
Python爬虫爬取高清壁纸
第一次创作,创作不易,有什么地方写的不对的欢迎大家一起讨论!下面的爬虫主要是爬取《彼岸壁纸》中所有的高清图,各个类型都包含在其中,想要什么类型都可以自己选择下载,下面附上源码,希望大家多多支持!!!import requests,re,osclass Downloadpucture(object):def __init__(self):#请求头self.headers={'Accept': 'te
·
电脑壁纸?手机壁纸?还去各个壁纸网站上去搜索吗?现在不需要了!只需要选择想要的壁纸类型,然后就静静等待一会儿,大量壁纸就保存在你的电脑上,一个爬虫解决你的想要壁纸的烦恼。
该爬虫比较简单,很容易上手,通过接口的方式去获取图片链接地址,其中有正则的运用,不会正则的小伙伴可以去学习一下正则,因为这是爬虫领域很重要的东西,在数据清洗中占领着重要位置,好了,不多说,直接展示代码
import time
import requests, re, os
class Downloadpucture(object):
def __init__(self):
# 请求头
self.headers = {
'User - Agent': 'Mozilla / 5.0(WindowsNT10.0;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / '
'70.0.3538.25Safari / 537.36Core / 1.70.3870.400QQBrowser / 10.8.4405.400'
}
# 选择图片类型
def choosevarise(self):
list = ["rili", "dongman", "fengjing", "meinv", "youxi", "yingshi", "dongtai", "weimei", "sheji", "keai",
"qiche", "huahui",
"dongwu", "jieri", "renwu", "meishi", "shuiguo", "jianzhu", "tiyu", "junshi", "feizhuliu", "qita",
"wangzherongyao", "huyan", "lol"]
LIST = ["0.日历", "1.动漫", "2.风景", "3.美女", "4.游戏", "5.影视", "6.动态", "7.唯美", "8.设计", "9.可爱",
"10.汽车", "11.花卉", "12.动物",
"13.节日", "14.人物", "15.美食", "16.水果", "17.建筑", "18.体育", "19.军事", "20.非主流", "21.其他",
"22.王者荣耀", "23.护眼", "24.LOL"]
print(LIST[0:12])
print(LIST[13:25])
self.choosepath() # 调用路径填写函数
self.choosenum() # 调用图片类型选择函数
self.judge(number, LIST, list) # 调用路径填写函数
# 保存路径,主要对路径做一个判断,判断路径是否填写正确,如果该路径下存在文件夹则跳过,不存在则创建文件夹
def choosepath(self):
global PATH
while True: # 对文件进行判定,文件夹后面是否带“/”,不带则主动添加“/”,因为这儿是为了下面图片下载函数能正确下载到填写的文件夹下
try:
try:
PATH = input("请输入保存路径,具体到某个文件夹:")
gz = r"/$"
rep = re.findall(gz, PATH)[0]
pass
if rep == "/":
pass
else:
pass
except:
PATH += "/"
folder = os.path.exists(PATH)
if not folder:
os.mkdir(PATH) # 创建文件夹
break
else:
break
except:
print("路径错误,请仔细检查路径后重试!!")
print("图片保存路径:%s" % PATH)
# 判断输入的序号是否正确
def choosenum(self):
global number
while True:
try:
number = int(input("请输入要下载的类型图序号:"))
if isinstance(number, int):
if 0 <= number <= 24:
break
else:
print("请输入正确序号!!!")
else:
print("请输入正确序号!!!")
except:
print("请输入正确序号!!!")
# 对页面URL进行处理,主要是爬取的页面URL不一致,进行判断,获取URL
def judge(self, number, LIST, list):
global Url
kd = list[number]
print("你已选择:%s" % LIST[number])
for i in range(1, self.picturepages(kd, number) + 1):
if 0 <= number < 22:
Url = "http://www.netbian.com/%s/index_%d.htm" % (kd, i)
if i == 1:
Url = "http://www.netbian.com/%s/" % kd
else:
pass
elif 22 <= number <= 24:
Url = "http://www.netbian.com/s/%s/index_%d.htm" % (kd, i)
if i == 1:
Url = "http://www.netbian.com/s/%s/" % kd
else:
pass
self.picturenum()
# 获取图片;类型下所有图片的二级链接
def indexdata(self):
rep = requests.get(url=Url, headers=self.headers)
return rep.text
# 正则提取出二级链接下响应页面的三级地址
def picturenum(self):
zz = r'href="/desk/.*?.htm"'
data = re.findall(zz, Downloadpucture.indexdata(self))
global URl
for i in data:
try:
URl = 'http://www.netbian.com%s' % i[6:-1]
self.picturenum2(URl)
time.sleep(1)
except:
pass
#获取真实图片地址
def picturenum2(self,url):
page = requests.get(url, headers=self.headers)
zz = re.findall(r'src=.*?alt',page.text)
print(zz[0][5:-5])
Downloadpucture.download(self, zz[0][5:-5])
# 获取图片所有页数,找到该图片类型下所有的页数
def picturepages(self, kd, number):
if 0 <= number < 22:
req = requests.get(url="http://www.netbian.com/%s/" % kd, headers=self.headers).text
gz = r'.htm">.*?</a><a href="/%s/index_2.htm' % kd
NUM = re.findall(gz, req)[0].split(">")[-2]
PAGE = re.match(r'\d{0,4}', NUM).group()
return int(PAGE)
else:
req = requests.get(url="http://www.netbian.com/s/%s/" % kd, headers=self.headers).text
gz = r'.htm">.*?</a><a href="/s/%s/index_2.htm' % kd
NUM = re.findall(gz, req)[0].split(">")[-2]
PAGE = re.match(r'\d{0,4}', NUM).group()
return int(PAGE)
# 下载图片
def download(self, url):
D = requests.get(url, stream=True)
path = PATH + url[-10:-4] + ".jpg"
with open(path, "wb") as f:
f.write(D.content)
print(url[-10:-4] + ".jpg" + "下载完成!")
if __name__ == "__main__":
a = Downloadpucture()
a.choosevarise()
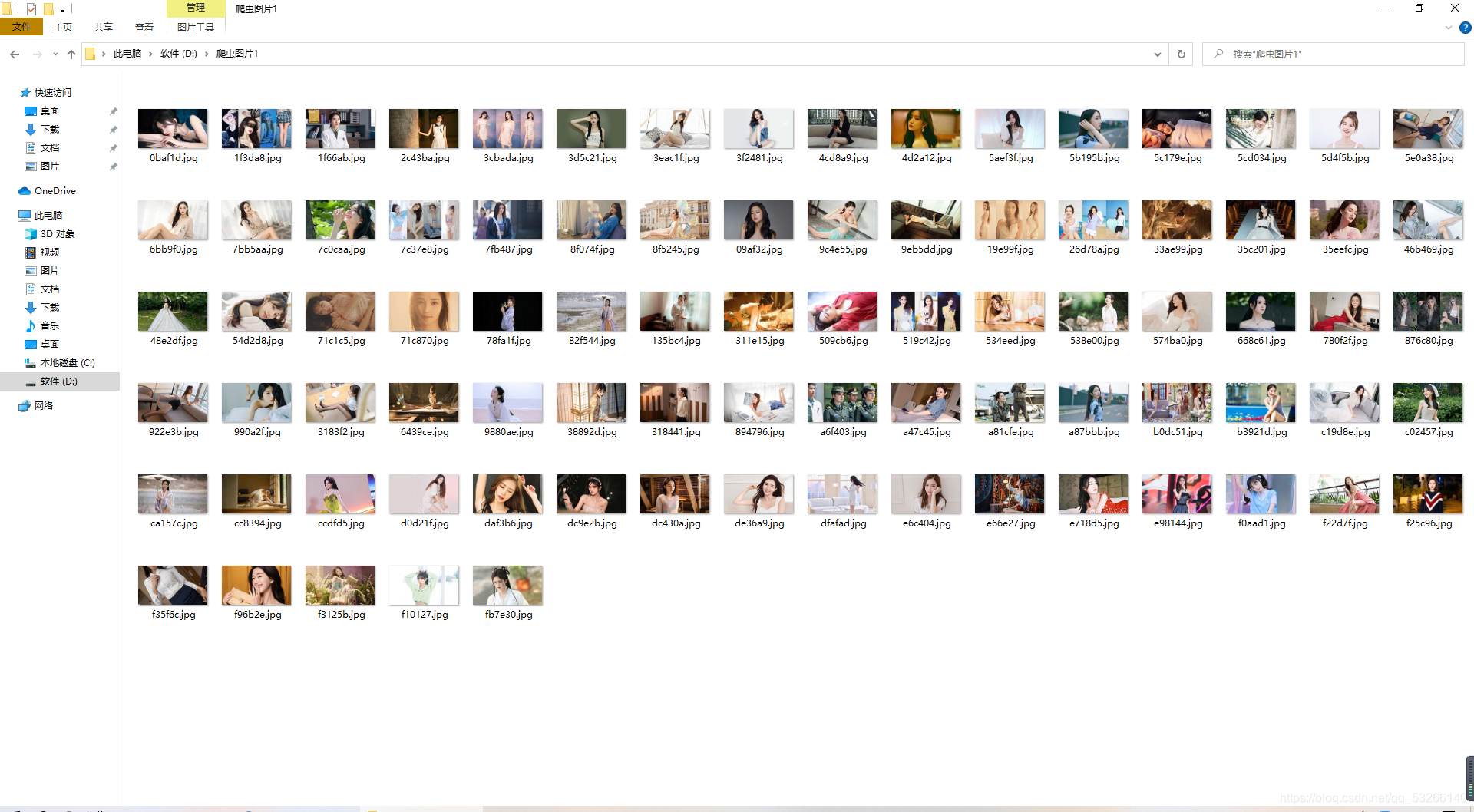
成果真的很nice,再也不用对没有好看的壁纸而烦恼啦!

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)