
python爬虫入门——Selenium
如果你的学习方向和我一样是大模型,在模型微调的过程中必然需要大量的数据,学会使用爬虫会非常有用。如果你是做电商的或是正在求职,那么学会使用爬虫也能帮助你快速找到你需要的信息。 亦或者你学习爬虫是有其他需求,我也希望这篇文章能帮助完成它。
前言
如果你的学习方向和我一样是大模型,在模型微调的过程中必然需要大量的数据,学会使用爬虫会非常有用。如果你是做电商的或是正在求职,那么学会使用爬虫也能帮助你快速找到你需要的信息。 亦或者你学习爬虫是有其他需求,我也希望这篇文章能帮助完成它。
python简易图片爬虫(基于requests而非selenium)-CSDN博客
上面是之前写过的图片爬虫,用的是request库,一个非常简单且标准的库,不过我写的比较简陋。我个人感觉Selenium要更加好用一些,现在我写爬虫也都是用Selenium了。恰好学校开了信息安全的课,要求编写爬虫爬取网页,所以想着顺便把学习成果整理出来分享给大家。
好了废话少说我们开始吧。
环境部署
网上有很多安装教程,在这里我就简单带您过一下好了。使用pip安装对应的库:
pip install selenium安装完对应的库之后我们还需要安装一个Webdriver,即浏览器驱动。这个驱动相当于一个浏览器的“壳”,Selenium无法直接打开你电脑的浏览器,而是通过这个与浏览器别无二致的“壳”来进行爬取操作的。下面是Edge和Google浏览器的驱动下载的网址:
Edge:Microsoft Edge WebDriver | Microsoft Edge Developer
Google:下载内容 | ChromeDriver | Chrome for Developers
在网页中找到合适自己电脑的版本下载之后,将 Webdriver放到解释器的目录下就可以了。
基础操作
下面我会为您演示Selenium的一些常用的基础操作:
导入Selenium并打开浏览器:
from selenium import webdriver
driver = webdriver.Edge()使用浏览器打开某个网页:
URL = r"https://blog.csdn.net/Ceverymxt7"
driver.get(URL)最大化/最小化窗口:
driver.maximize_window()
driver.minimize_window()等待网页加载:
driver.implicitly_wait(10) # 单位:秒定位网页中的某个元素:
from selenium.webdriver.common.by import By
driver.find_element(By.CSS_SELECTOR, "使用F12查看源码来复制元素的css帖到这里来吧")查找失败会报错。这里有多种方式定位,我常用的是CSS SELECTOR,定位方式如下:

其他定位方式也类似。
点击某个元素:
driver.find_element(By.CSS_SELECTOR, "元素位置").click()获取这个元素的文本内容:
str_info = driver.find_element(By.CSS_SELECTOR, "元素位置").text向文本框输入信息:
txt = "你想要输入什么内容呢?"
driver.find_element(By.CSS_SELECTOR, f"元素位置").send_keys(txt)在iframe框架和默认框架间切换:
driver.switch_to.frame(iframe)
driver.switch_to.default_content()(有的时候元素被设计在iframe框架中,你需要先切换才能定位到它们)
模拟鼠标滚动:
driver.execute_script('window.scrollBy(-20,1150)')-20代表向左滚动20个像素,1150代表向下滚动1150个像素,有的时候页面的元素需要随着你的鼠标的滚动才能加载出来。
返回上一级网页:
driver.back()更多内容请查看官方文档:入门指南 | Selenium
实践环节
一:爬取“https://www.ndss-symposium.org/ndss2024/accepted-papers”中的所有作者和文章标题,存入名为NDSS2024.xlsx的文件中
我们先打开网页看看:
import time
from selenium import webdriver
driver = webdriver.Edge()
driver.maximize_window()
driver.get("https://www.ndss-symposium.org/ndss2024/accepted-papers/")
time.sleep(1000)打开网页之后发现是一个关于论文的网站,陈列了一百多篇论文。文章的标题和作者在封面就能看到,但是不知道为什么我的定位器定位不到它们,还好点进去之后就能定位到了。
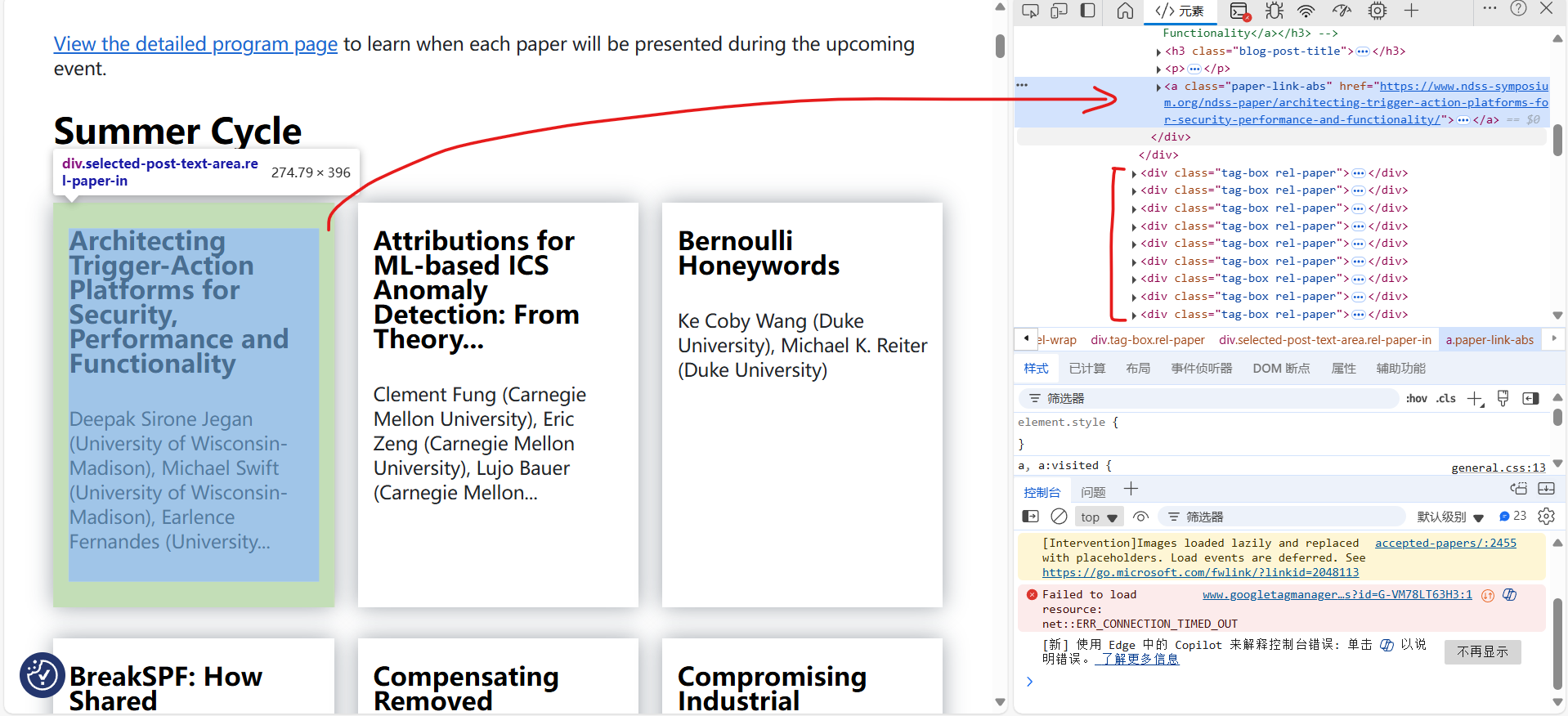
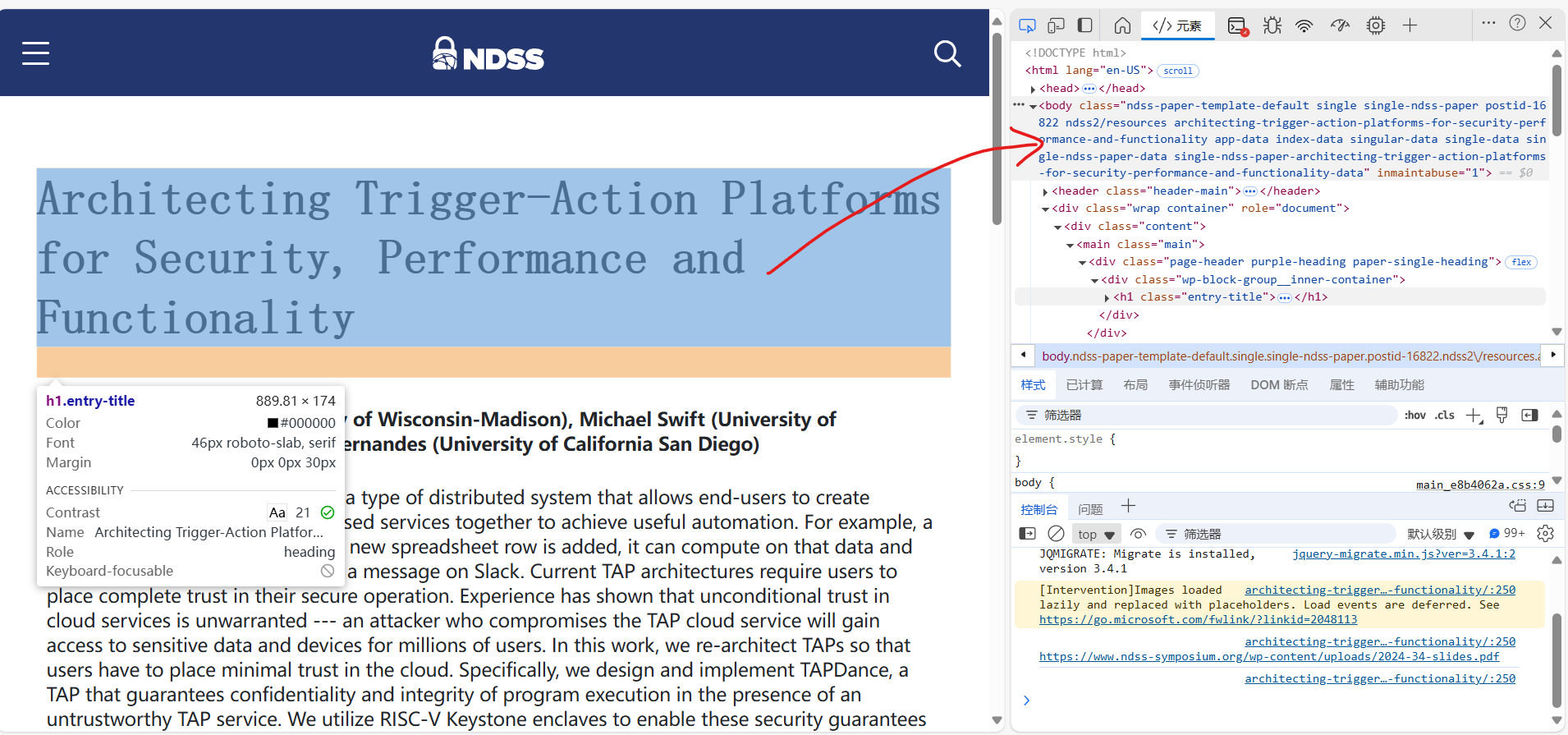
所以我们的思路如下:打开网页——点击文章进入下一级网页——爬取作者及标题信息写入xlsx——放回上一级并继续爬取下一篇,重复。这里有一个问题,就是我们可以通过定位器定位第一篇论文的位置,那么在爬取完第一篇的信息并返回来之后,怎么定位第二篇论文的位置呢,难道要我们一个一个定位过去吗?当然不用!我们来看第一篇和第二篇论文的css定位结果:
一:
body > div.wrap.container > div > main > section > div.wp-block-group.fixed-width.fixed-1110.section-padding.section-title-h.summer-circle.is-layout-flow.wp-block-group-is-layout-flow > div > div > div:nth-child(1) > div > a
二:
body > div.wrap.container > div > main > section > div.wp-block-group.fixed-width.fixed-1110.section-padding.section-title-h.summer-circle.is-layout-flow.wp-block-group-is-layout-flow > div > div > div:nth-child(2) > div > a
你发现了嘛?这两篇文章的定位器只有一个数字的差异,所以我们可以通过构造一个字符串的形式来定位所有的文章!
代码如下(xlsx读写的部分我就不赘述了哈):
import openpyxl
from selenium import webdriver
from selenium.webdriver.common.by import By # 寻找元素
excel_path = r"NDSS2024.xlsx"
workbook1 = openpyxl.load_workbook(excel_path)
sheet1 = workbook1['Sheet1']
sheet1["A1"] = "文章标题"
sheet1["B1"] = "作者"
driver = webdriver.Edge()
driver.maximize_window()
driver.get("https://www.ndss-symposium.org/ndss2024/accepted-papers/")
# part1
try:
for i in range(100000): # 没数
driver.find_element(By.CSS_SELECTOR,
f"body > div.wrap.container > div > main > section > div.wp-block-group.fixed-width.fixed-1110.section-padding.section-title-h.summer-circle.is-layout-flow.wp-block-group-is-layout-flow > div > div > div:nth-child({i + 1}) > div > a").click()
sheet1[f"A{i + 2}"] = driver.find_element(By.CSS_SELECTOR,
f"body > div.wrap.container > div > main > div > div > h1").text
sheet1[f"B{i + 2}"] = driver.find_element(By.CSS_SELECTOR,
f"body > div.wrap.container > div > main > section.new-wrapper.paper-single > article > div > div.paper-data > p:nth-child(2) > strong").text
driver.back()
workbook1.save(excel_path)
except Exception as e:
print(e)
workbook1.save(excel_path)运行之后,发现xlsx中只有41篇论文,怎么回事呢?我又去看了看原网页:
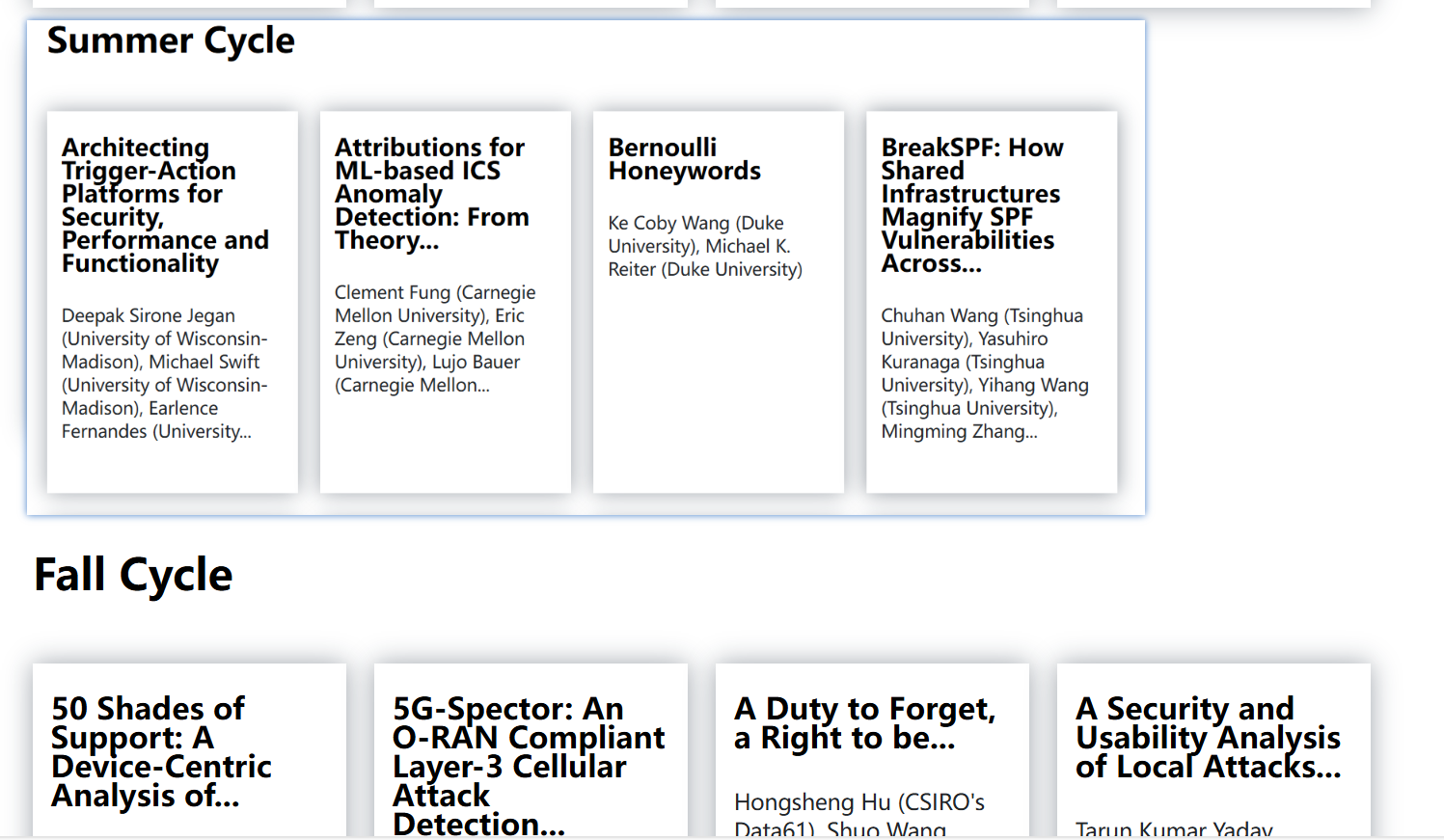
发现原来论文分成了两部分,我们只爬取了第一部分,所以才只有41条数据,不过没关系,我们有了之前的经验,只需要对代码稍加修改就可以对第二部分进行爬取了。
完整代码如下:
import openpyxl
from selenium import webdriver
from selenium.webdriver.common.by import By # 寻找元素
essay_num1 = 41 # 文章数量,亦即for循环次数,复制最后一篇文章的selector就知道了
essay_num2 = 99
excel_path = r"NDSS2024.xlsx"
workbook1 = openpyxl.load_workbook(excel_path)
sheet1 = workbook1['Sheet1']
sheet1["A1"] = "文章标题"
sheet1["B1"] = "作者"
driver = webdriver.Edge()
driver.maximize_window()
driver.get("https://www.ndss-symposium.org/ndss2024/accepted-papers/")
# part1
try:
for i in range(essay_num1):
driver.find_element(By.CSS_SELECTOR,
f"body > div.wrap.container > div > main > section > div.wp-block-group.fixed-width.fixed-1110.section-padding.section-title-h.summer-circle.is-layout-flow.wp-block-group-is-layout-flow > div > div > div:nth-child({i + 1}) > div > a").click()
sheet1[f"A{i + 2}"] = driver.find_element(By.CSS_SELECTOR,
f"body > div.wrap.container > div > main > div > div > h1").text
sheet1[f"B{i + 2}"] = driver.find_element(By.CSS_SELECTOR,
f"body > div.wrap.container > div > main > section.new-wrapper.paper-single > article > div > div.paper-data > p:nth-child(2) > strong").text
driver.back()
workbook1.save(excel_path)
except Exception as e:
print(e)
workbook1.save(excel_path)
# part2
try:
for i in range(essay_num2):
driver.find_element(By.CSS_SELECTOR,
f"body > div.wrap.container > div > main > section > div.wp-block-group.fixed-width.fixed-1110.section-padding.fall-circle.padding-top-0.section-title-h.is-layout-flow.wp-block-group-is-layout-flow > div > div > div:nth-child({i + 1}) > div > a").click()
sheet1[f"A{i + 2 + essay_num1}"] = driver.find_element(By.CSS_SELECTOR,
f"body > div.wrap.container > div > main > div > div > h1").text
sheet1[f"B{i + 2 + essay_num1}"] = driver.find_element(By.CSS_SELECTOR,
f"body > div.wrap.container > div > main > section.new-wrapper.paper-single > article > div > div.paper-data > p:nth-child(2) > strong").text
driver.back()
workbook1.save(excel_path)
except Exception as e:
print(e)
workbook1.save(excel_path)
二:爬取“https://book.douban.com/top250”中的豆瓣评分前250的书籍标题、主要信息、评分、总结等信息(注意需要爬取250本书籍),存入doubanBookTop250.csv文档中。
我们先打开网页看看,但是一打开就发现网页提示我们要登陆,那怎么办呢?我们的爬虫再厉害也没办法实现登陆的功能呀。既然爬虫登陆不了,我们就在打开网页之后,可以先不着急运行后面的脚本,使用time.sleep(X)留点时间给自己手动登陆,然后再运行脚本。但是要留多少时间呢?留的少了来不及登陆就开始执行后面的脚本,然后触发报错了,留的多了有很浪费时间。
我们换一种思维来看,我们的目的是登陆网页,在登陆之后能够看到很多登陆前没有的元素,那么我可以使脚本直到看见这个元素之前都不运行,一看到这个脚本之后就开始运行呀。
while True: # 快登录呀
try:
driver.find_element(By.CSS_SELECTOR, "登陆后才能看到的元素")
break
except:
pass这样我们就实现了使脚本等待我们登陆的功能。登陆后的操作也是和前一个任务差不多了:点击某一书籍——爬取书籍信息——返回上一级,重复。完整代码如下:
import openpyxl
from selenium import webdriver
from selenium.webdriver.common.by import By # 寻找元素
excel_path = r"doubanBookTop250.xlsx"
workbook1 = openpyxl.load_workbook(excel_path)
sheet1 = workbook1['Sheet1']
sheet1["A1"] = "书名"
sheet1["B1"] = "书籍信息"
sheet1["C1"] = "评分"
sheet1["D1"] = "内容简介"
driver = webdriver.Edge()
driver.maximize_window()
driver.get("https://book.douban.com/top250")
while True: # 快登录呀
try:
driver.find_element(By.CSS_SELECTOR, "#db-nav-book > div.nav-wrap > div > div.nav-logo > a")
break
except:
pass
for i in range(250): # 差不多每100本要重新加载一次
driver.get(f"https://book.douban.com/top250?start={i}")
driver.implicitly_wait(1)
driver.find_element(By.CSS_SELECTOR,
f"#content > div > div.article > div > table:nth-child(2) > tbody > tr > td:nth-child(2) > div.pl2 > a").click()
sheet1[f"A{i + 2}"] = driver.find_element(By.CSS_SELECTOR, f"#wrapper > h1 > span").text
sheet1[f"B{i + 2}"] = driver.find_element(By.CSS_SELECTOR, f"#info").text
sheet1[f"C{i + 2}"] = driver.find_element(By.CSS_SELECTOR,
f"#interest_sectl > div > div.rating_self.clearfix > strong").text
try:
sheet1[f"D{i + 2}"] = driver.find_element(By.CSS_SELECTOR, f"#link-report > span.short > div").text
except:
try:
sheet1[f"D{i + 2}"] = driver.find_element(By.CSS_SELECTOR, f"#link-report > div > div").text
except:
sheet1[f"D{i + 2}"] = "豆瓣暂无简介"
workbook1.save(excel_path)
你可以看到我的代码中使用了大量的try语句,这是必要的,因为在实际的应用中网页环境的复杂多变的,你必须不断地使用try语句捕获异常并处理它们,久而久之,你也就会变成爬虫高手啦。
最后
希望你在学有所成之后依旧秉持维护良好的网络环境的意识,不滥用爬虫技术,恶意向网站发起攻击,或是爬取私密信息。希望本文对你学习python爬虫有帮助,有任何问题可以向作者提出。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)