
初学者必看Python基础入门 基础语法和变量类型_python基础语法和变量类型
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。需要这份系统化的资料的朋友,可以戳这里获取一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!print(‘5 ** 2 =’, 5 ** 2)#
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
print(‘5 ** 2 =’, 5 ** 2) # 5 ** 2 = 25
复制代码
字符串
字符串或串(String)是由数字、字母、下划线组成的一串字符。一般是用单引号 `''` 或者 `""` 括起来。
注意,Python 没有单独的字符类型,一个字符就是长度为 1 的字符串。并且,Python 字符串是不可变,向一个索引位置赋值,如 `strs[0]='m'` 会报错。
可以通过索引值或者切片来访问字符串的某个或者某段元素,注意索引值从 0 开始,例子如下所示:
##
切片的格式是 `[start:end]`,实际取值范围是 `[start:end)` ,即不包含 `end` 索引位置的元素。还会除了正序访问,还可以倒序访问,即索引值可以是负值。
具体示例如下所示:
s1 = “talk is cheap”
s2 = ‘show me the code’
print(s1)
print(s2)
索引值以 0 为开始值,-1 为从末尾的开始位置
print('输出 s1 第一个到倒数第二个的所有字符: ', s1[0:-1]) # 输出第一个到倒数第二个的所有字符
print('输出 s1 字符串第一个字符: ', s1[0]) # 输出字符串第一个字符
print('输出 s1 从第三个开始到第六个的字符: ', s1[2:6]) # 输出从第三个开始到第六个的字符
print(‘输出 s1 从第三个开始的后的所有字符:’, s1[2:]) # 输出从第三个开始的后的所有字符
加号 + 是字符串的连接符
星号 * 表示复制当前字符串,紧跟的数字为复制的次数
str = "I love python "
print(“连接字符串:”, str + “!!!”)
print(“输出字符串两次:”, str * 2)
反斜杠 \ 转义特殊字符
若不想让反斜杠发生转义,可以在字符串前面添加一个 r
print(‘I\nlove\npython’)
print(“反斜杠转义失效:”, r’I\nlove\npython’)
复制代码
注意:
* 1、反斜杠可以用来转义,**使用 r 可以让反斜杠不发生转义**。
* 2、字符串可以用 + 运算符连接在一起,用 \* 运算符重复。
* 3、Python 中的字符串有两种索引方式,从左往右以 0 开始,从右往左以 -1 开始。
* 4、Python 中的**字符串不能改变**。
字符串包含了很多内置的函数,这里只介绍几种非常常见的函数:
* **strip(x)**:当包含参数 `x` 表示删除句首或者句末 `x` 的部分,否则,就是删除句首和句末的空白字符,并且可以根据需要调用 `lstrip()` 和 `rstrip()` ,分别删除句首和句末的空白字符;
* **split()**:同样可以包含参数,如果不包含参数就是将字符串变为单词形式,如果包含参数,就是根据参数来划分字符串;
* **join()**:主要是将其他类型的集合根据一定规则变为字符串,比如列表;
* **replace(x, y)**:采用字符串 `y` 代替 `x`
* **index()**:查找指定字符串的起始位置
* **startswith() / endswith()**:分别判断字符串是否以某个字符串为开始,或者结束;
* **find()**:查找某个字符串;
* **upper() / lower() / title()**:改变字符串的大小写的三个函数
下面是具体示例代码:
strip()
s3 = " I love python "
s4 = “show something!”
print('输出直接调用 strip() 后的字符串结果: ', s3.strip())
print('lstrip() 删除左侧空白后的字符串结果: ', s3.lstrip())
print(‘rstrip() 删除右侧空白后的字符串结果: ‘, s3.rstrip())
print(‘输出调用 strip(’!’)后的字符串结果: ‘, s4.strip(’!’))
split()
s5 = ‘hello, world’
print(‘采用split()的字符串结果: ‘, s5.split())
print(‘采用split(’,’)的字符串结果: ‘, s5.split(’,’))
join()
l1 = [‘an’, ‘apple’, ‘in’, ‘the’, ‘table’]
print('采用join()连接列表 l1 的结果: ‘, ‘’.join(l1))
print(‘采用’-’.join()连接列表 l1 的结果: ', ‘-’.join(l1))
replace()
print('replace(‘o’, ‘l’)的输出结果: ', s5.replace(‘o’, ‘l’))
index()
print('s5.index(‘o’)的输出结果: ', s5.index(‘o’))
startswith() / endswith()
print('s5.startswith(‘h’)的输出结果: ', s5.startswith(‘h’))
print('s5.endswith(‘h’)的输出结果: ', s5.endswith(‘h’))
find()
print('s5.find(‘h’)的输出结果: ', s5.find(‘h’))
upper() / lower() / title()
print('upper() 字母全大写的输出结果: ', s5.upper())
print('lower() 字母全小写的输出结果: ', s5.lower())
print('title() 单词首字母大写的输出结果: ', s5.title())
复制代码
列表
列表是 Python 中使用最频繁的数据类型,它可以完成大多数集合类的数据结构实现,可以包含不同类型的元素,包括数字、字符串,甚至列表(也就是所谓的嵌套)。
和字符串一样,可以通过索引值或者切片(截取)进行访问元素,索引也是从 0 开始,而如果是倒序,则是从 -1 开始。列表截取的示意图如下所示:
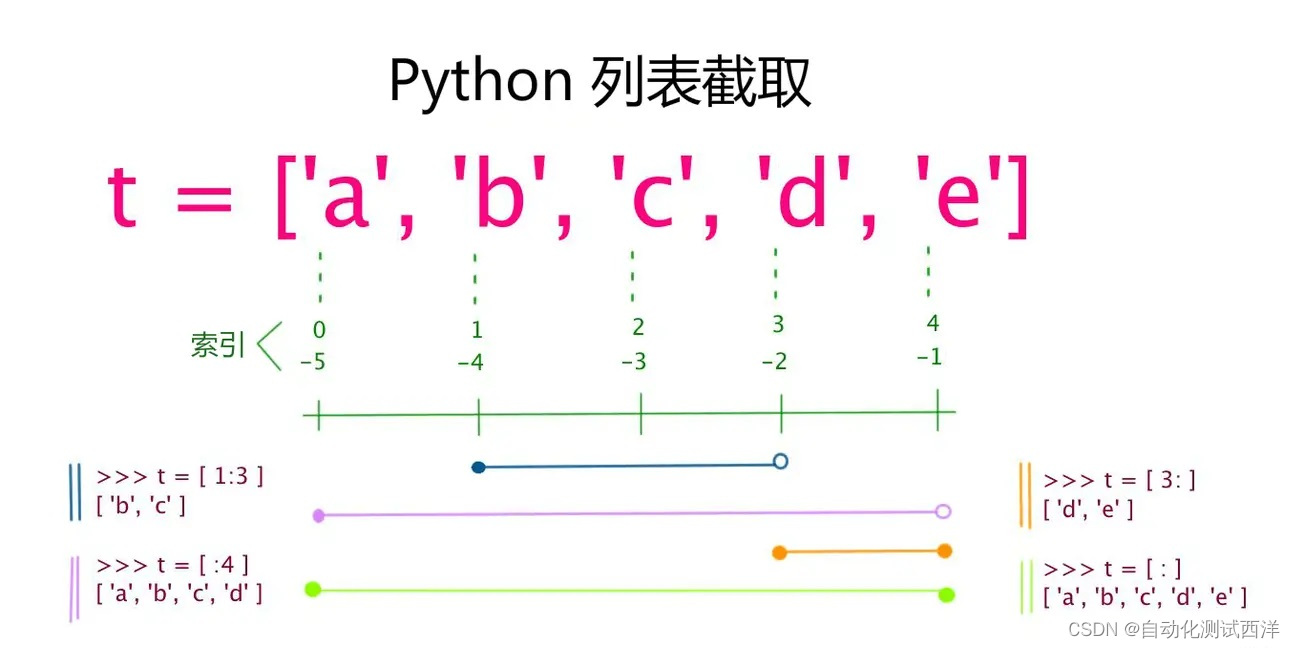
另外,还可以添加第三个参数作为步长:

同样,列表也有很多内置的方法,这里介绍一些常见的方法:
* **len(list)**:返回列表的长度
* **append(obj) / insert(index, obj) / extend(seq)**:增加元素的几个方法
* **pop() / remove(obj) / del list[index] / clear()**:删除元素
* **reverse() / reversed**:反转列表
* **sort() / sorted(list)**:对列表排序,注意前者会修改列表内容,后者返回一个新的列表对象,不改变原始列表
* **index()**:查找给定元素第一次出现的索引位置
初始化列表的代码示例如下:
创建空列表,两种方法
list1 = list()
list2 = []
初始化带有数据
list3 = [1, 2, 3]
list4 = [‘a’, 2, ‘nb’, [1, 3, 4]]
print(‘list1:’, list1)
print(‘list2:’, list2)
print(‘list3:’, list3)
print(‘list4:’, list4)
print('len(list4): ', len(list4))
复制代码
添加元素的代码示例如下:
末尾添加元素
list1.append(‘abc’)
print(‘list1:’, list1)
末尾添加另一个列表,并合并为一个列表
list1.extend(list3)
print(‘list1.extend(list3), list1:’, list1)
list1.extend((1, 3))
print(‘list1.extend((1,3)), list1:’, list1)
通过 += 添加元素
list2 += [1, 2, 3]
print(‘list2:’, list2)
list2 += list4
print(‘list2:’, list2)
在指定位置添加元素,原始位置元素右移一位
list3.insert(0, ‘a’)
print(‘list3:’, list3)
末尾位置添加,原来末尾元素依然保持在末尾
list3.insert(-1, ‘b’)
print(‘list3:’, list3)
复制代码
删除元素的代码示例如下:
del 删除指定位置元素
del list3[-1]
print(‘del list3[-1], list3:’, list3)
pop 删除元素
pop_el = list3.pop()
print(‘list3:’, list3)
print(‘pop element:’, pop_el)
pop 删除指定位置元素
pop_el2 = list3.pop(0)
print(‘list3:’, list3)
print(‘pop element:’, pop_el2)
remove 根据值删除元素
list3.remove(1)
print(‘list3:’, list3)
clear 清空列表
list3.clear()
print(‘clear list3:’, list3)
复制代码
查找元素和修改、访问元素的代码示例如下:
index 根据数值查询索引
ind = list1.index(3)
print(‘list1.index(3),index=’, ind)
访问列表第一个元素
print('list1[0]: ', list1[0])
访问列表最后一个元素
print('list1[-1]: ', list1[-1])
访问第一个到第三个元素
print('list1[:3]: ', list1[:3])
访问第一个到第三个元素,步长为2
print('list1[:3:2]: ', list1[:3:2])
复制列表
new_list = list1[:]
print(‘copy list1, new_list:’, new_list)
复制代码
排序的代码示例如下:
list5 = [3, 1, 4, 2, 5]
print(‘list5:’, list5)
use sorted
list6 = sorted(list5)
print(‘list6=sorted(list5), list5={}, list6={}’.format(list5, list6))
use list.sort()
list5.sort()
print('list5.sort(), list5: ', list5)
复制代码
**`sorted()` 都不会改变列表本身的顺序**,只是对列表临时排序,并返回一个新的列表对象;
相反,**列表本身的 `sort()` 会永久性改变列表本身的顺序**。
另外,如果列表元素不是单纯的数值类型,如整数或者浮点数,而是字符串、列表、字典或者元组,那么还可以自定义排序规则,这也就是定义中最后两行,例子如下:
列表元素也是列表
list8 = [[4, 3], [5, 2], [1, 1]]
list9 = sorted(list8)
print(‘list9 = sorted(list8), list9=’, list9)
sorted by the second element
list10 = sorted(list8, key=lambda x: x[1])
print(‘list10 = sorted(list8, key=lambda x:x[1]), list10=’, list10)
list11 = sorted(list8, key=lambda x: (x[1], x[0]))
print(‘list11 = sorted(list8, key=lambda x:(x[1],x[0])), list11=’, list11)
列表元素是字符串
list_str = [‘abc’, ‘pat’, ‘cda’, ‘nba’]
list_str_1 = sorted(list_str)
print(‘list_str_1 = sorted(list_str), list_str_1=’, list_str_1)
根据第二个元素排列
list_str_2 = sorted(list_str, key=lambda x: x[1])
print(‘list_str_2 = sorted(list_str, key=lambda x: x[1]), list_str_2=’, list_str_2)
先根据第三个元素,再根据第一个元素排列
list_str_3 = sorted(list_str, key=lambda x: (x[2], x[0]))
print(‘list_str_3 = sorted(list_str, key=lambda x: (x[2], x[0])), list_str_3=’, list_str_3)
复制代码
反转列表的代码示例如下:
反转列表
list5.reverse()
print('list5.reverse(), list5: ', list5)
list7 = reversed(list5)
print(‘list7=reversed(list5), list5={}, list7={}’.format(list5, list7))
#for val in list7:
print(val)
注意不能同时两次
list7_val = [val for val in list7]
print(‘采用列表推导式, list7_val=’, list7_val)
list8 = list5[::-1]
print(‘list5 = {}\nlist_reversed = list5[::-1], list_reversed = {}’.format(list5, list_reversed))
复制代码
`reverse()` 方法会永久改变列表本身,而 `reversed()` 不会改变列表对象,它返回的是一个迭代对象,如例子输出的 `<list_reverseiterator object at 0x000001D0A17C5550>` , 要获取其排序后的结果,需要通过 `for` 循环,或者列表推导式,但需要注意,**它仅仅在第一次遍历时候返回数值**。
以及,一个小小的技巧,**利用切片实现反转**,即 `<list> = <list>[::-1]`。
元组
元组和列表比较相似,不同之处是**元组不能修改,然后元组是写在小括号 `()` 里的**。
元组也可以包含不同的元素类型。简单的代码示例如下:
t1 = tuple()
t2 = ()
t3 = (1, 2, ‘2’, [1, 2], 5)
创建一个元素的元祖
t4 = (7, )
t5 = (2)
print(‘创建两个空元组:t1={}, t2={}’.format(t1, t2))
print(‘包含不同元素类型的元组:t3={}’.format(t3))
print(‘包含一个元素的元祖: t4=(7, )={}, t5=(2)={}’.format(t4, t5))
print(‘type(t4)={}, type(t5)={}’.format(type(t4), type(t5)))
print(‘输出元组的第一个元素:{}’.format(t3[0]))
print(‘输出元组的第二个到第四个元素:{}’.format(t3[1:4]))
print(‘输出元祖的最后一个元素: {}’.format(t3[-1]))
print(‘输出元祖两次: {}’.format(t3 * 2))
print(‘连接元祖: {}’.format(t3 + t4))
复制代码
元祖和字符串也是类似,索引从 0 开始,-1 是末尾开始的位置,可以将字符串看作一种特殊的元组。
此外,从上述代码示例可以看到有个特殊的例子,创建一个元素的时候,必须在元素后面添加逗号,即如下所示:
tup1 = (2,) # 输出为 (2,)
tup2 = (2) # 输出是 2
print(‘type(tup1)={}’.format(type(tup1))) # 输出是 <class ‘tuple’>
print(‘type(tup2)={}’.format(type(tup2))) # 输出是 <class ‘int’>
复制代码
还可以创建一个二维元组,代码例子如下:
创建一个二维元组
tups = (1, 3, 4), (‘1’, ‘abc’)
print(‘二维元组: {}’.format(tups)) # 二维元组: ((1, 3, 4), (‘1’, ‘abc’))
复制代码
然后对于函数的返回值,如果返回多个,实际上就是返回一个元组,代码例子如下:
def print_tup():
return 1, ‘2’
res = print_tup()
print(‘type(res)={}, res={}’.format(type(res), res)) # type(res)=<class ‘tuple’>, res=(1, ‘2’)
复制代码
元组不可修改,但如果元素可修改,那可以修改该元素内容,代码例子如下所示:
tup11 = (1, [1, 3], ‘2’)
print(‘tup1={}’.format(tup11)) # tup1=(1, [1, 3], ‘2’)
tup11[1].append(‘123’)
print(‘修改tup11[1]后,tup11={}’.format(tup11)) # 修改tup11[1]后,tup11=(1, [1, 3, ‘123’], ‘2’)
复制代码
因为元组不可修改,所以仅有以下两个方法:
* **count()**: 计算某个元素出现的次数
* **index()**: 寻找某个元素第一次出现的索引位置
代码例子:
count()
print(‘tup11.count(1)={}’.format(tup11.count(1)))
index()
print(‘tup11.index(‘2’)={}’.format(tup11.index(‘2’)))
复制代码
字典
字典也是 Python 中非常常用的数据类型,具有以下特点:
* 它是一种映射类型,用 `{}` 标识,是**无序**的 **键(key): 值(value)** 的集合;
* 键(key) 必须使用**不可变类型**;
* 同一个字典中,**键必须是唯一的**;
创建字典的代码示例如下,总共有三种方法:
{} 形式
dic1 = {‘name’: ‘python’, ‘age’: 20}
内置方法 dict()
dic2 = dict(name=‘p’, age=3)
字典推导式
dic3 = {x: x**2 for x in {2, 4, 6}}
print(‘dic1={}’.format(dic1)) # dic1={‘age’: 20, ‘name’: ‘python’}
print(‘dic2={}’.format(dic2)) # dic2={‘age’: 3, ‘name’: ‘p’}
print(‘dic3={}’.format(dic3)) # dic3={2: 4, 4: 16, 6: 36}
复制代码
常见的三个内置方法,`keys()`, `values()`, `items()` 分别表示键、值、对,例子如下:
print(‘keys()方法,dic1.keys()={}’.format(dic1.keys()))
print(‘values()方法, dic1.values()={}’.format(dic1.values()))
print(‘items()方法, dic1.items()={}’.format(dic1.items()))
复制代码
其他对字典的操作,包括增删查改,如下所示:
修改和访问
dic1[‘age’] = 33
dic1.setdefault(‘sex’, ‘male’)
print(‘dic1={}’.format(dic1))
get() 访问某个键
print(‘dic1.get(‘age’, 11)={}’.format(dic1.get(‘age’, 11)))
print(‘访问某个不存在的键,dic1.get(‘score’, 100)={}’.format(dic1.get(‘score’, 100)))
删除
del dic1[‘sex’]
print(‘del dic1[‘sex’], dic1={}’.format(dic1))
dic1.pop(‘age’)
print(‘dic1.pop(‘age’), dic1={}’.format(dic1))
清空
dic1.clear()
print(‘dic1.clear(), dic1={}’.format(dic1))
合并两个字典
print(‘合并 dic2 和 dic3 前, dic2={}, dic3={}’.format(dic2, dic3))
dic2.update(dic3)
print(‘合并后,dic2={}’.format(dic2))
遍历字典
dic4 = {‘a’: 1, ‘b’: 2}
for key, val in dic4.items():
print(‘{}: {}’.format(key, val))
不需要采用 keys()
for key in dic4:
print(‘{}: {}’.format(key, dic4[key]))
复制代码
最后,因为字典的键必须是不可改变的数据类型,那么如何快速判断一个数据类型是否可以更改呢?有以下两种方法:
* **id()**:判断变量更改前后的 id,如果**一样**表示**可以更改**,**不一样表示不可更改**。
* **hash()**:如果不报错,表示**可以被哈希**,就**表示不可更改**;否则就是可以更改。
首先看下 `id()` 方法,在一个整型变量上的使用结果:
i = 2
print(‘i id value=’, id(i))
i += 3
print(‘i id value=’, id(i))
复制代码
输出结果,更改前后 id 是更改了,表明整型变量是不可更改的。
i id value= 1758265872
i id value= 1758265968
复制代码
然后在列表变量上进行同样的操作:
l1 = [1, 3]
print(‘l1 id value=’, id(l1))
l1.append(4)
print(‘l1 id value=’, id(l1))
复制代码
输出结果,`id` 并没有改变,说明列表是可以更改的。
l1 id value= 1610679318408
l1 id value= 1610679318408
复制代码
然后就是采用 `hash()` 的代码例子:
hash
s = ‘abc’
print('s hash value: ', hash(s))
l2 = [‘321’, 1]
print('l2 hash value: ', hash(l2))
复制代码
输出结果如下,对于字符串成功输出哈希值,而列表则报错 `TypeError: unhashable type: 'list'`,这也说明了字符串不可更改,而列表可以更改。
s hash value: 1106005493183980421
TypeError: unhashable type: ‘list’
复制代码
集合
集合是一个**无序**的**不重复**元素序列,采用大括号 `{}` 或者 `set()` 创建,但空集合必须使用 `set()` ,因为 `{}` 创建的是空字典。
创建的代码示例如下:
创建集合
s1 = {‘a’, ‘b’, ‘c’}
s2 = set()
s3 = set(‘abc’)
print(‘s1={}’.format(s1)) # s1={‘b’, ‘a’, ‘c’}
print(‘s2={}’.format(s2)) # s2=set()
print(‘s3={}’.format(s3)) # s3={‘b’, ‘a’, ‘c’}
复制代码
注意上述输出的时候,每次运行顺序都可能不同,这是集合的**无序性**的原因。
利用集合可以去除重复的元素,如下所示:
s4 = set(‘good’)
print(‘s4={}’.format(s4)) # s4={‘g’, ‘o’, ‘d’}
复制代码
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
, ‘a’, ‘c’}
print(‘s2={}’.format(s2)) # s2=set()
print(‘s3={}’.format(s3)) # s3={‘b’, ‘a’, ‘c’}
复制代码
注意上述输出的时候,每次运行顺序都可能不同,这是集合的**无序性**的原因。
利用集合可以去除重复的元素,如下所示:
s4 = set(‘good’)
print(‘s4={}’.format(s4)) # s4={‘g’, ‘o’, ‘d’}
复制代码
[外链图片转存中…(img-7bEllQZU-1715307800327)]
[外链图片转存中…(img-fMC7MDeD-1715307800328)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)