
Huggingface transformers库使用教程(翻译)--------GetStarted(1)
你可以修改模型的配置类来改变模型的构建方式。配置指明了模型的属性,比如隐藏层或者注意力头的数量。当你从自定义的配置类初始化模型时,你就开始自定义模型构建了。模型属性是随机初始化的,你需要先训练模型,然后才能得到有意义的结果。通过导入 AutoConfig 来开始,之后加载你想修改的预训练模型。查阅创建一个自定义结构指南获取更多关于构建自定义配置的信息。
参考链接:
https://huggingface.co/docs/transformers/index
本文是对上面链接的翻译,本身有中文版本,本工作主要是更加层次化,并去掉感觉冗余的部分
1. Quick tour
启动并运行 🤗 Transformers!无论您是开发人员还是普通用户,此快速导览都将帮助您入门,并向您展示如何使用 pipeline() 进行推理、使用 AutoClass 加载预训练模型和预处理器,以及使用 PyTorch 或 TensorFlow 快速训练模型。如果您是初学者,我们建议您查看我们的教程或接下来的课程,以更深入地解释此处介绍的概念。
在开始之前,请确保已安装所有必要的库:
!pip install transformers datasets evaluate accelerate
您还需要安装首选的机器学习框架:
Pytorch
pip install torch
TensorFlow
pip install tensorflow
pipeline() 是使用预训练模型进行推理的最简单、最快捷的方法。你可以将 pipeline() 开箱即用地用于不同模式中的许多任务,其中一些任务如下表所示: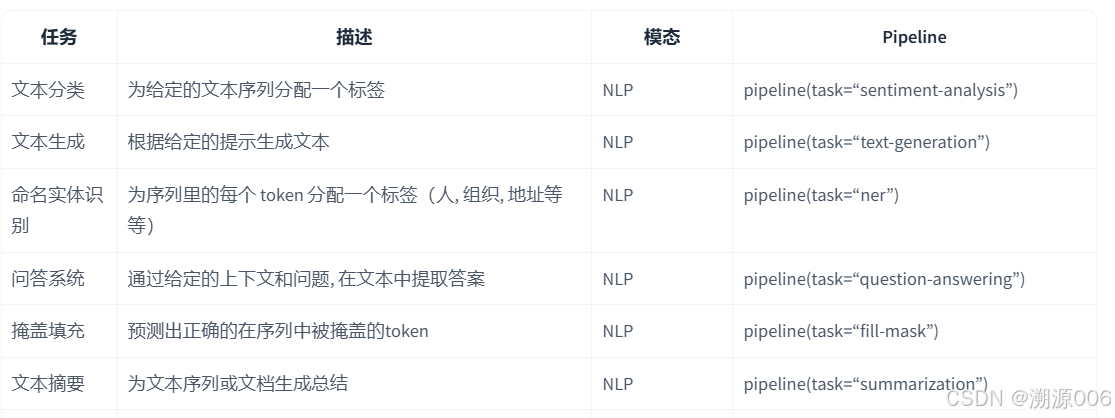
全表请看下面的链接:
添加链接描述
1.1 pipeline()使用例子
1.1.1 情感分析
创建一个 pipeline() 实例并且指定你想要将它用于的任务,就可以开始了。你可以将 pipeline() 用于任何一个上面提到的任务,如果想知道支持的任务的完整列表,可以查阅 pipeline API 参考。不过, 在这篇教程中,你将把 pipeline() 用在一个情感分析示例上:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
pipeline() 会下载并缓存一个用于情感分析的默认的预训练模型和分词器。现在你可以在目标文本上使用 classifier 了:
classifier("We are very happy to show you the 🤗 Transformers library.")
[{'label': 'POSITIVE', 'score': 0.9998}]
如果你有不止一个输入,可以把所有输入放入一个列表然后传给pipeline(),它将会返回一个字典列表:
results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
for result in results:
print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
label: POSITIVE, with score: 0.9998
label: NEGATIVE, with score: 0.5309
1.1.2 在 pipeline 中使用另一个模型和分词器
pipeline() 可以容纳 Hub 中的任何模型,这让 pipeline() 更容易适用于其他用例。比如,你想要一个能够处理法语文本的模型,就可以使用 Hub 上的标记来筛选出合适的模型。靠前的筛选结果会返回一个为情感分析微调的多语言的 BERT 模型,你可以将它用于法语文本:
model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
使用 AutoModelForSequenceClassification 和 AutoTokenizer 来加载预训练模型和它关联的分词器(更多信息可以参考下一节的 AutoClass):
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(model_name) ####加载预训练模型
tokenizer = AutoTokenizer.from_pretrained(model_name) ####加载关联的tokenizer
在 pipeline() 中指定模型和tokenizer,现在你就可以在法语文本上使用 classifier 了:
classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
[{'label': '5 stars', 'score': 0.7273}]
如果你没有找到适合你的模型,就需要在你的数据上微调一个预训练模型了。查看 微调教程 来学习怎样进行微调。最后,微调完模型后,考虑一下在 Hub 上与社区 分享 这个模型,把机器学习普及到每一个人! 🤗
1.2 AutoClass
在幕后,是由 AutoModelForSequenceClassification 和 AutoTokenizer 一起支持你在上面用到的 pipeline()。AutoClass 是一个能够通过预训练模型的名称或路径自动查找其架构的快捷方式。你只需要为你的任务选择合适的 AutoClass 和它关联的预处理类。
1.2.1 AutoTokenizer
分词器负责预处理文本,将文本转换为用于输入模型的数字数组。有多个用来管理分词过程的规则,包括如何拆分单词和在什么样的级别上拆分单词(在 分词器总结 学习更多关于分词的信息)。要记住最重要的是你需要实例化的分词器要与模型的名称相同, 来确保和模型训练时使用相同的分词规则。
使用 AutoTokenizer 加载一个分词器:
from transformers import AutoTokenizer
model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
tokenizer = AutoTokenizer.from_pretrained(model_name)
将文本传入分词器:
encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
print(encoding)
{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
分词器返回了含有如下内容的字典:
- input_ids:用数字表示的 token。
- attention_mask:应该关注哪些 token 的指示。
分词器也可以接受列表作为输入,并填充和截断文本,返回具有统一长度的批次:
pt_batch = tokenizer(
["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
padding=True,
truncation=True,
max_length=512,
return_tensors="pt",
)
1.3 AutoModel
Transformers 提供了一种简单统一的方式来加载预训练的实例. 这表示你可以像加载 AutoTokenizer 一样加载 AutoModel。唯一不同的地方是为你的任务选择正确的AutoModel。对于文本(或序列)分类,你应该加载AutoModelForSequenceClassification:
from transformers import AutoModelForSequenceClassification
model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
现在可以把预处理好的输入批次直接送进模型。你只需要通过 ** 来解包字典:
pt_outputs = pt_model(**pt_batch)
模型在 logits 属性输出最终的激活结果. 在 logits 上应用 softmax 函数来查询概率:
from torch import nn
pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
print(pt_predictions)
tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=<SoftmaxBackward0>)
| 所有 🤗 Transformers 模型(PyTorch 或 TensorFlow)在最终的激活函数(比如 softmax)之前 输出张量, 因为最终的激活函数常常与 loss 融合。模型的输出是特殊的数据类,所以它们的属性可以在 IDE 中被自动补全。模型的输出就像一个元组或字典(你可以通过整数、切片或字符串来索引它),在这种情况下,为 None 的属性会被忽略。 |
|---|
1.4 保存模型
当你的模型微调完成,你就可以使用 PreTrainedModel.save_pretrained() 把它和它的分词器保存下来:
pt_save_directory = "./pt_save_pretrained"
tokenizer.save_pretrained(pt_save_directory)
pt_model.save_pretrained(pt_save_directory)
当你准备再次使用这个模型时,就可以使用 PreTrainedModel.from_pretrained() 加载它了:
pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
Transformers 有一个特别酷的功能,它能够保存一个模型,并且将它加载为 PyTorch 或 TensorFlow 模型。from_pt 或 from_tf 参数可以将模型从一个框架转换为另一个框架:
from transformers import AutoModel
tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
pt_model = AutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
###from_pt=True此参数将模型加载为pyorch模型
1.5 自定义模型构建(TODO:待详细研究)
你可以修改模型的配置类来改变模型的构建方式。配置指明了模型的属性,比如隐藏层或者注意力头的数量。当你从自定义的配置类初始化模型时,你就开始自定义模型构建了。模型属性是随机初始化的,你需要先训练模型,然后才能得到有意义的结果。
通过导入 AutoConfig 来开始,之后加载你想修改的预训练模型。在 AutoConfig.from_pretrained() 中,你能够指定想要修改的属性,比如注意力头的数量:
from transformers import AutoConfig
my_config = AutoConfig.from_pretrained("distilbert/distilbert-base-uncased", n_heads=12)
使用 AutoModel.from_config() 根据你的自定义配置创建一个模型:
from transformers import AutoModel
my_model = AutoModel.from_config(my_config)
查阅 创建一个自定义结构 指南获取更多关于构建自定义配置的信息。
1.6 Trainer - PyTorch 优化训练循环
所有的模型都是标准的 torch.nn.Module,所以你可以在任何典型的训练模型中使用它们。当你编写自己的训练循环时,🤗 Transformers 为 PyTorch 提供了一个 Trainer 类,它包含了基础的训练循环并且为诸如分布式训练,混合精度等特性增加了额外的功能。
取决于你的任务, 你通常可以传递以下的参数给 Trainer:
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
TrainingArguments含有你可以修改的模型超参数,比如学习率,批次大小和训练时的迭代次数。如果你没有指定训练参数,那么它会使用默认值:
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="path/to/save/folder/",
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=2,
)
- 一个预处理类,比如分词器,特征提取器或者处理器:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
- 加载一个数据集:
from datasets import load_dataset
dataset = load_dataset("rotten_tomatoes") # doctest: +IGNORE_RESULT
- 创建一个给数据集分词的函数,并且使用 map 应用到整个数据集:
def tokenize_dataset(dataset):
return tokenizer(dataset["text"])
dataset = dataset.map(tokenize_dataset, batched=True)
- 用来从数据集中创建批次的 DataCollatorWithPadding:
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
现在把所有的类传给 Trainer:
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
processing_class=tokenizer,
data_collator=data_collator,
) # doctest: +SKIP
一切准备就绪后,调用 train() 进行训练:
trainer.train()
| 对于像翻译或摘要这些使用序列到序列模型的任务,用 Seq2SeqTrainer 和 Seq2SeqTrainingArguments 来替代。 |
|---|
你可以通过子类化Trainer中的方法来自定义训练循环。这样你就可以自定义像损失函数,优化器和调度器这样的特性。查阅 Trainer 参考手册了解哪些方法能够被子类化。
另一个自定义训练循环的方式是通过回调。你可以使用回调来与其他库集成,查看训练循环来报告进度或提前结束训练。回调不会修改训练循环。如果想自定义损失函数等,就需要子类化 Trainer 了。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)