
【机器学习】利用决策树分类Iris鸢尾花数据集
本文旨在实现一个基础的决策树分类模型,对鸢尾花数据集进行分类,理解并应用决策树分类模型
目标
本文旨在实现一个基础的决策树分类模型,理解并应用决策树分类模型:学习如何使用Scikit-learn库的DecisionTreeClassifier来实现分类任务。数据集划分与训练:掌握如何将数据划分为训练集和测试集,并进行模型训练。模型调优:通过测试不同深度的决策树,理解树的深度对模型性能的影响,并找到最佳深度。模型评估与可视化:评估决策树模型的准确率,学习如何通过可视化工具展示决策树及其规则。
环境
Python编程语言
Scikit-learn库
Matplotlib(用于数据可视化)
NumPy和Pandas库(用于数据处理)
Jupyter Notebook或类似IDE(用于代码编写和结果展示)
数据集
本实验使用的是鸢尾花数据集(Iris dataset),它是一个经典的多分类数据集,包含150个样本,4个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度),以及3个目标类别(Setosa、Versicolor、Virginica)。
步骤
1. 数据加载与初步探索
加载鸢尾花数据集,获取特征数据X和目标标签y。
初步了解数据集的特征和目标类别分布。
2. 数据集划分与标准化
使用 train_test_split 方法将数据划分为训练集(80%)和测试集(20%)。
3. 模型训练与预测
使用DecisionTreeClassifier(默认深度)对训练集进行拟合,得到分类模型。
在测试集上进行预测,计算模型的准确率。
4. 决策树可视化
使用plot_tree方法可视化决策树,展示决策树的结构和分类规则。
5. 模型深度调优
测试不同的树深度(从1到10),观察树深度对训练集和测试集准确率的影响。
绘制不同深度下的准确率曲线,选择最佳的树深度。
6. 最佳深度模型训练与评估
使用找到的最佳深度重新训练决策树模型。
评估并输出测试集的准确率。
7. 最佳决策树可视化与规则提取
可视化最佳深度下的决策树。
输出最佳深度决策树的规则,以便分析模型如何做出决策。
实验结果展示
基础决策树准确率:显示模型在测试集上的准确率
不同深度下的训练与测试准确率:显示不同深度下训练集和测试集的准确率曲线。
最佳决策树的可视化:使用plot_tree绘制最佳深度下的决策树图,展示每个节点的决策规则和类别分布。通过图形化形式直观展示决策树如何根据特征进行分类。
代码参考
导入必要的库
import numpy as np # 导入numpy,用于数值计算
import matplotlib.pyplot as plt # 导入matplotlib.pyplot,用于绘制图表
from sklearn.datasets import load_iris # 导入sklearn.datasets中的load_iris函数,用于加载Iris数据集
from sklearn.model_selection import train_test_split # 导入train_test_split函数,用于数据集划分
from sklearn.tree import DecisionTreeClassifier, export_text, plot_tree # 导入决策树分类器和相关函数
from sklearn.metrics import accuracy_score # 导入accuracy_score函数加载鸢尾花数据集(Iris Dataset)
iris = load_iris()
X = iris.data
y = iris.target数据划分
分为训练集和测试集,测试集占比为 20%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)基础模型训练
使用默认深度的决策树分类器
clf_base = DecisionTreeClassifier(random_state=42)
clf_base.fit(X_train, y_train)
图1
预测和评估模型的基础准确率
y_pred_base = clf_base.predict(X_test)
y_pred_base
base_accuracy = accuracy_score(y_test, y_pred_base)
print(f"基础模型准确率: {base_accuracy:.2f}")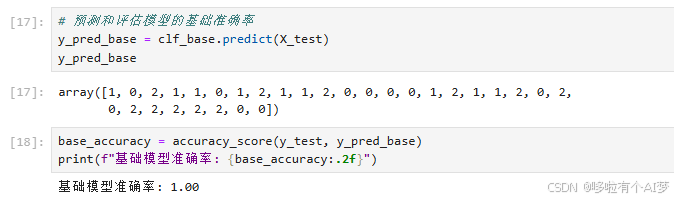
图2
可视化基础决策树
import matplotlib.pyplot as plt
from matplotlib import rcParams
# 配置中文字体
rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 可视化基础决策树
plt.figure(figsize=(12, 8)) # 创建一个12x8英寸的图形窗口
plot_tree(
clf_base,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True
) # 绘制决策树
plt.title("基础决策树", fontsize=16, pad=20) # 设置中文标题,增加与图的间距
plt.subplots_adjust(top=0.9) # 手动调整顶部边距,确保标题显示
plt.show() # 显示图形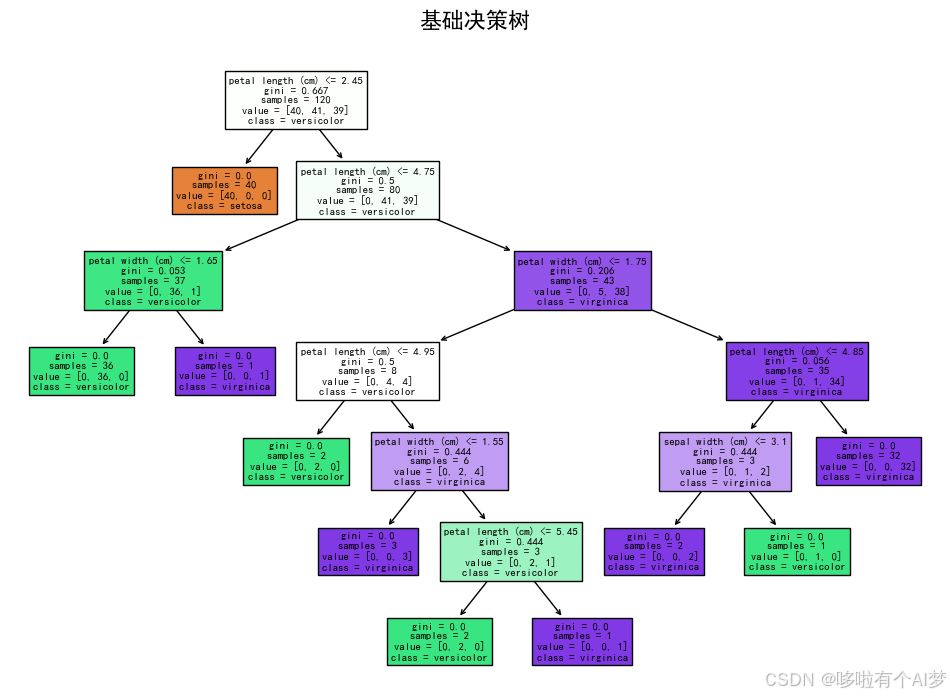
图3
打印决策树的规则
# 导出决策树的规则为文本格式
tree_rules = export_text(clf_base, feature_names=iris.feature_names)
# 打印决策树的规则
print("基础决策树规则:\n", tree_rules)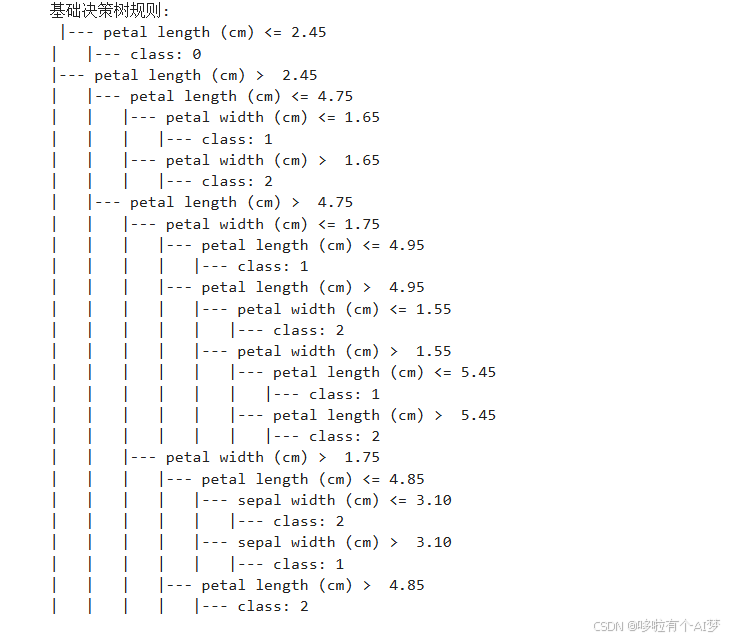
图4
深度优化实验
测试不同深度下的准确率
# 设置测试的决策树深度范围,从1到10
max_depth_range = range(1, 11)
train_accuracies = []
test_accuracies = []
for depth in max_depth_range:
clf = DecisionTreeClassifier(max_depth=depth, random_state=42)# 创建一个新的决策树分类器,限制树的最大深度
clf.fit(X_train, y_train)# 训练决策树模型
train_accuracies.append(accuracy_score(y_train, clf.predict(X_train)))# 计算训练集的准确率,将训练集准确率添加到列表中
test_accuracies.append(accuracy_score(y_test, clf.predict(X_test)))# 计算测试集的准确率,将测试集准确率添加到列表中绘制深度与准确率的关系图
rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.figure(figsize=(10, 6)) # 创建一个10x6英寸的图形窗口
plt.plot(max_depth_range, train_accuracies, label="训练集准确率", marker='o', color='lightblue', linestyle='--', linewidth=2) # 训练集曲线
plt.plot(max_depth_range, test_accuracies, label="测试集准确率", marker='s', color='lightpink', linestyle='-', linewidth=2) # 测试集曲线
# 设置轴标签、标题和图例
plt.xlabel("决策树深度", fontsize=12) # 设置x轴标签
plt.ylabel("准确率", fontsize=12) # 设置y轴标签
plt.title("决策树深度与准确率的关系", fontsize=16) # 设置中文标题
plt.legend(fontsize=10) # 显示图例
plt.grid(True, linestyle=':', linewidth=0.7) # 使用虚线网格
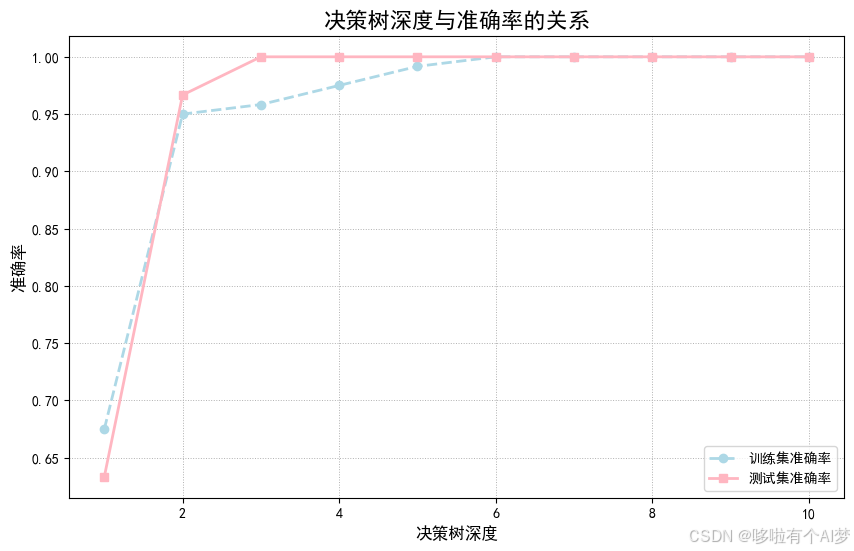
图5
找到测试集准确率最高的深度
best_depth = max_depth_range[np.argmax(test_accuracies)]
print(f"测试集准确率最高的决策树深度: {best_depth}")# 输出最佳深度
图6
使用最佳深度重新训练决策树
clf_best = DecisionTreeClassifier(max_depth=best_depth, random_state=42)# 创建一个决策树分类器,设置最佳深度
clf_best.fit(X_train, y_train)# 使用训练集数据训练模型
# 计算并打印最佳深度模型的准确率
y_pred_best = clf_best.predict(X_test)
best_accuracy = accuracy_score(y_test, y_pred_best)# 计算最佳深度模型在测试集上的准确率
print(f"最佳深度模型的测试集准确率: {best_accuracy:.2f}")# 输出准确率,保留两位小数
图7
可视化最佳深度的决策树
# 配置中文字体
rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 可视化最佳深度的决策树
plt.figure(figsize=(12, 8)) # 创建一个12x8英寸的图形窗口
plot_tree(
clf_best,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True
) # 绘制决策树
# 设置标题,并显示最佳深度
plt.title(f"最佳深度({best_depth})决策树", fontsize=16, pad=20) # 设置中文标题
plt.subplots_adjust(top=0.9) # 手动调整顶部边距,确保标题显示
plt.show() # 显示图形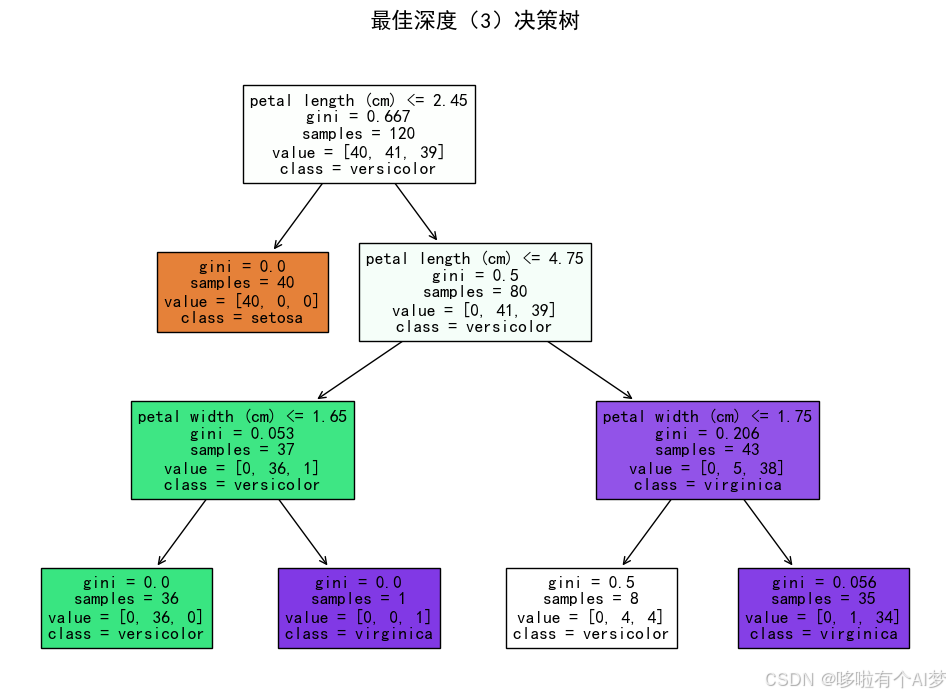
图8
打印最佳深度的决策树规则
best_tree_rules = export_text(clf_best, feature_names=iris.feature_names)# 导出最佳深度的决策树规则
print("最佳深度决策树规则:\n", best_tree_rules)# 打印决策树规则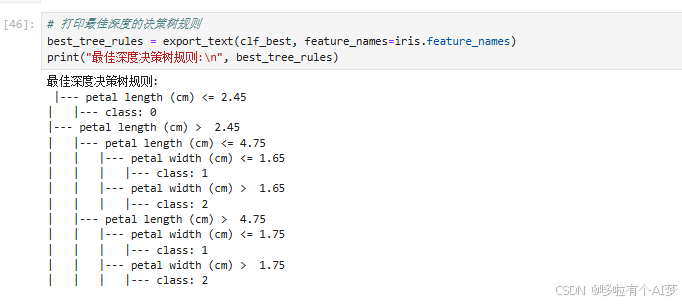
图9
绘制在 iris 数据集上训练的决策树的决策面
# 配置中文字体
rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 加载鸢尾花数据集
iris = load_iris()
# 参数设置
n_classes = 3
plot_colors = "ryb" # 分类颜色
plot_step = 0.02 # 决策边界的步长
# 遍历鸢尾花数据集的特征组合
for pairidx, pair in enumerate([[0, 1], [0, 2], [0, 3], [1, 2], [1, 3], [2, 3]]):
# 选择两个特征
X = iris.data[:, pair]
y = iris.target
# 训练决策树模型
clf = DecisionTreeClassifier().fit(X, y)
# 绘制决策边界
ax = plt.subplot(2, 3, pairidx + 1) # 创建子图
plt.tight_layout(h_pad=0.5, w_pad=0.5, pad=2.5) # 设置布局
DecisionBoundaryDisplay.from_estimator(
clf,
X,
cmap=plt.cm.RdYlBu,
response_method="predict",
ax=ax,
xlabel=iris.feature_names[pair[0]], # X轴标签
ylabel=iris.feature_names[pair[1]], # Y轴标签
)
# 绘制训练数据点
for i, color in zip(range(n_classes), plot_colors):
idx = np.where(y == i)
plt.scatter(
X[idx, 0],
X[idx, 1],
c=color,
label=iris.target_names[i],
edgecolor="black",
s=30, # 增加点的大小,使其更明显
linewidth=1.5
)
# 添加中文标题和图例
plt.suptitle("决策树分类器在特征对上的决策面", fontsize=16) # 设置中文标题(移除pad)
plt.subplots_adjust(top=0.9) # 调整上边距,确保标题显示
plt.legend(loc="lower right", borderpad=0.5, handletextpad=0.5, fontsize=12) # 设置中文图例并调整位置
plt.show()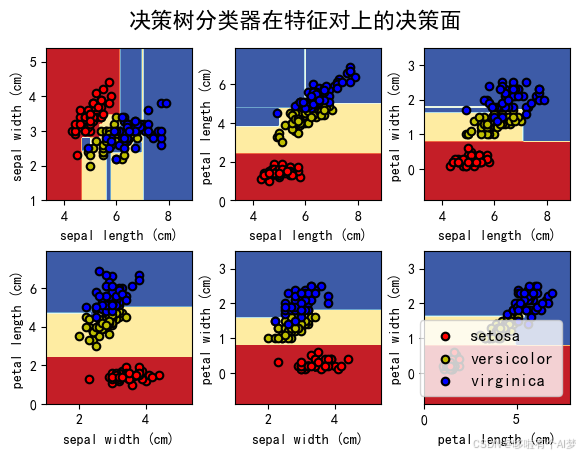
图10

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 33
33 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)