
基于知识图谱的智能问答系统教程实战六----智能问答系统【Django+neo4j+LLM大模型】
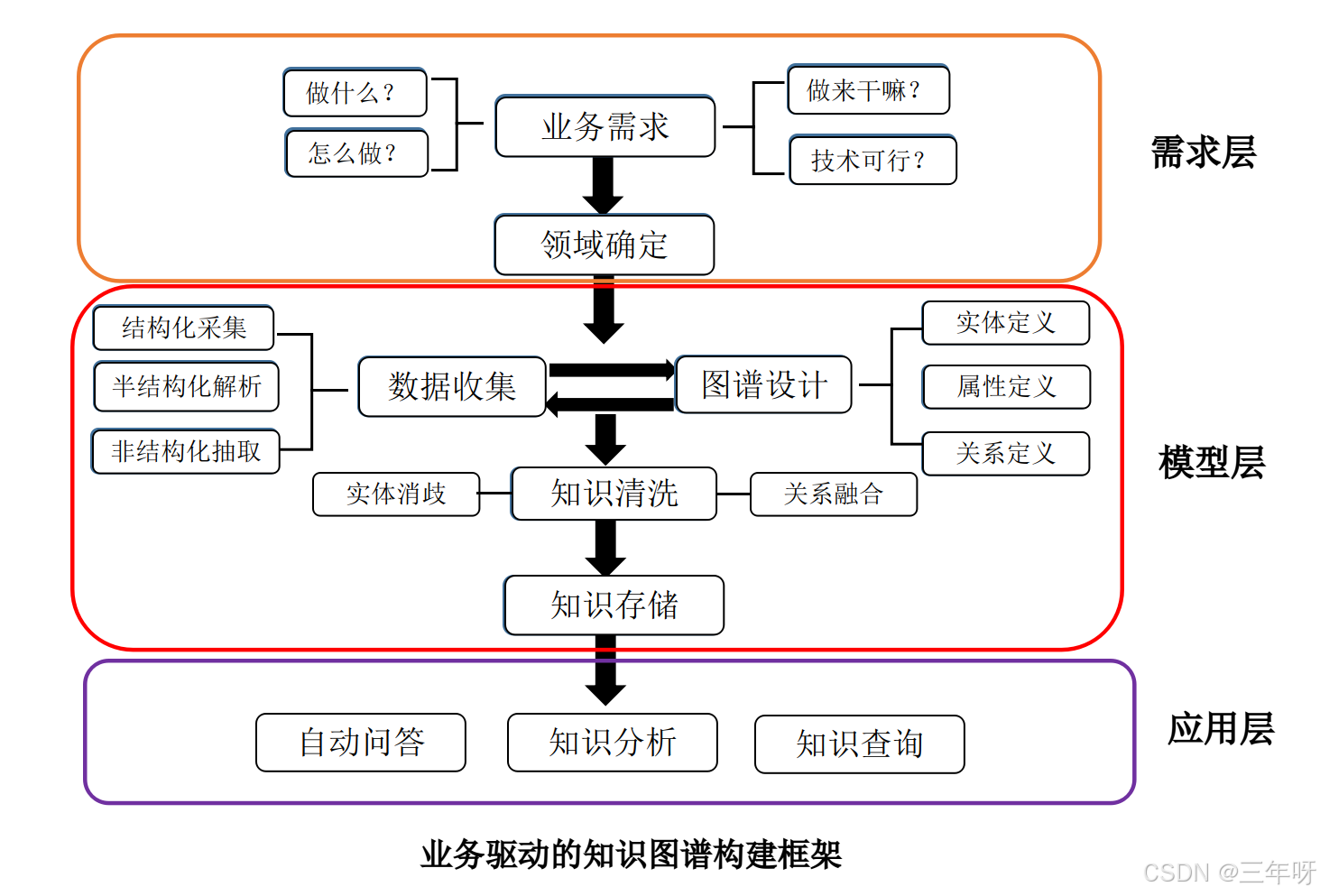
本项目基于垂直医疗网站数据构建医药领域知识图谱,包含4.4万实体和30万关系,支持自然语言问答。系统采用Neo4j图数据库存储,通过规则匹配实现问答功能。项目地址核心数据疾病数量:8000+(肝病相关200+)知识实体:7类4.4万实体关系:11类30万。
前言
本教程一共分为7个小教程专为零基础小白设计,从概念到实战,带你轻松入门!
📁 资源福利:教程代码+数据集+工具安装包,私信领取!
【解决毕设的最后一公里】基于知识图谱的智能问答系统教程实战一----项目整体介绍【Django+neo4j+大模型】
5.1 项目概述
本项目基于垂直医疗网站数据构建医药领域知识图谱,包含4.4万实体和30万关系,支持自然语言问答。系统采用Neo4j图数据库存储,通过规则匹配实现问答功能。
项目地址:
核心数据:
- 疾病数量:8000+(肝病相关200+)
- 知识实体:7类4.4万
- 实体关系:11类30万
5.2 系统架构
5.2.1 项目结构
5.2.2 代码架构:
5.3 数据库构建
build_medicalgraph.py 该脚本构建了一个MedicalGraph类,定义了Graph类的成员变量g和json数据路径成员变量data_path。
class MedicalGraph:
def __init__(self):
cur_dir = '\\\\'.join(os.path.abspath(__file__).split('\\\\')[:-1]) # 获取上层目录
self.data_path = os.path.join(cur_dir, 'data\\hepatopathy.json') # JSON数据路径
self.g = Graph(
host="127.0.0.1", # Neo4j服务器IP
http_port=7474, # 监听端口
user="neo4j", # 数据库用户名
password="neo4j") # 数据库密码
类中的函数如下:
5.3.1 read_nodes函数:读取数据文件
- 定义节点变量(list 类型)
disease_infos:包含所有疾病信息,每个元素为disease_dict(dict 类型)
- 定义节点实体关系变量(list 类型)
函数逐行读取 JSON 数据,每行构建一个包含疾病属性的disease_dict(dict 类型)
(注:除基本属性外,cure_department和symptom这两种实体也包含在疾病字典中)
处理 JSON 字典键的规则:
disease_dict['desc'] = data_json['desc']
若表示疾病关系,则添加到对应关系列表:
for acompany in data_json['acompany']:
rels_acompany.append([disease, acompan
若为其他实体,则添加到对应实体列表:
check = data_json['check']
checks += chec
注意:
symptoms既作为疾病属性,也表示疾病—症状的关系。cure_department在 JSON 中有两种形式,需要:- 添加到
disease_dict实体字典和departments实体列表 - 若只有一个科室,创建疾病—科室关系(
rels_category) - 若有两个科室,创建科室—科室关系(
rels_department)
- 添加到
if 'cure_department' in data_json:
cure_department = data_json['cure_department']
if len(cure_department) == 1:
rels_category.append([disease, cure_department[0]])
if len(cure_department) == 2:
big = cure_department[0]
small = cure_department[1]
rels_department.append([small, big]) # 提取科室——科室关系
rels_category.append([disease, small])
disease_dict['cure_department'] = cure_department
departments += cure_department
drug_details的数据格式如下:
"drug_detail" : [ "惠普森穿心莲内酯片(穿心莲内酯片)", "北京同仁堂百咳静糖浆(百咳静糖浆)"]
由于包含药品名和生产厂商,且使用括号分隔,需要特殊处理来提取药品—在售药品关系:
if 'drug_detail' in data_json:
drug_detail = data_json['drug_detail']
producer = [i.split('(')[0] for i in drug_detail]
rels_drug_producer += [[i.split('(')[0], i.split('(')[-1].replace(')', '')] for i in drug_detail]
producers += producer
最后返回经过 set 去重的所有实体、疾病属性信息和实体关系。
5.3.2 create_graphnodes函数:创建知识图谱实体节点类型 schema
首先调用read_nodes函数获取实体和实体关系变量。
知识图谱包含两类节点:
- 中心疾病节点:包含各种疾病属性
- 普通实体节点:如药品、食物等,不含属性。通过以下两个函数创建:
5.3.3 create_diseases_nodes函数:创建知识图谱中心疾病节点
遍历disease_infos,使用 py2neo 库的 Graph 类create函数,创建标签为"Disease"的节点,将disease_dict中的属性作为节点属性。
node = Node("Disease", name=disease_dict['name'], desc=disease_dict['desc'],
prevent=disease_dict['prevent'] ,cause=disease_dict['cause'],
easy_get=disease_dict['easy_get'],cure_lasttime=disease_dict['cure_lasttime'],
cure_department=disease_dict['cure_department']
,cure_way=disease_dict['cure_way'] , cured_prob=disease_dict['cured_prob'])
self.g.create(node)
5.3.4 create_node函数:创建普通实体节点
为每类实体创建节点,设置 label 为实体类别,name 为具体实体名称。
for node_name in nodes:
node = Node(label, name=node_name)
self.g.create(node)
5.3.5 create_graphrels函数:创建实体关系边
调用read_nodes函数获取实体和实体关系变量。
通过create_relationship函数创建 11 种实体关系边。
5.3.6 create_relationship函数:创建实体关联边
首先对实体关系列表去重。由于关系形如[["a","b"],["c","d"]]的嵌套列表无法直接用 set 去重,需要先将内层列表转为字符串。
然后使用 py2neo 库的run函数执行 Cypher 语言的 Neo4j CQL 语句,为每对实体创建关系边:
query = "match(p:%s),(q:%s) where p.name='%s'and q.name='%s' create (p)-[rel:%s{name:'%s'}]->(q)" % (
start_node, end_node, p, q, rel_type, rel_name)
try:
self.g.run(query)
count += 1
print(rel_type, count, all)
except Exception as e:
print(e)
5.3.7 export_data函数:导出数据到txt
调用read_nodes函数获取实体和实体关系变量。
将各变量数据逐行写入对应的 txt 文件。
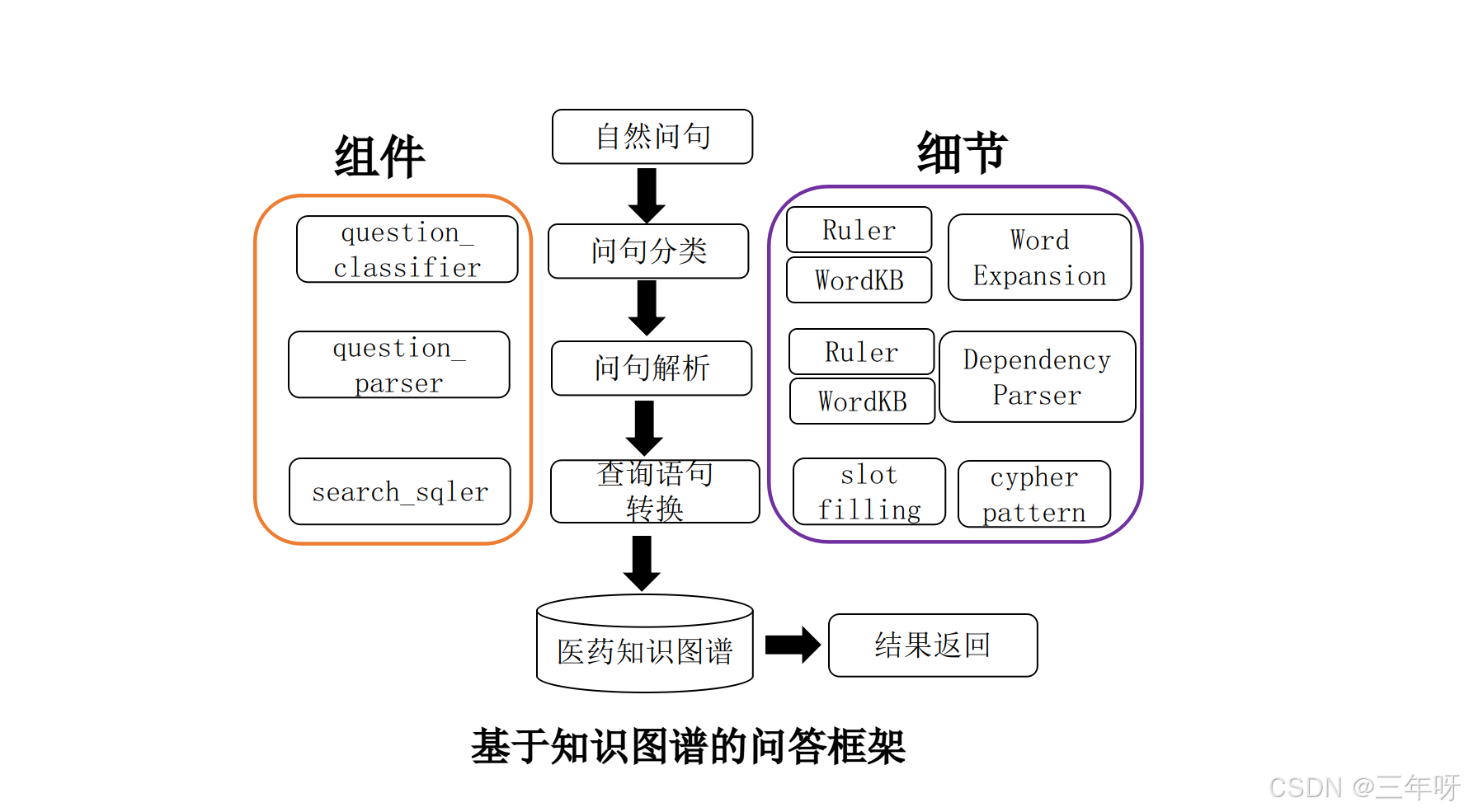
5.4 智能问答实现
本项目采用基于规则匹配的问答系统。系统通过关键词匹配对问句进行分类。由于医疗问题属于封闭域场景,系统首先对领域问题进行穷举分类,然后使用 Cypher 的 match 语句在 Neo4j 中查找匹配项,最后根据返回的数据组装答案。
问答框架通过 answer_search.py、question_classifier.py 、get_zhipu_response.py和 question_parser.py 等脚本实现。
5.4.1 question_classifier.py
该脚本定义了问题分类类 QuestionClassifier,包含特征词路径、特征词、领域 actree、词典和问句疑问词等成员变量。
特征词包括 7 类实体,以及由这些实体词构成的领域词 region_words 和否定词库 deny_words。
- 领域 actree 通过
self.build_actree构建。 - 词典通过
self.build_wdtype_dict()构建。 - 问句疑问词包含疾病的属性和边相关的问题词,对应上文提到的问答系统支持的问答类型。
build_actree 函数
该函数构建领域 actree 用于加速过滤,实现基于 Python 的 ahocorasick 库。
ahocorasick 是一种字符串匹配算法,由 trie 和 Aho-Corasick 自动机两种数据结构实现。Trie 是字符串索引的词典,检索时间与字符串长度成正比。AC 自动机能在一次运行中找到给定集合的所有字符串。它本质是在 Trie 树上实现 KMP,可完成多模式串匹配。
def build_actree(self, wordlist):
actree = ahocorasick.Automaton() # 初始化trie树
for index, word in enumerate(wordlist):
actree.add_word(word, (index, word)) # 向trie树中添加单词
actree.make_automaton() # 将trie树转化为Aho-Corasick自动机
return actree
build_wdtype_dict 函数
该函数基于 7 类实体构造 {特征词:特征词对应类型} 的词典。
wd_dict = dict()
for wd in self.region_words:
wd_dict[wd] = []
if wd in self.disease_wds:
wd_dict[wd].append('disease')
...
check_medical 函数
该函数通过 ahocorasick 库的 iter() 函数匹配领域词,去除重复字符串中较短的词,保留最长的领域词。
其功能是过滤问句中的领域词,返回 {问句中的领域词:词所对应的实体类型}。
def check_medical(self, question):
region_wds = []
for i in self.region_tree.iter(question): # ahocorasick库 匹配问题 iter返回一个元组,i的形式如(3, (23192, '乙肝'))
wd = i[1][1] # 匹配到的词
region_wds.append(wd)
stop_wds = []
for wd1 in region_wds:
for wd2 in region_wds:
if wd1 in wd2 and wd1 != wd2:
stop_wds.append(wd1) # stop_wds取重复的短的词,如region_wds=['乙肝', '肝硬化', '硬化'],则stop_wds=['硬化']
final_wds = [i for i in region_wds if i not in stop_wds] # final_wds取长词
final_dict = {i: self.wdtype_dict.get(i) for i in final_wds}
return final_dict
check_words 函数
该函数检查问句中是否包含特定实体类型的特征词。
def check_words(self, wds, sent):
for wd in wds:
if wd in sent:
return True
return False
classify 函数
这是分类的主函数。
首先调用 check_medical 函数获取问句中的领域词及其所属领域,并收集涉及的实体类型。
然后基于特征词进行分类:调用 check_word 函数检查问句是否包含特定领域特征词,并验证该领域是否存在于问句的实体类型中,从而判断问句类型。
示例如下:
# 症状
if self.check_words(self.symptom_qwds, question) and ('disease' in types):
question_type = 'disease_symptom'
question_types.append(question_type)
if self.check_words(self.symptom_qwds, question) and ('symptom' in types):
question_type = 'symptom_disease'
question_types.append(question_type)
# 已知食物找疾病
if self.check_words(self.food_qwds + self.cure_qwds, question) and 'food' in types:
deny_status = self.check_words(self.deny_words, question)
if deny_status:
question_type = 'food_not_disease'
else:
question_type = 'food_do_disease'
question_types.append(question_type)
如果没有找到相关的外部查询信息:对于疾病类型,返回疾病描述(question_types = ['disease_desc']);对于症状类型,返回相关疾病信息(question_types = ['symptom_disease'])。最后将分类结果合并为一个字典返回。
注意:
- 食物相关问题需要通过检查否定词
self.deny_words来判断是 do_eat 还是 not_eat。 - 已知食物查疾病和已知检查项目查疾病时,
check_words需要包含self.cure_qwds。
5.4.2 question_parser.py
问句分类后需要进行解析。该脚本定义了 QuestionPaser 类,包含三个成员函数。
build_entitydict 函数
示例:从分类结果 {'args': {'头痛': ['disease', 'symptom']}, 'question_types': ['disease_cureprob']} 中获取 args,返回 {'disease': ['头痛'], 'symptom': ['头痛']}。
sql_transfer 函数
该函数根据不同问题类型生成相应的 Cypher 查询语句。
示例:
# 查询疾病的原因
if question_type == 'disease_cause':
sql = ["MATCH (m:Disease) where m.name = '{0}' return m.name, m.cause".format(i) for i in entities]
# 查询疾病的忌口
elif question_type == 'disease_not_food':
sql = ["MATCH (m:Disease)-[r:no_eat]->(n:Food) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
注意:
- 查询可能涉及疾病节点的属性或关联边。
- 疾病的并发症需要双向查询。
- 推荐食物包括 do_eat 和 recommand_eat 两种关联边。
- 查询药品时需要考虑药品别名,包括 common_drug 和 recommand_durg 两种关联边。
parser_main 函数
这是问句解析的主函数。首先获取问句分类结果中的领域词及其实体类型。
然后调用 build_entitydict 函数,生成 {'实体类型': ['领域词'], ...} 格式的字典。
接着对分类结果中的每个 question_type 调用 sql_transfer 函数转换为 Neo4j 的 Cypher 查询语句。最后合并所有查询语句。
5.4.3 answer_search.py
问句解析后需要查询结果。该脚本定义了 AnswerSearcher 类。与 build_medicalgraph.py 类似,它包含 Graph 类的成员变量 g 和答案最大返回数 num_list。
该类有两个成员函数:查询主函数和回复模块。
search_main 函数
该函数接收问题解析结果 sqls,从 queries 中提取 ['question_type'] 和 ['sql']。
首先执行 self.g.run(query).data() 获取查询结果,
然后根据 ['question_type'] 调用 answer_prettify 函数组装答案。
最后返回完整答案。
answer_prettify 函数该函数根据 question_type 选择相应的回复模板。
elif question_type == 'disease_cause':
desc = [i['m.cause'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}可能的成因有:{1}'.format(subject, ';'.join(list(set(desc))[:sel)
5.4.4 get_zhipu_response.py
这段Python代码实现了一个与智谱AI(ZhipuAI)API交互的封装类,主要功能是通过glm-4大模型生成简洁的文本回复。
class GetZhipuResponse:
def __init__(self):
self.client = ZhipuAI(api_key=settings.ZHIPUAI_API_KEY)
def get_chatglm_response(self, prompt):
response = self.client.chat.completions.create(
model="glm-4",
messages=[
{"role": "system", "content": "你以简明扼要著称,所有回答都用最精炼的语言表达"},
{"role": "user", "content": f"【请用1-2句话回答】{prompt}"}, # 双重提示
],
temperature=0.3, # 降低随机性
max_tokens=200, # 限制最大长度
stream=False,
)
return response.choices[0].message.content

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)