
哈工大软件过程与工具复习2——第3-6讲 过程模型、敏捷方法、项目管理、软件演化和Git
目录一、软件过程模型1. 软件过程2. 典型软件过程模型(1)瀑布模型(2)增量过程模型(3)演化过程模型二、敏捷方法与过程1. 敏捷过程模型2. 极限编程3. Scrum4. 与传统开发过程模型的对比三、软件项目管理1. 软件项目管理2. 人员(People)3. 产品(Product)4. 过程(Process)5. 项目(Project)6. 可行性分析与估算7. 项目进度计划与监控四、软件
目录
一、软件过程模型
1. 软件过程
软件过程定义以下内容:
- 人员与分工
- 所执行的活动
- 活动的细节和步骤
软件过程通过以下方式组织和管理软件生命周期:
- 定义软件生产过程中的活动
- 定义这些活动的顺序及其关系
软件过程的目的:
- 标准化(可模仿)、可预见性(降低风险)、提高开发效率、得到高质量产品
- 提升制定时间和预算计划的能力
软件过程的典型阶段
- Dream(提出设想)
- Investigation(深入调研)
- Software Specification(需求规格说明)
- Software Design(软件设计)
- Software Implementation(软件实现)
- Software Deployment (软件部署)
- Software Validation(软件验证)
- Software Evolution(软件演化)
2. 典型软件过程模型
(1)瀑布模型
- 上一个阶段结束,下一个阶段才能开始
- 每个阶段均有里程碑和提交物
- 上一阶段的输出是下一阶段的输入
- 每个阶段均需要进行V&V
- 侧重于文档与产出物
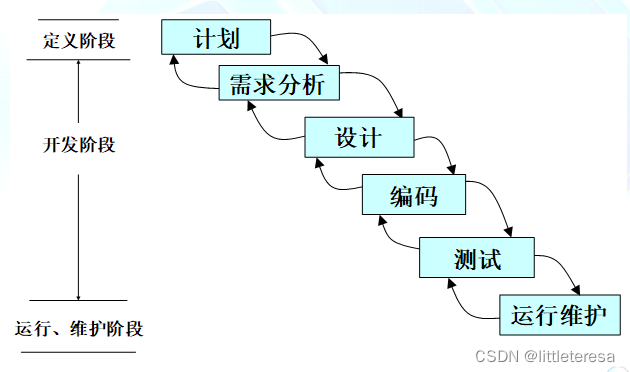
也叫做鲑鱼模型(Salmon model),很难向前一阶段回溯。
优点——追求效率
- 简单、易懂、易用、快速
- 为项目提供了按阶段划分的检查点,项目管理比较容易
- 每个阶段必须提供文档,而且要求每个阶段的所有产品必须进行正式、严格的技术审查
缺点——过于理想化
- 在开发早期,用户难以清楚地确定所有需求,需求的错误很难在开发后期纠正,因此难以快速响应用户需求变更
- 开发人员与用户之间缺乏有效的沟通,开发人员的工作几乎完全依赖规格说明文档,容易导致不能满足客户需求
- 客户必须在项目接近尾声的时候才能得到可执行的程序,对系统中存在的重大缺陷,如果在评审之前没有被发现,将可能会造成重大损失
瀑布模型太理想化,太单纯,已不再适合现代的软件开发模式,在大型系统开发中已经很少使用
适用场合:
- 软件项目较小,各模块间接口定义非常清晰
- 需求在项目开始之前已经被全面的了解,产品的定义非常稳定
- 需求在开发中不太可能发生重大改变
- 使用的技术非常成熟,团队成员都很熟悉这些技术
- 负责各个步骤的子团队分属不同的机构或不同的地理位置,不可能做到频繁的交流
- 外部环境的不可控因素很少
(2)增量过程模型
在很多情况下,由于初始需求的不明确,开发过程不宜采用瀑布模型。因此,无须等到所有需求都出来才进行开发,只要某个需求的核心部分出来,即可进行开发。另外,可能迫切需要为用户迅速提供一套功能有限的软件产品,然后在后续版本中再细化和扩展功能。在这种情况下,需要选用增量方式的软件过程模型——增量模型、RAD模型
增量模型
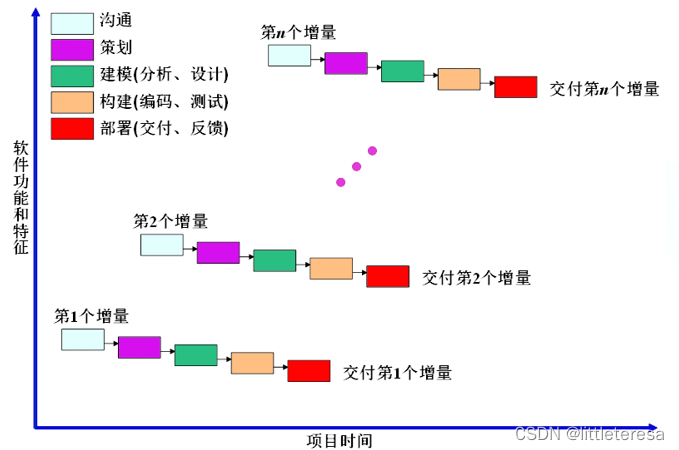
软件被作为一系列的增量来设计、实现、集成和测试,每一个增量是由多个相互作用的模块所形成的特定功能的代码片段构成。
本质:以迭代的方式运用瀑布模型
- 第一个增量往往是核心产品:满足了基本的需求,但是缺少附加的特性
- 客户使用上一个增量的提交物并进行自我评价,制定下一个增量计划,说明需要增加的特性和功能
- 重复上述过程,直到最终产品产生为止
优点:
- 在时间要求较高的情况下交付产品:在各个阶段并不交付一个可运行的完整产品,而是交付满足客户需求的一个子集的可运行产品,对客户起到“镇静剂”的作用
- 人员分配灵活:如果找不到足够的开发人员,可采用增量模型:早期的增量由少量人员实现,如果客户反响较好,则在下一个增量中投入更多的人力
- 逐步增加产品功能可以使用户有较充裕的时间来学习和适应新产品,避免全新软件可能带来的冲击
- 因为具有较高优先权的模块被首先交付,而后面的增量也不断被集成进来,这使得最重要的功能肯定接受了最多的测试,从而使得项目总体性失败的风险比较低
困难:
- 每个附加的增量并入现有软件时,必须不破坏原来已构造好的部分
- 同时,加入新增量时应简单、方便 ——该类软件的体系结构应当是开放的
- 仍然无法处理需求发生变更的情况
- 管理人员必须有足够的技术能力来协调好各增量之间的关系
RAD模型
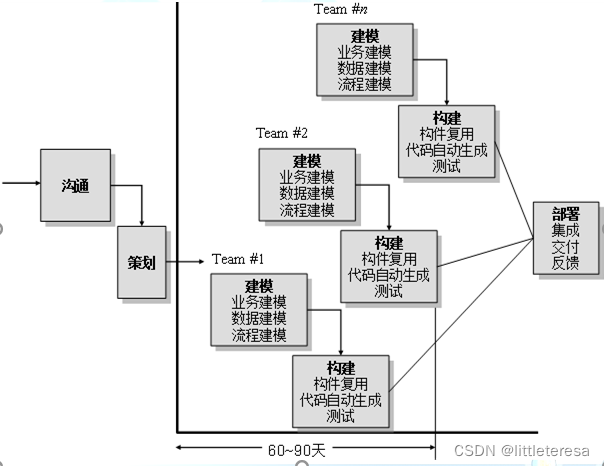
快速应用开发RAD (Rapid Application Development)
- 侧重于短开发周期(一般为60~90天)的增量过程模型,是瀑布模型的高速变体,通过基于构件的构建方法实现快速开发
- 多个团队并行进行开发,但启动时间有先后,先启动团队的提交物将作为后启动团队的输入
缺点:
- 需要大量的人力资源来创建多个相对独立的RAD团队
- 如果没有在短时间内为急速完成整个系统做好准备,RAD项目将会失败
- 如果系统不能被合理的模块化,RAD将会带来很多问题
- 技术风险很高的情况下(采用很多新技术、软件需与其他已有软件建立集成等等),不宜采用RAD
(3)演化过程模型
软件开发过程面临的客观情况:
- 软件系统会随着时间的推移而发生变化,在开发过程中,需求经常发生变化,直接导致产品难以实现
- 严格的交付时间使得开发团队不可能圆满完成软件产品,但是必须交付功能有限的版本以应对竞争或压力
- 很好的理解核心产品与系统需求,但对其他扩展的细节问题却没有定义
在上述情况下,需要一种专门应对不断演变的软件过程模型,即“演化过程模型”
本质:循环、反复、不断调整当前系统以适应需求变化
主要包括两种形态:快速原型法、螺旋模型
快速原型法
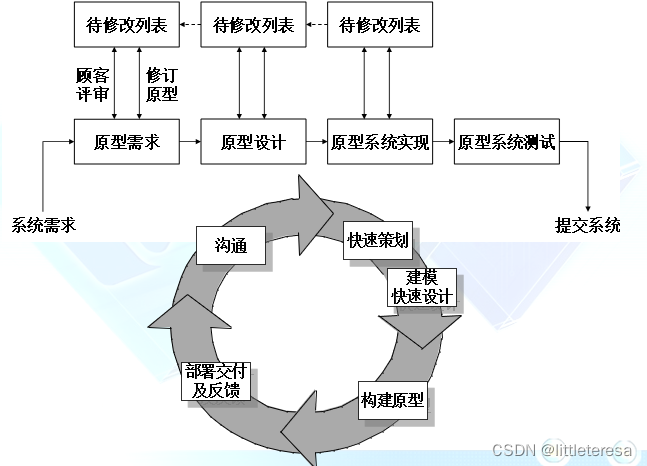
步骤
- 双方通过沟通,明确已知的需求,并大致勾画出以后再进一步定义的东西
- 迅速策划一个原型开发迭代并进行建模,主要集中于那些最终用户所能够看到的内容,如人机接口布局或者输出显示格式等
- 快速设计产生原型,对原型进行部署,由客户和用户进行评价
- 根据反馈,进一步细化需求并调整原型
- 原型系统不断调整以逼近用户需求
原型区分:抛弃式原型(不可执行)和演化型原型(可执行,有较高质量或核心功能)
优点:
提高和改善客户/用户的参与程度,最大程度的响应用户需求的变化
缺点:
- 为了尽快完成原型,开发者没有考虑整体软件的质量和长期的可维护性,系统结构通常较差
- 可能混淆原型系统与最终系统,原型系统在完全满足用户需求之后可能会被直接交付给客户使用
- 额外的开发费用
螺旋式过程模型——与增量、RAD等的最大区别在于重视风险评估
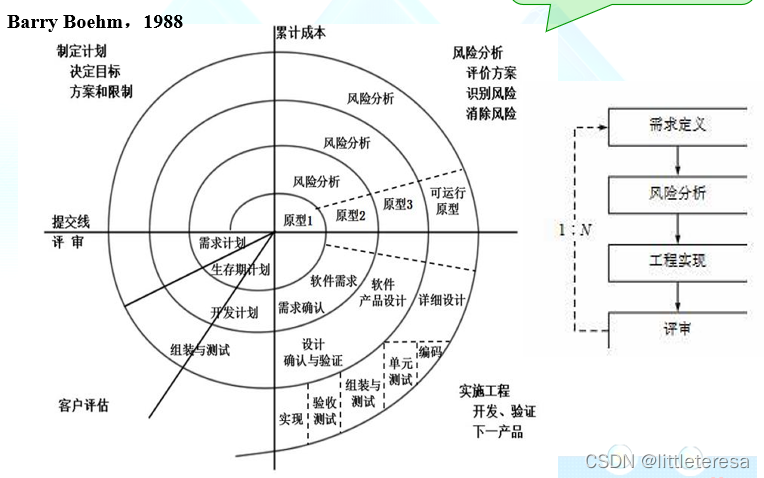
螺旋模型沿着螺线旋转,在四个象限内表达四个方面的活动:
- 制定计划:确定软件目标,选定实施方案,弄清项目开发的限制
- 风险分析:分析所选方案,考虑如何识别和消除风险
- 实施工程:实施软件开发
- 客户评估:评价开发工作,提出修正建议
出发点:开发过程中及时识别和分析风险,并采取适当措施以消除或减少风险带来的危害
优点:结合了原型的迭代性质与瀑布模型的系统性和可控性,是一种风险驱动型的过程模型:
- 采用循环的方式逐步加深系统定义和实现的深度,同时更好的理解、应对和降低风险
- 确定一系列里程碑,确保各方都得到可行的系统解决方案
- 始终保持可操作性,直到软件生命周期的结束
- 由风险驱动,支持现有软件的复用
缺陷:
- 适用于大规模软件项目,特别是内部项目,周期长、成本高
- 软件开发人员应该擅长寻找可能的风险,准确的分析风险,否则将会带来更大的风险
演化模型的缺点
演化过程模型的目的:需求的变更频繁,要求在非常短的期限内实现,以充分满足客户/用户要求、及时投入市场
存在的问题:
- 由于构建产品所需的周期数据不确定,给项目管理带来困难
- 演化速度太快,项目陷入混乱;演化速度太慢,影响生产率
- 为追求软件的高质量而牺牲了开发速度、灵活性和可扩展性
二、敏捷方法与过程
1. 敏捷过程模型
开发过程中的“变化”是无处不在的,也是不可避免的。在实际项目中,很难预测需求和系统何时以及如何发生变化。对开发者来说,应将变化的意识贯穿在每一项开发活动中
敏捷宣言12条原则
- 我们的最高目标是通过尽早和持续交付有价值的软件来满足客户
- 欢迎对需求提出变更—即使是在项目开发后期;要善于利用需求变更,帮助客户获得竞争优势
- 要不断交付可用的软件,周期从几周到几个月不等,且越短越好
- 项目过程中,业务人员与开发人员必须在一起工作
- 要善于激励项目人员,给他们所需要的环境和支持,并相信他们能够完成任务
- 无论是团队内还是团队间,最有效的沟通方法是面对面的交谈
- 可用的软件是衡量进度的主要指标
- 敏捷过程提倡可持续的开发;项目方、开发人员和用户应该能够保持恒久稳定的进展速度
- 对技术的精益求精以及对设计的不断完善将提升敏捷性
- 要做到简洁,即尽最大可能减少不必要的工作,这是一门艺术
- 最佳的架构、需求和设计出自于自组织的团队
- 团队要定期反省如何能够做到更有效,并相应地调整团队的行为
总结:小步快跑,及时反馈
本质:以快速的增量和迭代方式进行软件开发
- 不强调文档,转向强调可运行的软件片段
- 开发者与客户之间频繁沟通
- 快速开发,快速反馈,快速修改,增量交付
- 连续不断的短周期迭代
- 不看重形式和工具,看重“人”和内容,保持简洁
2. 极限编程
极限编程(XP):一种最广泛应用的敏捷开发方法
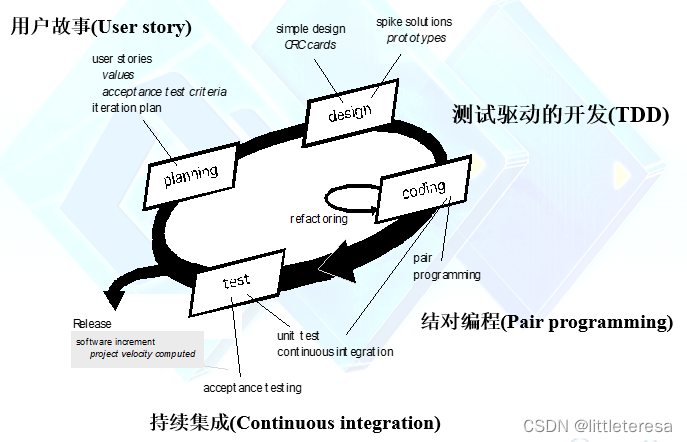
计划阶段
- 倾听客户陈述,形成一组“用户故事(user stories)” ,描述其输出、特性、功能等
- 按照价值或风险排序:客户为每个用户故事指定优先级(Priority)
- XP团队评估各个用户故事,为其指定成本(Cost, 开发周数),若超过3周,则拆分
- 将若干个用户故事指定为下一次发布的增量,确定发布日期:所有用户故事、优先级高的用户故事、风险高的用户故事
- 规划整体进度(project velocity):以怎样的速度开展项目
- 客户可以在开发过程中扩展新故事、去除原有故事、改变优先级、拆分等
设计阶段
- 遵循KIS原则(Keep It Simple);
- 设计模型:面向对象方法,CRC卡片(Class-Responsibility-Collaborator)
- 遇到困难问题,创建“Spike Solutions”(原型)
- 对设计方案不断重构(Refactoring):遵循用户故事的外特性要求、改善内部结构、消除bug、提高效率、提高易读性
编码与测试阶段
XP Coding
- 在编码之前,根据用户故事设计单元测试用例
- 结对编程(Pair programming):两人一起编程,实时讨论、实时评审
- 测试驱动的开发(TDD):先写测试用例,再写代码
XP Testing
- 自动化单元测试(Unit test)
- 持续集成(Continuous Integration)
- 持续进行回归测试(Regression test)
- 验收测试(Acceptance test)
极限:把某件事情做到极致
3. Scrum
Scrum
- 一个敏捷开发框架:增量/迭代的开发过程
- 整个开发过程由若干个短的迭代周期组成,一个短的迭代周期称为一个Sprint,每个Sprint的建议长度是2到4周
- 使用产品Backlog来管理需求,是一个按照商业价值排序的需求列表,列表条目的体现形式通常为用户故事
- 总是先开发对客户具有较高价值的需求
- 在Sprint中,Scrum团队从产品Backlog中挑选最高优先级的需求进行开发;挑选的需求在Sprint计划会议上经过讨论、分析和估算得到相应的任务列表(Sprint backlog)
- 在每个迭代结束时,Scrum团队将提交潜在可交付的产品增量
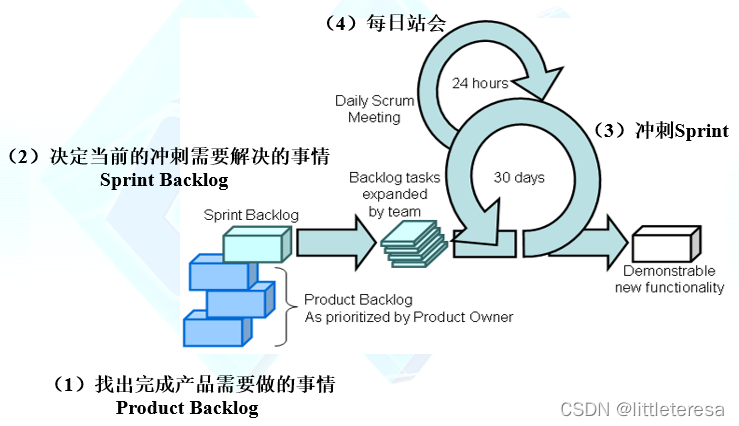
六项活动
- Sprint (冲刺):代表一个1-4周的迭代
- 发布计划会议(Release Planning Meeting) → Product Backlog
- Sprint计划会议(Sprint Planning Meeting) → Sprint Backlog
- 每日站会(Daily Scrum Meeting)
- Sprint评审会(Sprint Review Meeting)
- Sprint回顾会议(Sprint Retrospective Meeting)
每日站会
- 团队成员站着开会——强迫在短时间(15分钟)内高效率讨论问题,保持注意力集中
- 强迫每个人向同伴报告进度, 迫使大家把问题摆在明面上:1. 我昨天做了什么(What have you done since yesterday? ) 2. 我今天要做什么(What are you planning to do today? ) 3. 我碰到了哪些问题(Do you have any problems that would prevent you from accomplishing your goal? )
- 用简明的图表展现整个项目的进度,这个图最好放在大家工作的环境中,或者每天传达给各个成员
4. 与传统开发过程模型的对比
| 开发过程模型 | 特点 | 概括 |
| 瀑布模型 | 将全部需求以整体方式向前推进,无迭代 | 基本模型 |
| 增量模型 | 将需求分成多份,串行推进,无迭代 | 串行的瀑布 |
| RAD模型 | 将需求分成多份,并行推进,无迭代 | 并行的瀑布 |
| 原型模型 | 迭代 | 基本模型 |
| 螺旋模型 | 按瀑布阶段划分,各阶段分别迭代(原型+风险分析) | 原型+瀑布 |
| 敏捷模型 | 将需求分成尽量小的碎片,以碎片为单位进行高速迭代 | 增量+迭代 |
|
适用方式 客观因素 |
敏捷 (Agile) |
计划驱动 (Plan-driven) |
形式化的开发方法 (Formal Method) |
|
产品可靠 性要求 |
不高, 容忍经常出错 |
必须有较高可靠性 |
有极高的可靠性和质量要求 |
|
需求变化 |
经常变化 |
不经常变化 |
固定的需求,需求可以建模 |
|
团队人员 数量 |
不多 |
较多 |
不多 |
|
人员经验 |
有资深程序员带队 |
以中层技术人员为主 |
资深专家 |
|
公司文化 |
鼓励变化, 行业充满变数 |
崇尚秩序, 按时交付 |
精益求精 |
|
实际例子 |
写一个微博网站 |
开发下一版本办公软件;给商业用户开发软件 |
开发底层正则表达式解析模块; |
|
用错方式 的后果 |
用敏捷的方法开发登月火箭控制程序, 前N 批宇航员都挂了。 |
用敏捷方法, 商业用户未必受得了两周一次更新的频率。 |
敏捷方法的大部分招数都和这类用户无关, 用户关心的是: 把可靠性提高到 99.99%, 不要让微小的错误把系统搞崩溃! |
三、软件项目管理
1. 软件项目管理
软件项目管理的4P:People、Process、Project、Product
2. 人员(People)
- 高级管理者:负责定义业务问题
- 项目(技术)管理者:计划、激励、组织和控制软件开发人员
- 开发人员:拥有开发软件所需技能的人员——系统分析员、系统架构师、设计师、程序员、测试人员、质量保证人员、…
- 客户:进行投资、详细描述待开发软件需求、关心项目成败的组织/人员
- 最终用户:一旦软件发布成为产品,最终用户就是直接使用软件的人
组织方式
- 一窝蜂模式 :没有明确分工,存活的时间一般都不长
- 主治医师模式: 首席程序员处理主要模块的设计和编码,其他成员从各种角度支持他的工作
- 社区模式 :由很多志愿者参与,每个人参与自己感兴趣的项目,贡献力量。好处是“众人拾柴火焰高”, 但是如果大家都只来烤火, 不去拾柴, 或者捡到的柴火质量太差, 最后火也熄灭了。比如像开源项目
- 交响乐团模式 :人多,门类齐全,各司其职,各自有专门场地,演奏期间严格遵循纪律。演奏靠指挥协调,各自遵循曲谱(工作流程)。演奏的都是练习过多次的曲目,重在执行类。似于“工厂”,严格遵循预定的生产流程
- 爵士乐模式:演奏时没有谱子,没有现场指挥,平时有arranger起到协调和指导作用。模式为主乐手先吹出主题,其余人员根据这个主题各自即兴发挥;主乐手最后再加入,回应主题,像是对曲子的总结。“强调个性化的表达,强有力的互动, 对变化的内容有创意的回应”。类似于一群天才构成的敏捷团队,率性而为
- 功能团队模式:具备不同能力的同事平等协作,共同完成一个项目开发。在这个项目完成之后, 这些人又重新组织,和别的角色一起去完成下一个功能, 他们之间没有管理和被管理的关系
- 官僚模式:成员之间不光有技术方面的合作和领导,同时还混进了组织上的领导和被领导关系,跨组织的合作变得比较困难
3. 产品(Product)
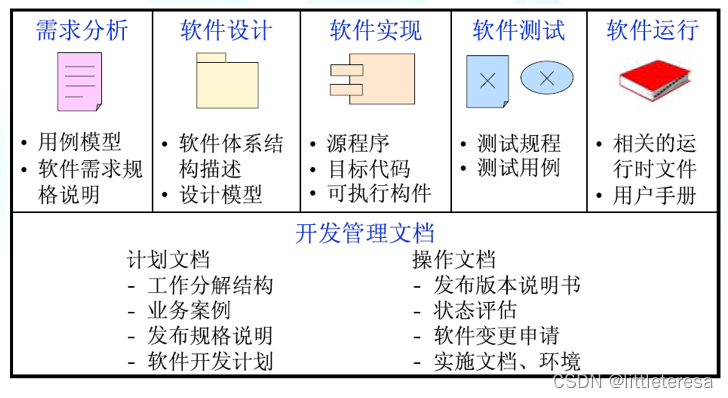
首先应确定软件范围:
- 功能和非功能(性能、可用性、安全、法律等)
- 软件范围应是确定的:在管理层和技术层都必须是无歧义的和可理解的
一旦确定了范围,需要对其进行分解——分而治之
项目管理里通常使用“产品结构分解(Product Breakdown Structure, PBS)”作为产品分解的工具:
- PBS:通过分层的树型结构来定义和组织项目范围内的所有产出物(产品),自顶向下,逐级细分
- 产出物:项目结束时需要提交的最终产品,在项目之初就可以准确预计
4. 过程(Process)
Step 1: 选择合适的软件过程模型,原因是存在多种过程模型,而各过程模型适用不同类型的软件项目。
Step 2: 根据所选的过程模型,对其进行适应性修改
Step 3: 确定过程中应包含的工作任务列表
项目管理里通常使用“工作结构分解(Work Breakdown Structure, WBS)”作为过程分解的工具
WBS:通过分层的树型结构来定义和组织工作任务之间的分解关系,自顶向下,逐级细分
5. 项目(Project)
项目关注的四个方面:范围、时间、成本、质量
项目管理的主要任务:项目可行性分析与估算、项目进度安排、项目风险管理、项目质量管理、项目跟踪与控制
W5HH原则
Why:为什么要开发这个系统?
What:将要做什么?
When:什么时候做?
Who:某功能由谁来做?
Where:他们的机构组织位于何处?
How:如何完成技术与管理工作?
How much:各种资源分别需要多少?
6. 可行性分析与估算
确认范围
范围(Scope):描述将要交付给最终用户的功能和特性、输入输出数据、用户界面、系统的性能、约束条件、接口和可靠性等,以及期望的时间、成本目标
两种方法:
- 与所有项目成员交流之后,写出对软件范围的叙述性描述
- 由最终用户给出一组用例
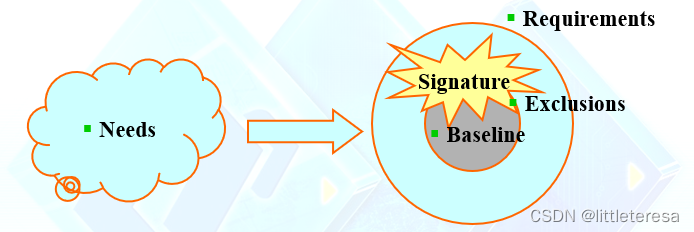
Needs:客户/最终用户的请求、想法和业务需求
Requirements:对未来系统所应具备的功能的陈述
Exclusions:将不包含在未来系统中的功能的陈述
Baseline:对未来系统中应包含的功能的陈述
可行性分析:包括技术可行性、经济可行性、时间可行性、资源可行性
估算方法:代码行估算方法、功能点估算方法、过程时间估算方法
7. 项目进度计划与监控
任务进度安排——甘特图
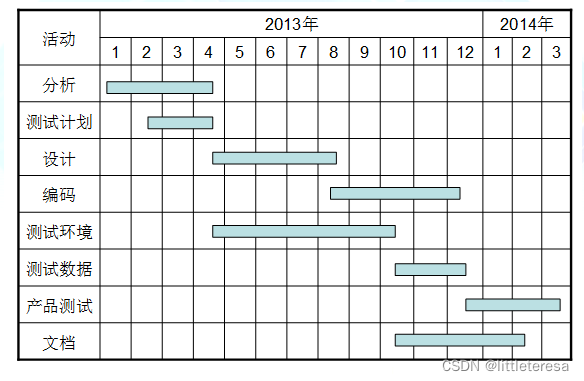
将资源(资金、人员、设备、环境)分配给任务,明确产出结果(outcomes)。每一项任务的产出结果是什么?对应于PBS中的哪一部分?明确里程碑(milestones),即项目的关键产出物,标志着某一阶段的完成。
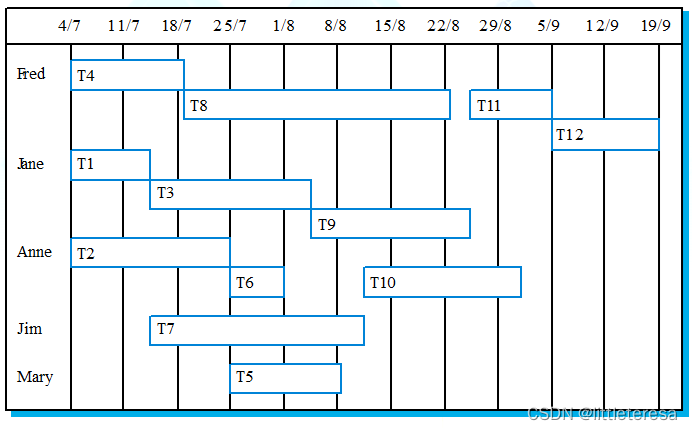
人员/资源分配图
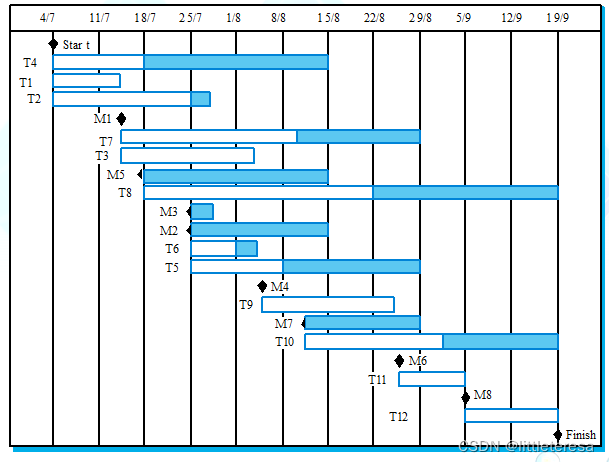
项目进度跟踪——甘特图
XP/Scrum敏捷开发中的进度计划与监控
- 以“迭代”为单位:每次迭代包含多少个用户故事或用例
- 每次迭代为30天左右
- 针对每个用户故事,团队成员联合估算和协商开发代价(时间)
- 使用任务墙(Task Board)/燃尽图(Burndown Chart)等作为进度监控工具,评估迭代的当前进展情况
- 敏捷开发的项目管理工具:VersionOne
四、软件演化与配置管理
1. 软件演化
软件演化:软件在使用过程中,新的需求不断出现,商业环境在不断地变化,软件中的缺陷需要进行修复,计算机硬件和软件环境的升级需要更新现有的系统,软件的性能和可靠性需要进一步改进
软件演化的Lehman定律:持续变化、复杂度逐渐增大
软件演化的处理策略:软件维护(发生在局部,不会改变整个结构)、软件再工程(对软件的一部分进行重新设计、编码和测试,提高软件的可维护性和可靠性),前者比后者力度要小
2. 软件维护
类型:
- 纠错性维护:修改软件中的缺陷或不足
- 适应性维护:修改软件使其适应不同的操作环境,包括硬件变化、操作系统变化或者其他支持软件变化等
- 完善性维护:增加或修改系统的功能,使其适应业务的变化
- 预防性维护:为减少或避免以后可能需要的前三类维护而提前对软件进行的修改工作
最多的维护为完善性维护
软件维护的内容:
- 程序维护:根据使用的要求,对程序进行全部或部分修改。修改以后,必须书写修改设计报告
- 数据维护:数据维护指对数据有较大的变动,如安装与转换新的数据库,或者某些数据文件或数据库出现异常时的维护工作,如文件的容量太大而出现数据溢出等
- 硬件维护:硬件人员应加强设备的保养以及定期检修,并做好检验记录和故障登记工作
软件的维护成本:极其昂贵
业务应用系统:维护费用与开发成本大体相同
嵌入式实时系统:维护费用是开发成本的4倍以上
遗留系统(legacy system):“已经运行了很长时间的、对用户来说很重要的、但是目前已无法完全满足要求却不知道如何处理的软件系统”
特点:现有维护人员没有参与开发。不具备现有的开发规范。文档不完整,修改记录简略
3. 软件配置管理(SCM)
缺乏管理的问题:软件生产达不到规模化、缺少有效的沟通机制、成员间确实沟通、人员流动
软件配置(software configuration):由在软件工程过程中产生的所有信息项构成,它可以看作该软件的具体形态(软件配置项)在某一时刻的瞬间映像
软件配置管理(Software Configuration Management, SCM)
SCM贯穿整个软件生命周期与软件工程过程
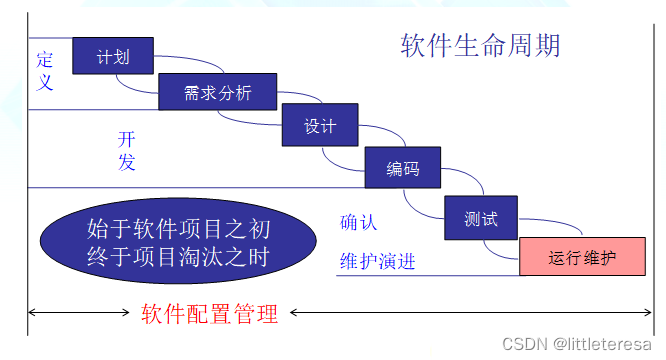
SCM的目标:标识变更、控制变更、确保变更的正确实现、向开发组织内各角色报告变更
总结:当变更发生时,能够提高适应变更的容易程度,并且能够减少所花费的工作量
SCM基本元素
1. 配置项(Configuration Item, CI)
软件过程的输出信息可以分为三个主要类别:
- 计算机程序(源代码和可执行程序)
- 描述计算机程序的文档(针对技术开发者和用户)
- 数据(包含在程序内部或外部)
这些项包含了所有在软件过程中产生的信息,总称为软件配置项(SCI)。SCI是软件全生命周期内受管理和控制的基本单位,大到整个系统,小到某个硬件设备或软件模块。
SCI具有唯一的名称标识和多个属性:名称、描述、类型(模型元素、程序、数据、文档等)、项目标识符、关联关系、变更和版本信息
配置项之间的依赖关系:整体——部分关系、关联关系
在对象成为基线以前可能要做多次变更,在成为基线之后也可能需要频繁的变更。对于每一配置项都要建立一个演变图,以记录对象的变更历史
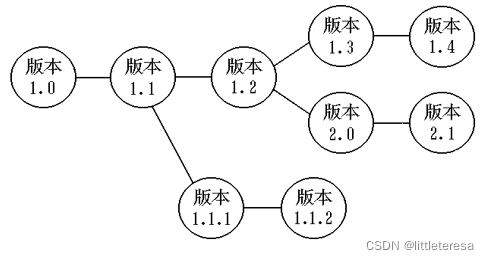
2. 基线(Baseline)
基线:已经通过正式评审和批准的软件规格说明或代码,它可以作为进一步开发的基础,并且只有通过正式的变更规程才能修改它
在软件配置项成为基线之前,可以迅速而随意的进行变更。一旦成为基线,变更时需要遵循正式的评审流程才可以变更。因此,基线可看作是软件开发过程中的“里程碑”
基线是在某个时间点上对产品属性的一致描述,它是定义变化的基础
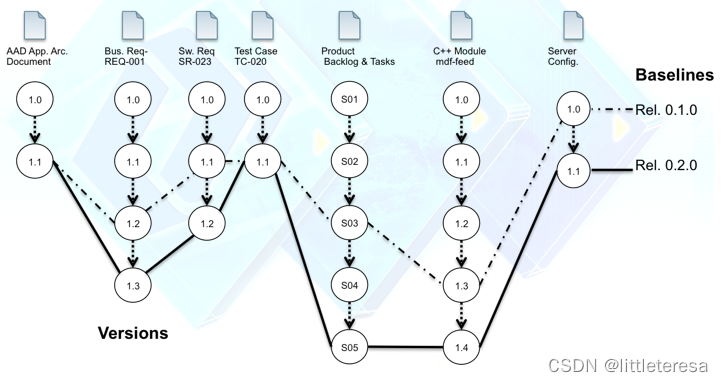
3. 配置管理数据库(CMDB)
配置管理数据库(CMDB)(也称“SCM中心存储库”),用于保存与软件相关的所有配置项的信息以及配置项之间关系的数据库
- 每个配置项及其版本号
- 变更可能会影响到的配置项
- 配置项的变更路线及轨迹
- 与配置项有关的变更内容
- 计划升级、替换或弃用的配置项
- 不同配置项之间的关系
CMDB的功能:
- 存储配置项及其之间的关系
- 版本控制
- 相关性跟踪和变更管理
- 需求跟踪
- 配置管理
- 审核跟踪
SCM常用工具
- VSS (Microsoft Visual SourceSafe)
- CVS (Concurrent Version System)
- IBM Rational ClearCase
- SVN (Subversion)
- Git
4. 最终硬件库(Definitive Hardware Store, DHS)
5. 最终软件库(Definitive Software Library, DSL)
4. 持续集成
持续集成:敏捷开发的一项重要实践
Martin Fowler:团队开发成员经常集成他们的工作,每个成员每天至少集成一次,每天可能会发生多次集成;每次集成都通过自动化的构建(包括编译,发布,自动化测试)来验证,从而尽快地发现集成错误,大大减少集成的问题,让团队能够更快的开发内聚的软件
价值:
- 减少风险:不是等到最后再做集成测试,而是每天都做
- 减少重复过程:通过自动化来实现
- 任何时间、任何地点生成可部署的软件
- 增强项目的可见性
- 建立团队对开发产品的信心
所有的开发人员需要在本地机器上做本地构建,然后再提交到版本控制库中,从而确保他们的变更不会导致持续集成失败。开发人员每天至少向版本控制库中提交一次代码,至少需要从版本控制库中更新一次代码到本地机器。需要有专门的集成服务器来执行集成构建,每天要执行多次构建,且每次构建都要100%通过。每次构建都可以生成可发布的产品。修复失败的构建是优先级最高的事情
五、Git与Github
1. 本地 vs 分布式版本控制系统
本地版本控制系统:采用简单的数据库或文件系统来记录本地文件的历次更新差异
集中化的版本控制系统:CVS,Subversion 以及 Perforce 等,有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的开发者通过客户端连到这台服务器,取出最新的文件或者提交更新。缺陷:单点故障,可靠性问题
分布式版本控制系统:客户端并不只提取最新版本的文件快照,而是把原始的代码仓库完整地镜像下来。任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。每一次的提取操作,实际上都是一次对代码仓库的完整备份
2. Git的基本思想
Git关心文件数据的整体是否发生变化,并不保存这些前后变化的差异数据
Git的思路:存储项目随时间改变的快照
Git的三种状态:已提交、已修改、已暂存
三个工作区域:Git目录(仓库)、工作目录、暂存区域
基本工作流程
1. 在工作目录中修改某些文件
2. 对修改后的文件进行快照,然后保存到暂存区域
3. 提交更新,将保存在暂存区域的文件快照永久转储到Git目录中
可以从文件所处的位置来判断状态:
如果是 git 目录中保存着的特定版本文件,就属于已提交状态
如果作了修改并已放入暂存区域,就属于已暂存状态
如果自上次取出后,作了修改但还没有放到暂存区域,就是已修改状态
3. 基本Git指令
取得Git仓库
在工作目录中初始化新仓库。要对现有的某个项目开始用Git管理,只需到此项目所在的目录,执行git init命令,用 git add 命令告诉Git开始对这些文件进行跟踪,然后提交:
git add *.c
git add README
git commit -m 'initial project version'
通过git clone [URL]从远程服务器克隆特定的git仓库至本地
检查文件状态——git status
# On branch master nothing to commit (working directory clean) :当前没有任何跟踪着的文件,也没有任何文件在上次提交后更改过
# On branch master # Untracked files: …:有未跟踪的文件,使用git add开始跟踪一个新文件
# On branch master # Changes to be committed: 有处于已暂存状态的文件
跟踪文件与暂存已修改的文件——git add
潜台词:把目标文件快照放入暂存区域,也就是 add file into staged area,同时未曾跟踪过的文件标记为需要跟踪
查看具体修改——git diff
- 要查看尚未暂存的文件更新了哪些部分,不加参数直接输入git diff:比较的是工作目录中当前文件和暂存区域快照之间的差异,也就是修改之后还没有暂存起来的变化内容(修改之后但未加入暂存
- 若要查看已暂存起来的文件和上次提交时的快照之间的差异,可以用 git diff --cached 命令:比较的是暂存区域内的文件的更改(修改之后加入缓存但尚未提交)
- 若想查看已缓存和未缓存的所有差异,使用git diff HEAD命令:是对上述两种情况的复合
提交更新——git commit
每次准备提交前,先用git status进行检查,然后再运行提交命令git commit
Git提供了一个跳过使用暂存区域的方式,只要在提交的时候,给 git commit 加上-a 选项,Git 就会自动把所有已经跟踪过的文件暂存起来一并提交,从而跳过git add步骤
跳过使用暂存区域、移除文件
- git reset [files] ——重置文件的暂存状态,把文件从暂存区移除,使得暂存区版本和仓库版本一致;暂存区内其他文件不变——相当于git add的反向操作。--hard, --soft, --mixed:多种不同的reset行为
- git checkout ——把文件从暂存区复制到工作目录,丢弃自上一次git add以来的所有本地修改
- git checkout HEAD ——将最后一次提交的结果复制到工作目录和暂存区,丢弃了本地修改
- git rm ——从Git中移除某个文件,把它从已跟踪文件清单(暂存区域)中移除,并连带从工作目录中删除指定的文件。若不想从工作目录中删除,使用git rm --cached
查看提交历史——git log
- 不加任何参数:会按提交时间列出所有的commit,最近的排在最上面,包含 SHA-1 校验和、作者的名字和电子邮件地址、提交时间以及提交说明
- -p参数:显示每次提交的内容差异 (针对每个变化了的文件,增加了哪些行、删除了哪些行)
- --stat参数:查看每次commit的简要统计信息,列出所有被修改过的文件及总数量、每个被修改过的文件有多少行发生变化等
- --pretty=format:… 按特定格式展示commit的结果 (格式化输出)
- --graph:以图形方式展示commit的历史
- 其他各种参数
更改一次提交
如果在一次commit之后发现遗漏了某些文件修改或者提交信息不正确,使用git commit --amend撤销上一次提交,形成新的提交
本质:合并暂存区的修改和最近的一次commit的修改内容,用生成的新的commit替换掉原来的commit,而不会形成新的分支
另一种方法:
git reset HEAD^ :工作区不变,暂存区回退到上一次commit之前,上一次commit取消
#重新修改
git add
git commit
4. Git远程仓库指令
添加远程仓库:
git clone指令在克隆远程仓库内容到本地之后,自动生成了一个远程仓库配置 (origin)
git remote add <shortname> <url>: 添加一个新的远程 Git 仓库,同时指定一个缩写
查看已配置的远程仓库:
git remote:获取当前配置的所有远程仓库
git remote –v: 显示当前配置的远程仓库及其读写操作权限(fetch, push)和URL地址
git remote show [remote-name]:查看某个远程仓库的详细信息
移除/推送/拉取远程仓库:
git remote rm pb:从本地移除远程仓库 (不再关注其更新、不再对其有贡献)
git remote rename pb pb1:将远程仓库重命名
git fetch:从远程仓库抓取数据到本地,获取本地仓库尚未拥有的全部更新。如果本地仓库有了不同的修改,则需要手工将本地修改与远程仓库的修改合并起来 (分支的合并 git merge)
git pull == git fetch + git merge:获取远程仓库的更新并与本地当前分支合并 【慎用】
git push [remote-name] [branch-name]:将本地仓库中的数据推送到远程仓库
5. Git分支指令
git使用一个叫做HEAD的特别指针来获知你当前在哪个分支上工作。再切换分支时,HEAD标识会移动到那个分支,暂存区域和工作目录中的内容会和HEAD对应的提交节点一致。新提交节点中的所有文件都会被复制到暂存区域和工作目录中;只存在于老的提交节点中的文件会被删除
创建/切换/删除分支:
git branch——列出当前所有分支
git branch (name) ——在当前commit对象上新建一个分支指针
git checkout ——切换到其他分支
git branch –b ——创建一个新的分支并立即切换过去
git branch –d ——删除一个分支
git log –decorate ——查看当前各个分支所指的commit对象
分支合并
git merge (name):将该分支合并到当前分支
git rebase
Merge和Rebase的区别:
- merge把两个父分支合并进行一次提交,提交历史不是线性的
- rebase在当前分支上重演另一个分支的历史,提交历史是线性的——保持提交历史的整洁
6. 远程分支
Push:推送本地分支至远程
- 将本地分支推送至有写入权限的远程仓库上
- 不能自动同步,由本地开发者自行决定要分享哪些新工作给其他人
- git push [remote] [branch] 将本地的当前分支推送到remote服务器的branch分支上
- 但是,如果该远程分支已经被其他人做过更新,则本次推送无法生效。解决办法:将其他人的更新fetch到本地,在本地合并之后,再重新push
Fetch:将远程分支同步到本地
- git fetch [remote] [branch]
- git merge remote/branch:将远程分支的变化合并到本地当前分支
跟踪远程分支
跟踪分支是与远程分支有直接关系的本地分支
- git checkout --track origin/serverfix:创建一个叫做serverfix的本地分支,并跟踪origin远程仓库上的serverfix分支
- git checkout -b sf origin/serverfix:创建一个名为sf的本地分支,并跟踪origin远程仓库上的serverfix分支
- git branch -u origin/serverfix:设置本地的当前分支跟踪origin远程仓库上的serverfix分支
- 使用git branch 的 –vv 参数列出各本地分支是否跟踪远程分支、进度如何(领先、落后)
如果在一个跟踪分支上输入 git pull,git 能自动地识别去哪个服务器上抓取、合并到哪个分支。等价于git fetch + git merge
删除远程分支
git push origin --delete serverfix 从origin远程仓库上删除serverfix的远程分支
7. Github
(麻了,复习这个东西人容易麻,建议不要复习一下午,人会麻掉。不对,你看到这意味着你也一直看了下来,估计也和我一样麻了)
GitHub:共享虚拟主机服务,用于存放使用Git版本控制的软件代码和内容项目,是目前最流行的Git存取站点,同时提供付费账户和为开源项目提供的免费账户

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)