
基于K近邻算法的分类器的实现
实现了一个基于KNN的简单分类器,通过标准化处理提高了模型的稳定性,并通过计算欧几里得距离进行分类预测,预测出海伦对约会对象喜好程度,便于平台准确推送。
基于K近邻算法的分类器的实现
一、问题引入
海伦一直使用在线约会网站寻找适合自己的约会对象。她曾交往过三种类型的人:
- 不喜欢的人
- 一般喜欢的人
- 非常喜欢的人
这些人包含以下三种特征
- 每年获得的飞行常客里程数
- 玩视频游戏所耗时间百分比
- 每周消费的冰淇淋公升数
该网站现在需要尽可能向海伦推荐她喜欢的人,需要我们设计一个分类器,根据用户的以上三种特征,识别出是否该向海伦推荐。
二、需求概要分析
根据问题,我们可知,样本特征个数为3,样本标签为三类。现需要实现将一个待分类样本的三个特征值输入程序后,能够识别该样本的类别,并且将该类别输出。
三、程序结构设计说明
根据问题,可以知道程序大致流程如下。
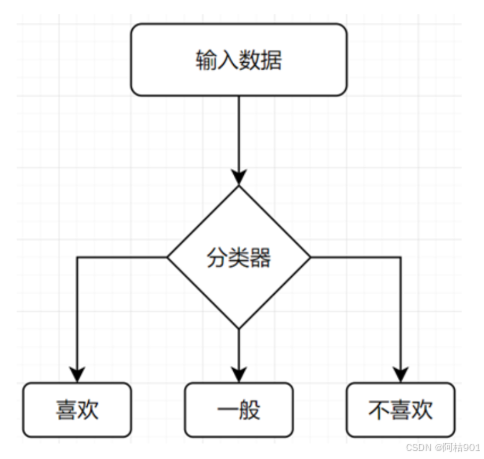
其中输入数据应包含三个值,输出应为喜欢,一般,不喜欢,三个中的一个。
四、K近邻算法的一般流程及代码实现
- 数据准备 : 这包括收集、清洗和预处理数据。预处理可能包括归一化或标准化特征,以确保所有特征在计算距离时具有相等的权重。
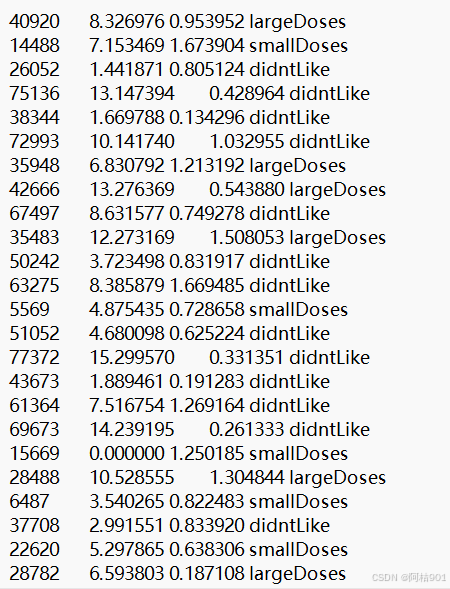
| 玩视频游戏所耗时间百分比 | 每年获得的飞行常客里程数 | 每周消费的冰淇淋的公升数 | 样本分类 | |
|---|---|---|---|---|
| 1 | 0.8 | 400 | 0.5 | 1 |
| 2 | 12 | 134000 | 0.9 | 3 |
| 3 | 0 | 20000 | 1.1 | 2 |
| 4 | 67 | 32000 | 0.1 | 2 |
我们很容易发现,当计算样本之间的距离时数字差值最大的属性对计算结果的影响最大,也就是说,
每年获取的飞行常客里程数对于计算结果的影响将远远大于上表中其他两个特征-玩视频游戏所耗时间占比和每周消费冰淇淋公斤数的影响。
而产生这种现象的唯一原因,仅仅是因为飞行常客里程数远大于其他特征值。
但海伦认为这三种特征是同等重要的,因此作为三个等权重的特征之一,飞行常客里程数并不应该如此严重地影响到计算结果。
在处理这种不同取值范围的特征值时,我们通常采用的方法是将数值归一化,如将取值范围处理为0到1或者-1到1之间。
下面的公式可以将任意取值范围的特征值转化为0到1区间内的值:
v n e w = ( v o l d − v m i n ) ( v m a x − v m i n ) v_{new}=(v_{old}-v_{min})(v_{max}-v_{min}) vnew=(vold−vmin)(vmax−vmin)
#导入数据文本
data_file = r"C:\Users\ASUS\Downloads\datingTestSet.txt"
data = pd.read_csv(data_file, header=None, delim_whitespace=True)
data.columns = ['VideoGame', 'Miles', 'IceCream', 'Label']
#数据预处理
# 将类别标签 'largeDoses', 'smallDoses', 'didntLike' 转换为数字便于训练
label_map = {'largeDoses': 1, 'smallDoses': 2, 'didntLike': 3}
data['Label'] = data['Label'].map(label_map)
# 分割数据为特征和类别
X = data[['VideoGame', 'Miles', 'IceCream']] # 特征
y = data['Label'] # 类别
# 数据均一化
X_scaled = (X - X.mean()) / X.std()
- 选择距离度量方法 :确定用于比较样本之间相似性的度量方法,常见的如欧几里得距离、曼哈顿距离等。
# 计算欧几里得距离
def euclidean_distance(x1, x2):
"""计算两个样本之间的欧几里得距离"""
return np.sqrt(np.sum((x1 - x2) ** 2))
- 确定K值 : 即在分类或回归时应考虑的邻居数量。这是一个超参数,可以通过交叉验证等方法来选择最优的K值。
#这里选择常用的k值3
# 使用K近邻进行预测
y_pred = knn_predict(X_scaled, y, X_scaled, k=3)
- 找到K个最近邻居 :对于每一个需要预测的未标记的样本:
- 计算该样本与训练集中所有样本的距离。
- 根据距离对它们进行排序。
- 选择距离最近的K个样本
# K近邻分类器
def knn_predict(X_train, y_train, X_test, k=3):
predictions = []
for test_sample in X_test:
# 计算该样本与训练集中所有样本的距离
distances = [euclidean_distance(test_sample, train_sample) for train_sample in X_train]
# 根据距离对它们进行排序。
k_neighbors_indices = np.argsort(distances)[:k]
# 选择距离最近的K个样本
k_neighbors_labels = y_train[k_neighbors_indices]
# 使用多数投票法确定预测类别
most_common = Counter(k_neighbors_labels).most_common(1)[0][0]
predictions.append(most_common)
return np.array(predictions)
- 预测:
- 对于分类任务:查看K个最近邻居中最常见的类别,作为预测结果。例如,如果K=3,并且三个最近邻居的类别是[1, 2, 1],那么预测结果就是类别1。
- 对于回归任务:预测结果可以是K个最近邻居的平均值或加权平均值。
# 使用K近邻进行预测
y_pred = knn_predict(X_scaled, y, X_scaled, k=3)
# 打印每个样本的预测结果和真实结果
inv_label_map = {v: k for k, v in label_map.items()}
for i in range(len(y)):
predicted_class = y_pred[i]
actual_class = y[i]
predicted_class_name = inv_label_map[predicted_class]
actual_class_name = inv_label_map[actual_class]
print(f"Sample {i + 1}: Predicted = {predicted_class_name}, Actual = {actual_class_name}")
- 评估 : 使用适当的评价指标(如准确率、均方误差等)评估模型的性能。
# 计算准确率
accuracy = np.mean(y_pred == y)
print(f"Overall model accuracy: {accuracy * 100:.2f}%")
# 用户输入并预测模块
def predict_likes_chengdu():
# 提示用户输入特征信息
video_game = float(input("输入玩视频游戏所耗时间百分比: "))
miles = float(input("输入每年获得的飞行常客里程数: "))
ice_cream = float(input("输入每周消费的冰淇淋公升数: "))
# 将输入的特征进行标准化
user_data = [[video_game, miles, ice_cream]]
user_data_scaled = (np.array(user_data) - X.mean(axis=0)) / X.std(axis=0)
# 预测用户是否喜欢
prediction = knn_predict(X_scaled, y, user_data_scaled, k=3)
# 显示预测结果
inv_label_map = {v: k for k, v in label_map.items()}
predicted_class_name = inv_label_map[prediction[0]]
print(f"预测的喜欢程度: {predicted_class_name}")
# 调用
predict_likes_chengdu()
- 优化 : 基于性能评估结果,返回并调整某些参数,如K值、距离度量方法等,以获得更好的性能。
当K值很小时,模型可能会过拟合,如下图k=1时
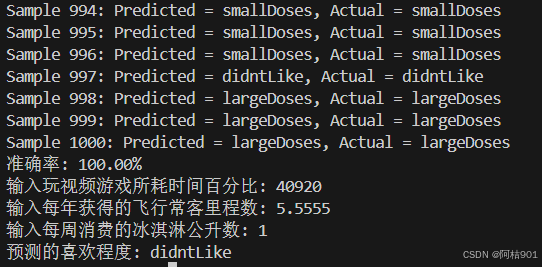
k=5
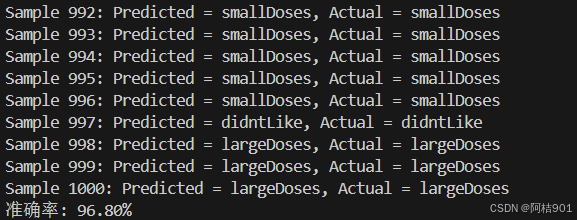
k=7
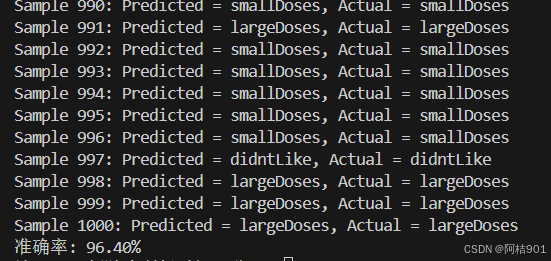
k=10
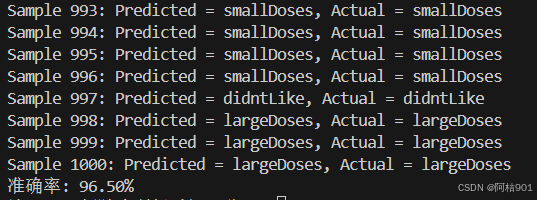
五、总结
实现了一个基于KNN的简单分类器,通过标准化处理提高了模型的稳定性,并通过计算欧几里得距离进行分类预测,预测出海伦对约会对象喜好程度,便于平台准确推送。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 39
39 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)