
2.3 Transformer 模型搭建 Task 05
datawhale AI共学。
datawhale AI共学
1 | 整体思路回顾
目标:把前面已经单测通过的所有组件(Multi-Head Attention、FFN、LayerNorm、残差、Encoder、Decoder)串成一条完整的数据管线,并补上Token Embedding + Positional Encoding。最后接线性层 + Softmax 即得端到端的 Seq2Seq 生成器。
2 | Embedding 层
-
作用:将 token id 查表映射为连续向量。
-
实现:
nn.Embedding(vocab_size, d_model)本质是一个可训练的 (|V| × d) 权重矩阵self.tok_embeddings = nn.Embedding(args.vocab_size, args.n_embd) -
数据形状
-
输入:
(batch, seq_len)整型 id -
输出:
(batch, seq_len, n_embd)浮点向量
-
3 | 位置编码 Positional Encoding
自注意力对序列顺序必须显式注入位置信息
-
公式(正余弦绝对位置)
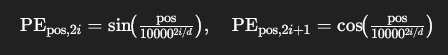
-
优点
-
周期性 → 可外推到比训练序列更长的位置
-
任意距离 kk 的相对位移用三角恒等式表达,方便网络学“距离”概念
-
-
代码核心
class PositionalEncoding(nn.Module): def __init__(self, args): super().__init__() pe = torch.zeros(args.block_size, args.n_embd) position = torch.arange(0, args.block_size).unsqueeze(1) div_term = torch.exp( torch.arange(0, args.n_embd, 2) * -(math.log(10000.0)/args.n_embd)) pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) self.register_buffer("pe", pe.unsqueeze(0)) # 不计入梯度 self.dropout = nn.Dropout(args.dropout) def forward(self, x): x = x + self.pe[:, :x.size(1)] return self.dropout(x)Buffer 的使用意味着 推理阶段不用再计算,节省显存与算力
4 | Encoder-Decoder 框架(Pre-Norm 版)
| 组件 | 顺序 | 是否共享权重 |
|---|---|---|
| Encoder | [LN → SA → +] → [LN → FFN → +] × N |
每层独立 |
| Decoder | [LN → MaskSA → +] → [LN → CrossSA → +] → [LN → FFN → +] × N |
每层独立 |
| 备注 | 采用 Pre-Norm,梯度更稳;Cross-SA 的 K,V 来源于 Encoder 输出 |
5 | 完整 Transformer 类
class Transformer(nn.Module):
def __init__(self, args):
super().__init__()
# ① 嵌入与位置
self.wte = nn.Embedding(args.vocab_size, args.n_embd)
self.wpe = PositionalEncoding(args)
self.drop = nn.Dropout(args.dropout)
# ② Encoder / Decoder 堆叠
self.encoder = Encoder(args)
self.decoder = Decoder(args)
# ③ 词表投影 (共享或独立皆可,这里与输入嵌入不共享)
self.lm_head = nn.Linear(args.n_embd, args.vocab_size, bias=False)
self.apply(self._init_weights) # 权重初始化
-
参数规模:
get_num_params方法统计总量,调试时一眼排 GPU 内存 -
权重初始化:遵循论文 std=0.02,高层更易收敛
def forward(self, idx, targets=None):
# idx: (B, T) int64
tok_emb = self.wte(idx) # (B, T, D)
x = self.drop(self.wpe(tok_emb)) # 加位置并 dropout
enc_out = self.encoder(x) # (B, T, D)
dec_out = self.decoder(x, enc_out) # (B, T, D)
logits = self.lm_head(dec_out) # (B, T, |V|)
if targets is None: # 推理:只要最后一步 logits
return logits[:, -1, :]
# 训练:交叉熵忽略填充索引 -1
loss = F.cross_entropy(
logits.view(-1, logits.size(-1)),
targets.view(-1), ignore_index=-1)
return logits, loss
关键细节
-
Decoder 输入
x可以是 teacher-forcing 的已对齐目标,也可以像 GPT 那样先 pad 后移一位 -
ignore_index=-1让填充 token 不产生梯度 -
推理时只回传最后时间步 logits,可配合 beam search / Top-k 采样
6 | 图片
-
正余弦曲线 展示了不同维度位置编码随 token 位置的波动情况;频率指数递增,保证细粒度与大跨度信息兼备。

-
官方结构图 两条塔状堆叠。注意我们实现的是 Pre-Norm(LayerNorm 在子层前),图中为 Post-Norm
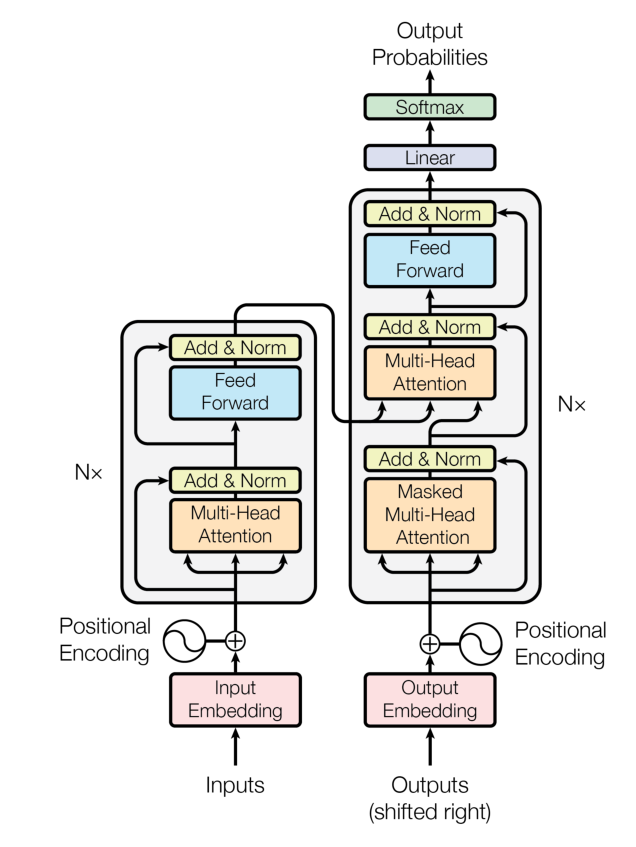
7 | 常见调试片段
| 问题 | 典型症状 | 处理技巧 |
|---|---|---|
| 序列超长 | assert t <= block_size 触发 |
增大 block_size 或截断输入 |
转置后 view 报错 |
RuntimeError: view size is not compatible |
在 transpose 后加 .contiguous() |
| 输出全 NAN | 极有可能梯度爆炸 | 检查 LayerNorm 位置/学习率;确保 mask 中 inf 处理正确 |
8 | 纲要
Embedding → Pos-Enc → Dropout → Encoder(N) → Decoder(N) → Linear → Softmax
既保留了自注意力的全局依赖,又通过 Mask & Cross-Attn 支持自回归生成,是现代 LLM 的祖型。
参考
Vaswani et al., Attention Is All You Need, 2017.
Jay Mody, An Intuition for Attention.

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)