
python虚拟环境搭建YOLO并训练自己的数据集
最近在网上看到YOLO目标检测,感觉很有意思,就尝试去搭建了一下YOLO的环境并训练了自己的一个猫狗的数据集,还是挺有意思的,下面从环境搭建到训练模型进行详细的介绍,由于是第一次接触YOLO,如果有不正确的地方,望指出。
最近在网上看到YOLO目标检测,感觉很有意思,就尝试去搭建了一下YOLO的环境并训练了自己的一个猫狗的数据集,还是挺有意思的,下面从环境搭建到训练模型进行详细的介绍,由于是第一次接触YOLO,如果有不正确的地方,望指出。
一、环境搭建
搭建环境的话我是用了python虚拟环境,且并没有安装pytorch,网上很多教程都是让安装anaconda和pytorch,我并没有安装,直接在python虚拟环境下安装YOLO的库是可以的,所以我感觉并没有必要安装anaconda和pytorch,如果你想利用conda虚拟环境的话,也可以安装anaconda,毕竟易于管理,下面我详细介绍我是如何搭建YOLO的库的。
首先就是python虚拟环境的搭建,在之前的博客中我已经详细的介绍过了,这里就不再赘述,接下来就是进入自己的虚拟环境,并在虚拟环境中输入如下命令:
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
等待下载完成后就可以了。
然后需要再下载一个对数据分配标签的库labeling库,在虚拟环境中输入如下命令:
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
等待下载完成即可。
二、预训练权重的加载和环境测试
首先需要先下载一个yolo的预训练权重,我在网上只找到了yolov8的预训练权重,网站地址:项目文件预览 - YOLOv8预训练权重文件集合:本仓库提供了YOLOv8系列预训练权重文件集合,包括YOLOv8n、YOLOv8s、YOLOv8m、YOLOv8l和YOLOv8x。这些模型在COCO数据集上进行了预训练,适用于目标检测任务。分类模型则在ImageNet数据集上进行了预训练。 - GitCode![]() https://gitcode.com/open-source-toolkit/4b6b9/blob/main/YOLOv8%E9%A2%84%E8%AE%AD%E7%BB%83%E6%9D%83%E9%87%8D%E6%96%87%E4%BB%B6%E9%9B%86%E5%90%88(YOLOv8n,YOLOv8s,YOLOv8m,YOLOv8l,YOLOv8x).zip下载后解压下来,最好解压到环境所在的文件夹中以便使用,解压后得到如下五个文件:
https://gitcode.com/open-source-toolkit/4b6b9/blob/main/YOLOv8%E9%A2%84%E8%AE%AD%E7%BB%83%E6%9D%83%E9%87%8D%E6%96%87%E4%BB%B6%E9%9B%86%E5%90%88(YOLOv8n,YOLOv8s,YOLOv8m,YOLOv8l,YOLOv8x).zip下载后解压下来,最好解压到环境所在的文件夹中以便使用,解压后得到如下五个文件:
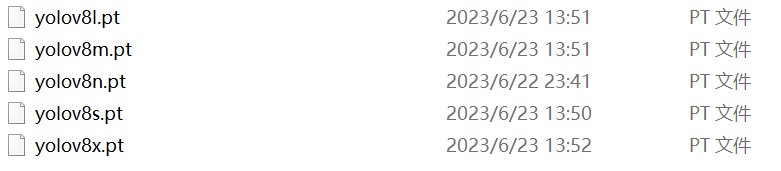
都可以使用,我使用的是yolov8n.pt。
接下来打开pycharm,加载好刚刚创建的虚拟环境后,新建一个python文件,命名为yolo_test(自己可以随意取名字),输入如下代码:
from ultralytics import YOLO
'''这个路径地址是我们刚才下载的预训练权重'''
model= YOLO('D:\openCV\YOLO\pretrain_wight/yolov8n.pt')
'''下面随便选取一张图片,我随便选择了一张狗的图片'''
img_root = 'D:/openCV/data_splited/test/images/flickr_dog_000032.jpg'
#模型检测
model.predict(img_root, save=True)然后运行,的到如下结果:
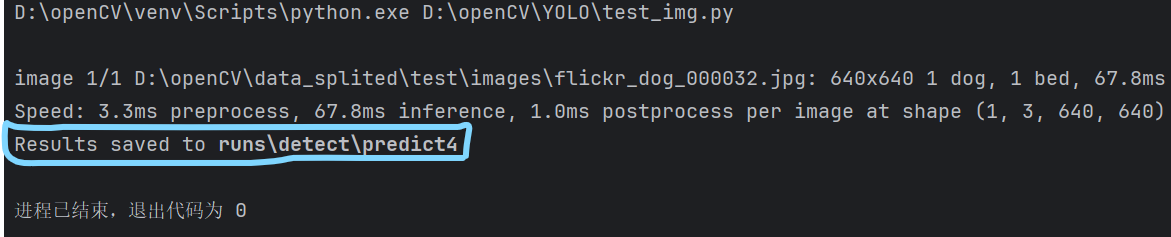
得到上述结果,说明结果被储存下来了,且在run\detect\predict4中,根据这个地址找到这张图片,如下,如果有检测结果说明环境安装成功了。

三、数据集标注和划分
我们已经安装过labelimg了,现在准备好我们的数据集,数据集是一个文件夹,里面有很多图片,我们用labelimg对我们的数据集进行标注,首先依然是进入我们的虚拟环境,在虚拟环境里输入labelimg,如下:
在按下回车之后会弹出如下页面:
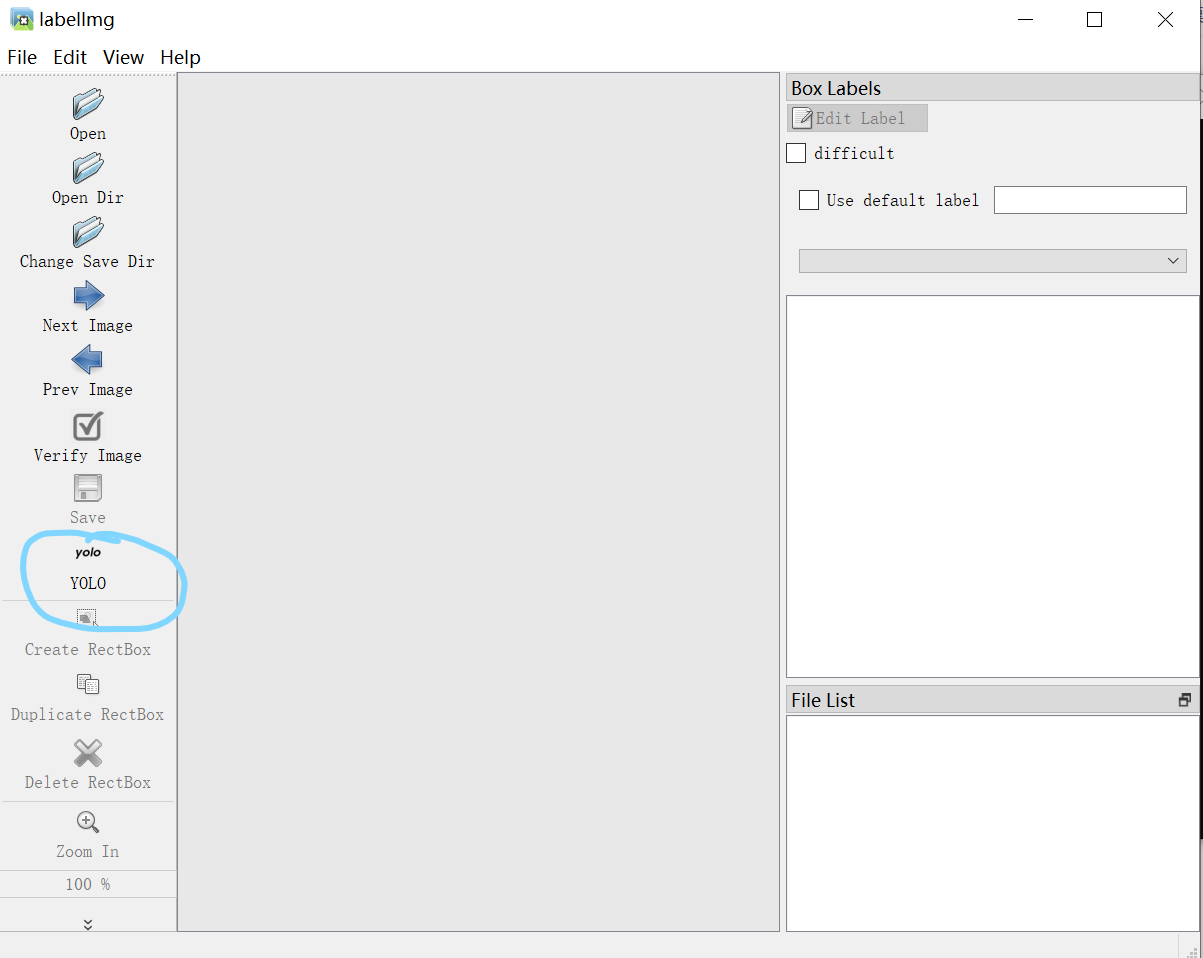
我们点击 Open Dir,然后选择我们存放数据的文件夹,再点击Change Save Dir 来选择存放标签的文件夹(建议跟数据文件夹放在一起)。千万注意要将上述框住的地方选择YOLO,否则标记后的标签是不能使用的。之后我们就可以对图片进行标注了。在这之前,我们可以点击最上面的View来设置自动保存,防止自己辛辛苦苦标记的数据忘记保存的现象,
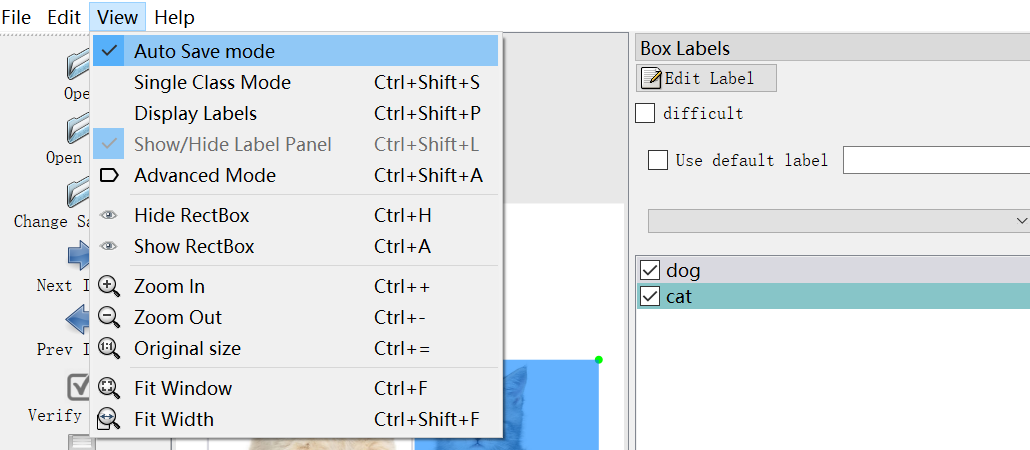
labelimg中有许多快捷键可以加快标记数据,最常用的有三个,快捷键W表示开始标注,标注完成后要对标注的区域设置标签,比如cat或者dog,如下图所示:
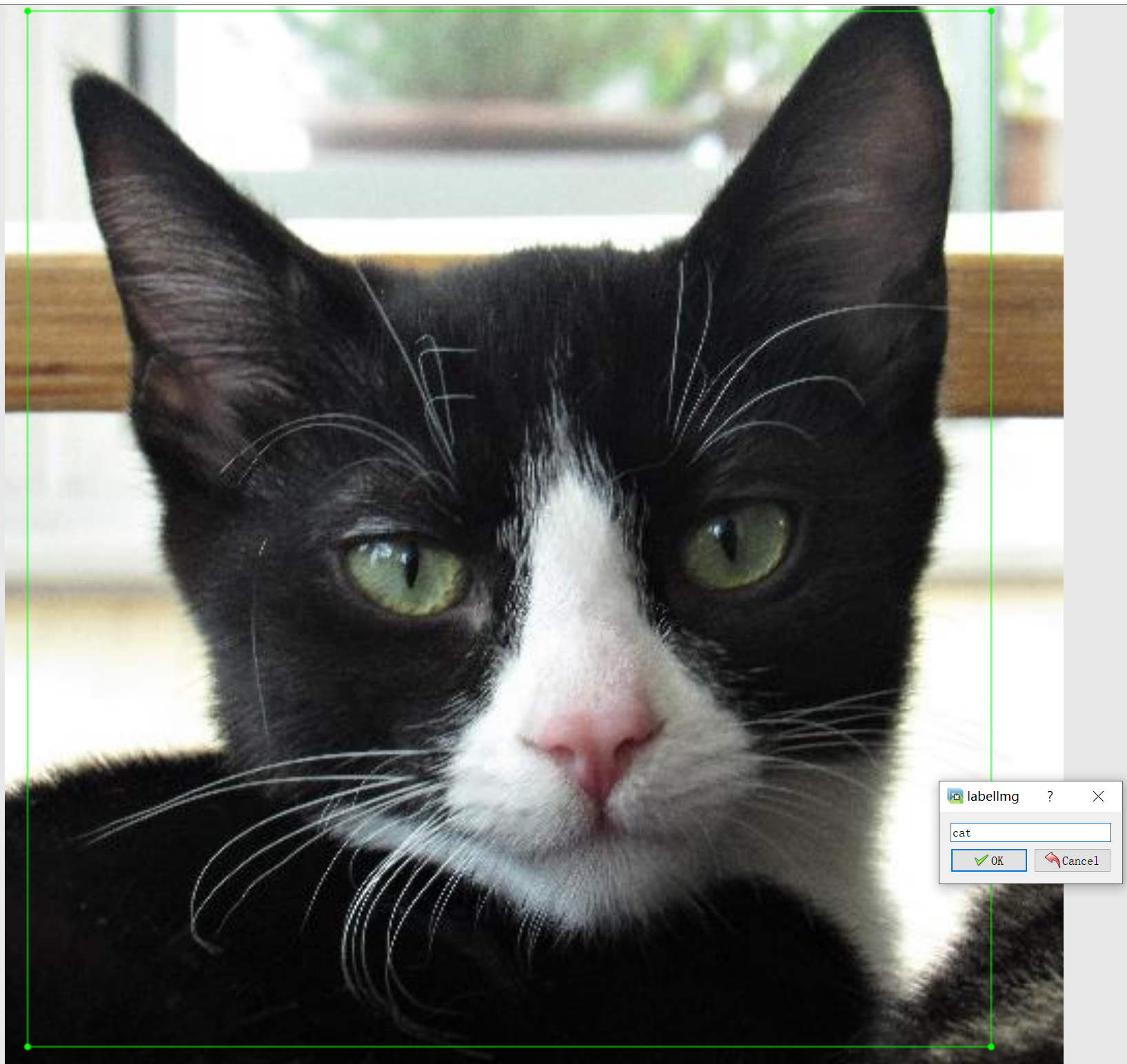
一张图片中也可以标记多个标签,如下图,如下图,同时标记了一个狗和一个猫。
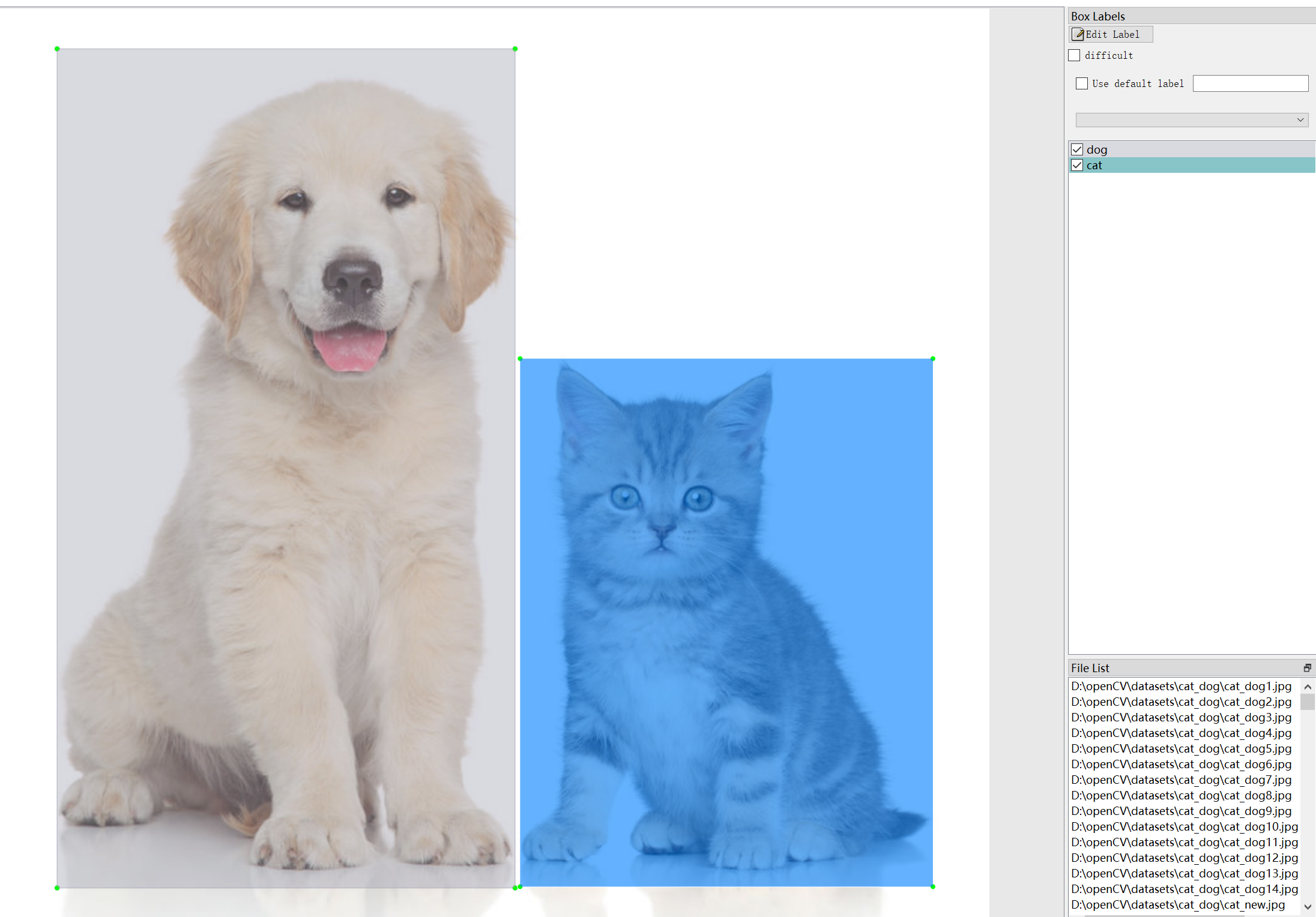
标注完一张图片之后,按快捷键D可以转到下一张图片,快捷键A可以转到上一张图片,按照上述方法对所有图片进行标注。
标注完成后,打开我们存放标签的文件夹,里面应该是很多txt文件,如果不是txt文件,则原因就是没有选择为YOLO标签。在这个文件夹中,有一个classes.txt文件,存放的是你的标签名字,如我标记完后一共有两类,分别是cat和dog,则我的这个文件中就是cat和dog。之后所有的文件就是所有图片对应的标签,里面是对应的类别和坐标数据,如下:

这个表示,这张图片一共有两个区域被标记,第一个属于第0类,后面是桌标,第二个属于第一类,后面跟坐标。这样就完成了我们整个图片的标记
三、数据集的划分
在数据上打上标签后,我们需要将数据划分为训练集、验证集和测试集,我参考了另一篇博客,代码直接放下面,大家注意更改地址,改成自己数据的地址。
# 作者:CSDN-笑脸惹桃花 https://blog.csdn.net/qq_67105081?type=blog
# github:peng-xiaobai https://github.com/peng-xiaobai/Dataset-Conversion
import os
import shutil
import random
# random.seed(0) #随机种子,可自选开启
def split_data(file_path, label_path, new_file_path, train_rate, val_rate, test_rate):
images = os.listdir(file_path)
labels = os.listdir(label_path)
images_no_ext = {os.path.splitext(image)[0]: image for image in images}
labels_no_ext = {os.path.splitext(label)[0]: label for label in labels}
matched_data = [(img, images_no_ext[img], labels_no_ext[img]) for img in images_no_ext if img in labels_no_ext]
unmatched_images = [img for img in images_no_ext if img not in labels_no_ext]
unmatched_labels = [label for label in labels_no_ext if label not in images_no_ext]
if unmatched_images:
print("未匹配的图片文件:")
for img in unmatched_images:
print(images_no_ext[img])
if unmatched_labels:
print("未匹配的标签文件:")
for label in unmatched_labels:
print(labels_no_ext[label])
random.shuffle(matched_data)
total = len(matched_data)
train_data = matched_data[:int(train_rate * total)]
val_data = matched_data[int(train_rate * total):int((train_rate + val_rate) * total)]
test_data = matched_data[int((train_rate + val_rate) * total):]
# 处理训练集
for img_name, img_file, label_file in train_data:
old_img_path = os.path.join(file_path, img_file)
old_label_path = os.path.join(label_path, label_file)
new_img_dir = os.path.join(new_file_path, 'train', 'images')
new_label_dir = os.path.join(new_file_path, 'train', 'labels')
os.makedirs(new_img_dir, exist_ok=True)
os.makedirs(new_label_dir, exist_ok=True)
shutil.copy(old_img_path, os.path.join(new_img_dir, img_file))
shutil.copy(old_label_path, os.path.join(new_label_dir, label_file))
# 处理验证集
for img_name, img_file, label_file in val_data:
old_img_path = os.path.join(file_path, img_file)
old_label_path = os.path.join(label_path, label_file)
new_img_dir = os.path.join(new_file_path, 'val', 'images')
new_label_dir = os.path.join(new_file_path, 'val', 'labels')
os.makedirs(new_img_dir, exist_ok=True)
os.makedirs(new_label_dir, exist_ok=True)
shutil.copy(old_img_path, os.path.join(new_img_dir, img_file))
shutil.copy(old_label_path, os.path.join(new_label_dir, label_file))
# 处理测试集
for img_name, img_file, label_file in test_data:
old_img_path = os.path.join(file_path, img_file)
old_label_path = os.path.join(label_path, label_file)
new_img_dir = os.path.join(new_file_path, 'test', 'images')
new_label_dir = os.path.join(new_file_path, 'test', 'labels')
os.makedirs(new_img_dir, exist_ok=True)
os.makedirs(new_label_dir, exist_ok=True)
shutil.copy(old_img_path, os.path.join(new_img_dir, img_file))
shutil.copy(old_label_path, os.path.join(new_label_dir, label_file))
print("数据集已划分完成")
if __name__ == '__main__':
file_path = r"f:\data\JPEGImages" # 图片文件夹
label_path = r'f:\data\labels' # 标签文件夹
new_file_path = r"f:\VOCdevkit" # 新数据存放位置
split_data(file_path, label_path, new_file_path, train_rate=0.8, val_rate=0.1, test_rate=0.1)在运行完上述代码后,会在指定的文件夹形成为三个文件夹,分别为train、val、test,里面分别都有image和label,这样数据集就划分完成了。
四、训练模型
在训练模型之前,我们需要先创建一个.yaml文件来存放我们的数据地址和一些必要的参数,先创建一个文本文件,在里面输入如下代码,并根据自己的数据进行更改,更改完成后把后缀改成.yaml。
train: D:\openCV\data_splited\train\images
val: D:\openCV\data_splited\val\images
test: D:\openCV\data_splited\test\images
nc: 2
# Classes
names: ['cat','dog']然后再创建一个python文件,命名为main,然后输入下面的代码,进行训练
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/v8/yolov8n.yaml')#用了yolov8
model.load('D:\openCV\YOLO\pretrain_wight/yolov8n.pt') #这个为预训练权重的路径
model.train(data='D:\openCV\YOLO\data.yaml', #这个填刚才创建的.yaml文件的路径
imgsz=512,#将图片归为512*512的
epochs=16,
batch=64,
workers=8,
device='cpu', #没显卡则将0修改为'cpu'
optimizer='SGD',
amp = False,
cache=False, #服务器可设置为True,训练速度变快
)
训练完成后,会得到一个run\detect\train文件夹,里面会保存训练的权重和一些训练过程。
五、模型测试
from ultralytics import YOLO
# 加载训练好的模型,改为自己的路径
model = YOLO('D:/openCV/YOLO/runs/detect/train2/weights/best.pt')
'''随便选取一张目送或者狗的图片,我选择了一张狗'''
img_root = 'D:/openCV/data_splited/test/images/flickr_dog_000032.jpg'
# 运行推理,并附加参数
model.predict(img_root, save=True)测试结果如下所示:

希望这篇文章能够对你有所帮助。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 35
35 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)