吞吐背后的工程魔法
Kafka实现百万级TPS的核心技术:
-
分区并行化:Topic拆分为多个Partition分散存储压力
-
零拷贝技术:通过sendfile系统调用绕过内核缓冲区
-
批量压缩:Snappy压缩算法降低网络IO达70%
-
ISR副本机制:In-Sync Replicas保障数据高可用
验证题目:若某Topic配置3分区2副本,集群最少需要几台Broker?
答案:2台(副本不能全部位于同一Broker)
第二章 PySpark:分布式计算的终极形态
PySpark的核心功能
PySpark是Spark的Python API,支持使用Python进行大规模数据处理。其核心功能包括:
- 弹性分布式数据集(RDD):分布式的数据集合,支持并行操作。
- DataFrame和Dataset:结构化的数据处理API,支持高效的数据操作。
- 流处理:通过Structured Streaming进行实时数据处理。
弹性分布式数据集(RDD)革命
Spark核心抽象RDD(Resilient Distributed Dataset) 具备:
-
不可变性:每次操作生成新RDD(函数式编程范式)
-
血缘关系:Lineage机制实现故障重算(非数据复制)
-
延迟计算:Action触发DAG执行计划优化
# 导入必要的PySpark模块
from pyspark import SparkConf, SparkContext
# 初始化Spark配置(实际应用中可配置集群参数)
conf = SparkConf().setAppName("WordCount") # 设置应用名称
sc = SparkContext(conf=conf) # 创建SparkContext实例
# 从HDFS分布式文件系统加载文本数据创建初始RDD
# 参数:HDFS文件路径(假设为访问日志)
text_rdd = sc.textFile("hdfs://logs/access.log") # 返回RDD[String]类型
# ===== 转换操作(Transformations)=====
# 惰性操作:仅定义计算逻辑,不立即执行
# 扁平化操作:将每行文本分割成单词
# flatMap: 每行输入 -> 多个输出元素(单词)
words_rdd = text_rdd.flatMap(lambda line: line.split(" "))
# 映射操作:将每个单词转换为(单词, 1)键值对
# map: 每个单词 -> (word, 1) 二元组
pairs_rdd = words_rdd.map(lambda word: (word, 1))
# 按键聚合:对相同单词的计数值进行累加
# reduceByKey: 对相同key的值执行聚合函数(这里是加法)
counts_rdd = pairs_rdd.reduceByKey(lambda a, b: a + b)
# ===== 行动操作(Action)=====
# 触发实际计算并返回结果到驱动程序
# 获取词频最高的10个单词(按词频降序)
# takeOrdered: 返回按指定键排序的前N个元素
# key=lambda x: -x[1]: 按计数值(元组第二项)降序排列
top10 = counts_rdd.takeOrdered(10, key=lambda x: -x[1])
# 打印结果到控制台
print("Top10高频词:", top10)
# 可选:关闭SparkContext释放资源
# 在长时间运行的Spark应用(如Spark Streaming)中可能不立即关闭
sc.stop()2.2 Structured Streaming:流处理的范式转移
相比传统微批次处理,Structured Streaming实现:
-
无限表模型:流数据视为持续增长的表
-
事件时间处理:基于watermark处理乱序事件
-
端到端Exactly-Once:通过检查点+幂等写入保障
# 导入必要的PySpark模块 from pyspark.sql import SparkSession from pyspark.sql.functions import col, from_json, window from pyspark.sql.types import StructType, StructField, StringType, IntegerType, TimestampType, DoubleType # 创建SparkSession实例(流处理程序的入口点) spark = SparkSession.builder \ .appName("KafkaPaymentMonitor") \ # 设置应用名称 .config("spark.sql.shuffle.partitions", "4") \ # 优化小规模数据处理 .getOrCreate() # 获取或创建会话实例 # 定义JSON事件的结构化模式 # 对应Kafka消息中的JSON格式:{'user_id':101, 'action':'payment', 'amount':299.9, 'timestamp':'2023-01-01T12:00:00Z'} event_schema = StructType([ StructField("user_id", IntegerType(), True), # 用户ID整型字段 StructField("action", StringType(), True), # 行为类型字符串字段 StructField("amount", DoubleType(), True), # 支付金额双精度字段 StructField("timestamp", TimestampType(), True) # 事件时间戳字段(关键用于窗口计算) ]) # ===== 定义Kafka流源 ===== # 创建流式DataFrame,从Kafka持续读取数据 df = spark.readStream \ # 创建流式读取器 .format("kafka") \ # 指定Kafka数据源格式 .option("kafka.bootstrap.servers", "kafka1:9092") \ # Kafka集群地址 .option("subscribe", "user_events") \ # 订阅的主题名称 .option("startingOffsets", "latest") \ # 从最新偏移量开始(可选:earliest) .option("failOnDataLoss", "false") \ # 容忍数据丢失(生产环境推荐) .load() # 加载流数据源 # ===== 数据处理管道 ===== # 步骤1:解析JSON并过滤支付事件 payments = df.select( # 解析value字段(二进制转为字符串,再按schema解析为结构化数据) from_json(col("value").cast("string"), event_schema).alias("data"), # 保留Kafka消息自带的时间戳(可选,通常使用事件时间) col("timestamp").alias("kafka_timestamp") ).filter("data.action = 'payment'") # 过滤出支付事件 # 步骤2:实时窗口聚合(每5分钟窗口按用户统计支付次数) windowed_count = payments.groupBy( # 基于事件时间创建5分钟滚动窗口 window(col("data.timestamp"), "5 minutes"), # 使用事件时间字段 col("data.user_id") # 按用户ID分组 ).count() # 计算每个(窗口,用户)组合的支付次数 # ===== 输出结果 ===== # 创建流式查询,将聚合结果输出到控制台 query = windowed_count.writeStream \ .outputMode("complete") \ # 完整输出模式(更新整个结果集) .format("console") \ # 输出到控制台(生产环境可用Kafka/文件系统) .option("truncate", "false") \ # 显示完整内容(不截断) .option("numRows", 20) \ # 每次触发显示20行 .trigger(processingTime="1 minute") \ # 每分钟触发一次计算 .start() # 启动流处理作业 # 等待查询终止(实际应用可添加优雅停止逻辑) query.awaitTermination()验证题目:列举Spark中三个Transformation操作和两个Action操作
答案:
Transformation: map, filter, reduceByKey
Action: collect, count
第三章 流处理引擎的深度集成
3.1 精准一次消费的工程实现
Kafka + Spark的Exactly-Once保障机制:
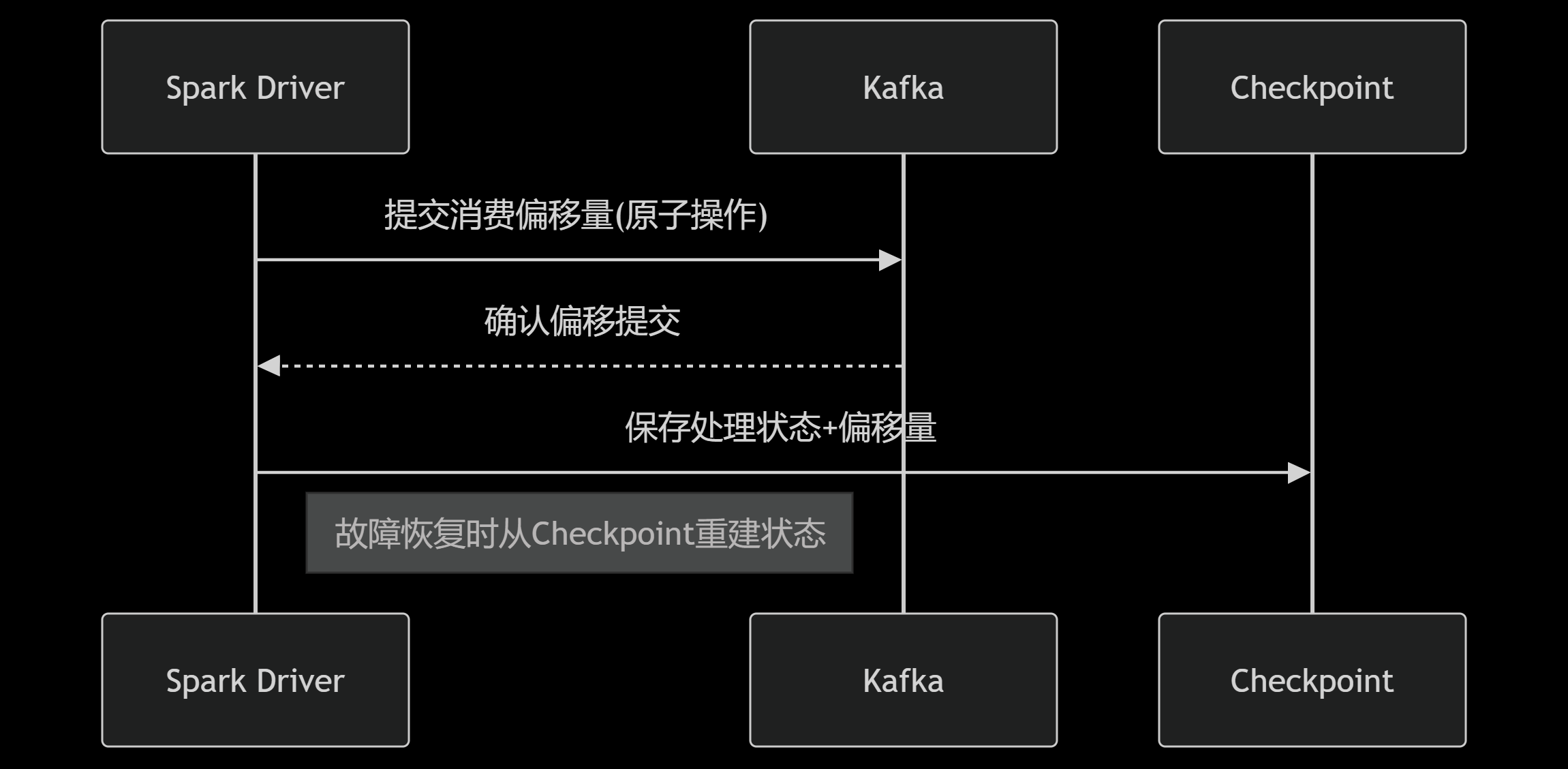
3.2 动态负载均衡策略
通过Kafka的消费者组协议实现:
-
分区再均衡(Rebalance)自动分配
-
消费者心跳检测(session.timeout.ms)
-
偏移量提交(enable.auto.commit=false)
# 导入必要的PySpark模块 from pyspark.sql import SparkSession from pyspark.sql.functions import col, from_json from pyspark.sql.types import StructType, StructField, StringType, DoubleType, TimestampType # 创建SparkSession实例(流处理程序的入口点) # 使用builder模式配置并创建Spark会话 spark = SparkSession.builder \ .appName("KafkaIoTStreamProcessor") \ # 设置应用名称 .config("spark.sql.shuffle.partitions", "8") \ # 设置shuffle分区数(根据集群规模调整) .config("spark.streaming.backpressure.enabled", "true") \ # 启用背压机制(动态调整接收速率) .getOrCreate() # 获取或创建会话实例 # 定义IoT设备遥测数据的结构化模式 # 假设JSON格式:{"device_id": "sensor-001", "temperature": 23.5, "humidity": 45.2, "timestamp": "2023-01-01T12:00:00Z"} iot_schema = StructType([ StructField("device_id", StringType(), True), # 设备ID字符串 StructField("temperature", DoubleType(), True), # 温度值(双精度浮点) StructField("humidity", DoubleType(), True), # 湿度值(双精度浮点) StructField("timestamp", TimestampType(), True) # 数据采集时间戳 ]) # ===== 创建Kafka流源 ===== # 定义从Kafka读取数据的结构化流 stream = spark.readStream \ # 创建流式读取器 .format("kafka") \ # 指定Kafka数据源格式 .option("kafka.bootstrap.servers", "kafka1:9092") \ # Kafka集群地址(逗号分隔多个broker) .option("subscribe", "iot_telemetry") \ # 订阅的主题名称(可逗号分隔多个主题) .option("group.id", "spark-streaming-group") \ # 消费者组ID(用于偏移量管理) .option("startingOffsets", "earliest") \ # 从最早偏移量开始(可选:latest, 或指定JSON偏移量) .option("failOnDataLoss", "false") \ # 容忍数据丢失(Kafka主题删除或偏移量超出范围时不失败) .option("maxOffsetsPerTrigger", 10000) \ # 每批处理的最大消息数(控制批处理大小) .option("kafka.security.protocol", "SASL_SSL") \ # 安全协议(生产环境需要) .option("kafka.sasl.mechanism", "PLAIN") \ # SASL机制(生产环境需要) .load() # 加载流数据源 # ===== 数据处理管道 ===== # 解析JSON数据并转换为结构化格式 parsed_data = stream.select( col("key").cast("string").alias("device_key"), # 可选:转换消息键 from_json(col("value").cast("string"), iot_schema).alias("data"), # 解析JSON值 col("topic").alias("kafka_topic"), # 原始Kafka主题 col("partition").alias("kafka_partition"), # Kafka分区 col("offset").alias("kafka_offset"), # 消息偏移量 col("timestamp").alias("kafka_timestamp") # Kafka消息时间戳 ).select("device_key", "data.*", "kafka_topic", "kafka_partition", "kafka_offset", "kafka_timestamp") # 展平嵌套结构 # 过滤异常值(示例:温度在合理范围内) filtered_data = parsed_data.filter( (col("temperature") >= -40) & (col("temperature") <= 100) & (col("humidity") >= 0) & (col("humidity") <= 100) ) # ===== 输出结果 ===== # 创建流式查询,将处理后的数据写入控制台(用于调试) # 生产环境通常会写入其他系统(如HDFS、Kafka、数据库等) query = filtered_data.writeStream \ .outputMode("append") \ # 追加模式(只输出新数据) .format("console") \ # 输出到控制台(开发/调试用) .option("truncate", "false") \ # 显示完整内容(不截断) .option("numRows", 100) \ # 每次触发显示100行 .trigger(processingTime="30 seconds") \ # 每30秒触发一次微批处理 .option("checkpointLocation", "/checkpoints/iot_stream") \ # 检查点目录(保证容错性) .start() # 启动流处理作业 # 等待流查询终止(通常持续运行直到手动停止) # 实际应用中可添加优雅停止逻辑(如响应终止信号) query.awaitTermination() # 可选:在程序退出时停止Spark会话 spark.stop()验证题目:如何避免Spark处理过程中Kafka消息重复消费?
答案:1. 手动管理偏移量 2. 启用Spark检查点 3. 下游写入幂等操作
第四章 实战:实时风控系统构建
4.1 架构拓扑
4.2 异常行为检测模型
# 导入必要的PySpark模块
from pyspark.sql import SparkSession
from pyspark.sql.functions import expr, window, count, col
from pyspark.sql.types import StructType, StructField, StringType, TimestampType, IntegerType
# 创建SparkSession实例(流处理程序的入口点)
spark = SparkSession.builder \
.appName("RealTimeRiskEngine") \ # 设置应用名称
.config("spark.sql.shuffle.partitions", "6") \ # 优化分区数
.getOrCreate() # 获取或创建会话实例
# 假设事件数据模式(实际应用中根据业务定义)
event_schema = StructType([
StructField("user_id", StringType(), True), # 用户ID
StructField("event_type", StringType(), True), # 事件类型(登录、支付等)
StructField("ip_address", StringType(), True), # IP地址
StructField("device_id", StringType(), True), # 设备ID
StructField("location_city", StringType(), True), # 城市位置
StructField("event_time", TimestampType(), True) # 事件时间戳
])
# ===== 创建事件流源 =====
# 假设从Kafka读取事件数据(实际源可能是Kafka、Kinesis等)
events_df = spark.readStream \
.format("kafka") \ # 数据源格式
.option("kafka.bootstrap.servers", "kafka-risk:9092") \ # Kafka集群
.option("subscribe", "user_events") \ # 订阅主题
.load() \
.select(
from_json(col("value").cast("string"), event_schema).alias("data") # 解析JSON
).select("data.*") # 展平结构
# 添加水印处理延迟数据(基于事件时间)
events_df = events_df.withWatermark("event_time", "10 minutes")
# ===== 特征工程 =====
# 计算设备变更次数(基于用户会话)
device_change_df = events_df.groupBy(
"user_id",
window("event_time", "1 hour") # 1小时滚动窗口
).agg(
count("device_id").alias("device_count"), # 设备使用次数
expr("count(distinct device_id)").alias("distinct_devices") # 不同设备数
).withColumn(
"device_change",
expr("CASE WHEN distinct_devices > 1 THEN 1 ELSE 0 END") # 设备变更标志
)
# 计算城市变更次数(类似设备变更)
city_change_df = events_df.groupBy(
"user_id",
window("event_time", "1 hour")
).agg(
expr("count(distinct location_city)").alias("distinct_cities")
).withColumn(
"city_change",
expr("CASE WHEN distinct_cities > 1 THEN 1 ELSE 0 END")
)
# 计算登录次数(1小时内)
login_count_df = events_df.filter("event_type = 'login'") \ # 仅登录事件
.groupBy(
"user_id",
window("event_time", "1 hour")
).agg(count("*").alias("login_count"))
# 合并特征数据集
feature_df = device_change_df.join(
city_change_df,
["user_id", "window"],
"left_outer" # 左外连接确保所有用户
).join(
login_count_df,
["user_id", "window"],
"left_outer"
).fillna(0) # 填充空值为0
# ===== 规则引擎 =====
# 定义风险规则集(业务逻辑)
# 格式:条件 -> 风险等级
risk_rules = [
"(device_change = 1 AND city_change = 1) -> 'HIGH_RISK'", # 规则1:设备+城市同时变更
"(login_count > 5) -> 'MEDIUM_RISK'", # 规则2:1小时内登录超过5次
# 默认规则(无匹配时)
"1 = 1 -> 'LOW_RISK'" # 默认低风险
]
# 构建CASE表达式
case_expr = "CASE "
for rule in risk_rules:
# 分割规则为条件和风险等级
condition, risk_level = rule.split("->")
# 添加到CASE表达式
case_expr += f"WHEN {condition.strip()} THEN '{risk_level.strip()}' "
case_expr += "END"
# 应用风险规则引擎
risk_df = feature_df.withColumn(
"risk_level", # 新增风险等级列
expr(case_expr) # 执行规则引擎
).select( # 选择关键字段
"user_id",
"window.start",
"window.end",
"device_change",
"city_change",
"login_count",
"risk_level"
)
# ===== 输出到风险数据库 =====
# 将风险评估结果写入Elasticsearch
risk_query = risk_df.writeStream \
.outputMode("update") \ # 更新模式(只输出变更记录)
.format("org.elasticsearch.spark.sql") \ # Elasticsearch连接器
.option("es.nodes", "es1:9200,es2:9200") \ # ES集群节点
.option("es.resource", "risk_events") \ # ES索引/类型(ES7+使用索引名)
.option("es.mapping.id", "user_id") \ # 文档ID字段(基于用户ID)
.option("es.write.operation", "upsert") \ # 更新插入模式
.option("checkpointLocation", "/checkpoints/risk_engine") \ # 检查点目录(容错)
.trigger(processingTime="1 minute") \ # 每分钟触发
.start() # 启动流处理
# 同时输出到控制台用于调试
console_query = risk_df.writeStream \
.outputMode("update") \
.format("console") \
.option("truncate", "false") \
.start()
# 等待流处理终止
spark.streams.awaitAnyTermination()
# 生产环境应添加优雅停止逻辑验证题目:设计一个检测同IP高频注册的Spark流处理逻辑
答案:
# 导入必要的PySpark模块
from pyspark.sql import SparkSession
from pyspark.sql.functions import window, count, col
from pyspark.sql.types import StructType, StructField, StringType, TimestampType
# 初始化Spark会话(配置反压和检查点)
spark = SparkSession.builder \
.appName("IPRegistrationFraudDetection") \
.config("spark.sql.shuffle.partitions", "8") \ # 根据集群规模调整
.config("spark.streaming.backpressure.enabled", "true") \ # 启用反压
.config("spark.streaming.kafka.maxRatePerPartition", "1000") \ # 每分区最大速率
.getOrCreate()
# 定义注册事件的数据结构
registration_schema = StructType([
StructField("user_id", StringType(), True), # 注册用户ID
StructField("ip", StringType(), True), # 注册IP地址
StructField("device_id", StringType(), True), # 设备标识
StructField("event_time", TimestampType(), True) # 事件时间(必须时间戳类型)
])
# ===== 数据源配置 =====
# 从Kafka读取注册事件流(生产环境配置)
registrations = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "kafka1:9092,kafka2:9092") \
.option("subscribe", "user_registrations") \ # 订阅注册主题
.option("startingOffsets", "latest") \ # 从最新位置开始
.option("failOnDataLoss", "false") \ # 容忍数据丢失
.load() \
.select(
from_json(col("value").cast("string"), registration_schema).alias("data")
).select("data.*") # 提取结构化数据
# 添加水印处理延迟数据(10分钟延迟)
registrations = registrations.withWatermark("event_time", "10 minutes")
# ===== 核心检测逻辑 =====
# 每10分钟窗口统计每个IP的注册次数
ip_registration_counts = registrations.groupBy(
window("event_time", "10 minutes"), # 10分钟滚动窗口
"ip" # 按IP分组
).agg(
count("*").alias("registration_count") # 计算注册次数
)
# 过滤出异常IP(10分钟内注册超过20次)
suspicious_ips = ip_registration_counts.filter(
col("registration_count") > 20 # 阈值可根据业务调整
).select(
col("window.start").alias("window_start"), # 窗口开始时间
col("window.end").alias("window_end"), # 窗口结束时间
col("ip"), # 嫌疑IP
col("registration_count") # 注册次数
)
# ===== 输出配置 =====
# 方案1:输出到控制台(调试用)
console_query = suspicious_ips.writeStream \
.outputMode("complete") \ # 完整模式(显示所有结果)
.format("console") \
.option("truncate", "false") \
.option("numRows", 100) \
.trigger(processingTime="1 minute") \ # 每分钟触发一次
.start()
# 方案2:输出到Elasticsearch(生产环境)
es_query = suspicious_ips.writeStream \
.outputMode("complete") \
.format("org.elasticsearch.spark.sql") \
.option("es.nodes", "es1:9200") \
.option("es.resource", "fraud_ips") \ # 索引名称
.option("es.mapping.id", "ip") \ # 使用IP作为文档ID
.option("es.write.operation", "upsert") \
.option("checkpointLocation", "/checkpoints/ip_fraud") \ # 检查点目录
.start()
# 方案3:输出到Kafka告警主题(生产环境)
alert_query = suspicious_ips.selectExpr(
"CAST(ip AS STRING) AS key",
"to_json(struct(*)) AS value"
).writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "kafka1:9092") \
.option("topic", "fraud_alerts") \
.option("checkpointLocation", "/checkpoints/ip_fraud_kafka") \
.start()
# 等待任意流查询终止
spark.streams.awaitAnyTermination()
# 生产环境应添加信号捕获和优雅关闭逻辑第五章 性能调优:从百级到百万级的跨越
5.1 Kafka优化黄金参数
Kafka是一个高吞吐量、低延迟的分布式流处理平台。其核心功能包括:
- 生产者(Producer):将数据发送到Kafka主题(Topic)。
- 消费者(Consumer):从Kafka主题中读取消息。
- 主题(Topic):消息的分类目录。
- 分区(Partition):主题的逻辑划分,支持并行处理。
# server.properties num.network.threads=16 # 网络线程池 num.io.threads=32 # 磁盘IO线程 log.flush.interval.messages=10000 socket.send.buffer.bytes=1024000 # 发送缓冲区
5.2 Spark资源分配公式
# 集群资源配置示例
spark-submit --master yarn \
--num-executors 16 \ # 执行器数量
--executor-cores 4 \ # 每执行器内核
--executor-memory 8g \ # 执行器内存
--conf spark.sql.shuffle.partitions=128 \ # 并行度
--conf spark.streaming.backpressure.enabled=true # 反压5.3 压测指标解读
| 指标 | 健康阈值 | 优化方向 |
|---|---|---|
| 批处理延迟 | < 1s | 增加executor |
| GC时间占比 | < 10% | 调整内存比例 |
| Kafka Lag | < 1000 | 提升消费并行度 |
验证题目:当观察到Spark任务GC时间占比超30%,应如何调整?
答案:1. 增加executor-memory 2. 调整内存分数(spark.memory.fraction)3. 改用G1垃圾回收器
结语:实时智能决策的未来
随着Flink等新一代引擎崛起,PySpark+Kafka架构持续进化。2023年Databricks推出Delta Live Tables,实现流批一体新范式。但核心原则不变:
“实时数据系统的价值不在于速度本身,而在于决策链路的闭环效率”
无论架构如何演进,掌握分布式系统核心原理、理解数据流动的本质,才是工程师应对技术洪流的终极铠甲。
终极挑战:设计支持动态规则更新的实时风控系统架构
参考答案:
规则存储在Redis/配置中心
Spark Streaming通过
broadcast机制加载规则规则变更时触发广播变量更新
结合CEP引擎(如Flink)处理复杂事件序列
通过本文的讲解,你已经掌握了PySpark和Kafka在实时数据处理中的核心原理和实战技巧。PySpark提供了强大的分布式数据处理能力,而Kafka则为实时数据传输提供了高效的解决方案。通过两者的结合,可以构建一个高效、可靠的实时数据处理系统。
在实际开发中,合理使用这些技术可以显著提升系统的性能和稳定性。通过PySpark和Kafka的结合,可以实现更复杂的数据处理场景,满足企业对实时数据分析的需求。
实践建议:
- 在实际项目中根据需求选择合适的PySpark和Kafka配置。
- 学习和探索更多的实时数据处理技巧,如流式机器学习和复杂事件处理(CEP)。
- 阅读和分析优秀的实时数据处理项目,学习如何在实际项目中应用这些技术。
希望这篇博客能够帮助你深入理解PySpark和Kafka在实时数据处理中的应用,提升你的开发效率和代码质量!如果你有任何问题或建议,欢迎在评论区留言!

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 52
52 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)