
路透社数据集
文章目录路透社数据集简介keras中使用路透社数据集加载数据集准备数据数据样本向量化标签向量化创建验证集构建网络编译模型训练模型绘制训练损失和验证损失绘制训练精度和验证精度评估模型预测路透社数据集简介路透社数据集包含许多短新闻及其对应的主题,由路透社在 1986 年发布。它是一个简单的、广泛使用的文本分类数据集。它包括 46 个不同的主题:某些主题的样本更多,但训练集中每个主题都有至少 10 个样
文章目录
路透社数据集简介
路透社数据集包含许多短新闻及其对应的主题,由路透社在 1986 年发布。它是一个简单的、广泛使用的文本分类数据集。它包括 46 个不同的主题:某些主题的样本更多,但训练集中每个主题都有至少 10 个样本。
有 8982 个训练样本和 2246 个测试样本
keras中使用路透社数据集
与 IMDB 和 MNIST 类似,路透社数据集也内置为 Keras 的一部分
加载数据集
参数 num_words=10000 将数据限定为前 10 000 个最常出现的单词
有 8982 个训练样本和 2246 个测试样本
每个样本都是一个整数列表(表示单词索引)
样本对应的标签是一个 0~45 范围内的整数,即话题索引编号
from keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
# 查看数据
print(len(train_data))
print(len(test_data))
# 输出第十个数据
print(train_data[10])
# 输出第十个数据的标签
print(train_labels[10])
准备数据
数据样本向量化
import numpy as np
# 数据向量化
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
标签向量化
将标签向量化有两种方法:
- 将标签列表转换为整数张量
- 使用 one-hot 编码,one-hot 编码是分类数据广泛使用的一种格式,也叫分类编码(categorical encoding)
在这个例子中,标签的 one-hot 编码就是将每个标签表示为全零向量,只有标签索引对应的元素为 1。
# 标签向量化
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
one_hot_train_labels = to_one_hot(train_labels)
one_hot_test_labels = to_one_hot(test_labels)
标签向量化可以使用Keras 内置方法
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
另一种编码标签的方法,就是将其转换为整数张量
y_train = np.array(train_labels)
y_test = np.array(test_labels)
创建验证集
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]
构建网络
网络的最后一层是大小为 46 的 Dense 层。这意味着,对于每个输入样本,网络都会输
出一个 46 维向量。这个向量的每个元素(即每个维度)代表不同的输出类别。
最后一层使用了 softmax 激活。网络将输出在 46个不同输出类别上的概率分布——对于每一个输入样本,网络都会输出一个 46 维向量,其中 output[i] 是样本属于第 i 个类别的概率。46 个概率的总和为 1。
对于这个例子,最好的损失函数是 categorical_crossentropy(分类交叉熵)。它用于衡量两个概率分布之间的距离,这里两个概率分布分别是网络输出的概率分布和标签的真实分布。通过将这两个分布的距离最小化,训练网络可使输出结果尽可能接近真实标签。
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
编译模型
使用one-hot编码对标签进行向量化时使用的损失函数为categorical_crossentropy
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
对于将标签列表转换为整数张量这种编码方法,唯一需要改变的是损失函数的选择。对于整数标签,应该使用sparse_categorical_crossentropy。
model.compile(optimizer='rmsprop',
loss='sparse_categorical_crossentropy',
metrics=['acc'])
训练模型
history = model.fit(partial_x_train,
partial_y_train,
epochs=50,
batch_size=128,
validation_data=(x_val, y_val))
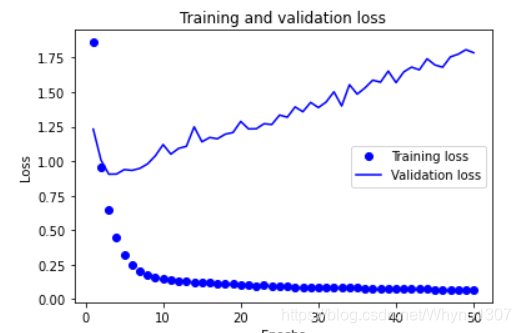
绘制训练损失和验证损失
import matplotlib.pyplot as plt
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
绘制训练精度和验证精度
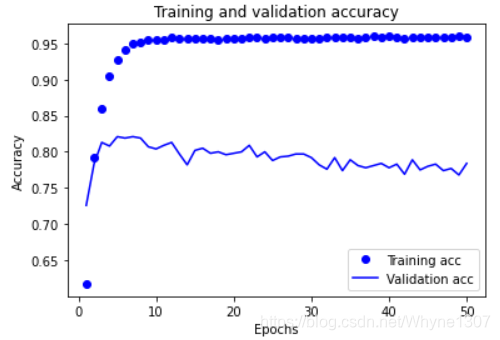
plt.clf() # 清空图像
acc = history.history['acc']
val_acc = history.history['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
评估模型
results = model.evaluate(x_test, one_hot_test_labels)
print(results)
预测
predictions = model.predict(x_test)
print(predictions)

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)