
Vision Transformer(ViT): An Image is Worth 16x16 Words 论文精读
transformer在NLP领域很牛逼,但是在目前自注意力与cnn的结合在图像领域无法进行有效拓展,目前仍然是resnet框架的天下。思路作者的思路是直接把标准Transformer 直接应用于图像,尽量不修改内容。所以,作者将一个图像分割成一个patch,并提供这些patch的线性embeddings序列作为一个Transformer 的输入。图像patch的处理方式与NLP应用程序中的标记(
1.摘要
Transformer在自然语言处理领域很牛逼,但是他们在计算机视觉领域应用少,作者证明了transformer可以不依靠cnn而独立应用于图像领域。使用了多个数据来进行实验。
Transformer广泛用于NLP领域,但它在CV领域的应用仍然有限。
本文证明了transformer可以不依靠cnn而独立应用于图像领域。
vit效果很好。
2. 简介
transformer在NLP领域很牛逼,但是在目前自注意力与cnn的结合在图像领域无法进行有效拓展,目前仍然是resnet框架的天下。
思路作者的思路是直接把标准Transformer 直接应用于图像,尽量不修改内容。所以,作者将一个图像分割成一个patch,并提供这些patch的线性embeddings序列作为一个Transformer 的输入。图像patch的处理方式与NLP应用程序中的标记(单词)的处理方式相同。我们以有监督的方式训练该模型进行图像分类。(就是把一张图分成多个小块,每一块当做一个单词去传入到transformer模型里)

作者试验了一下:在小数据集上,Transformer 缺乏一些cnn固有的归纳偏差,如翻译等方差和局部性,因此在数据量不足的训练下不能很好地泛化。在大数据上,transformer效果很好。(数据少时,会导致模型泛化不足)
3. 相关工作
在处理自然语言时,Transformer通常先在大模型上进行预训练,最后再微调到现有任务。
对图像的纯注意力机制将要求每个像素关注每个其他像素。由于像素数的二次代价,这不能扩展到实际的输入大小。先前的研究人员研究出了几种方案:类似1.只在每个查询像素的局部社区中应用自注意力,而不是全局应用。2.这种局部多头点积自我注意块可以完全取代卷积,3.衡量注意力的方法是将其应用于不同大小的块中(这些在实际应用时太麻烦了)
作者使用的是把大图像切分成小图像,效果牛逼。
4.方法
4.1 视觉Transformer(vit)
标准 Transformer :标准 Transformer 的输入是一维标记嵌入序列 不能吃(sequence of token embeddings)。作者把图像
![]()
转化成了展平的二维补丁,转化为
![]()
,其中
![]()
。这样的话,
patch embeddings:transformer就可以处理我们的图片信息。我们把这个投影输出成为patch embeddings。
[class] token:同时在每个patches序列加入一个可学习的embeddings,他就是加入了一个额外的可学习的嵌入向量,作者称为[class] token,它可以捕捉潜在关系和模式,并且提高模型性能。
position embeddings:这个事位置编码,他被添加到patch embeddings中以保留位置信息。
Transformer encoder:multi-head self-attention和 MLP blocks(方程 2、3)的交替层组成。在每个块之前应用layerNorm (LN),在每个块之后应用残差连接。
归纳偏置: Vision Transformer 比 CNN 具有更少的特定于图像的归纳偏差。
混合架构:作为原始图像patches的替代方案,输入序列可以由 CNN 的feature maps形成。 作为一种特殊情况,patch 的空间大小可以为 1x1,这意味着输入序列是通过简单地将feature maps的空间维度展平并投影到 Transformer 维度来获得的。 如上所述添加了分类输入embedding和position embeddings。
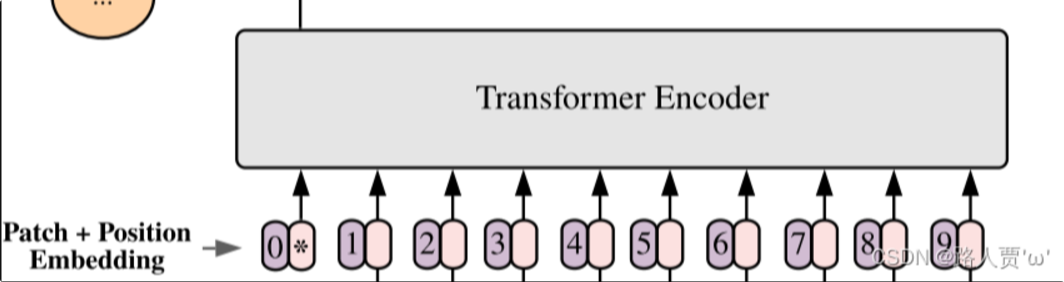
vit模型如下图:
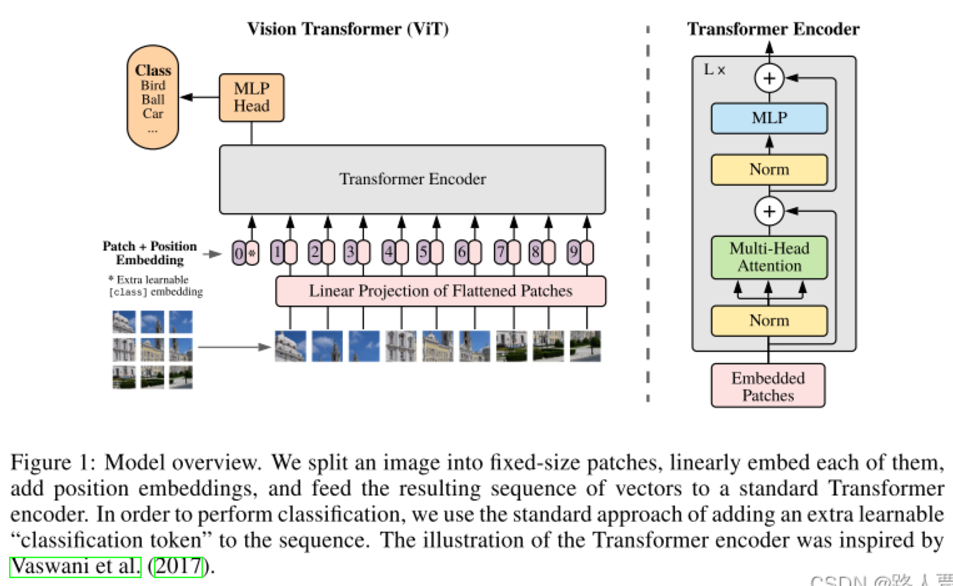
第一步:将图形转化为序列化数据
-
首先输入为一张图片,将图片划分成*9个patch*,然后将每个patch重组成一个向量,得到所谓的*flattened patch*。
-
如果图片是*H×W×C*维的,就用*P×P*大小的patch去分割图片可以得到*N个patch*,那么每个patch的大小就是*P×P×C*,将*N个patch* 重组后的向量concat在一起就得到了一个*N×P×P×C*的二维矩阵,相当于NLP中输入Transformer的词向量。
-
*patch大小变化时,重组后的向量维度也会变化*,作者对上述过程得到的flattened patches向量做了Linear Projection,将不同长度的flattened patch向量转化为固定长度的向量(记作D维向量)。
综上,原本H×W×C 维的图片被转化为了*N个D维*的向量(或者一个N×D维的二维矩阵)。
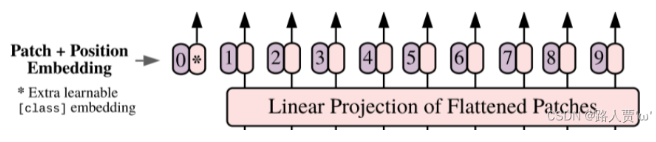
第二步:Position embedding
由于Transformer模型本身是没有位置信息的,和NLP中一样,我们需要用position embedding将位置信息加到模型中去。
如上图所示,编号有0-9的紫色框表示各个位置的position embedding,而紫色框旁边的粉色框则是经过linear projection之后的flattened patch向量。
文中采用将position embedding(即图中紫色框)和patch embedding(即图中粉色框)相加的方式结合position信息。
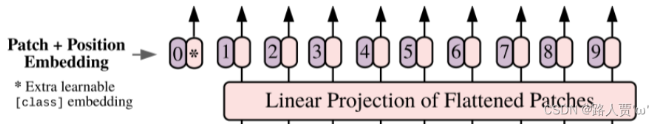
第三步:Learnable embedding
将 patch 输入一个 Linear Projection of Flattened Patches 这个 Embedding 层,就会得到一个个向量,通常就称作 tokens。tokens包含position信息以及图像信息。
紧接着在一系列 token 的前面加上加上一个新的 token,叫做class token,也就是上图带星号的粉色框(即0号紫色框右边的那个),注意这个不是通过某个patch产生的。其作用类似于BERT中的[class] token。在BERT中,[class] token经过encoder后对应的结果作为整个句子的表示;class token也是其他所有token做全局平均池化,效果一样。 第四步Transformer encoder
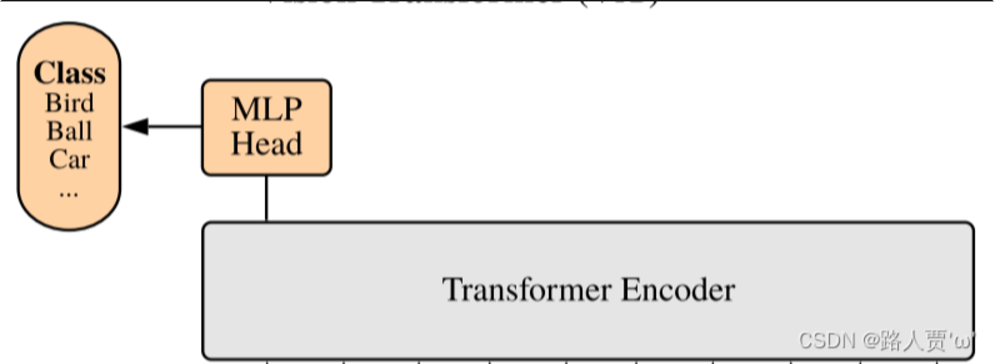
最后输入到 Transformer Encoder 中,对应着右边的图,将 block 重复堆叠 L 次,整个模型也就包括 L 个 Transformer。Transformer Encoder结构和NLP中Transformer结构基本上相同,class embedding 对应的输出经过 MLP Head 进行类别判断。
4.2 fine-tuning(微调)和更大的分辨率
目前作者使用方法存在的问题:
我们在使用大模型进行微调时,他使用的图片分辨率大小是固定的,但是我们在处理实际任务时,它的图片分辨率可能会更高,这意味着图片的长和宽变高了。
如果在微调时图像分辨率增加,而patch的大小保持不变,那么分割得到的patches数量就会增加。
如果图像分辨率增加导致patches数量增加,那么原有的position embeddings就不足以覆盖新增加的patches,因此Position Embeddings变得“不再有意义”。
解决方案:
为了解决这个问题,文章提出了使用2D插值的方法。
2D插值是一种基于原始图像位置信息的技术,可以增加position embeddings的数量,以匹配更高分辨率图像产生的更多patches。()
通过这种方式,不仅能够获得与新的patches数量相匹配的position embeddings,还能保持position embeddings的语义信息,即它们能够正确地反映patches在图像中的位置关系。
5.实验
5.1 实验搭建(参数设置)
数据集: ImageNet,ImageNet-21k,以及JFT、VTAB
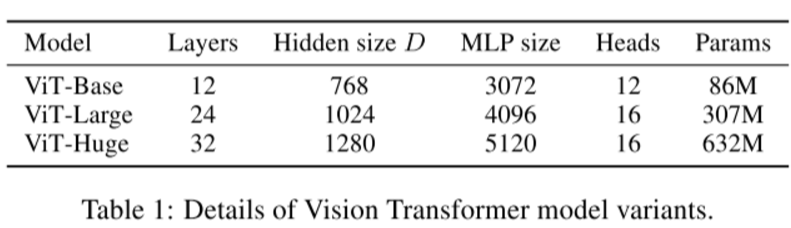
模型: 论文共设计了Base、Large和Huge三款不同大小的ViT模型,分别表示基础模型、大模型和超大模型,三款模型的各参数如下表所示。
-
以BERT使用的ViT配置为基础
-
对于标准CNNs,使用了ResNet,修改后的模型表示为 ResNet(BiT)
-
对于混合体,将中间特征图输入到ViT中
训练&微调:
-
Adam训练、批次大小为4096
-
SGD微调、批量大小为512
衡量标准:少数镜头或微调精度
5.1 实验结果对比
作者使用vit和cnn去进行对比,研究者们拿出了他们最大的两个ViT模型(ViT-H/14和ViT-L/16)与其他顶级的CNN模型进行了对比测试。
第一个对比的是Big Transfer(BiT),它用了很大的ResNet模型来做监督迁移学习。
第二个对比的是Noisy Student,这是一个很大的EfficientNet模型,它在ImageNet和JFT-300M数据集上用半监督学习方法训练,也就是有些数据有标签,有些数据没标签。
实验结果
ViT-L/16模型在JFT-300M数据集上预训练后,在所有任务上的表现都比BiT-L好,而且用的计算资源更少。
更大的ViT-H/14模型在更难的数据集上表现得更好,比如ImageNet、CIFAR-100和VTAB,而且它用的计算资源也比之前的模型少。
作者进一步展示了ViT-H/14在VTAB任务中与其他顶尖方法(比如BiT和VIVI)的比较结果。ViT-H/14在自然和结构化任务上都表现得更好。
实验结果:
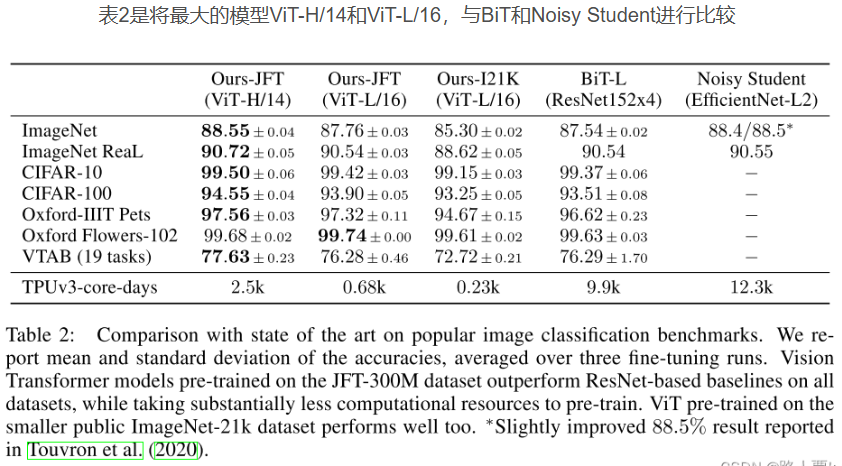
结论:我们的模型计算量要小得多,并且精度更高
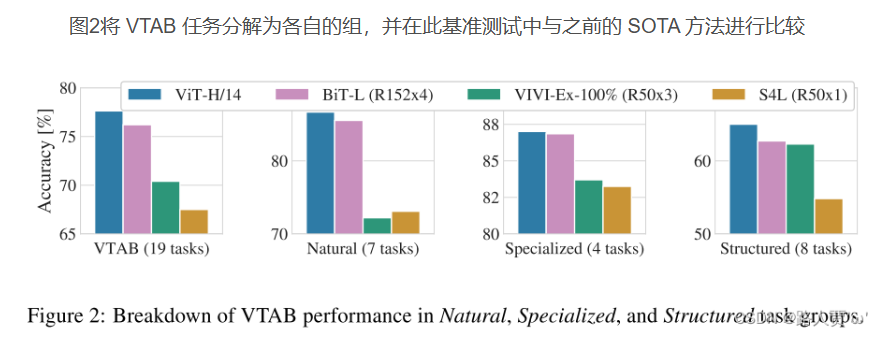
结论:ViT和BiT类似,并高于别的方法
5.2预训练数据要求
作者这个在大数据上使用效果最好,为了强调这一点作者写了这个部分写的这一段。作者使用了大数据集和小数据集进行对比。
ViT在非常大的数据集JFT-300M上进行预训练时,表现得非常好。
与ResNet相比,ViT的“视觉归纳偏差”较少,这意味着ViT不像ResNet那样依赖于图像的一些固有特征(比如局部性、平移不变性等)。
研究者们在不同大小的数据集(ImageNet、ImageNet-21k和JFT-300M)上预训练ViT模型,并发现数据集越大,ViT的表现越好。
在较小的数据集上,ViT需要更多的正则化参数(比如权重衰减、dropout和label smoothing)来避免过拟合。
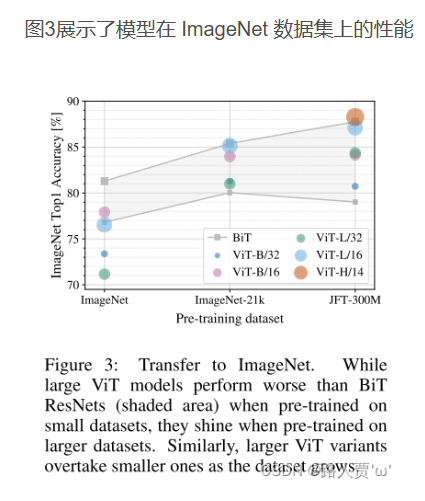
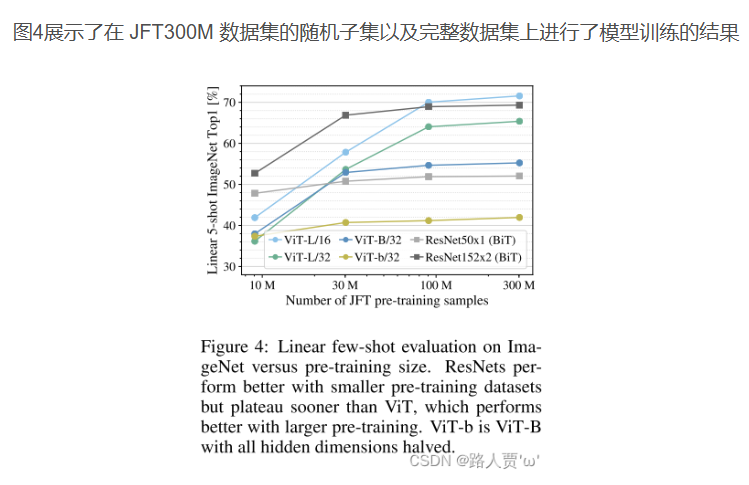
结论:卷积归纳偏置对于规模较小的数据集较为有用,但对于较大的数据集而言,学习相关模式就足够了,甚至更加有效。
5.3缩放研究
作者使用了几种不同的模型,(六种不同版本的VIT,七种不同配置的resnet,以及五种resnet与vit的结合)并且计算它们的表现得分以及成本。结果如下
vit可以用更少的成本达到更好的效果
vit+resnet 虽然也能使用更少的成本达到更好的效果,但是它面对大规模数据时表现效果并不好。
resnet在面对小数据集时效果会有一定的优势,但是在面对大数据集时,效果不如vit.
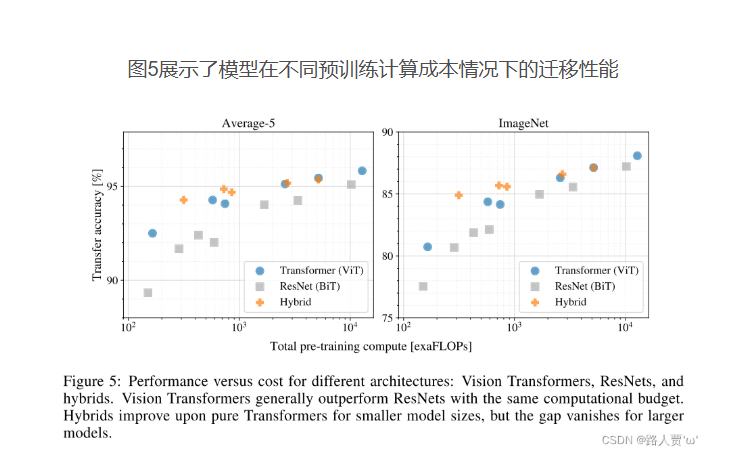
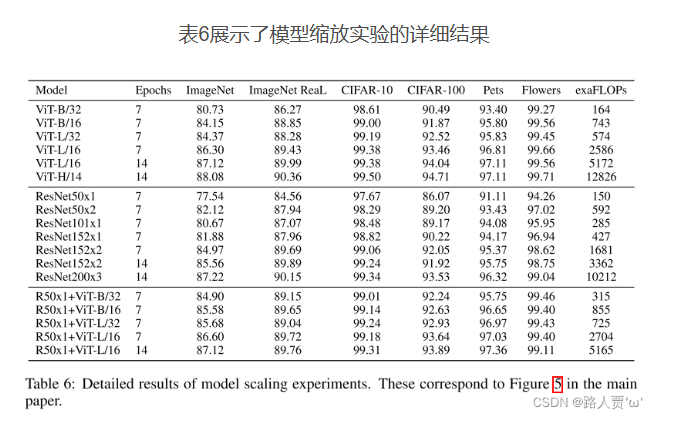
结论:ViT在性能 / 算力权衡中显著优于 ResNet。
5.4 检查vision transformer
为了理解这个vit的具体过程,作者具体分析它的内部结构:vit第一次线性投射扁平的patch到一个低维空间,并且实现过滤器可视化。
投影结束后,将学习到的位置embeding添加到patch表示中。模型通过位置embeding的相似性来学习对图像内的距离进行编码,即越近的斑块往往具有更多相似的位置embeding。同一行/列中的patch具有类似的embeding。
自我注意允许ViT整合整个图像的信息,即使是在最低的层。我们将研究该网络在多大程度上利用了这种能力。具体来说,我们根据注意力权重计算信息在被整合过的图像空间中的平均距离(图7,右)。这种“注意距离”类似于cnn中的接受野大小。我们发现,一些头部关注了已经在最低层的大部分图像,这表明模型确实使用了全局集成信息的能力。其他的注意力头脑在低层的注意距离一直很小。这种高度局部化的注意在transformer之前应用ResNet的混合模型中不那么明显(图7,右),这表明它可能在cnn中具有与早期卷积层类似的功能。此外,注意距离随着网络深度的增加而增加。在全球范围内,我们发现该模型关注的是与分类有语义相关的图像区域(图6)。
图7:左图:ViT-L/32 RGB 值的初始线性embedding滤波器。 中:ViT-L/32 的position embedding的相似性。 右图:按heads和网络深度划分的参与区域大小。
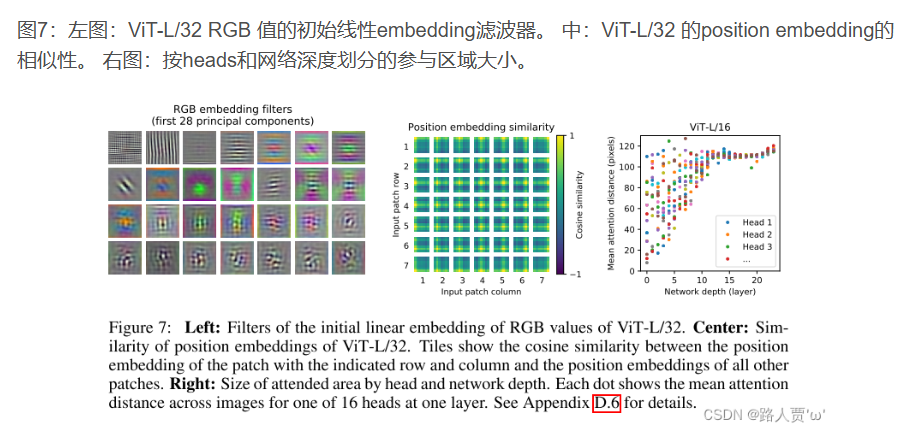

结论:
(1)模型使用了全局集成信息的能力。其他注意力head在低层中始终具有较小的注意力距离
(2)该模型关注与分类语义相关的图像区域
5.5自监督
这个vit之所以牛逼,不仅仅因为他的可伸缩性,更因为他大模型的自我监督和预训练。作者模仿了 BERT 中使用的masked语言建模任务,比从头训练精确度高,但效果还不如监督训练,这就留给未来的探索了。
6 结论
本文工作
本文主要将图片处理成 patch 序列,然后使用 Transformer 去处理,取得了接近或超过卷积神经网络的结果,同时训练起来也更快。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)