
[VL | RIS ]LAVT:Language-Aware Vision Transformer for Referring Image Segmentation
Swin Transformer 采用 pixel-word attention module (PWAM) 模块进行多模态融合。语言门 Language gate (LG),用于管理语言在语言路径 Language pathway (LP) 上的信息流动。拼接后的特征图做两个 conv 3x3 + Batch Norm + ReLU。PWAM:conv 1x1 + ReLU 视觉特征和多模态注意
1. BaseInfo
| Title | LAVT: Language-Aware Vision Transformer for Referring Image Segmentation |
| Adress | https://arxiv.org/abs/2112.02244 |
| Journal/Time | CVPR 2022 |
| Author | University of Oxford, Shanghai AI Laboratory |
| Code | https://github.com/yz93/LAVT-RIS |
| Read | 2024/07/29 |
| Table | #RS #Seg |
加上 3D 视频再投了 2024 TPAMI Language-Aware Vision Transformer for Referring Segmentation。
2. Creative Q:A
- 特征编码后的融合只起到了模态对齐 -> 对视觉和语言同时编码

主要两个模块 PWAM 视觉语言融合模块,res_gate 门控模块。
3. Concrete
3.1. Model
![![[LAVT-f2.png]]](https://i-blog.csdnimg.cn/direct/d9e1deffda5c47898085aae725db9418.png)
在 encoder 里做融合
属于是串行的,语言视觉融合完的特征图再送入 encoder 继续提取特征。
3.1.1. Input
图片+文本
3.1.2. Backbone
Swin Transformer + BERT
Swin Transformer 采用 pixel-word attention module (PWAM) 模块进行多模态融合
-
PWAM:conv 1x1 + ReLU 视觉特征和多模态注意力的结果做点乘
感觉这个模块就很像 CrossAttention。![![[LAVT-f3.png]]](https://i-blog.csdnimg.cn/direct/f76abe36192947f28c3157350a79ba94.png)
-
语言门 Language gate (LG),用于管理语言在语言路径 Language pathway (LP) 上的信息流动。
![![[LAVT-f4.png]]](https://i-blog.csdnimg.cn/direct/ff944f4b1d3747e1a8935a0f8e6f88bf.png)
nn.Linear(dim, dim, bias=False),
nn.ReLU(),
nn.Linear(dim, dim, bias=False),
nn.Tanh()
3.1.3. Neck
3.1.4. Decoder
双线性上采样插值后的特征图和前一个拼接,以此类推。
拼接后的特征图做两个 conv 3x3 + Batch Norm + ReLU
最终利用 conv 1x1 做 2 分类
3.1.5. Loss
CE
3.2. Training
Swin Transformer - ImageNet-22K 维度 512
BERT,12层,维度 768
CE-loss,AdamW weight_decay: 0.01 lr: 0.00005
40 个 epoch,batch 32
img_size : 480 (no_augment)
3.2.1. Resource
3.2.2 Dataset
| Name | Number | Size | Task | Note |
|---|---|---|---|---|
| RefCOCO | 19,994 | - | Referring Expression Segmentation | |
| RefCOCO+ | 19,992 | - | ||
| G-Ref | 26,711 | 比前两个的句子表达长,object少 |
3.3. Eval
verall intersectionover-union (oIoU),
mean intersection-over-union (mIoU),
precision at the 0.5, 0.7, and 0.9 threshold values.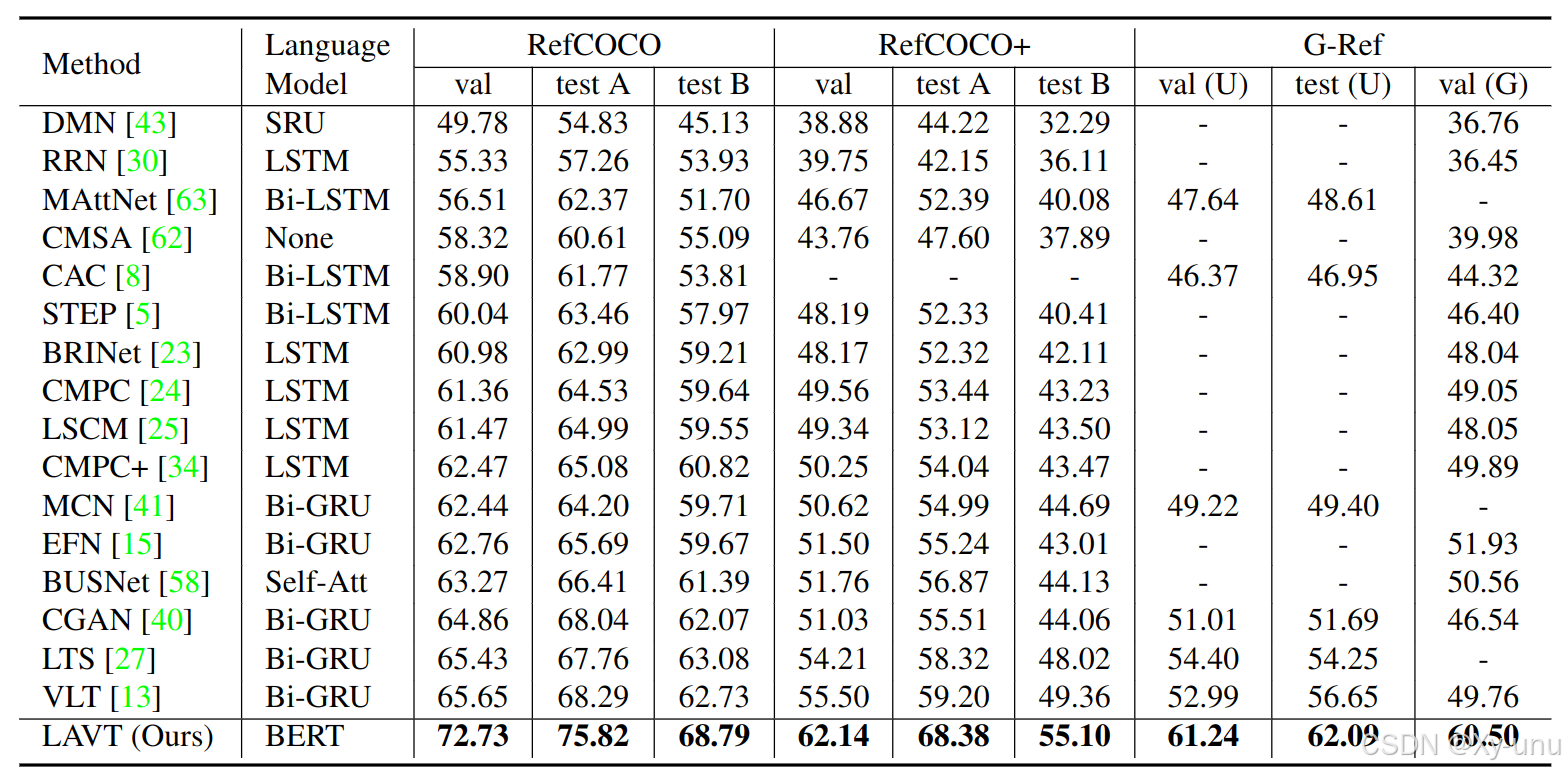
3.4. Ablation
- 语言路径 LP
- 像素-单词注意力模块 PWAM
- 语言门中的激活函数
- PWAM 中的归一化层
- 用于预测的特征
- 多模态注意力模块
4. Reference
[5] Ding-Jie Chen, Songhao Jia, Yi-Chen Lo, Hwann-Tzong Chen, and Tyng-Luh Liu. See-through-text grouping for referring image segmentation. In ICCV, 2019. 1, 2, 6
[13] Henghui Ding, Chang Liu, Suchen Wang, and Xudong Jiang. Vision-language transformer and query generation for referring segmentation. In ICCV, 2021. 1, 2, 6, 8
结合 Swin-Transformer 的 LAVT: Language-Aware Vision Transformer for Referring Image Segmentation 论文笔记
5. Additional
5.1. RIS
参考图像分割 (RIS)和参考表达式理解(REC)
Referring Image Detection and Segmentation
Remote Sensing Referring Image Detection and Segmentation
5.2. Chatter
消融实验的内容非常充分。
语言模型中潜在的歧义。
建议使用 mIoU 更公平。
属于是 RIS 系列的经典之作,结构创新,效果显著。大道至简了属于是。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)