
python数据处理方法——pkl格式文件_pkl文件
在 Python 编程中,我们通常需要将数据保存到文件中以便在以后的执行中使用。pkl 文件是一种常见的文件格式,它可以保存 Python 对象的状态,并且可以在需要时将其恢复到内存中,pkl 文件是以二进制格式保存的。pkl 文件提供了一种简单而有效的方法来序列化和反序列化 Python 对象,使其易于存储、传输和共享。1.1 什么是 pkl 文件?pkl文件是指使用Python的pickle模
2.1 对象序列化为 pkl 文件(将数据保存为pkl文件)
2.2 从 pkl 文件中反序列化对象(打开读取pkl文件)
3.2.1 joblib保存pkl模型文件joblib.dump()
3.2.2 joblib加载pkl模型文件joblib.load()
3.3.1 pickle保存pkl模型文件pickle.dump()
3.3.2 pickle加载pkl模型文件pickle.load()
4.pkl模型文件加载后预测结果prdict_proba()
7.如何通过github上拿到的pkl文件找到制作该文件的方法?
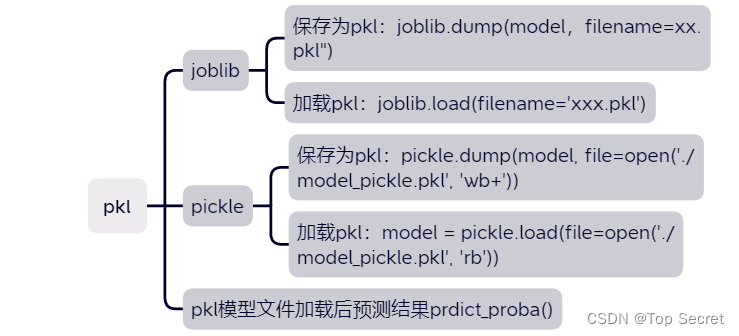
1.pkl文件格式简介:
在 Python 编程中,我们通常需要将数据保存到文件中以便在以后的执行中使用。 pkl 文件是一种常见的文件格式,它可以保存 Python 对象的状态,并且可以在需要时将其恢复到内存中,pkl 文件是以二进制格式保存的。pkl 文件提供了一种简单而有效的方法来序列化和反序列化 Python 对象,使其易于存储、传输和共享。
1.1 什么是 pkl 文件?
pkl 文件是指使用 Python 的 pickle 模块生成的二进制文件,用于将 Python 对象序列化到磁盘上。序列化是指将对象转换为字节流的过程,以便将其保存到文件中。 pkl 文件包含了对象的状态信息,包括对象的数据和方法。
稍微总结一下,pkl文件,即
1)python中有一种存储方式,可以存储为.pkl文件。
2)该存储方式,可以将python项目过程中用到的一些暂时变量、或者需要提取、暂存的字符串、列表、字典等数据保存起来。
3)保存方式就是保存到创建的.pkl文件里面。
4)然后需要使用的时候再 open,load。
1.2 pkl文件和pmml文件的简单区别
在学习pkl文件之前,我们再来了解另外一种文件格式: pmml文件。
python机器学习模型训练完之后可以保存为pkl文件,也可以保存为pmml文件。
那么什么时候保存为pkl文件,什么时候保存为pmml文件呢?
专业点说:模型需要跨平台使用,交由技术部门用java上线运行,需要使用pmml文件。
简单点说:给python开发用就保存为pkl文件,给java开发用就保存为pmml文件。
1.3 pkl 文件的优点
使用 pkl 文件有以下几个优点:
(1)简单易用: pickle 模块提供了简单的接口,使得序列化和反序列化 Python 对象变得非常容易。
(2)数据完整性: pkl 文件保存了对象的完整状态,包括对象的数据和方法,确保了数据的完整性。
(3)跨平台兼容性:由于 pkl 文件是以二进制格式保存的,因此可以在不同的操作系统和 Python 版本之间进行交互。
(4)数据压缩: pickle 模块支持数据压缩,可以减小文件大小并节省存储空间。
1.4 使用场景
1)保存模型:在机器学习和深度学习中,我们可以使用 pkl 文件保存训练好的模型,以便在需要时加载和使用。
2)缓存数据:当我们需要频繁地读取和处理数据时,可以将数据序列化为 pkl 文件,以便提高读取和处理的速度。
3)传输数据: pkl 文件可以用于将数据传输到不同的系统和环境中,确保数据的完整性和一致性。
2.使用 Python 操作 pkl 文件
2.1 对象序列化为 pkl 文件(将数据保存为pkl文件)
要将 Python 对象序列化为 pkl 文件,我们需要使用 pickle 模块的 dump() 函数。
以下是一个将 Python 对象保存为 pkl 文件的示例代码:
import pickle
# 创建一个Python对象
data = {'name': 'Alice', 'age': 30}
# 将对象序列化为pkl文件
with open('data.pkl', 'wb') as file:
pickle.dump(data, file)
如此便实现了将对象保存到pkl文件中:
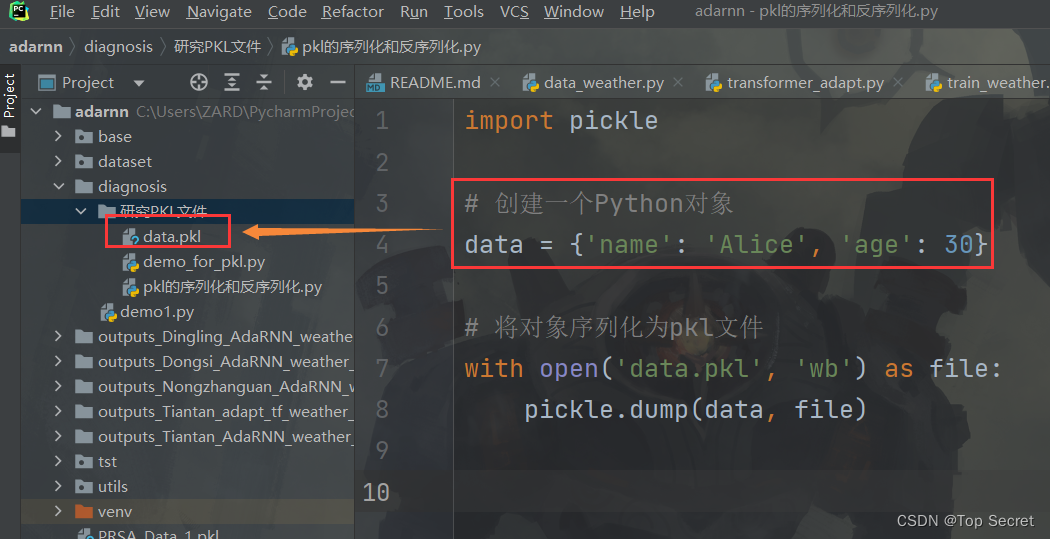 上述代码将一个字典对象保存到名为
上述代码将一个字典对象保存到名为 data.pkl 的 pkl 文件中。
2.2 从 pkl 文件中反序列化对象(打开读取pkl文件)
要从 pkl 文件中反序列化对象,我们需要使用 pickle 模块的 load() 函数。
以下是一个从 pkl 文件中加载 Python 对象的示例代码:
import pickle
# 从pkl文件中反序列化对象
with open('data.pkl', 'rb') as file:
loaded_data = pickle.load(file)
# 打印加载的对象
print(loaded_data)
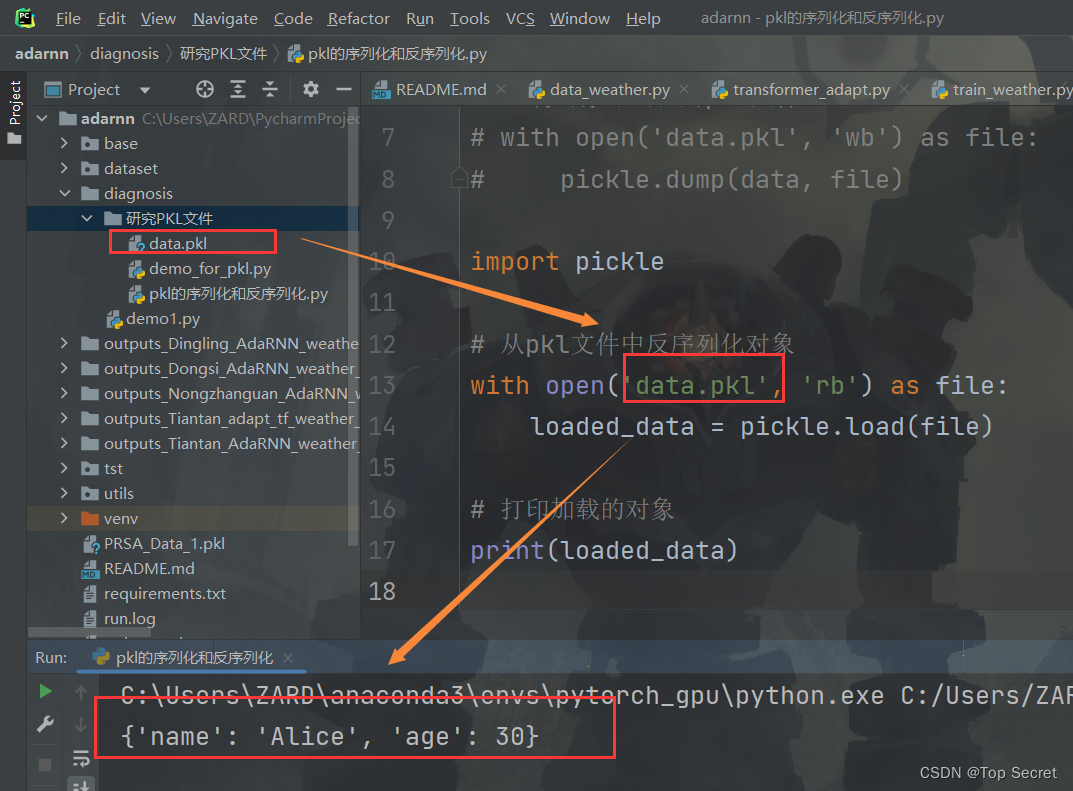 上述代码将从名为
上述代码将从名为 data.pkl 的 pkl 文件中加载对象,并将其打印到控制台。
再来一个例子:
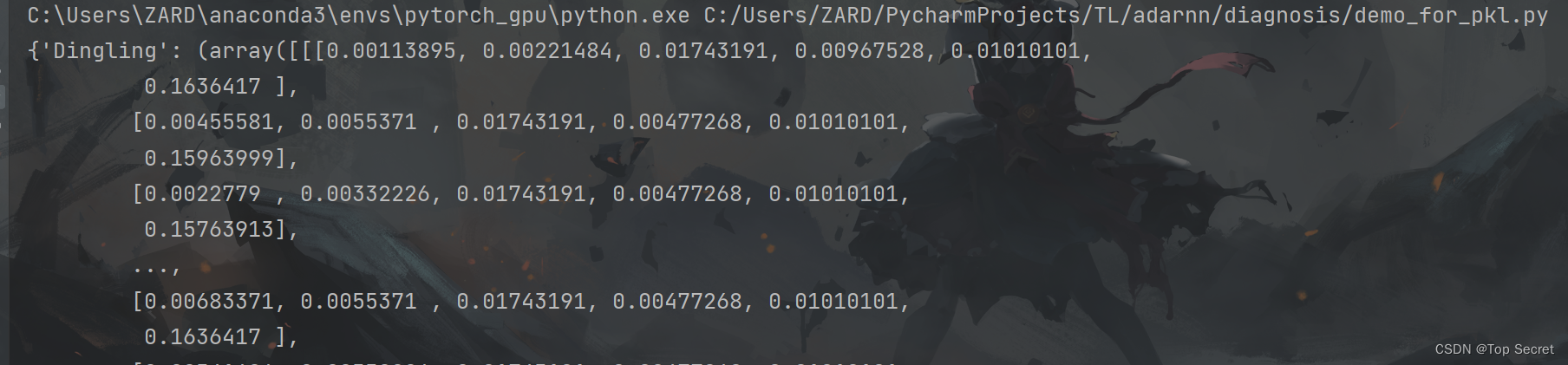
如何打开pkl文件?
# cPickle是python2系列用的,3系列已经不用了,直接用pickle就好了
import pickle
# 重点是rb和r的区别,rb是打开2进制文件,文本文件用r
f = open('../PRSA_Data_1.pkl','rb')
data = pickle.load(f)
print(data)
pycharm中输出结果:
3. pkl文件的保存,加载,使用详解
机器学习模型保存为pkl文件有两种方式:可以使用joblib包,也可以使用pickle包。
3.1 joblib包和pickle包保存加载pkl区别
joblib包是由scikit-learn外带的,常用于保存机器学习模型。对于大数据而言,joblib比pickle更加高效。需要注意的是实际使用时用joblib包和pickle包时不要混用!!!
用joblib包保存的模型,最好还是用joblib包加载。因为用joblie包保存模型,加载时却用pickle包会报错:invalid load key, ‘\x00’。所以保存加载模型的时候建议使用同一个包,不要混着用。
接下来就用鸢尾花数据集,具体演示一下使用joblib包和pickle包保存加载pkl模型,以及用加载的pkl模型文件来预测结果。
3.2 使用joblib包保存加载pkl模型文件
3.2.1 joblib保存pkl模型文件joblib.dump()
# 导入并处理鸢尾花数据集
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris() # 导入鸢尾花数据集
# 数据预处理
# 特征转DataFrame
df = pd.DataFrame(data=iris.data, columns=[i.replace(' ', '_')for i in iris.feature_names])
df['target'] = iris.target # 添加目标值
# print(df) # 此时打印的df数据中的target有:0,1,2
#df = df[df.target.isin([0, 1, 2 ])] # 此时拿到0,1,2这三种target的所有数据,是3分类
df = df[df.target.isin([0, 1])] # 取目标值中的0,1类型的数据,用来做二分类算法
# 分割数据集,用来训练模型
x_train = df.drop('target', axis=1) # 拿到target除外的所有数据
y_train = df['target'] # 拿到每组数据对应的标签
# 使用LGBM训练模型
from lightgbm import LGBMClassifier
model = LGBMClassifier()
model.fit(x_train, y_train)
# 使用joblib保存模型为pkl文件
import joblib
joblib.dump(model, filename='./model_LGBM_joblib.pkl')
joblib.dump()参数说明:
参数model:要保存的模型(fit训练后的)。
参数filename:要保存的模型路径和名称。
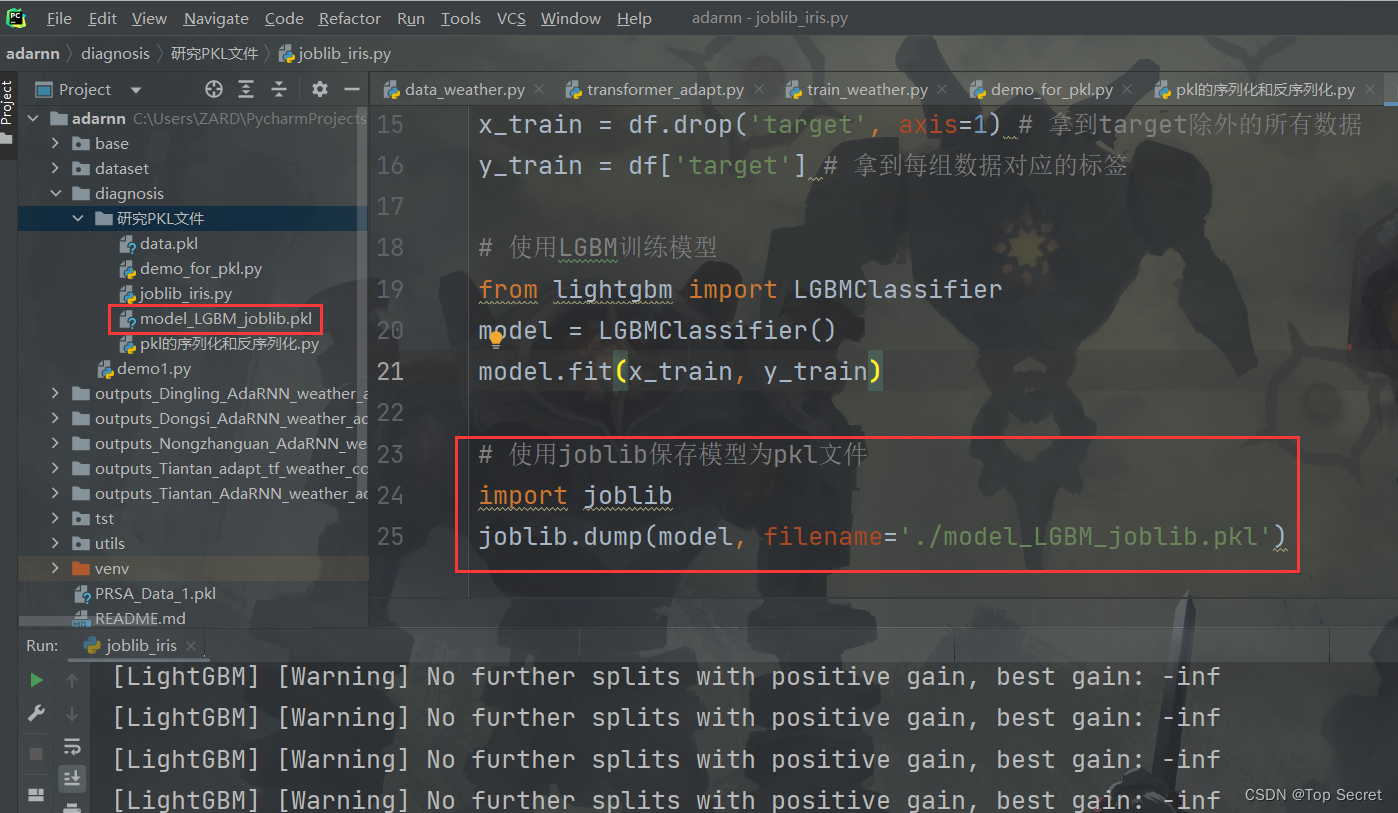
3.2.2 joblib加载pkl模型文件joblib.load()
import joblib
model = joblib.load(filename='./model_LGBM_joblib.pkl')
print(model)
joblib.load()参数说明:
参数filename:要加载的模型路径和名称。
3.3 使用pickle包保存加载pkl模型文件
3.3.1 pickle保存pkl模型文件pickle.dump()
# 导入并处理鸢尾花数据集
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris() # 导入鸢尾花数据集
df = pd.DataFrame(data=iris.data, columns=[i.replace(' ', '_')for i in iris.feature_names]) # 特征转DataFrame
df['target'] = iris.target # 添加目标值
df = df[df.target.isin([0, 1 ])] # 取目标值中的0,1类型的数据,用来做二分类算法
# 分割数据集,用来训练模型
x_train = df.drop('target', axis=1)
y_train = df['target']
# 使用LGBM训练模型
from lightgbm import LGBMClassifier
model = LGBMClassifier()
model.fit(x_train, y_train)
# 使用pickle保存模型为pkl文件
import pickle
pickle.dump(model, file=open('./model_pickle.pkl', 'wb+'))
pickle.dump()参数说明:
参数model:要保存的模型(fit训练后的)。
参数file:简单点说就是要保存的模型路径和名称外加个open。
3.3.2 pickle加载pkl模型文件pickle.load()
import pickle
model = pickle.load(file=open('./model_pickle.pkl', 'rb'))
pickle.load()参数说明:
参数file:简单点说就是要加载的模型路径和名称外加个open。
4.pkl模型文件加载后预测结果prdict_proba()
pkl模型文件加载后的模型,和建模时训练后的模型是一模一样的,所以建模时怎么预测,加载后就怎么预测。(注:pmml模型文件加载后的模型,预测结果的方式是不同的。)
predict_proba预测结果时,不需要输入变量的名称,但输入的变量顺序必须和模型训练时相同。对比以下两种方式:
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)
中…(img-ZLEAS2Zv-1712920736891)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)


GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)