
【模型压缩】(一)开篇及轻量模型介绍
一、开篇随着神经网络的发展,transformers和高级卷积网络架构给视觉和预研领域任务带来提升的同时,模型的规模及计算量也越来越大;虽然模型的体积增大往往能带来更好的效果,但在实际场景的应用性几乎为0,这也是学术界和工业界存在的一个最大差异,模型的落地往往要考虑的方面有很多,并不只是单纯看预测的效果;模型变大引发的一些问题:更长训练时间;更长的推断时间;更多的内存占用;模型压缩的目的:以一
一、开篇
随着神经网络的发展,transformers和高级卷积网络架构给视觉和预研领域任务带来提升的同时,模型的规模及计算量也越来越大;
虽然模型的体积增大往往能带来更好的效果,但在实际场景的应用性几乎为0,这也是学术界和工业界存在的一个最大差异,模型的落地往往要考虑的方面有很多,并不只是单纯看预测的效果;
模型变大引发的一些问题:
- 更长训练时间;
- 更长的推断时间;
- 更多的内存占用;
模型压缩的目的:以一种对性能影响最小,最有效的结构或格式表示模型,从而减轻大模型的各项成本;
二、模型部署方法
AI模型的部署有两种方法:云端和终端;
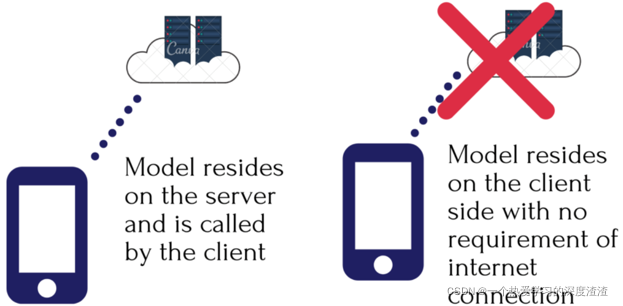
云端也就是将模型部署在服务器上,部署起来容易,但有以下几个缺点:
- 模型在大规模使用时网络连接的可变性导致服务不可用或中断;
- 客户端隐私;
- 服务器成本;
- 实时服务的支持;
- 处理端远离数据源;
终端也就是将模型部署在设备上,部署相对麻烦,存在以下几个问题:
- AI模型往往在上百MB的级别,在手机上是不能直接部署这么大的模型的;
- 推理时间较长,在云端可使用GPU进行推理,而终端设备的算力要低很多;
- 能耗效率,设备端电池耗电严重;
三、模型压缩方法
模型压缩技术可以分为两类:
1、模型训练后的压缩方法,也称为后处理技术,例如剪枝和量化技术;
2、模型本身的轻量化方法,也称为前处理技术,通过模型结构或训练方法的优化,达到较高的准确性,例如知识蒸馏技术、MobileNet等压缩模型结构;
四、压缩模型
这里所说的压缩模型是名词,也成为轻量模型,主要有以下特点:
- 拥有特定结构的一类神经网络模型;
- 在原有结构上进行优化,大量减少网络参数的同时,性能接近先进模型的水平;
- 训练时间更短,推理速度更快;
1、SqueezeNet
SqueezeNet中最重要的部分就是Fire Moduel,如下图所示:
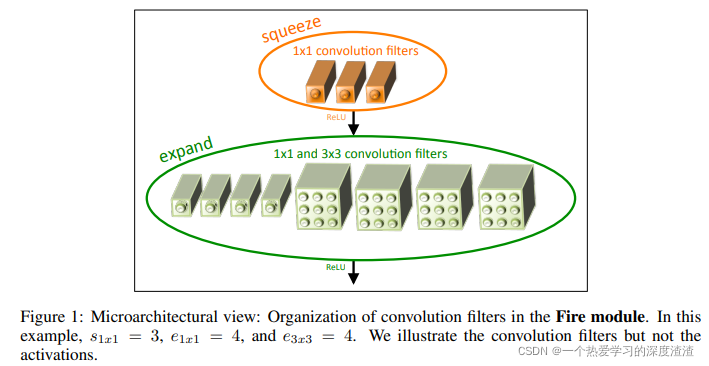
Fire Module结构说明:
- 首先通过Squenze部分对输入进行压缩,用到了1x1卷积核减少通道数;
- 随后通过Expand部分进行处理和合并,输出的通道数为1x1卷积核输出加上3x3卷积核输出;
1x1卷积核的作用:
- 将3x3卷积核替换成1x1卷积核后,参数量减少9倍;
- 减少输入到expand部分中3x3卷积的通道数;
整个SqueezeNet模型的结构图:
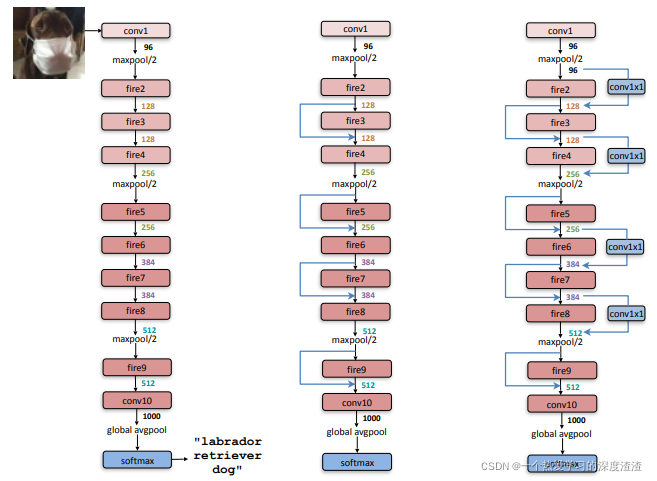
从结构图上可以看出,由少量的conv层核pooling层组成,其余的都是fire的结构,也可以加入一些残差模块;
SqueezeNet的效果:
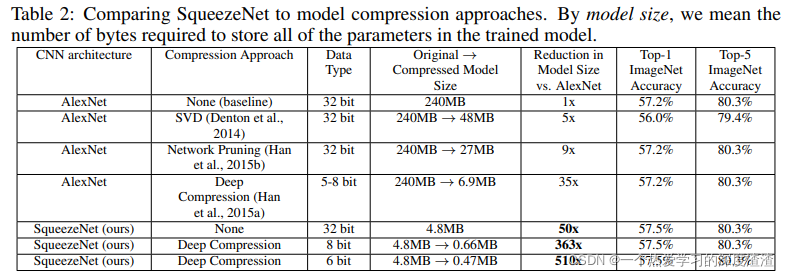
代码实现:
Fire结构:
class Fire(nn.Module):
def __init__(self, inplanes: int, squeeze_planes: int, expand1x1_planes: int, expand3x3_planes: int) -> None:
super().__init__()
self.inplanes = inplanes
self.squeeze = nn.Conv2d(inplanes, squeeze_planes, kernel_size=1)
self.squeeze_activation = nn.ReLU(inplace=True)
self.expand1x1 = nn.Conv2d(squeeze_planes, expand1x1_planes, kernel_size=1)
self.expand1x1_activation = nn.ReLU(inplace=True)
self.expand3x3 = nn.Conv2d(squeeze_planes, expand3x3_planes, kernel_size=3, padding=1)
self.expand3x3_activation = nn.ReLU(inplace=True)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.squeeze_activation(self.squeeze(x))
return torch.cat([self.expand1x1_activation(self.expand1x1(x)), self.expand3x3_activation(self.expand3x3(x))], 1)
这里就不实现整个模型的结构了,根据模型结构图进行叠加即可;
2、MobileNet
MobileNet创新点:Depth-wise Separable Convolution(深度可分离卷积)
主要将原来的卷积拆分为:深度卷积和逐点卷积;
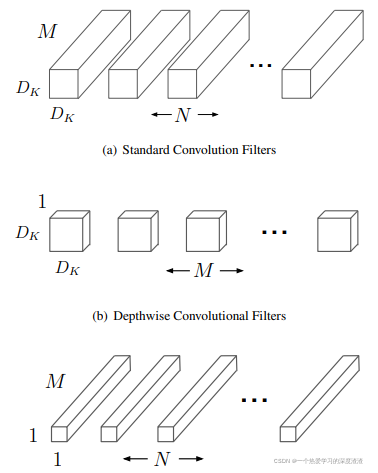
由上图可以知道,将原始的D x D x M的卷积核分成D x D x 1的卷积核和1 x 1 x M的卷积核两部分;
从结构上变化如下图所示:
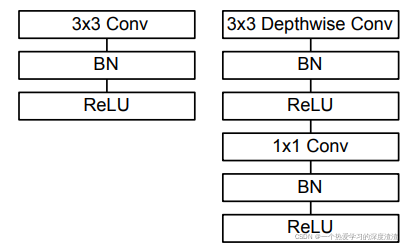
MobileNet还提供了两个超参数因子:
- 宽度因子:用于调整输入和输出特征的通道数;
- 分辨率因子:用于控制输入的分辨率;
MobileNet的压缩效果:
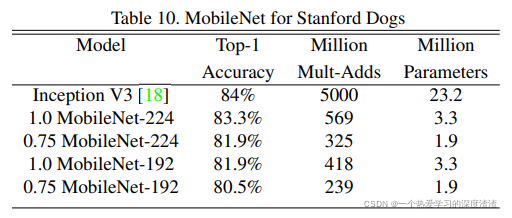
可以看出,宽度因子和分辨率因子也能在一定程度上减少模型的计算量和参数量,这就是模型效果和性能的权衡问题了;
代码实现:
下面代码实现深度卷积和逐点卷积:
class Block(nn.Module):
"""
DWConv + PointWiseConv
"""
def __init__(self, in_planes, out_planes, stride):
super(Block, self).__init__()
self.conv1 = nn.Conv2d(in_planes,
in_planes,
kernel_size=3,
stride=stride,
padding=1,
groups=in_planes, # 这里引入分组卷积这个参数,实现深度卷积
bias=False)
self.bn1 = nn.BatchNorm2d(in_planes)
self.conv2 = nn.Conv2d(in_planes,
out_planes,
kernel_size=1,
stride=1,
padding=0,
bias=False)
self.bn2 = nn.BatchNorm2d(out_planes)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
return out
这里不实现整个MobileNet的结构,根据模型结构图进行叠加即可;
后续还有MobileNet V2版本,用到了SqueezeNet中的拓展和压缩方法,还加入了残差结构,在这里就不讲解了;
3、ShuffleNet
ShuffleNet主要创新点:转置重组;
设计思路:
- 对不同的通道进行shuffle来解决分组卷积带来的问题;
- 解决深度可分离卷积核ResNext的缺陷
- 分组卷积的缺陷:组与组之间的信息难以传递;
Shuffle结构:
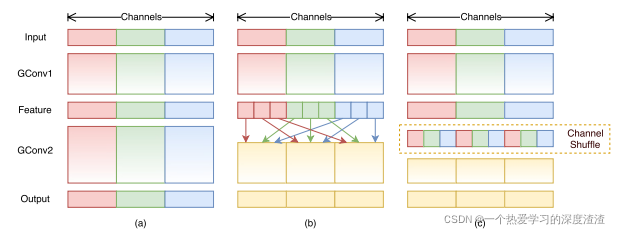
这个结构能够将每个通道中的组进行转置,从而达到信息传递的作用;
代码实现:
class ShuffleBlock(nn.Module):
def __init__(self,groups):
super(ShuffleBlock,self).__init__()
self.groups = groups
def forward(self, x): # 转置重组操作
'''
[N,C,H,W]->分组操作->[N,C/g,H,W]*g->转置重组->[N,g,H,W]*C/g
'''
N, C, H, W = x.size()
g = self.groups
return x.view(N, g ,int(C/g), H, W).permute(0, 2, 1, 3, 4).contiguous().view(N, C, H, W)
五、总结
比较经典的轻量化网络就是以上三种,主要是学习其中的思想,了解能够实现压缩模型的一个原理;现在视觉领域的任务面临的一大难点就是难以落地,有许多能够达到更好效果的模型和算法,但其庞大的计算量和参数量就让工业界直接放弃;
模型压缩的方法让视觉和自然语言领域的项目得以落地。这也是很多头部公司正在发展的方向;

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)