
54、K-Means聚类的原理和算法步骤【用Python进行AI数据分析进阶教程】
摘要:K-Means聚类是一种无监督学习算法,旨在将数据集划分为K个不同的簇,通过迭代方式不断调整簇质心,使每个数据点到所属簇质心的距离之和最小。算法步骤包括随机选择初始簇质心、根据距离分配数据点到最近簇、重新计算并更新簇质心,重复这些步骤直至质心稳定或达到最大迭代次数。关键点在于K值的选择、初始质心的选取以及距离度量方法。数据预处理如标准化或归一化是必要步骤,以避免特征尺度差异影响聚类结果。
用Python进行AI数据分析进阶教程54:
K-Means聚类的原理和算法步骤
关键词:K-Means聚类、无监督学习、簇质心、迭代、欧几里得距离
摘要:K-Means聚类是一种无监督学习算法,旨在将数据集划分为K个不同的簇,通过迭代方式不断调整簇质心,使每个数据点到所属簇质心的距离之和最小。算法步骤包括随机选择初始簇质心、根据距离分配数据点到最近簇、重新计算并更新簇质心,重复这些步骤直至质心稳定或达到最大迭代次数。关键点在于K值的选择、初始质心的选取以及距离度量方法。数据预处理如标准化或归一化是必要步骤,以避免特征尺度差异影响聚类结果。此外,K-Means算法易陷入局部最优解,可多次运行选择最优结果。本文还提供了使用Python和scikit-learn库实现K-Means聚类的示例代码,包括数据生成、模型创建、拟合、获取聚类标签和质心,以及聚类结果的可视化展示。
👉 欢迎订阅🔗
《用Python进行AI数据分析进阶教程》专栏
《AI大模型应用实践进阶教程》专栏
《Python编程知识集锦》专栏
《字节跳动旗下AI制作抖音视频》专栏
《智能辅助驾驶》专栏
《工具软件及IT技术集锦》专栏
一、原理
K-Means聚类是一种无监督学习算法,旨在将给定数据集划分为K个不同的簇(cluster)。其核心思想是通过迭代的方式,不断调整簇的中心(质心),使得每个数据点到其所属簇质心的距离之和最小。
二、算法步骤
- 初始化:随机选择K个数据点作为初始的簇质心。
- 分配数据点:对于数据集中的每个数据点,计算其到各个簇质心的距离,将该数据点分配给距离最近的簇。
- 更新质心:对于每个簇,重新计算其所有数据点的均值,将该均值作为新的簇质心。
- 重复步骤(2)和(3):不断重复分配数据点和更新质心的过程,直到质心不再发生显著变化或达到最大迭代次数。
三、关键点
- K 值的选择:K值决定了最终聚类的数量,需要根据具体问题和数据特点进行选择。
- 初始质心的选择:初始质心的选择会影响最终的聚类结果,不同的初始质心可能导致不同的局部最优解。
- 距离度量:常用的距离度量方法是欧几里得距离,但也可以根据具体问题选择其他距离度量方法。
四、注意点
- 数据预处理:在进行K-Means聚类之前,需要对数据进行预处理,如标准化或归一化,以确保不同特征具有相同的尺度。
- 局部最优解:K-Means算法容易陷入局部最优解,因此可以多次运行算法,选择最优的聚类结果。
五、示例代码
以下是一个使用Python和scikit-learn库实现K-Means聚类的示例代码:
Python脚本
# 导入numpy库,用于数值计算和数组操作
import numpy as np
# 导入matplotlib库的pyplot模块,用于数据可视化
import matplotlib.pyplot as plt
# 从sklearn库的cluster模块中导入KMeans类,用于K-Means聚类算法
from sklearn.cluster import KMeans
# 从sklearn库的datasets模块中导入make_blobs函数,用于生成聚类数据集
from sklearn.datasets import make_blobs
# 定义参数
# 样本数量,即生成的数据点的个数
NUM_SAMPLES = 300
# 聚类中心的数量,也就是要划分的簇的数量
NUM_CENTERS = 4
# 每个簇数据的标准差,控制数据点的分散程度
CLUSTER_STD = 0.60
# 随机数种子,保证每次运行代码生成的随机数据一致
RANDOM_STATE = 0
# 生成示例数据
# 使用make_blobs函数生成数据集
# n_samples指定样本数量,centers指定聚类中心数量,
# cluster_std指定簇的标准差,random_state指定随机数种子
# X是生成的数据点矩阵,_表示忽略生成的标签(因为这里不使用标签)
X, _ = make_blobs(n_samples=NUM_SAMPLES, centers=NUM_CENTERS,
cluster_std=CLUSTER_STD, random_state=RANDOM_STATE)
# 创建K-Means模型
# 使用KMeans类创建一个K-Means聚类模型
# n_clusters指定聚类的数量,random_state指定随机数种子,
# 保证每次运行模型的初始状态一致
kmeans = KMeans(n_clusters=NUM_CENTERS, random_state=RANDOM_STATE)
# 拟合模型
# 使用生成的数据X来训练K-Means模型,让模型学习数据的分布并进行聚类
kmeans.fit(X)
# 获取聚类标签
# labels属性存储了每个数据点所属的簇的标签
# 通过该属性可以知道每个数据点被划分到了哪个簇
labels = kmeans.labels_
# 获取簇质心
# cluster_centers_属性存储了每个簇的质心坐标
# 质心是每个簇数据的中心位置
centroids = kmeans.cluster_centers_
# 可视化聚类结果
# 创建一个新的图形窗口,并设置图形的大小为宽10英寸,高6英寸
plt.figure(figsize=(10, 6))
# 绘制数据点的散点图
# X[:, 0]表示数据点的第一个特征,X[:, 1]表示数据点的第二个特征
# c=labels根据数据点所属的簇标签进行颜色编码
# s=50指定数据点的大小
# cmap='viridis'指定颜色映射,让不同簇的数据点显示不同颜色
# label='Data Points'为图例添加数据点的标签
plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis', label='Data Points')
# 绘制簇质心的散点图
# centroids[:, 0]表示质心的第一个坐标,centroids[:, 1]表示质心的第二个坐标
# c='red'指定质心的颜色为红色
# s=200指定质心的大小
# alpha=0.5指定质心的透明度为0.5
# label='Centroids'为图例添加质心的标签
plt.scatter(centroids[:, 0], centroids[:, 1], (
c='red', s=200, alpha=0.5, label='Centroids'))
# 设置图形的标题为'K-Means Clustering'
plt.title('K-Means Clustering')
# 设置X轴的标签为'Feature 1'
plt.xlabel('Feature 1')
# 设置Y轴的标签为'Feature 2'
plt.ylabel('Feature 2')
# 显示图例,方便区分数据点和质心
plt.legend()
# 显示网格线,方便查看数据点的位置
plt.grid(True)
# 显示绘制好的图形
plt.show()输出 / 打印结果说明
这段代码没有直接的打印输出内容。它的主要功能是生成一个聚类数据集,使用 K-Means 算法对数据进行聚类,然后将聚类结果可视化展示出来。运行代码后,会弹出一个窗口,显示一个散点图,图中不同颜色的点表示不同簇的数据点,红色的大圆点表示每个簇的质心。
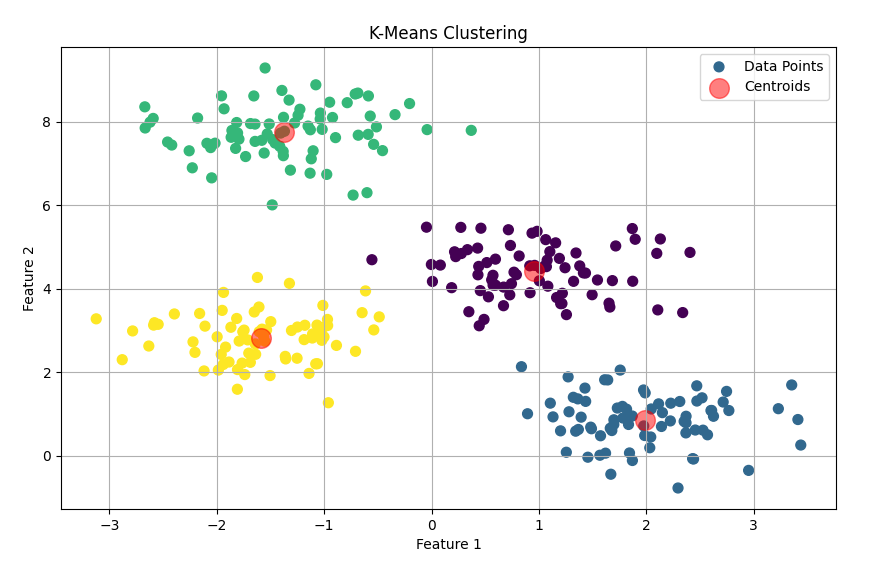
重点语句解读
- X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0):使用make_blobs函数生成一个包含 300 个样本、4 个簇的示例数据集。
- kmeans = KMeans(n_clusters=4, random_state=0):创建一个K-Means模型,指定聚类的数量为 4。
- kmeans.fit(X):使用数据集X拟合K-Means模型。
- labels = kmeans.labels_:获取每个数据点的聚类标签。
- centroids = kmeans.cluster_centers_:获取每个簇的质心。
- plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis'):绘制数据点,根据聚类标签进行颜色编码。
- plt.scatter(centroids[:, 0], centroids[:, 1], c='red', s=200, alpha=0.5):绘制簇质心,用红色表示。
通过以上步骤,你可以使用K-Means算法对数据集进行聚类,并可视化聚类结果。
——The END——
🔗 欢迎订阅专栏
| 序号 | 专栏名称 | 说明 |
|---|---|---|
| 1 | 用Python进行AI数据分析进阶教程 | 《用Python进行AI数据分析进阶教程》专栏 |
| 2 | AI大模型应用实践进阶教程 | 《AI大模型应用实践进阶教程》专栏 |
| 3 | Python编程知识集锦 | 《Python编程知识集锦》专栏 |
| 4 | 字节跳动旗下AI制作抖音视频 | 《字节跳动旗下AI制作抖音视频》专栏 |
| 5 | 智能辅助驾驶 | 《智能辅助驾驶》专栏 |
| 6 | 工具软件及IT技术集锦 | 《工具软件及IT技术集锦》专栏 |
👉 关注我 @理工男大辉郎 获取实时更新
欢迎关注、收藏或转发。
敬请关注 我的
微信搜索公众号:cnFuJH
CSDN博客:理工男大辉郎
抖音号:31580422589

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 61
61 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)