
百度飞桨图像分类------基于飞桨2.0的食品图片分类实战
基于飞桨2.0的食品图片分类实战应用文章目录基于飞桨2.0的食品图片分类实战应用项目描述项目的优化课程链接数据集介绍第一步 必要的库引入,数据读取第二步 数据预处理第三步 继承paddle.io.Dataset对数据集做处理第四步 自行搭建CNN神经网络第五步 模型配置以及训练多次运行,在验证集正确率达到0.50-0.55之间第六步 保存模型第七步 测试集案例展示小结项目描述本项目使用的是李宏毅机
基于飞桨2.0的食品图片分类实战应用
文章目录
项目描述
本人项目源码已经放在AIstudio上,欢迎fork三连
https://aistudio.baidu.com/aistudio/projectdetail/1750484
本项目使用的是李宏毅机器学习中作业三的数据集
包含(面包,乳制品,甜点,鸡蛋,油炸食品,肉类,面条/意大利面,米饭,海鲜,汤,蔬菜/水果)十一类的食品数据,对其进行训练分类
搭建训练一个简单的卷积神经网络,实现这十一类食物图片的分类
项目的优化
1.对各通道进行求均值和标准差
2.更改训练参数
课程链接
课程链接:https://aistudio.baidu.com/aistudio/course/introduce/1978
数据集介绍
本次使用的数据集为food-11数据集,共有11类
Bread, Dairy product, Dessert, Egg, Fried food, Meat, Noodles/Pasta, Rice, Seafood, Soup, and Vegetable/Fruit.
(面包,乳制品,甜点,鸡蛋,油炸食品,肉类,面条/意大利面,米饭,海鲜,汤,蔬菜/水果)
Training set: 9866张
Validation set: 3430张
Testing set: 3347张
数据格式
下载 zip 档后解压缩会有三个资料夹,分别为training、validation 以及 testing
training 以及 validation 中的照片名称格式为 [类别]_[编号].jpg,例如 3_100.jpg 即为类别 3 的照片(编号不重要)
!unzip -d work data/data76472/food-11.zip # 解压缩food-11数据集
!rm -rf work/__MACOSX
第一步 必要的库引入,数据读取
- 读取数据,新建路径+标签的txt的三个文件
- 核实数据量与题目所给是否相同
import os
import paddle
import paddle.vision.transforms as T
import numpy as np
from PIL import Image
import paddle
import paddle.nn.functional as F
from sklearn.utils import shuffle
#在python中运行代码经常会遇到的情况是——代码可以正常运行但是会提示警告,有时特别讨厌。
#那么如何来控制警告输出呢?其实很简单,python通过调用warnings模块中定义的warn()函数来发出警告。我们可以通过警告过滤器进行控制是否发出警告消息。
import warnings
warnings.filterwarnings("ignore")
data_path = 'work/food-11/' # 设置初始文件地址
character_folders = os.listdir(data_path) # 查看地址下文件夹
# 每次运行前删除txt,重新新建标签列表
if(os.path.exists('./training_set.txt')): # 判断有误文件
os.remove('./training_set.txt') # 删除文件
if(os.path.exists('./validation_set.txt')):
os.remove('./validation_set.txt')
if(os.path.exists('./testing_set.txt')):
os.remove('./testing_set.txt')
for character_folder in character_folders: #循环文件夹列表
with open(f'./{character_folder}_set.txt', 'a') as f_train: # 新建文档以追加的形式写入
character_imgs = os.listdir(os.path.join(data_path,character_folder)) # 读取文件夹下面的内容
count = 0
if character_folder in 'testing': # 检查是否是测试集
for img in character_imgs: # 循环列表
f_train.write(os.path.join(data_path,character_folder,img) + '\n') # 把地址写入文档
count += 1
print(character_folder,count)
else:
for img in character_imgs: # 检查是否是训练集和测试集
f_train.write(os.path.join(data_path,character_folder,img) + '\t' + img[0:img.rfind('_', 1)] + '\n') # 写入地址及标签
count += 1
print(character_folder,count)
testing 3347
training 9866
validation 3430
第二步 数据预处理
下面使用paddle.vision.transforms.Compose做数据预处理,主要是这几个部分:
- 以RGB格式加载图片
- 将图片resize,从224x224变成100x100
- 进行transpose操作,从HWC格式转变成CHW格式
- 将图片的所有像素值进行除以255进行归一化
- 对各通道进行减均值、除标准差
# 只有第一次需要执行 一次需要一分钟多
import numpy as np
import cv2
import os
img_h, img_w = 100, 100 #适当调整,影响不大
means, stdevs = [], []
img_list = []
imgs_path = 'work/food-11/training'
imgs_path_list = os.listdir(imgs_path)
len_ = len(imgs_path_list)
i = 0
for item in imgs_path_list:
img = cv2.imread(os.path.join(imgs_path,item))
img = cv2.resize(img,(img_w,img_h))
img = img[:, :, :, np.newaxis]
img_list.append(img)
i += 1
# print(i,'/',len_)
imgs_path = 'work/food-11/testing'
imgs_path_list = os.listdir(imgs_path)
len_ = len(imgs_path_list)
i = 0
for item in imgs_path_list:
img = cv2.imread(os.path.join(imgs_path,item))
img = cv2.resize(img,(img_w,img_h))
img = img[:, :, :, np.newaxis]
img_list.append(img)
i += 1
imgs = np.concatenate(img_list, axis=3)
imgs = imgs.astype(np.float32) / 255.
for i in range(3):
pixels = imgs[:, :, i, :].ravel() # 拉成一行
means.append(np.mean(pixels))
stdevs.append(np.std(pixels))
# BGR --> RGB , CV读取的需要转换,PIL读取的不用转换
means.reverse()
stdevs.reverse()
print("normMean = {}".format(means))
print("normStd = {}".format(stdevs))
# 只需要执行一次代码记录住数据即可
# normMean = [0.5560434, 0.4515875, 0.34473255]
# normStd = [0.27080873, 0.2738704, 0.280732]
normMean = [0.5560434, 0.4515875, 0.34473255]
normStd = [0.27080873, 0.2738704, 0.280732]
# 定义数据预处理
data_transforms = T.Compose([
T.Resize(size=(100, 100)),
T.RandomHorizontalFlip(100),
T.RandomVerticalFlip(100),
T.RandomRotation(90),
T.CenterCrop(100),
T.Transpose(), # HWC -> CHW
T.Normalize(
mean=[0.5560434, 0.4515875, 0.34473255], #归一化 上个模块所求的均值与标准差
std=[0.27080873, 0.2738704, 0.280732],
to_rgb=True)
#计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
第三步 继承paddle.io.Dataset对数据集做处理
对数据集进行处理
class FoodDataset(paddle.io.Dataset):
"""
数据集类的定义
"""
def __init__(self, mode='training_set'):
"""
初始化函数
"""
self.data = []
with open(f'{mode}_set.txt') as f:
for line in f.readlines():
info = line.strip().split('\t')
if len(info) > 0:
self.data.append([info[0].strip(), info[1].strip()])
def __getitem__(self, index):
"""
读取图片,对图片进行归一化处理,返回图片和标签
"""
image_file, label = self.data[index] # 获取数据
img = Image.open(image_file).convert('RGB') # 读取图片
return data_transforms(img).astype('float32'), np.array(label, dtype='int64')
def __len__(self):
"""
获取样本总数
"""
return len(self.data)
train_dataset = FoodDataset(mode='training')
train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=64, shuffle=True, num_workers=0)
eval_dataset = FoodDataset(mode='validation')
val_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=64, shuffle=True, num_workers=0)
# 查看训练和验证集数据的大小
print('train size:', train_dataset.__len__())
print('eval size:', eval_dataset.__len__())
train size: 9866
eval size: 3430
第四步 自行搭建CNN神经网络
# 继承paddle.nn.Layer类,用于搭建模型
class MyCNN(paddle.nn.Layer):
def __init__(self):
super(MyCNN,self).__init__()
self.conv0 = paddle.nn.Conv2D(in_channels=3, out_channels=20, kernel_size=5, padding=0) # 二维卷积层
self.pool0 = paddle.nn.MaxPool2D(kernel_size =2, stride =2) # 最大池化层
self._batch_norm_0 = paddle.nn.BatchNorm2D(num_features = 20) # 归一层
self.conv1 = paddle.nn.Conv2D(in_channels=20, out_channels=50, kernel_size=5, padding=0)
self.pool1 = paddle.nn.MaxPool2D(kernel_size =2, stride =2)
self._batch_norm_1 = paddle.nn.BatchNorm2D(num_features = 50)
self.conv2 = paddle.nn.Conv2D(in_channels=50, out_channels=50, kernel_size=5, padding=0)
self.pool2 = paddle.nn.MaxPool2D(kernel_size =2, stride =2)
self.fc1 = paddle.nn.Linear(in_features=4050, out_features=218) # 线性层
self.fc2 = paddle.nn.Linear(in_features=218, out_features=100)
self.fc3 = paddle.nn.Linear(in_features=100, out_features=11)
def forward(self,input):
# 将输入数据的样子该变成[1,3,100,100]
input = paddle.reshape(input,shape=[-1,3,100,100]) # 转换维读
# print(input.shape)
x = self.conv0(input) #数据输入卷积层
x = F.relu(x) # 激活层
x = self.pool0(x) # 池化层
x = self._batch_norm_0(x) # 归一层
x = self.conv1(x)
x = F.relu(x)
x = self.pool1(x)
x = self._batch_norm_1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.pool2(x)
x = paddle.reshape(x, [x.shape[0], -1])
# print(x.shape)
x = self.fc1(x) # 线性层
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
x = self.fc3(x)
#y = F.softmax(x) # 分类器
return x
network = MyCNN() # 模型实例化
paddle.summary(network, (1,3,100,100)) # 模型结构查看
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[1, 3, 100, 100]] [1, 20, 96, 96] 1,520
MaxPool2D-1 [[1, 20, 96, 96]] [1, 20, 48, 48] 0
BatchNorm2D-1 [[1, 20, 48, 48]] [1, 20, 48, 48] 80
Conv2D-2 [[1, 20, 48, 48]] [1, 50, 44, 44] 25,050
MaxPool2D-2 [[1, 50, 44, 44]] [1, 50, 22, 22] 0
BatchNorm2D-2 [[1, 50, 22, 22]] [1, 50, 22, 22] 200
Conv2D-3 [[1, 50, 22, 22]] [1, 50, 18, 18] 62,550
MaxPool2D-3 [[1, 50, 18, 18]] [1, 50, 9, 9] 0
Linear-1 [[1, 4050]] [1, 218] 883,118
Linear-2 [[1, 218]] [1, 100] 21,900
Linear-3 [[1, 100]] [1, 11] 1,111
===========================================================================
Total params: 995,529
Trainable params: 995,249
Non-trainable params: 280
---------------------------------------------------------------------------
Input size (MB): 0.11
Forward/backward pass size (MB): 3.37
Params size (MB): 3.80
Estimated Total Size (MB): 7.29
---------------------------------------------------------------------------
{'total_params': 995529, 'trainable_params': 995249}
第五步 模型配置以及训练
运行时长: 3小时22分钟19秒5毫秒
# 实例化模型
inputs = paddle.static.InputSpec(shape=[None, 3, 100, 100], name='inputs')
labels = paddle.static.InputSpec(shape=[None, 11], name='labels')
model = paddle.Model(network,inputs,labels)
# 模型训练相关配置,准备损失计算方法,优化器和精度计算方法
# 定义优化器
scheduler = paddle.optimizer.lr.LinearWarmup(
learning_rate=0.001, warmup_steps=100, start_lr=0, end_lr=0.001, verbose=True)
optim = paddle.optimizer.SGD(learning_rate=scheduler, parameters=model.parameters())
# 配置模型
model.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy()
)
visualdl = paddle.callbacks.VisualDL(log_dir='visualdl_log')
# 模型训练与评估
model.fit(
train_loader, # 训练数据集
val_loader, # 评估数据集
epochs=100, # 训练的总轮次
batch_size=128, # 训练使用的批大小
verbose=1, # 日志展示形式
callbacks=[visualdl]) # 设置可视化
# 模型评估
model.evaluate(eval_dataset, batch_size=128, verbose=1)
#已运行,结果太长,已经删除,数据在下图显示
多次运行,在验证集正确率达到0.50-0.55之间
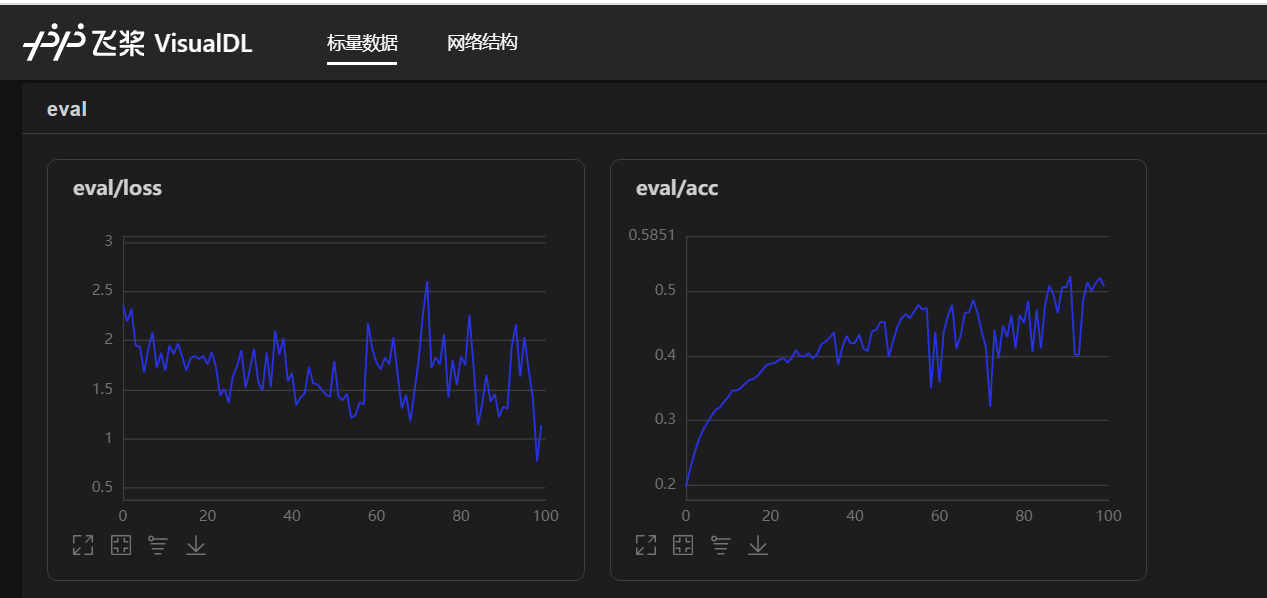
第六步 保存模型
model.save('finetuning/mnist') # 保存模型
第七步 测试集案例展示
def opening(): # 读取图片函数
with open(f'testing_set.txt') as f: #读取文件夹
test_img = []
txt = []
for line in f.readlines(): # 循环读取每一行
img = Image.open(line[:-1]) # 打开图片
img = data_transforms(img).astype('float32')
txt.append(line[:-1]) # 生成列表
test_img.append(img)
return txt,test_img
img_path, img = opening() # 读取列表
from PIL import Image
model_state_dict = paddle.load('finetuning/mnist.pdparams') # 读取模型
model = MyCNN() # 实例化模型
model.set_state_dict(model_state_dict)
model.eval()
site = 10 # 读取图片位置
ceshi = model(paddle.to_tensor(img[site])) # 测试
print('预测的结果为:', np.argmax(ceshi.numpy())) # 获取值
value = ["面包","乳制品","甜点","鸡蛋","油炸食品","肉类","面条/意大利面","米饭","海鲜","汤","蔬菜/水果"]
print(' ', value[np.argmax(ceshi.numpy())])
Image.open(img_path[site]) # 显示图片
预测的结果为: 9
汤

小结
项目还有很大的提升空间
本人的可以说是很垃圾了(仅供学习参考还是不错的)
只有0.5附近
但是根据可视化结果来看
继续训练仍然有很大的提升空间。
我在AI Studio上获得黄金等级,点亮7个徽章,来互关呀~
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/643467

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)