
python cubes逻辑模型和元数据(靠google翻译+个别术语调整)
逻辑模型和元数据逻辑模型从用户或分析人员的角度描述数据:记录如何测量,汇总和报告数据。模型独立于数据的物理实现。这种物理上的独立性使得更容易专注于数据,而不是专注于如何以易于理解的形式获取数据的方式。也可以介绍逻辑模型使用户能够:从业务角度看数据隐藏数据的物理结构(“应用程序的使用方式”)指定属性的概念层次结构,例如:产品类别>产品>子类别>产品国家>地区>县>
逻辑模型和元数据
逻辑模型从用户或分析人员的角度描述数据:记录如何测量,汇总和报告数据。模型独立于数据的物理实现。这种物理上的独立性使得更容易专注于数据,而不是专注于如何以易于理解的形式获取数据的方式。
也可以
介绍
逻辑模型使用户能够:
-
从业务角度看数据
-
隐藏数据的物理结构(“应用程序的使用方式”)
-
指定属性的概念层次结构,例如:
- 产品类别>产品>子类别>产品
- 国家>地区>县>城镇。
-
提供更多描述性的属性标签以显示在应用程序或报告中
-
元数据和数据的透明本地化
分析师或报告作者不必知道组织或类别名称的存储位置,也不必关心客户数据是存储在单个表中还是分布在多个表(客户,客户类型等)中。他们只要求提供customer.name或category.code。
除了物理模型上的抽象外,还包括本地化抽象。在多语言环境中工作时,仅需编写报告/查询的一种版本,可以根据需要切换语言环境。如果请求“合同类型名称”,分析人员只需编写constract_type.name即可,而Cubes框架会考虑值的适当本地化。
示例:分析师希望按地理位置报告合同金额,该地理位置有两个级别:国家级别和地区级别。在原始物理数据库中,地理信息已规范化并存储在两个单独的表中,一个表用于国家/地区,另一表用于地区。分析师不必知道数据存储在哪里,他只需查询geography.country和/或 geography.region即可获取正确的数据。下图显示了如何完成此操作:
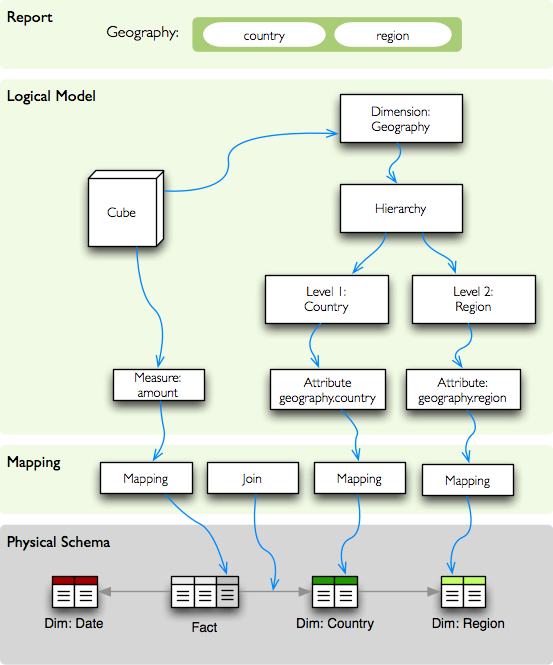
从逻辑模型到物理数据的映射。
逻辑模型描述了维度地理,其中默认层次结构具有两个级别:country和region。每个级别可以具有更多属性,例如代码,名称,人口...在我们的示例报告中,我们仅对地理名称感兴趣,即:country.name和region.name。
模型(Model)
使用模型元数据字典描述逻辑模型。内容是逻辑对象,物理存储和其他附加信息的描述。

逻辑模型元数据
模型说明的逻辑部分:
name- 型号名称label–可读模型标签(可选)description–模型的可读描述(可选)locale–写入模型元数据的语言环境(可选,用于可本地化的模型)cubes–多维数据集元数据列表(见下文)dimensions–维度元数据列表(请参见下文)
模型说明的物理部分:
store–存储模型的多维数据集的数据存储的名称。默认值为default。有关更多信息,请参见分析工作区。mappings-特定于后端的逻辑到物理映射字典。该字典由模型中的每个多维数据集继承。joins-特定于后端的连接规范(例如在SQL后端中使用)。它应该是词典列表。该列表由模型中的多维数据集继承。browser_options–传递给浏览器的选项。选项与多维数据集中的选项合并。
模型片段示例:
{
"name": "public_procurements",
"label": "Public Procurements of Slovakia",
"description": "Contracts of public procurement winners in Slovakia"
"cubes": [...]
"dimensions": [...]
}
映射和联接(Mappings and Joins)
可以指定共享映射并在模型级别上进行联接。这些映射和联接被模型中的所有多维数据集继承。
mappigns多维数据集的字典与模型的全局映射字典合并。多维数据集的值将覆盖模型的值。
该joins可视为命名模板。它们应包含 name将由多维数据集引用的属性。
可见性:联接和映射对于单个模型而言是本地的。它们不在工作空间内共享。
继承(Inheritance)
模型中的多维数据集将继承该模型的映射并进行联接。以多维数据集的映射替换具有相同名称的现有模型的映射的方式合并映射。连接按其名称串联或合并。
SQL后端的示例:假设您要将日期维度表加入dim_date每个多维数据集。然后,您在模型级别将联接指定为:
"joins": [
{
"name": "date",
"detail": "dim_date.date_id",
"method": "match"
}
]联接具有指定的名称,该名称用于匹配多维数据集中的联接。请注意,联接包含不完整的信息:它仅包含detail 部分,即维度健(dimession key)。要在具有两个日期维的开始日期和结束日期的多维数据集中使用联接,请执行以下操作:
"joins": [
{
"name": "date",
"master": "fact_contract.contract_start_date_id",
},
{
"name": "date",
"master": "fact_sales.contract_sign_date_id",
}
]
在模型的联接中搜索具有给定名称的模板,然后多维数据集完成(甚至替换)联接信息。
文件表示
该模型可以表示为JSON文件或带有JSON文件的目录。单文件模型规范只是具有模型属性的字典。模型目录捆绑软件应具有以下内容:
model.json–模型的主元数据–与单文件模型相同dim_*.json–维元数据文件–单维字典cube_*.json–多维数据集元数据–单个多维数据集字典
中的维度和多维数据集列表model.json与单独文件中的维度和多维数据集合并。避免重复定义。
示例目录捆绑模型:
model.cubesmodel /
model.json
dim_date.json
dim_organization.json
dim_category.json
cube_contracts.json
cube_events.json
模型提供者和外部模型
如果模型是从外部来源(例如API或数据库)提供的,则应该在中指定提供者的名称provider。
提供者接收模型的元数据和模型的数据存储(如果提供者愿意)。然后,提供程序将生成所有多维数据集和维度。
由外部来源(Mixpanel)提供的模型示例:
{
“ name” : “ Events” ,
“ provider” : “ mixpanel”
}
笔记
生成的模型中的多维数据集和维度仅对模型提供者有用。提供程序可以产生元数据中指定的一组不同的多维数据集和维度。
维度可见性(Dimension Visibility)
默认情况下,静态(文件)模型的所有维度在工作空间中共享。这意味着这些维度可以在不同模型的多维数据集中自由重用。
可以定义仅包含维度而没有多维数据集的主模型。然后为每个多维数据集类别,数据集市或任何其他类别定义一个模型。这些模型可以共享主模型维度。
要仅公开模型中的某些维度,请在public_dimensionsmodel属性中指定维度名称列表。工作区中的其他多维数据集只能共享列表中的维度。
笔记
某些后端(例如Mixpanel)根本不共享维度
立方体
立方描述存储为字典键cubes在模型中描述的字典或前缀JSON文件cube_一样 cube_contracts。
| Key | 描述 |
|---|---|
| 基本的(逻辑的) | |
name * |
多维数据集名称,唯一标识符。必需的。 |
label |
可读的名称-可以在应用程序中使用 |
description |
多维数据集的更长的人类可读描述(可选) |
info |
自定义信息,例如格式。多维数据集框架未使用。 |
dimensions * |
维度名称或维度链接的列表(推荐,但对于无维度的多维数据集可能为空)。推荐的。 |
measures |
多维数据集度量值列表(推荐,但对于无度量值而言,可能为空,仅记录计数的多维数据集)。推荐的。 |
aggregates |
汇总度量值列表。如果未指定任何措施,则为必需。 |
details |
事实详细信息列表(作为属性)-与聚合无关,但在显示事实时很好用的属性(可以单独存储) |
| 物理的(存储性质) | |
joins |
物理表联接的规范(星型/雪花模式必需) |
mappings |
逻辑属性到物理属性的映射 |
key |
事实键字段或列名。如果未指定,则后端可能拒绝生成事实,也可能使用某些默认列名,例如 id。 |
fact |
事实表,集合或源名称-由后端解释。事实表不必指定,因为大多数后端将从多维数据集的名称派生名称。 |
| 高级部分 | |
browser_options |
浏览器特定的选项,请查阅后端以获取更多信息 |
store |
存储多维数据集的数据存储的名称。仅当默认商店分配与您的要求不同时才使用此选项。 |
标有*为必填项。
例子:
{
"name": "sales",
"label": "Sales",
"dimensions": [ "date", ... ]
"measures": [...],
"aggregates": [...],
"details": [...],
"fact": "fact_table_name",
"mappings": { ... },
"joins": [ ... ]
}记
该key会由一些后端,如SQL是必需的,以便能够生成详细的事实或获得一个事实。请参阅后端的文档以获取更多信息。
度量和汇总
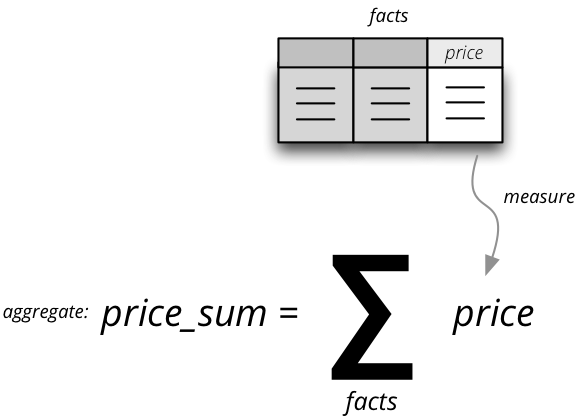
衡量和衡量总和
度量是事实的数字属性。例如,它们可能表示为表格列。度量汇总到度量汇总中。该措施描述为:
name–度量标识符(必填)label–显示的人类可读名称(本地化)info–其他自定义信息(未指定)aggregates–为此措施提供的汇总功能列表。此属性用于自动生成默认聚合。强烈建议显式列出聚合,并避免使用此属性。window_size–窗口功能(例如移动平均值)在窗口中的元素数量。如果未提供且功能需要,则假定为1(一个元素)。
例子:
“ measures” : [
{
“ name” : “ amount” ,
“ label” : “ Sales Amount”
},
{
“ name” : “ vat” ,
“ label” : “ VAT”
}
]
度量聚合是通过对事实聚合度量而计算出的值。它的属性是:
name–集合标识符,例如:amount_sum,price_avg, total,record_countlabel–显示的人类可读标签(本地化)measure–测量聚合的来源(如果存在或已知)。可能是空的。function-应用于度量的聚合函数的名称(如果已知)。例如:sum,min,max。window_size–窗口功能(例如移动平均值)在窗口中的元素数量。如果未提供且功能需要,则假定为1(一个元素)。info–其他自定义信息(未指定)
例子:
“ aggregates” : [
{{
name“ : ” amount_sum“ ,
” label“ : ”总销售额“ ,
” measure“ : ” amount“ ,
” function“ : ” sum“
},
{
” name“ : ” vat_sum“ ,
“ label” : “总增值税” ,
“ measure” : “ vat” ,
“ function” : “ sum”
},
{
“ name” : “item_count” ,
“ label” : “ Item Count” ,
“ function” : “计数”
}
]
注意最后一个合计item_count–它计算一个单元格中事实的数量。无需采取任何措施作为汇总的来源。
如果未指定聚合,则多维数据集将根据度量生成默认聚合。对于措施:
“ measures” : [
{
“ name” : “ amount” ,
“ aggregates” : [ “ sum” , “ min” , “ max” ]
}
]
创建了以下聚合:
“ aggregates” = [
{{
“ name” : “ amount_sum” ,
“ measure” : “ amount” ,
“ function” : “ sum”
},
{
“ name” : “ amount_min” ,
“ measure” : “ amount” ,
“ function “ : ” min“
},
{
” name“ : ” amount_max“ ,
” measure“ : ” amount“ ,
” function“ : ” max“
}
]
如果多维数据集中已经明确指定了一个聚合列表,则两个列表将合并在一起。
笔记
为了防止根据度量自动创建默认聚合,有一个高级多维数据集选项implicit_aggergates。如果只想保留明确的聚合列表,则将此属性设置为 False。
在以前的多维数据集版本中,有无处不在的度量聚合称为record_count。默认情况下不再提供它,而必须在模型中明确定义。名称可以是任何选择,它不再是内置聚合。为了保持原始行为,应添加以下汇总:
“ aggregates” : [
{
“name” : “ record_count” ,
“ function” : “ count”
}
]
笔记
某些总量不必从度量中计算出来。它们可能已经由数据存储提供为计算的聚合值(例如Mixpanel的total)。在这种情况下,度量和功能 仅用于后端或用于信息目的。有关汇总和度量的更多信息,请查阅后端文档。
自定义维度链接
可以指定如何将维度链接到多维数据集。该 dimensions列表除维名称外,还可能包含一个规范,说明如何在多维数据集的上下文中使用维。该规范可能包含:
hierarchies(等级/层级)–与多维数据集相关的层次结构列表。例如,日期维度可能被定义为具有日粒度,但是某些多维数据集可能仅处于月份级别(level)。要仅指定相关的层次结构,请使用hierarchies元数据属性:exclude_hierarchies–克隆原始维度时要排除的层次结构。hierarchies如果想保留大多数层次结构并仅删除其中的几个层次结构,请使用此方法代替hierarchies。default_hierarchy_name–多维数据集上下文中维的默认层次结构名称cardinality–关于多维数据集的维数基数。例如,一个多维数据集可能包含housands产品类型,另一个可能只有少数,但它们都共享相同的产品维度- ps:维度的基数(Cardinality)指的是该维度在数据中出现的不同值的个数;例如一个国家是一个维度,如果有200个不同的值,那么此维度的基数是200
alias–如何在多维数据集中调用维度。例如,您可能有两个日期维度,并使用别名将它们命名为start_date和 end_date
例子:
{
“ name” : “ churn” ,
“ dimensions” : [
{ “ name” : “ date” , “ hierarchies” : [ “ ym” , “ yqm” ]},
“ customer” ,
{ “ name” : “ date” , “ alias” : “ contract_date” }
],
...
}
上面的多维数据集将具有三个维度:date,customer和 contract_date。该日期维度将只有两个层级与最低粒度月,在客户维度将被指定为-是和contract_date维度将是相同的原始日期 维度。
维度
维度描述存储在模型字典中(在关键字 dimensions下)。
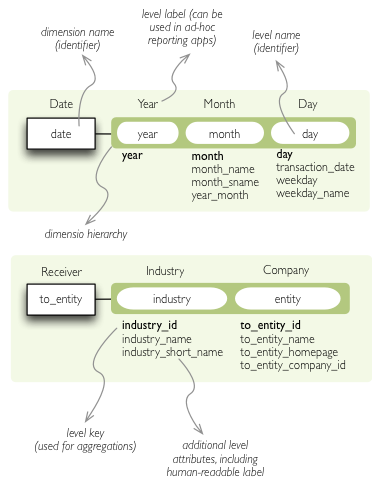
维度描述-属性。
维度描述包含键:
| key | 描述 |
|---|---|
| basic | |
name * |
维度名称,用作标识符 |
label |
可读的名称-可以在应用程序中使用 |
description |
人可读的维度描述(可选) |
info |
自定义信息,例如格式。传递到前端。 |
levels |
级别描述列表 |
hierarchies |
维度层次结构列表 |
default_hierarchy_name |
将用作默认名称的层次结构的名称 |
| 高级 | |
cardinality |
维度基数(有关更多信息,请参见级别) |
role |
维度角色 |
category |
逻辑类别(面向用户的元数据) |
template |
用作模板的维度的名称 |
ps:一个维度可以有多个hierarchies如上面的一个例子,维度有ym 、yqm 二个hierarchies(老夫注)
标有*为必填项。
如果未指定级别(levels ),则将创建一个默认级别。
如果未指定层次结构(hierarchies),则默认层次结构将包含维度的所有级别。(If no hierarchy is specified, then the default hierarchy will contain all levels of the dimension.)
例子:
{
“ name” : “ date” ,
“ label” : “Dátum” ,
“ levels : [ ... ]
” hierarchies“ : [ ... ]
}
使用hierarchies或hierarchy只能二选一,两者都使用会导致错误。
维度模板
如果要创建更多具有相同或相似结构的维度,例如多个日期或不同类型的组织关系,则可以创建模板维度,然后将其用作其他维度的基础:
“ dimensions” = [
{
“ name” : “ date” ,
“ levels” : [...]
},
{
“ name” : “ creation_date” ,
“ template” : “ date”
},
{
“ name” : “ closing_date “ ,
” template“ : ” date“
}
]
模板维度中的所有属性都将复制到新维度。可以在新维度中重新定义属性。在这种情况下,旧值将被丢弃。您可以更改级别,层次结构或默认层次结构。无法从模板添加或删除级别,如果所有新级别与原始模板维度不同,则必须再次指定所有新级别。但是,您可能只想重新定义层次结构以忽略不必要的级别。
笔记
在映射中,应使用新维度的名称。模板维度仅用于创建新维度,并且新维度与模板之间的连接丢失。在上面的示例中,如果多维数据集使用creation_date和closeing_date维度,并且需要任何映射,则它们应用于这两个维度,而不是日期维度。
level
维度层次结构级别(Dimension hierarchy levels)描述为:
| 钥匙 | 描述 |
|---|---|
name * |
级别名称,用作标识符 |
label |
可读的名称-可以在应用程序中使用 |
attributes |
与级别相关的其他附加属性的列表。该属性未用于聚合,它们提供了其他有用的信息。 |
key |
级别的关键字段(客户级别的客户编号,地区级别的地区代码,月份级别的年月)。键将用作聚合的分组字段。密钥在级别内应该是唯一的。 |
label_attribute |
包含要显示的标签的属性名称(客户级别的客户名称,地区级别的区域名称,月份级别的月份名称) |
order_attribute |
用于排序的属性名称,默认为第一个属性(键) |
cardinality |
类似成员数量的符号 |
role |
等级角色(见下文) |
info |
自定义信息,例如格式。多维数据集框架未使用。 |
标有*为必填项。
如果未指定任何属性,则仅假设一个属性具有与级别相同的名称。
如果未指定键,则采用第一个属性。
如果未指定label_attribute,则如果level具有多个属性,则假定第二个属性,否则使用第一个属性。
日期维度的月份级别示例:
{
“ month” ,
“ label” : “ Mesiac” ,
“ key” : “ month” ,
“ label_attribute” : “ month_name” ,
“ attributes” : [ “ month” , “ month_name” , “ month_sname” ]
},
供应商维度的供应商级别示例(supplier level of supplier dimension):
{
“ name” : “供应商” ,
“ label” : “Dodávateľ” ,
“ key” : “ ico” ,
“ label_attribute” : “ name” ,
“ attributes” : [ “ ico” , “ name” , “ address” , “ date_start” , “ date_end” ,
“ legal_form” ]
}
也可以看看
维度类参考
cubes.create_dimension()
从描述字典创建维度对象。
等级课程参考
cubes.create_level()
从描述字典创建关卡对象。
笔记
在拥有level的维度中,level属性名称必须唯一。
基数
后端和前端可以选择将基数属性用于各种目的。可能的值为:
tiny–几个值,每个值都可以在屏幕上显示出来,建议:最多5个。low–可以在列表UI元素中使用,建议使用5到50(如果已排序)medium– UI元素是搜索/文本字段,建议用于50个以上的元素high–后端可能会拒绝在没有明确分页或切入该级别的情况下产生结果。
Hierarchy
层次结构(Hierarchies)描述为:
| 钥匙 | 描述 |
|---|---|
name |
层次结构名称,用作标识符 |
label |
可读的名称-可以在应用程序中使用 |
levels |
级别名称从上到下的排序列表-从最高层到最详细(例如:从年到日,从国家到城市) |
仅要求名称。
例子:
“ hierarchies” : [
{
“ name” : “ default” ,
“ levels” : [ “ year” , “ month” ]
},
{
“ name” : “ ymd” ,
“ levels” : [ “ year” , “ month” , “ day” ]
},
{
“ name” : “ yqmd” ,
“ levels” : [ “ year” , “ quarter” , “ month”, “ day” ]
}
]
属性(Attributes)
维度级别属性可以指定为丰富的元数据,也可以仅指定为字符串。如果仅指定字符串,则所有属性元数据将具有默认值,label将等于属性名称。
| 钥匙 | 描述 |
|---|---|
| name | 属性名称(在维度内应该是唯一的) |
| label | 易读的名称-可以在应用程序中使用,可本地化 |
| order | 属性的自然顺序(可选),可以是asc或desc |
| format | 特定于应用程序的显示格式信息 |
| missing_value | 当源中没有值(NULL)时要替换的值(后端必须支持此功能) |
| locales | 属性值可用的语言环境列表(可选) |
| info | 自定义信息,例如格式。多维数据集框架未使用。 |
可选顺序用于聚合浏览和报告。如果指定,则所有查询都将具有按此字段按指定方向排序的结果。级别层次结构用于对有序属性进行排序。每个维度级别只能指定一个有序属性,否则该行为是不可预测的。此自然(或默认)顺序可以稍后在报表中通过显式指定其他排序方向或属性来覆盖。显式顺序优先于自然顺序。
例如,您可能希望指定默认情况下所有日期都应排序:
“ attributes” = [
{ “ name” = “ year” , “ order” : “ asc” }
]
语言环境是语言环境名称的列表。假设我们具有CPV维度(通用的采购词汇-欧盟采购主题层次结构),并且我们以斯洛伐克语,英语和匈牙利语进行报告。因此,属性将指定为:
“ attributes” = [
{
“ name” = “ group_code”
},
{
“ name” = “ group_name” ,
“ order” : “ asc” ,
“ locales” = [ “ sk” , “ en” , “ hu” ]
}
]
组名称已本地化,但组代码未本地化。您还可以看到结果将始终按组名的字母顺序升序排序。
在报表中,您没有为每个本地化的属性指定区域设置,而是为整个报表或浏览会话指定了区域设置。所有语言的报表查询均保持不变。
Roles
某些维度和级别可能具有特殊但众所周知的角色。一个角色的例子是时间。将来可能会有更多公认的角色,例如地理。
关联角色的前端可能会提供不同的用户界面元素,例如用于选择日期/时间维度值的日期和时间选择器。为了使日期选择器正常工作,前端必须知道,哪个维表示日期,哪个维级别表示日历单位,例如年,月或日。
必须明确说明维度的作用。不需要前端假定名为date的维度实际上是完整日期的维度。
如果可以识别级别名称以匹配特定角色,则不必明确提及级别角色。例如,在具有角色时间级别名称为year的维度中,将自动具有角色year。
当级别名称使用不同的语言或出于任何原因与英语日历单位名称不匹配时,必须指定级别角色。
当前只有一个公认的维度角色:time。与级别名称的默认分配认可级别角色是:year, quarter,month,day,hour,minute,second,week, weeknum,dow,isoyear,isoweek,isoweekday。
具有角色级别的关键值week应具有格式 YYYY-MM-DD。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)