
51c大模型~合集143
最近,我们撰写并发布了第一篇系统性的 SAE 综述文章,对该领域的技术、演化和未来挑战做了全面梳理,供关注大模型透明性、可控性和解释性的研究者参考。本周三,该模型官宣上线。在官方发布的视频里,Minimax 给大家展示了新模型的生成的各项「杂技」,并表示,「艺术家们发现类似体操这种高度复杂的场景,Hailuo 02 是目前全球唯一一个可以做到的模型。在 ChatGPT 等大语言模型(LLMs)席卷
我自己的原文哦~ https://blog.51cto.com/whaosoft/1400163
#海螺新模型海外爆火
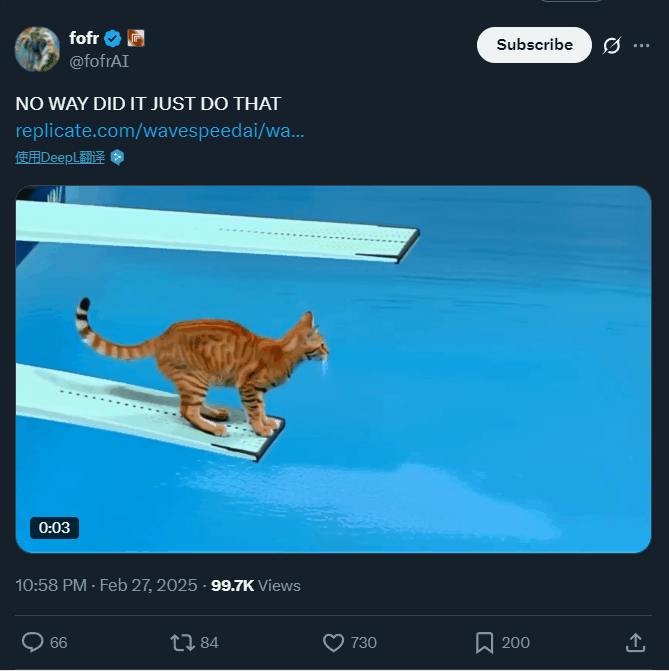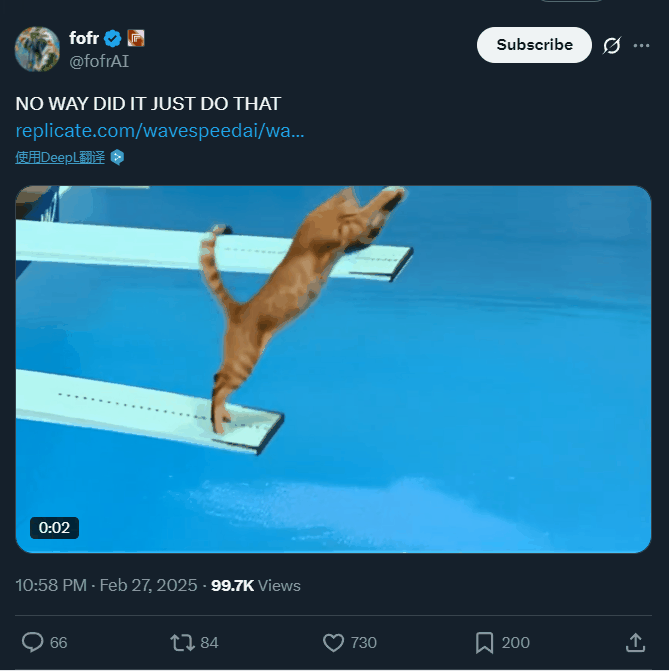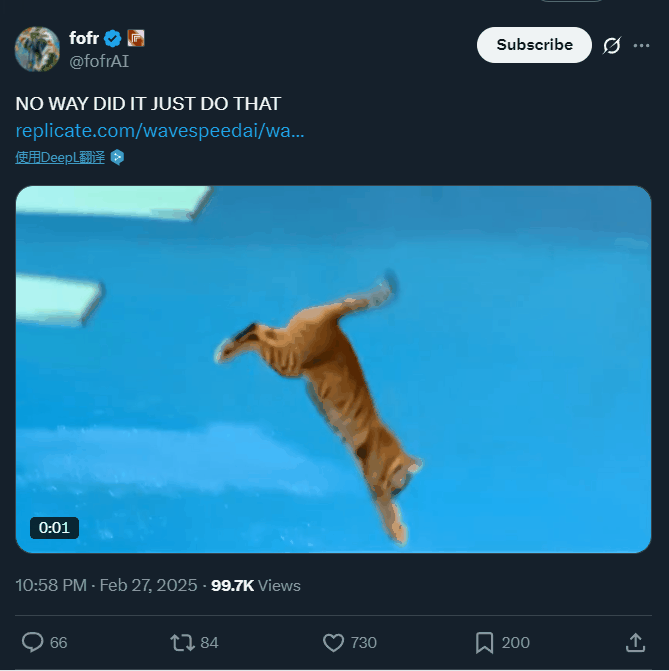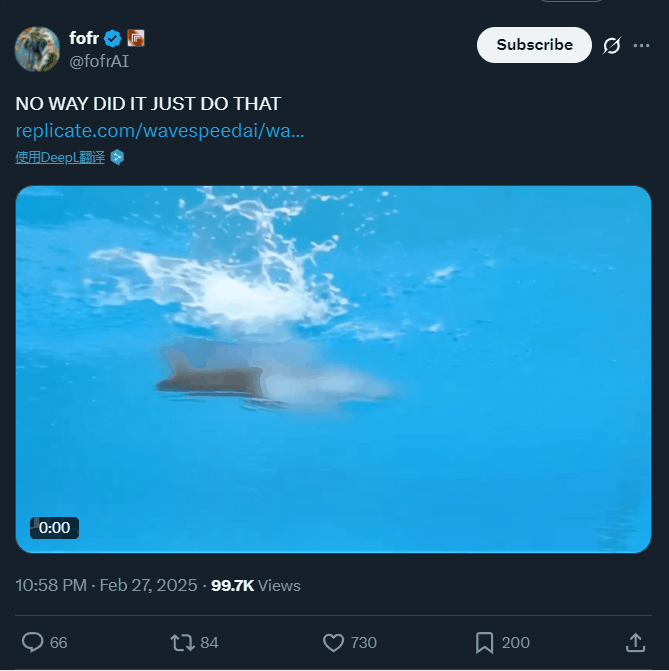
一夜之间,猫、羊驼、长颈鹿都学会跳水了
一个猫咪跳水的视频,5 小时就引得上百万人围观,这是动物界的奥林匹克?
,时长00:34
除了猫咪,参赛的还有羊驼、熊猫甚至长颈鹿……



当然,大家都知道这是 AI 做的,但相比之前,里面的 AI 痕迹已经没有那么明显了。要知道,以前让 AI 生成复杂运动,它们给出的结果大多是这样的:
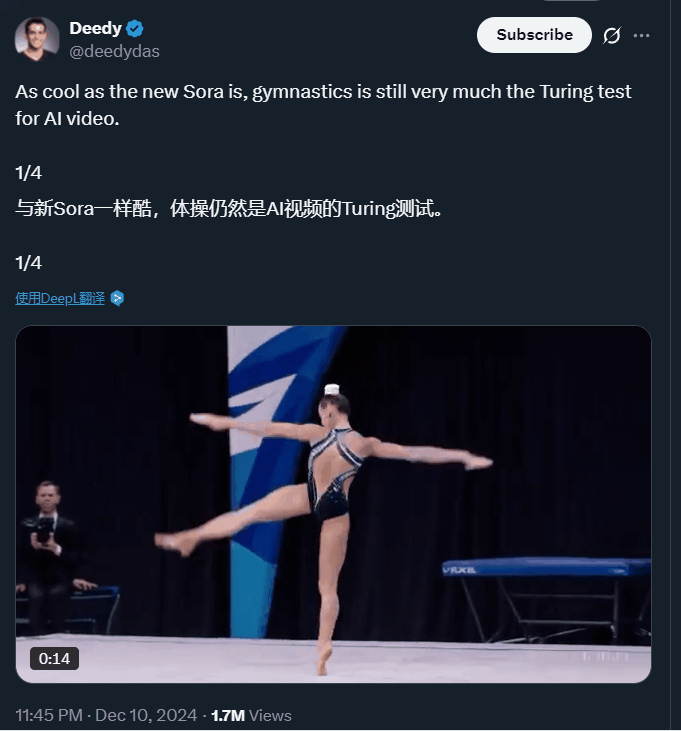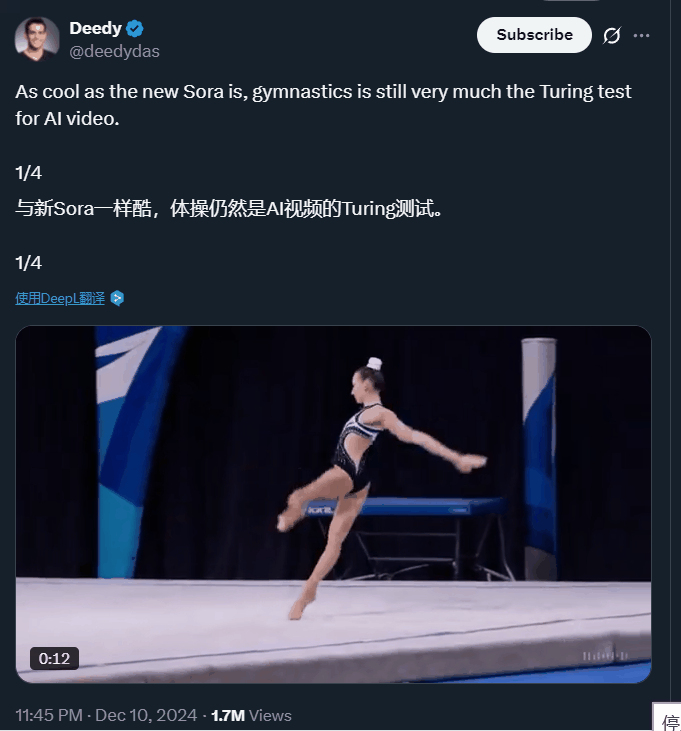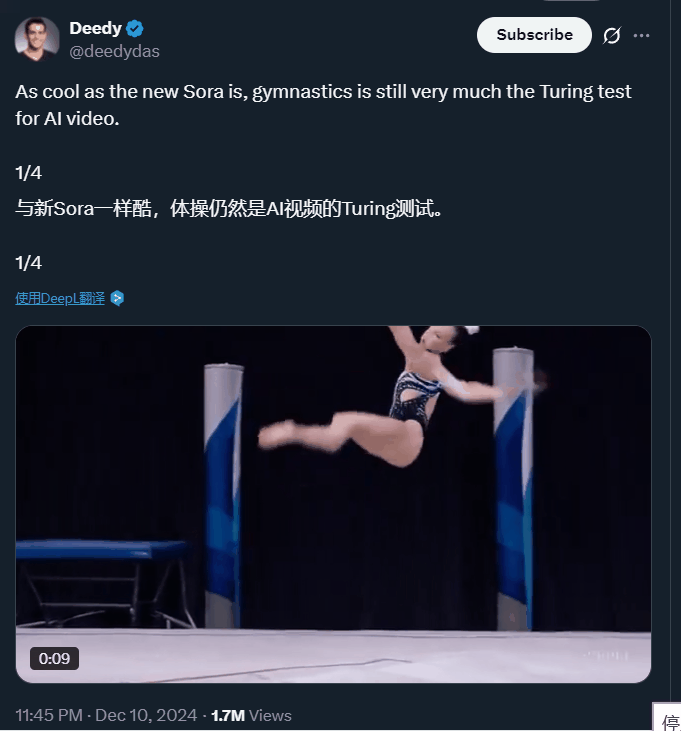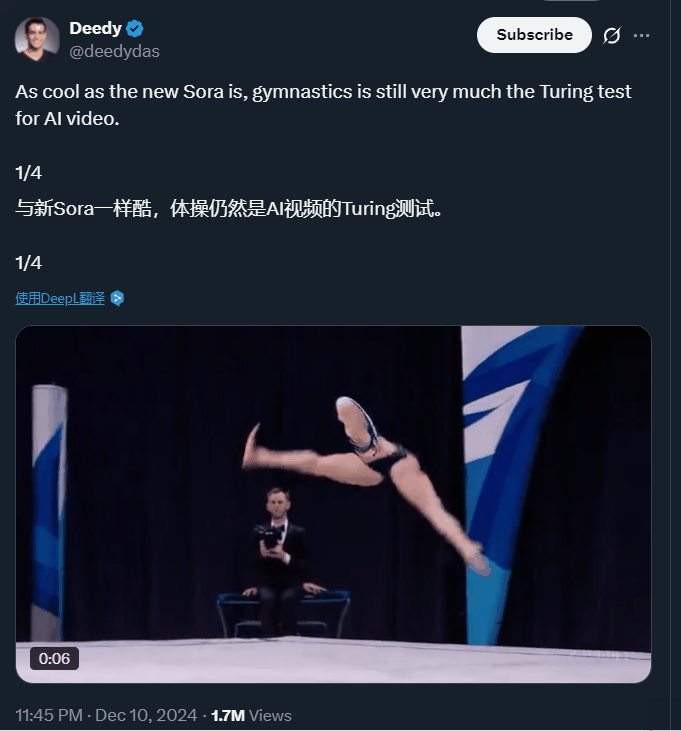
这也是为什么,体操等复杂运动一直被视为视频 AI 模型的「图灵测试」。
这波「动物界奥林匹克」的热度是国内 AI 公司 Minimax 的新模型 ——「Hailuo 02」所带来的。本周三,该模型官宣上线。在官方发布的视频里,Minimax 给大家展示了新模型的生成的各项「杂技」,并表示,「艺术家们发现类似体操这种高度复杂的场景,Hailuo 02 是目前全球唯一一个可以做到的模型。」
,时长00:54
当然,这个「全球唯一」还有待验证,但在大家发现它惊人的物理动作生成能力后,社交媒体上便充满了海螺 AI 生成的高难度动作视频。

这些视频的提示词并不复杂,我们找到了其中一个版本进行测试,效果还不错(不过要想得到完美结果,可能需要多次测试):

提示词:televised footage of a cat is doing an acrobatic dive into a swimming pool at the olympics, from a 10m high diving board, flips and spins
如果你想生成其他动物的视频,只需要替换提示词中的「cat」。
不过,有人提到,就跳水这个动作来说,阿里的通义万相 wan-2.1-t2v 也能做得很好,这是他在该模型 2 月份刚开源时测到的结果:
除了跳水,网友们还拿 Hailuo 02 测试了其他复杂运动,比如单双杠、艺术体操、跳高:

这个模型是怎么把复杂运动做这么好的?在官宣模型的文章中,Minimax 表示新模型使用了一种名叫「Noise-aware Compute Redistribution(NCR)」的架构,并公布了架构图:

看到这里,很多人可能会问,这些视频有什么用呢?这就不得不提最近在短视频平台上走红的各路 AI 视频 up 了。有人用一只橘猫,就能编出各种小短剧,比如把各种动物拐回家吃掉,偶尔一集不吃都能让观众觉得非常新鲜。这样的视频,甚至有人每天追更。

说到底,这些 AI 视频工具最广泛的用途就在于帮普通人实现创意。AI 视频工具功能越完善,能借助它们进行创作的人就越多,大家能看到的内容就越丰富。当然,相应地,观众对于「创意」的要求也就越高。
除了工具,在现阶段,提示词对于 AI 视频创作也很关键。如果大家有好玩的提示词,欢迎在评论区分享。
#A Survey on Sparse Autoencoders
大模型到底是怎么「思考」的?第一篇系统性综述SAE的文章来了
作者介绍:本篇文章的作者团队来自美国四所知名高校:西北大学、乔治亚大学、新泽西理工学院和乔治梅森大学。第一作者束东与共同第一作者吴烜圣、赵海燕分别是上述高校的博士生,长期致力于大语言模型的可解释性研究,致力于揭示其内部机制与 “思维” 过程。通讯作者为新泽西理工学院的杜梦楠教授。
在 ChatGPT 等大语言模型(LLMs)席卷全球的今天,越来越多的研究者意识到:我们需要的不只是 “会说话” 的 LLM,更是 “能解释” 的 LLM。我们想知道,这些庞大的模型在接收输入之后,到底是怎么 “思考” 的?
为此,一种叫做 Sparse Autoencoder(简称 SAE) 的新兴技术正迅速崛起,成为当前最热门的 mechanistic interpretability(机制可解释性) 路线之一。最近,我们撰写并发布了第一篇系统性的 SAE 综述文章,对该领域的技术、演化和未来挑战做了全面梳理,供关注大模型透明性、可控性和解释性的研究者参考。
论文题目:A Survey on Sparse Autoencoders: Interpreting the Internal Mechanisms of Large Language Models
论文地址:https://arxiv.org/pdf/2503.05613

(图 1):该图展示了 SAE 的基本框架。
什么是 Sparse Autoencoder?
简单来说,LLM 内部的许多神经元可能是“多义的”,意思是它们同时处理好几个不相关的信息。在处理输入时,LLM 会在内部生成一段高维向量表示,这种表示往往难以直接理解。然后,如果我们将它输入一个训练好的 Sparse Autoencoder,它会解构出若干稀疏激活的“特征单元”(feature),而每一个feature,往往都能被解释为一段可读的自然语言概念。
举个例子:假设某个特征(feature 1)代表 “由钢铁建造的建筑”,另一个特征(feature 2)代表 “关于历史的问题”。当 LLM 接收到输入 “这座跨海大桥真壮观” 时,SAE 会激活 feature 1,而不会激活 feature 2。这说明模型 “意识到” 桥是一种钢结构建筑,而并未将其理解为历史类话题。
而所有被激活的特征就像拼图碎片,可以拼接还原出原始的隐藏表示(representation),让我们得以窥见模型内部的 “思维轨迹”。这也正是我们理解大模型内部机制的重要一步。

(图 2):该图展示了 SAE 的发展历史。
为什么大家都在研究 SAE?
过去主流的可解释方法多依赖于可视化、梯度分析、注意力权重等 “间接信号”,这些方法虽然直观,但往往缺乏结构性和可控性。而 SAE 的独特优势在于:它提供了一种结构化、可操作、且具语义解释力的全新视角。它能够将模型内部的黑盒表示分解为一组稀疏、具备明确语义的激活特征(features)。
更重要的是,SAE 不只是可解释性工具,更可以用于控制模型怎么想、发现模型的问题、提升模型的安全性等一系列实际应用。当前,SAE 已被广泛应用于多个关键任务:
- 概念探测(Concept Discovery):自动从模型中挖掘具有语义意义的特征,如时间感知、情绪倾向、语法结构等;
- 模型操控(Steering):通过激活或抑制特定特征,定向引导模型输出,实现更精细的行为控制;
- 异常检测与安全分析:识别模型中潜藏的高风险特征单元,帮助发现潜在的偏见、幻觉或安全隐患。
这种 “解释 + 操控” 的结合,也正是 SAE 能在当前 LLM 可解释性研究中脱颖而出的关键所在。目前包括 OpenAI、Anthropic、Google DeepMind 等机构都在推进 SAE 相关研究与开源项目。

(图 3):该图演示了如何通过 SAE 操控模型输出,实现对大语言模型行为的定向引导。
本文有哪些内容?
作为该领域的首篇系统综述,我们的工作涵盖以下几个核心部分:
1. Technical Framework of SAEs(SAE 的技术框架)
本部分系统介绍了 SAE 的基本结构及其训练流程,它是一种特殊的神经网络。具体包括:
- 编码器:把 LLM 的高维向量表示 “分解” 成一个更高维并且稀疏的特征向量。
- 解码器:根据这个稀疏特征向量,尝试 “重建” 回原始的 LLM 信息。
- 稀疏性损失函数:确保重建得足够准确,并且特征足够稀疏。
同时我们总结了现有的常见架构变体与改进策略。例如解决收缩偏差(shrinkage bias)的 Gated SAE,通过直接选择 Top-K 个激活来强制稀疏性的 TopK SAE,等等。
2. Explainability Analysis of SAEs(SAE 可解释性分析)
总结当前主流的解释方法,旨在将 SAE 学习到的稀疏特征用自然语言进行描述,从而把模型的 “抽象思维” 转化为人类可理解的见解 。这些方法主要分为两大类:
- 输入驱动:寻找那些能最大程度激活某个特征的文本片段。通过总结这些文本,我们就能大致推断出这个特征代表什么意思(如 MaxAct、PruningMaxAct)。
- 输出驱动:将特征与 LLM 生成的词语联系起来。例如,一个特征激活时,LLM 最可能输出哪些词,这些词就能帮助我们理解这个特征的含义(如 VocabProj、Mutual Info)。
3. Evaluation Metrics and Methods(评估指标与方法)
评估 SAE 就像评估一个工具:既要看它内部构造是否合理(结构评估),也要看它实际用起来有没有效果(功能评估)。
- 构性评估:检查 SAE 是否按设计工作,比如重建的准确度如何,稀疏性是否达到要求(如重构精度与稀疏度)。
- 功能评估:评估 SAE 能否帮助我们更好地理解 LLM,以及它学习到的特征是否稳定和通用(如可解释性、健壮性与泛化能力)。
4. Applications in Large Language Models(在大语言模型中的应用)
SAE 不仅能帮助我们理解 LLM,还能实际操作它们。我们展示了 SAE 在模型操控、行为分析、拒答检测、幻觉控制、情绪操控等方面的实际应用案例与前沿成果。
5. 与 Probing 方法的对比分析
除了 SAE,还有一种叫做 “Probing(探针)” 的方法也被用于理解 LLM。本文比较了 SAE 与传统的 Probing 技术在模型操纵和特征提取等方面的优势与不足。尽管 Probing 方法在某些方面表现出色,但 SAE 作为一种新兴的机制可解释性方法,具有其独特的潜力。然而,研究也指出,在某些复杂场景(如数据稀缺、类别不平衡等)下,SAE 在提供一致优势方面仍有很长的路要走。
6. 当前研究挑战与未来方向
尽管 SAE 前景广阔,但仍面临一些挑战,如:语义解释仍不稳定;特征字典可能不完整;重构误差不可忽视;训练计算成本较高。同时也展望了未来可能的突破点,包括跨模态扩展、自动解释生成、架构轻量化等。
结语:从 “看得懂” 到 “改得动”
在未来,解释型 AI 系统不能只满足于可视化 attention 或 saliency map,而是要具备结构化理解和可操作性。SAE 提供了一个极具潜力的路径 —— 不仅让我们看到模型 “在想什么”,还让我们有能力去 “改它在想什么”。
我们希望这篇综述能为广大研究者提供一个系统、全面、易于参考的知识框架。如果您对大模型可解释性、AI 透明性或模型操控感兴趣,这将是一篇值得收藏的文章。
#大模型强化学习,相比PPO,DPO 还是个弟弟?
论文地址:https://arxiv.org/pdf/2404.10719v2

这是一篇四月份的新论文,一作单位是清华
这篇主要有三个部分,1. 从理论和实验上看,DPO 可能有本质缺陷 2. 研究了 PPO 提升的几个重要因素 3. 实验证实 PPO 可以在硬核任务上(编程比赛)碾压 DPO 达到新的 SoTA
论文先指出了一个令业界困惑的现状,即大部分的开源的榜单上,DPO 占据了领先的位置,但是众所周知,最好的闭源模型 GPT4 和 Claude,用的都是 PPO 方案。所以这里就自然引出两个问题,即 1. DPO 相对 PPO 真的有优势吗?2. 如何让 PPO 也很能刷榜呢?
DPO 的缺陷
在调教 PPO 的时候,一种常见的现象是语言模型发现了奖励模型的缺陷,而构造出不符合人类偏好,但是却能拿到高奖励的解,即 reward hacking 现象。作者首先指出,虽然 DPO 没有显式的奖励模型,它也会遇到类似的问题。作者的理论指出,PPO 找到的解同样最小化 DPO 目标函数,因此这些 reward hacking 的解也存在于 DPO 的求解空间里。而且,DPO 可能会有过度偏离参考策略的风险。
理论 1:在给定真值奖励 r 和偏好数据集 D 时,PPO 导出的策略是 DPO 导出策略的真子集
直觉理解此时的策略完美的学会了 r,那么从 DPO 的角度看也是最优的
然后作者给了一个在 DPO 的解空间但不在 PPO 解空间的例子,是说 DPO 没有直接拉近当前策略和参考策略,产生了一个符合偏好但是偏离参考策略的解


作者做了一个验证性实验,发现在偏好数据集没有覆盖的数据点上,DPO 可能分配了比参考模型更高的概率,奖励模型也会在这些数据点赋予偏高的奖励,而 PPO 在 KL 约束下,却能优化出一个优秀的解
所以在真实场景下,DPO 会不断冒出在数据分布外的回复,导致无法预期的行为
PS:DPO 也可以做更显式的 KL 约束,效果会怎么样呢?
SafeRLHF 实验

在这个场景下,可以通过减轻分布漂移的方式来提高 DPO 的性能,做法是先通过 SafeSFT 来给 DPO 一个更贴近偏好数据的起点,也可以通过迭代 DPO,即训练 -> 生成新样本 -> 奖励模型标注 -> 训练的方式来提高性能;还可以通过降低偏好数据集中的噪声来提高 DPO 性能,但依然无法胜过 PPO
提高 PPO 效果的关键因素
作者使用的奖励方式是对每个回复奖励一次,而不是稠密奖励

这里涨点的三个技巧是优势函数规范化,大 Batch 训练,以及对参考模型做滑动更新;当 batchsize 太小的时候,PPO 的性能甚至差于 SFT
Benchmark 结果
这一部分大部分就是在说 PPO > Iter DPO > DPO
我最关心的实验结果是编程:


对于解编程题来说,不需要人工标注或者训练奖励模型,因为可以直接测试测例来得到结果,正确的回复给高奖励,错误的回复给低奖励,形成成对数据
而最终结果是 DPO 训炸了,产生的都是无意义的结果,Iter DPO 稍微好点,但都不如 SFT
而 PPO 刷新了 SoTA
#深入浅出完整解析LoRA(Low-Rank Adaptation)模型核心基础知识
大模型高效微调已经成为业界关注的焦点,无论是通用大模型,还是智驾大模型,如何通过轻量微调变成各个不同领域的专业模型,成为讨论的热点。所以今天就来大家一起聊聊LORA。
背景: 业内的大公司或者研究机构,都是有足够资源的来开发大模型,但是对于一般的小公司或者个人来说,要想开发自己的大模型几乎不可能,要知道像 ChatGPT 这样的大模型,一次训练的成本就在上千万美元,而即使是DeepSeekv3,单次训练成本也在500万美元以上,所以充分利用开源大模型,在领域任务上高效微调便成为了当下学术界和工业界迫切需要解决的问题,至此LoRA问世:

LoRA 的思想很简单:
- 在原始 PLM (Pre-trained Language Model) 旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的intrinsic rank。
- 训练的时候固定 PLM 的参数,只训练降维矩阵 A 与升维矩阵 B 。而模型的输入输出维度不变,输出时将 BA 与 PLM 的参数叠加。
- 用随机高斯分布初始化 A ,用 0 矩阵初始化 B ,保证训练的开始此旁路矩阵依然是 0 矩阵。
而这个降维的操作就需要用到低秩分解了,接下来我们回顾下低秩分解:
那么LoRA训练的思路和优势是什么呢?
下面介绍LoRA的原理:
LORA 的这种思想有点类似于残差连接,同时使用这个旁路的更新来模拟 Full Fine-Tuning的过程。并且,Full Fine-Tuning可以被看做是 LoRA 的特例。
值得注意的是在推理过程中,LoRA 也几乎未引入额外的 Inference Latency,只需要计算W=W0+△W即可。
#斯坦福2025 CS336课程全公开
新鲜出炉!从零开始搓大模型
斯坦福大学 2025 年春季的 CS336 课程「从头开始创造语言模型(Language Models from Scratch)」相关课程和材料现已在网上全面发布!

课程视频:https://www.youtube.com/watch?v=SQ3fZ1sAqXI&list=PLoROMvodv4rOY23Y0BoGoBGgQ1zmU_MT_
课程主页:https://stanford-cs336.github.io/spring2025/
这是该课程的教职工阵容:

其中,讲师 Tatsunori Hashimoto 现为斯坦福大学计算机科学系助理教授。此前,他是斯坦福大学 John C. Duchi 和 Percy Liang 的博士后,研究机器学习模型平均性能和最差性能之间的权衡。在博士后研究之前,他在麻省理工学院攻读研究生,导师是 Tommi Jaakkola 和 David Gifford。他本科在哈佛大学学习统计学和数学,导师是 Edoardo Airoldi。他的研究成果已总计获得了超 3 万引用。

另一位讲师 Percy Liang 是斯坦福大学计算机科学系副教授,同时也是基础模型研究中心(CRFM)主任,同时也有参与以人类为中心的人工智能(HAI)、人工智能实验室、自然语言处理研究组和机器学习研究组等的研究工作。他本科毕业于 MIT,之后在该校获得工程学硕士学位,导师是 Michael Collins;之后,他在伯克利获得博士学位,导师是 Michael Jordan 和 Dan Klein;后来他进入谷歌从事博士后研究。Percy Liang 是一位引用量超过 10 万的研究大牛,我们此前也曾多次报道他的研究成果。

CS336 课程简介
CS336 课程的目标是「引导学生完成开发自己的语言模型的整个过程,从而帮助他们全面理解语言模型。」该课程借鉴了操作系统课程中从零开始创建完整操作系统的教学方法,引导学生完成语言模型创建的各个环节,包括预训练的数据收集和清理、Transformer 模型的构建、模型训练以及部署前的评估。

该课程包含 5 个单元,分别是基础、系统、扩展、数据、对齐和推理强化学习。
该课程也非常注重实践操作,因此也需要相当多的学习和开发时间。Percy Liang 也在 𝕏 上简单分享了学生需要实践的内容,包括:

- 作业 1(使基本流程正常运行):实现 BPE 分词器、Transformer 架构、Adam 优化器,并在 TinyStories 和 OpenWebText 上训练模型。只允许使用 PyTorch 原语(不能直接调用 torch. nn. Transformer 或 torch. nn. Linear)。
- 作业 2(让 GPU 运行起来):在 Triton 中实现 Flash Attention 2、分布式数据并行 + 优化器分片。
- 作业 3(Scaling Law):使用 IsoFLOP 拟合 Scaling Law。为了模拟训练运行的高风险,学生会获得一个训练 API [超参数→损失] 和一个固定的计算预算,并且必须选择提交哪些运行来收集数据点。在后台,训练 API 是通过在一系列预先计算的运行之间进行插值来支持的。
- 作业 4(数据):将 Common Crawl HTML 转换为文本,过滤(质量、有害内容、PII),删除重复数据。这是一项苦差事,却没有得到足够的重视。
- 作业 5(对齐):实现监督微调、专家迭代、GRPO 和变体,在 Qwen 2.5 Math 1.5B 上运行 RL 以提升在 MATH 上的指标。我们也曾考虑过让学生自己实现推理(inference),但决定(可能是明智的)让人们使用 vllm。
更具体来说,CS336 课程的 5 个单元包含 19 门课。这里简单总结了该课程的目录,你可以在课程主页下载相应的材料:
- 课程概述和 token 化
- PyTorch 和资源(包括内存和计算资源)
- 架构与超参数
- 混合专家(MoE)
- GPU
- Kernel,Triton
- 并行化
- 并行化
- Scaling Law
- 推理
- Scaling Law
- 评估
- 数据
- 数据
- 对齐 ——SFT/RLHF
- 对齐 —— 强化学习
- 对齐 —— 强化学习
- 客座讲座:阿里巴巴达摩院研究员、Qwen 团队技术负责人 Junyang Lin(林俊旸)
- 客座讲座:Facebook AI 研究科学家、Llama 3 预训练负责人 Mike Lewis
另外,在考虑学习这门课程之前,你应该先具备以下能力:
- 熟练掌握 Python:大部分课程作业将使用 Python 完成。与大多数其他 AI 课程不同,本课程只会给学生提供极少的脚手架。你编写的代码量将至少比其他课程多一个数量级。因此,熟练掌握 Python 和软件工程至关重要。
- 有深度学习和系统优化经验:本课程的很大一部分内容是关于如何使神经语言模型在多台机器的 GPU 上快速高效地运行。我们希望学生能够熟练掌握 PyTorch,并了解内存层次结构等基本系统概念。
- 大学微积分、线性代数(例如 MATH 51、CME 100):你应该能够轻松理解矩阵 / 向量符号和运算。
- 基础概率与统计(例如 CS 109 或同等课程):你应该了解概率、高斯分布、均值、标准差等基础知识。
- 机器学习(例如 CS221、CS229、CS230、CS124、CS224N):你应该熟悉机器学习和深度学习的基础知识。
顺带一提,CS336 课程还为完成课程的学生赠送了纪念 T 恤,有如下 4 种图案。你觉得如何呢?

#AlphaOne
AI真的需要「像人类」那样思考吗?AlphaOne揭示属于大模型的「思考之道」
本文共同第一作者为张均瑜与董润沛,分别为伊利诺伊大学厄巴纳-香槟分校计算机科学研究生与博士生;该研究工作在伊利诺伊大学厄巴纳-香槟分校张欢教授与 Saurabh Gupta 教授,加州大学伯克利分校 Jitendra Malik 教授的指导下完成。
「The most effortful forms of slow thinking are those that require you to think fast.」 ——Daniel Kahneman,Thinking,Fast and Slow(2011)
在思维节奏这件事上,人类早已形成一种独特而复杂的模式。
我们习惯让 AI 模仿人类思维方式:先依赖直觉快速反应(System 1),再慢慢进入逻辑推理(System 2);答题时先给出初步判断,再自我反思逐步修正……模仿人类的推理节奏,已经成为语言模型推理策略的默认路径。
最近,一项来自 UIUC 与 UC Berkeley 的新研究提出:也许模型不该再走这条「人类范式」的老路。
他们提出了一种新的测试时推理调控框架——AlphaOne,主张让模型反其道而行:先慢速思考,再快速推理。
- 论文标题: AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time
- 项目主页:https://alphaone-project.github.io/
- 论文地址:https://arxiv.org/pdf/2505.24863
- 代码地址:https://github.com/ASTRAL-Group/AlphaOne
令人意外的是,这一策略不依赖任何额外训练,仅需在测试阶段引入一个全局推理调控超参数 α,即可显著提升模型的推理准确率,同时让生成过程更加高效紧凑。或许,是时候重新思考:AI 真的需要「像人类」那样思考吗?
看似聪明的推理,其实是不懂停下来的错觉
近年的大型推理模型(LRMs),如 OpenAI o1 和 DeepSeek-R1,在复杂推理任务上取得显著进展,逐渐具备类似人类的 System-2 能力,能够在测试阶段主动慢思考,从而处理需要高阶认知的难题。
这些模型通过强化学习训练出的「慢思考」策略,让它们在面对复杂问题时能够自动放缓推理节奏,从而取得更好的表现。但这种自动「慢下来」的能力真的可靠吗?
与人类不同的是,大模型在推理过程中很难像我们那样灵活切换快慢节奏。心理学中描述的 System-1 与 System-2 转换,是一种受控、动态的思维过程——我们先快速判断,再在困难时激活深度思考,从而在效率与准确之间找到平衡。
相比之下,现有模型往往要么陷入过度思考(overthinking),生成冗长无用的推理链;要么思考不足(underthinking),在问题真正展开前就草率收场。
这背后的根源在于:模型缺乏对推理节奏的主动调控能力,无法准确找到「该慢下来」的最佳时机。
无需训练的全局推理调控,AlphaOne 只做了一件事
AlphaOne 的核心,是引入统一的调控点 α-moment:α-moment 之前通过 Bernoulli 过程插入「慢思考」标记,之后用终止标记切换为快思考,实现无需训练的连续推理调控。

图 1: 不同推理调控方法在推理过程中的表现对比。α1(红色)采用由 α 控制的「先慢后快」推理策略,相比之下,α1 的推理效率优于单调延长思考型方法 s1(黄色),并在整体表现上普遍优于单调压缩推理型方法(紫色)。
什么是 α-moment?
目前多数现有方法要么采用固定的慢思考机制(如在末尾强制延长思考),或者采用单调压缩推理生成策略。然而,这类设计通常缺乏对推理阶段整体结构的统一建模。我们是否可以在无需训练的前提下,统一调控整个推理过程的演进方式,并设计出更高效的「慢思考转化策略」?
AlphaOne 对此提出了解答:通过引入 α-moment——一个统一的调控节点,即推理阶段达到平均思考长度 α 倍的位置。在此之前引导深度思考,在此之后转入快速推进。它不依赖固定阈值或启发式规则,而是提供了一个可调、可迁移的推理控制接口。

图 2: AlphaOne(α1)整体流程示意图。在 α-moment 之前,模型按照用户设定的策略,以 Bernoulli 过程插入 wait,引导深度推理;α-moment 之后,wait 会被替换为 </think>,以促进快思考。α 的数值决定这一转换的时机,例如将 α 从 1.4 降至 1.0,会提前结束慢思考,并加快 pwait 的衰减速度。
α-moment 前:慢思考调控机制
在 α-moment 之前,α1 通过一种概率驱动的调控策略,逐步引导模型进入深度推理状态。
具体来说,当模型生成结构性停顿(如 \n\n)时,会以一定概率插入 wait——这是一种慢思考过渡标记(slow-reasoning transition token),用于显式地触发模型的慢思考行为。这种插入并不是固定次数,而是基于一个 Bernoulli 采样过程,其概率 pwait 由用户设定的调度函数 S(t) 控制。
调度函数可以是线性下降(先慢后快)、线性上升(先快后慢)、指数衰减等多种形式。AlphaOne 默认采用线性衰减策略——在推理初期更频繁地引导慢思考,后期逐步减少干预,避免过度拖延。
图 3: 不同调度函数的可视化
α-moment 后:快思考引导机制
但另一个挑战随之而来:如果持续插入 wait,模型可能会陷入「慢思考惯性」,迟迟无法回归高效推理。
为了解决这个问题,AlphaOne 在 α-moment 之后显式终止慢思考: 一旦生成节点超过 α-moment,所有后续的 wait(即慢思考过渡标记)将被统一替换为 </think>——这是一个思考终止标记(end-of-thinking token),用于打断延续中的慢思考链。
值得注意的是,</think> 并不代表模型立即开始作答。由于慢思考惯性,模型往往无法直接切换到答案生成阶段。因此,</think> 实际上起到的是快思考触发信号的作用,用于提醒模型当前应结束反复推理、转向高效推进。这种机制被称为确定性推理终止,它让模型能够自然地从「深度反思」切换到「快速收敛」,避免低效的推理拖延。
从数学到科学问答,AlphaOne 的策略胜在哪里?
研究团队在六大推理任务中进行了系统实验,涵盖数学题解、代码生成、科学问题理解等多种类型。
实验总结
- 准确率全面领先:无论在小模型(1.5B)还是大模型(32B)上,α1 都比原始模型和现有推理调控方法(如 s1 和 CoD)更准确。
- 以 1.5B 模型为例,α1 提升准确率达 +6.15%。
- 推理效率显著优化:尽管采用了慢思考机制,α1 在 1.5B 模型中平均生成 token 数却减少了 14%,展现出高效慢思考的非直觉优势。

表 1:α1 与基线方法在数学、代码与科学推理任务中的系统性能比较
关键问题分析
- 哪种「慢思考调度」最有效?
对比四种调度策略(常数调度、线性递增、线性衰减、指数衰减)后发现,线性衰减在多个任务上均取得最优表现,验证了 α1 所采用的「先慢思、后加速」式推理调控方式在实践中更加有效和稳定。

图 4: 不同调度策略在 AMC23 和 OlympiadBench 上的推理准确率
- α-moment 能否灵活调控「思考预算」?
实验结果表明,调节 α 值可以有效扩展或压缩模型的「思考阶段」长度。随着 α 增大,模型插入的 wait 标记数量相应增加,平均思考 token 数也随之增长,体现出 α-moment 对思考预算具有良好的可伸缩性(scalability)。
尽管如此,推理准确率并非随 α 增大而持续提升,存在一个性能最优的 α 区间,而 α1 在较宽的 α 调控范围内始终优于原模型,体现出良好的鲁棒性和泛化能力。

图 5:α 的缩放特性分析
- α1 推理效率真的更高吗?
使用 REP(Reasoning Efficiency–Performance)指标系统评估后发现,α1 在多个任务中更高效率下的更优推理准确率,优于 s1 和 CoD 等基线方法。


图 6: 基于 REP 指标的推理效率分析
- 慢思考标记的采样频率应如何设定?
通过调整
![]()
,我们发现:过低或过高的采样频率都会降低模型性能,说明慢思考既不能太少,也不能太密。不过,α1 在较宽频率区间内依然表现稳健,说明只需设定一个适中频率,即可带来稳定的推理提升。

图 7: 常数调度下 wait 插入频率的缩放特性
- α-moment 后的快思考引导机制是否必要?
如果在 α-moment 后没有明确「结束慢思考」,模型容易陷入推理惯性,导致性能明显下降。实验证明,仅依赖前段慢思考调控是远远不够的。
α1 通过 α-moment 之后的显式终止操作,成功促使模型切换至快思考,验证了从快到慢的双阶段调控策略对于提升推理效果的必要性。

表 2: 是否启用后 α-moment 调控机制对推理性能的影响
具体案例
为了更直观地理解 α1 的作用,研究者展示了来自不同基准的推理案例,分别对应模型在使用 α1 后的成功与失败。
- 成功案例:化学混合题(OlympiadBench)

- 失败案例:多角恒等式推理(AMC23)

AlphaOne 之后,还有哪些可能?
α1 提供了一种无需训练、即可在测试阶段灵活调控推理过程的全新框架,初步验证了「慢思考→快思考」的策略对大模型推理效果与效率的显著提升。
但真正理解「思考」如何被更好地建模,仅仅迈出了一小步。研究者提出了几个值得关注的方向:
- 更复杂的慢思考调度策略:当前只探索了简单的「先慢后快」调控策略,未来可以设计更精细的调度函数,甚至发展出独立的推理调控模块。
- 摆脱特定标记的依赖:现阶段调控往往依赖 wait 等特殊转移标记,但不同模型对这些标记的响应不同。未来若能完全摆脱这些「外部标签」,将极大增强泛化能力。
- 跨模态推理的扩展:当前工作聚焦于文本推理,而多模态大模型(如图文、视频大模型)正快速崛起。未来可将 α1 框架扩展至多模态场景,探索语言与感知信息的协同推理。
#StreamBP
无损减少80%激活值内存,提升5倍训练序列长度,仅需两行代码
本文的第一作者罗琪竣、第二作者李梦琦为香港中文大学(深圳)计算机科学博士生,本文在上海交通大学赵磊老师、香港中文大学(深圳)李肖老师的指导下完成。
长序列训练对于模型的长序列推理等能力至关重要。随着序列长度增加,训练所需储存的激活值快速增加,占据训练的大部分内存。即便使用梯度检查点(gradient checkpointing)方法,激活值依然占据大量内存,限制训练所能使用的序列长度。
来自港中文(深圳)和上海交通大学的团队提出 StreamBP 算法。通过对链式法则进行线性分解和分步计算,StreamBP 将大语言模型训练所需的激活值内存(logits 和 layer activation)降低至梯度检查点(gradient checkpointing)的 20% 左右。
论文标题:StreamBP: Memory-Efficient Exact Backpropagation for Long Sequence Training of LLMs
论文:https://arxiv.org/abs/2506.03077
代码:https://github.com/Ledzy/StreamBP
在相同内存限制下,StreamBP 最大序列长度为梯度检查点的 2.8-5.5 倍。在相同序列长度下,StreamBP 的速度和梯度检查点接近甚至更快。StreamBP 适用于 SFT、GRPO、PPO 和 DPO 等常见 LLM 目标函数。代码已开源,可集成至现有训练代码。
激活值内存和梯度检查点
在反向传播(Backpropagation, BP)的过程中,计算模型梯度需要用到模型的中间输出(激活值)。举例来说,对于模型中的线性变换
![]()
的梯度为
![]()
,因而计算
![]()
的梯度时需要储存相应的激活值
![]()
。
对于模型中的任意函数变换

的梯度由以下链式法则计算:

其中 L 为目标函数,

为 Jacobian 矩阵。为了计算以上 Jacobian-vector product,需要在模型 forward 时储存函数变换
![]()
的中间值(激活值),其内存消耗与 batch size、序列长度以及中间值维度正相关。
为了减少激活值的内存消耗,梯度检查点(gradient checkpointing)方法在 forward 时只储存每一层网络的输入,而不储存该层的中间值。在 backward 至该层时,将重新 forward 此层输入来计算得到该层激活值。使用梯度检查点时储存的激活值包括:
- 所有层的输入,一般为激活值内存的 5%-15%。
- 单层的完整激活值,占据超过 85% 的激活值内存。
StreamBP 的核心思想
不同于梯度检查点,StreamBP 避免储存单层的完整激活值,而将单层的 BP 过程进行线性分解,序列化计算并累加。注意到对于函数变换
![]()
,链式法则存在以下线性分解:

StreamBP 基于以下观察:对于 LLM 中的大部分函数变换
![]()
,如 Transformer 层、lmhead 层,可通过策略性地将输出分块

,使得计算块 Jacobian-vector product

所需的激活值远小于计算完整的 Jacobian-vector product。基于该观察,StreamBP 依次计算上式中 D 个块的 Jacobian-vector product 并累加,得到准确的梯度。
为了计算块 Jacobian-vector product,需要分析
![]()
输入和输出的相关性,每次 forward 块输入

得到块输出

,建立对应子计算图。以简单的线性变换
![]()
为例,输出和输入在行维度上一一对应。StreamBP 按行分块,每次计算单行的 Jacobian-vector product 并累加。下图对比了标准 BP 和 StreamBP 在上述线性变换下的实现:

D 步累加得到的
![]()
和
![]()
即为
![]()
和
![]()
准确梯度。相比于标准 BP,StreamBP 仅需储存
![]()
和
![]()
,且总计算 FLOPs 相同。下表为 StreamBP 和标准 BP 的内存和时间对比:

LLM 训练中的 StreamBP
StreamBP 应用于 LLM 中的 Transformer 层和 lmhead 层,分别用于降低层激活值和 logits 的内存消耗。
与线性变换不同,由于 Transformer 层存在注意力机制,块输出

并非仅由对应位置的块输入

决定,而与该块及以前所有位置的输入

都有关。StreamBP 利用

只与块
![]()
有关的性质,建立了如下计算图:

StreamBP 所需储存的激活值和注意力掩码(橙色)大幅低于梯度检查点(橙色 + 白色部分)。
对于 lmhead 层,当以 SFT 或 GRPO 为目标函数时,观察到不同位置的 logits 对于目标函数的影响相互独立。因此,StreamBP 从序列维度分块,每次计算单块损失函数的梯度,从而只需储存单块 logits 和 logits 梯度。

图:StreamBP for SFT

图:StreamBP for GRPO
对于 DPO,由于非线性 sigmoid 函数的存在,每个位置的 logits 对于目标函数的影响并不独立。StreamBP 利用 logits 梯度在序列维度的独立性,分块进行梯度计算。

图:StreamBP for DPO
实验结果
我们在单张 A800-80GB GPU 上测试了不同大小的模型,StreamBP 的最大 BP 序列长度为标准 BP 的 23-36 倍,梯度检查点的 2.5-5.5 倍。

图:不同序列长度下的 BP 峰值内存
在现有 Transformers 框架下,StreamBP 的实现可避免计算掩码部分的 pre-attention score(见论文 3.2.2 部分),在长序列训练下相较于梯度检查点实现了加速。

通过使用 StreamBP,不同目标函数下最大的序列长度得到了大幅提升。在同样的序列长度下,StreamBP 允许更大的批处理大小以加速训练。


表:Qwen 3-4B 单个样本 BP 时间,序列长度为 9000。
在 Deepspeed ZeRO 分布式训练模式下,Distributed StreamBP 比梯度检查点的最大可训练序列长度提升了5—5.6倍。

#Astra
我在哪?要去哪?要怎么去?字节跳动提出Astra双模型架构助力机器人自由导航
在当今科技飞速发展的时代,机器人在各个领域的应用越来越广泛,从工业生产到日常生活,都能看到它们的身影。然而,现代机器人导航系统在多样化和复杂的室内环境中面临着诸多挑战,传统方法的局限性愈发明显。
一、传统导航瓶颈凸显,Astra 应势而生
在复杂的真实世界中,移动机器人想要安全可靠地行走,必须解决三大挑战:我要去哪?我在哪?我要怎么去?这正是目标定位、自我定位与路径规划三大导航核心问题。目标定位时,在某些应用中,目标可能通过自然语言或目标图像提示指定,这就需要系统理解提示并在地图中定位目标;自我定位要求机器人在地图中确定自身位置,尤其是在像仓库这样高度重复且缺乏全局地标的复杂场景中,传统导航系统常依赖人工地标,如 QR 码;路径规划又分为全局规划和局部规划,全局规划根据机器人位姿和目标位姿生成粗略路线,局部规划则负责在避开障碍物的同时到达全局路径上的中间路点。
为解决这些任务,传统导航系统通常由多个模块组成,包含多个小模型或基于规则的系统。近年来,基础模型的出现促使人们将小模型集成到更大的模型中以解决更多任务,但所需模型数量及如何有效整合仍有待探索。
为了突破传统导航系统的瓶颈,字节跳动研发了一种创新的双模型架构 Astra。
论文标题:Astra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning
网站:https://astra-mobility.github.io/
通过两大子模型:Astra-Global 与 Astra-Local,在环境理解感知与实时规划决策之间建立通路,为下一代智能体的 “通用导航能力” 打下基础。Astra 遵循 System 1/System 2 理念,Astra-Global 负责低频任务,如目标和自我定位;Astra-Local 管理高频任务,包括局部路径规划和里程计估计。这种架构的出现,为移动机器人导航领域带来了新的希望,有望彻底改变机器人在复杂室内环境中的导航方式。

图1: Astra模型概述
二、Astra 双模型架构揭秘,赋能机器人高效导航
1. Astra-Global:全局定位的智慧大脑
Astra-Global 作为 Astra 架构中的重要组成部分,犹如智慧大脑,承担着关键的低频任务,即自我定位和目标定位。它是一个多模态大语言模型(MLLM),能够巧妙地处理视觉和语言输入,在全局地图中实现精准定位。其核心在于利用混合拓扑语义图,将其作为上下文输入,使得模型能够依据查询图像或文本提示,在地图中准确找到对应的位置。

图2: Astra-Global 架构
在构建这个强大的定位系统时,离线映射是关键的第一步。研究团队提出了一种离线方法来构建混合拓扑语义图 G=(V,E,L)。在这个图中,V 代表节点集合,通过对输入视频进行时间下采样,并利用 SfM 估计近似的 6 自由度(DoF)相机位姿,将关键帧设为节点,这些节点编码了相机位姿和地标引用;E 是基于节点相对位姿关系建立的无向边集合,对于全局路径规划至关重要,它代表了几何连通性;L 则是地标信息集合,通过 Astra-Global 从每个节点的视觉数据中提取语义地标,丰富了地图的语义理解,地标存储了语义属性,并通过共视关系与多个节点相连。例如,在一个办公室场景中,拓扑地图构建确定了各个房间、走廊等位置的节点和连接关系,地标语义丰富则为这些节点添加了如 “会议室”“办公桌区域” 等地标信息。地标共视图表的构建进一步确保了不同节点间关于地标信息的一致性,使得机器人能够更全面地理解场景。
在实际定位过程中,Astra-Global 的自定位与目标定位功能展现出独特的优势。视觉 - 语言定位采用粗到精的两阶段过程。在粗定位阶段,模型分析输入图像和定位提示,检测地标并与预建地标地图建立对应关系,同时通过视觉一致性过滤,依据图像相似性进一步优化匹配结果,确定最终候选节点。如在一个仓库环境中,机器人通过摄像头获取图像,Astra-Global 能够识别出货架、叉车等地标,并与地图中的地标信息匹配,筛选出可能的位置。在精定位阶段,模型利用查询图像和粗定位输出的候选节点,从离线地图中采样参考地图节点,通过比较参考节点的视觉和位置信息,直接输出查询图像的预测位姿,实现高精度定位。基于语言的目标定位同样出色,模型根据自然语言指令,利用地图中地标已有的功能描述,识别相关地标,再通过地标到节点的关联机制,定位相关节点,获取目标位置的图像和 6 自由度位姿。比如,当用户发出 “找到打印机” 的指令时,Astra-Global 能迅速在地图中找到与 “打印机” 相关的地标节点,从而确定打印机的位置。
为了让 Astra-Global 具备强大的定位能力,研究团队采用了精心设计的训练方法。以 Qwen2.5-VL 为骨干,结合监督微调(SFT)和组相对策略优化(GRPO)。在 SFT 阶段,准备包含不同任务的多样化数据集,除了粗定位和精定位数据集外,还构建了如共视检测、共视图像选择、运动趋势估计等辅助任务数据集,以提升模型的空间理解能力。在 GRPO 阶段,针对视觉 - 语言定位任务,利用基于规则的奖励函数进行训练,奖励函数包括格式奖励、地标提取奖励、地图匹配奖励和额外地标奖励等,通过不断优化奖励函数,提升模型在定位任务中的表现。实验结果表明,GRPO 显著提升了 Astra-Global 在零样本场景下的泛化能力,如在未见过的家庭环境中,SFT + GRPO 方法的定位准确率达到 99.9%,超过同等数据量下 SFT-only 方法的 93.7% 。
2. Astra-Local:本地规划的智能助手
Astra-Local 则是 Astra 架构中负责高频任务的智能助手,它是一个多任务网络,能够从传感器数据中高效地生成局部路径并准确估计里程计。其架构包含三个核心组件:4D 时空编码器、规划头和里程计头,每个组件都发挥着不可或缺的作用。

图3: Astra-Local 架构
4D 时空编码器是 Astra-Local 的基础组件,它旨在取代传统移动性堆栈中的感知和预测模块。首先是 3D 空间编码器,它以 N 个环视图像为输入,通过 Vision Transformer(ViT)将图像编码为判别性特征表示,再利用 Lift-Splat-Shoot 将 2D 图像特征转换为 3D voxel 特征。为了训练 3D 空间编码器,采用自监督学习方式,通过 3D 体积可微神经渲染,利用深度和颜色图像进行监督。对于缺乏深度标签的情况,借助大尺度单目深度估计模型对齐稀疏深度传感器数据后生成伪深度标签。接着,4D 时空编码器在 3D 编码器的基础上进行训练,它以过去的 voxel 特征和未来时间戳为输入,通过 ResNet 和 DiT 模块预测未来 voxel 特征。经过预训练的 4D 时空编码器能够生成当前和未来的环境状态表示,为后续的路径规划和里程计估计提供有力支持。
规划头基于预训练的 4D 特征,结合机器人速度和任务信息(如目标位姿),通过基于 Transformer 的流匹配来生成可执行的轨迹。在复杂环境中,轨迹具有多模态特性,流匹配因其高效率成为实时系统中路径规划的理想方法。为了避免与各种障碍物发生碰撞,规划头引入了掩码 ESDF 损失。通过计算 3D 占用地图的欧几里得空间距离场(ESDF)图,并在 ESDF 图上添加 2D 地面真实轨迹掩码,有效地减少了碰撞率。实验结果显示,在包含许多未见拥挤场景的 OOD 数据集上,使用掩码 ESDF 损失的方法在碰撞率和综合得分方面都优于其他方法,充分证明了其在生成高质量轨迹方面的有效性。
里程计头的主要任务是利用当前和过去的 4D 特征以及额外的传感器数据(如 IMU、车轮数据)来预测机器人的相对位姿。它通过训练一个 Transformer 模型来融合不同传感器的信息,每个传感器模态的数据都经过特定的 tokenizer 处理,再结合模态嵌入和时间位置嵌入,输入到 Transformer 编码器中,最后利用 CLS token 预测相对位姿。在实验中,与基于两帧的基线方法相比,Astra-Local 的里程计头在多传感器融合和位姿估计方面表现出色,如在加入 IMU 数据后,旋转估计精度大幅提升,整体轨迹误差降低到约 2%,进一步加入车轮数据后,尺度稳定性和估计精度进一步增强,展示了其在多传感器数据融合方面的优势。
三、实验数据见证实力
为了全面评估 Astra 的性能,研究团队在多种不同的室内环境中展开了广泛且深入的实验,涵盖了仓库、办公楼和家庭等场景。这些实验不仅验证了 Astra 在理论上的创新架构和算法的有效性,更展示了其在实际应用中的潜力和可靠性。
1. 多模态定位能力
Astra-Global 的多模态定位能力通过一系列实验得到了验证。在处理文本和图像定位查询时,Astra-Global 表现出色。对于目标定位任务,它能够准确地根据文本指令在地图中识别出匹配的图像和位姿,例如当接收到 “找到休息的地方” 这样的指令时,Astra-Global 能够迅速定位到地图中沙发等休息区域的位置信息。与传统的视觉位置识别(VPR)方法相比,Astra-Global 具有较大优势。在细节捕捉方面,传统 VPR 方法常依赖全局特征,容易忽略像房间号这样的精细细节,而 Astra-Global 能够精准捕捉这些关键信息,避免在相似场景中出现定位错误。在视点变化的鲁棒性上,Astra-Global 基于语义地标进行定位,即使相机角度发生较大变化,地标之间的相对位置关系保持不变,使其能够更稳定地进行定位,而传统 VPR 方法在面对大的视点变化时往往会出现定位偏差。在位姿精度上,当存在多个相似候选位置时,Astra-Global 能够利用地标空间关系选择最佳匹配位姿,在 1 米距离误差和 5 度角误差范围内的位姿精度显著高于传统 VPR 方法,在仓库环境中的位姿精度比传统方法提升了近 30%+。

图4: 不同场景下Astra Global的定位精度都显著高于传统VPR方法
2. 规划与里程计性能
Astra-Local 中规划头和里程计头的性能同样在实验中得到了充分的评估。在规划头方面,研究团队将其与 ACT 和扩散策略(DP)等方法进行了对比。在碰撞率、速度和得分等指标上,使用基于 Transformer 的流匹配和掩码 ESDF 损失的 Astra-Local 规划头表现良好。在包含许多未见拥挤场景的 OOD 数据集上,Astra-Local 的碰撞率明显低于其他方法,同时能够保持较高的速度和综合得分,充分证明了掩码 ESDF 损失在减少碰撞风险方面的有效性。在里程计头方面,通过在包含同步图像序列、IMU 和车轮数据以及地面真实位姿的多模态数据集上进行实验,结果显示,与基于两帧 BEV-ODOM 的基线方法相比,Astra-Local 的里程计头在多传感器融合和位姿估计方面具有较大优势。加入 IMU 数据后,旋转估计精度大幅提升,整体轨迹误差降低到约 2%,进一步加入车轮数据后,尺度稳定性和估计精度进一步增强,有效提升了机器人在复杂环境中的运动控制和导航能力。

图5: 通过掩码esdf loss可以显著降低规划头的碰撞率

图6: 里程计任务头通过transformer有效的融合多传感器信息
四、未来展望
展望未来,Astra 有着广阔的发展前景和应用潜力。在更广泛的场景部署方面,Astra 有望拓展到更多复杂的室内环境,如大型商场、医院、图书馆等。在大型商场中,Astra 可帮助机器人快速定位商品位置,为顾客提供精准的导购服务;在医院里,能协助医疗机器人高效地运送药品和物资,提高医疗服务效率;在图书馆中,可助力机器人整理书籍、引导读者查找资料。
然而,Astra 目前也存在一些需要改进的地方。对于 Astra-Global 模块,当前的地图表示虽在信息损失和 token 长度上取得了一定平衡,但在某些情况下仍可能缺乏关键的语义细节,影响定位的准确性。未来,研究团队计划深入研究替代地图压缩方法,在优化效率的同时,最大限度地保留重要语义信息,以提升定位精度。此外,现有的定位仅依赖单帧观测,在特征缺失或高度重复的环境中可能会失效。为解决这一问题,后续将引入主动探索机制,让机器人能够主动感知周围环境,并将时间推理融入模型,利用序列观测实现更稳健的定位,使机器人在复杂环境中也能准确找到自身和目标的位置。
在本地导航与控制方面,Astra-Local 模块也有提升空间。在实际机器人部署中,受限于模型的泛化能力以及基于规则的回退系统在边缘情况下容易误触发,导致回退率不可忽视。为了增强对分布外(OOD)场景的鲁棒性,团队将通过改进模型架构和训练方法,使其能够更好地应对各种未知情况。同时,重新设计回退系统,使其更紧密地集成到整个系统中,实现更无缝的切换,提高系统的稳定性和可靠性。此外,还计划将指令跟随能力集成到模型中,使机器人能够理解和执行人类的自然语言指令,进一步拓展其在动态、以人为中心的环境中的可用性,实现更自然、高效的人机交互。
#MegaKernel~Mirage Persistent Kernel
显著提升小LLM的性能,将所有kernel搞到一个巨大kernel中,即MegaKernel
本文介绍了 Mirage Persistent Kernel,它能自动把小语言模型(LLM)推理转化为一个融合的 GPU kernel,消除启动开销,实现计算通信重叠,显著降低推理延迟,特别适合小规模 LLM 优化,但也存在资源利用和多 GPU 适配等局限。
来源自 https://zhihaojia.medium.com/compiling-llms-into-a-megakernel-a-path-to-low-latency-inference-cf7840913c17
一个LLM编译器,它可以自动将LLM推理转换为单个megakernel——一个融合的GPU kernel,能在一次启动中执行所有必要的计算和通信。这种端到端的GPU融合方法将LLM推理延迟降低了1.2-6.7倍。我们的编译器使用简单——只需几十行Python代码就可以将LLM编译成高性能megakernel。
核心理念是什么? 传统的LLM系统通常依赖于一系列GPU kernel启动和外部通信调用,导致硬件利用率不足。我们的编译器可以自动将这些操作(跨越多层、多次迭代和多个GPU)融合为一个megakernel。这种设计消除了启动开销,实现了细粒度的软件流水线,并使计算与跨GPU通信重叠。
团队成员: Xinhao Cheng[1], Bohan Hou[2], Yingyi Huang[3], Jianan Ji[4], Jinchen Jiang[5], Hongyi Jin[6], Ruihang Lai[7], Shengjie Lin[8], Xupeng Miao[9], Gabriele Oliaro[10], Zihao Ye[11], Zhihao Zhang[12], Yilong Zhao[13], Tianqi Chen[14], Zhihao Jia[15]
项目地址: https://github.com/mirage-project/mirage/tree/mpk
降低LLM推理延迟最有效的方法之一是将所有计算和通信融合到单个megakernel_——_也称为persistent kernel中。在这种设计中,系统只需启动一个GPU kernel就能执行整个模型——从逐层计算到跨GPU通信——无需中断。这种方法带来几个关键性能优势:
- 消除kernel启动开销,即使在多GPU设置中,也可以避免重复的kernel调用;
- 实现跨层软件流水线,使kernel能在计算当前层的同时开始加载下一层的数据;
- 重叠计算和通信,因为megakernel可以同时执行计算操作和跨GPU通信以隐藏延迟。
尽管有这些优势,将LLM编译成megakernel仍然具有很大挑战。现有的高级ML框架——如PyTorch[16]、Triton[17]和TVM[18]——都不原生支持端到端的megakernel生成。此外,现代LLM系统是由各种专用kernel库构建的:NCCL[19]或NVSHMEM[20]用于通信,FlashInfer[21]或FlashAttention[22]用于高效注意力计算,以及CUDA或Triton[23]用于自定义计算。这种碎片化使得将整个推理流水线整合到单个统一kernel中变得困难。
我们能通过编译来自动化这个过程吗? 基于这个问题,我们来自CMU、UW、Berkeley、NVIDIA和清华的团队开发了Mirage Persistent Kernel[24] (MPK)——一个编译器和运行时系统,可以自动将多GPU LLM推理转换为高性能megakernel。MPK释放了端到端GPU融合的优势,同时只需要开发者付出最少的手动努力。MPK牛逼在哪?
MPK的一个关键优势是通过消除kernel启动开销并最大程度地重叠计算、数据加载和跨GPU通信,实现了LLM推理的极低延迟。
图1. 比较MPK与现有系统的LLM解码延迟。我们使用了39个token的提示词并生成了512个token,未使用推测解码。

图1展示了MPK与现有LLM推理系统在单GPU和多GPU配置下的性能对比。在单个NVIDIA A100 40GB GPU上,MPK将每个token的解码延迟从14.5毫秒(这是像vLLM和SGLang这样的优化系统所能达到的水平)降低到了12.5毫秒,接近10毫秒的理论下限(基于以1.6 TB/s的内存带宽加载16 GB的权重)。
除了单GPU优化之外,MPK将计算和跨GPU通信融合到单个megakernel中。这种设计使MPK能够最大程度地重叠计算和通信。因此,MPK相比当前系统的性能提升会随着GPU数量的增加而增加,这使其在多GPU部署中特别有效。
接下来是什么?
本博客的其余部分将深入探讨MPK的工作原理:
- 第1部分介绍MPK编译器,它将LLM的计算图转换为优化的任务图;
- 第2部分介绍MPK运行时,它在megakernel中执行这个任务图以实现高吞吐量和低延迟。
第1部分:编译器:将LLM转换为细粒度Task Graph
大型语言模型(LLM)的计算通常表示为一个computation graph,其中每个节点对应一个计算操作(如matrix multiplication、attention)或集体通信原语(如all-reduce),边表示操作之间的数据依赖关系。在现有系统中,每个operator通常通过一个专用的GPU kernel来执行。然而,这种kernel-per-operator execution model往往无法充分利用流水线机会,因为依赖关系是在粗粒度层面(跨整个kernel)而不是实际数据单元层面强制执行的。
LLM的计算通常表示为一个computation graph,其中每个节点是一个计算operator(如matrix multiplication、attention)或集体通信原语(如allreduce),边表示operator之间的数据依赖关系。现有系统通常为每个operator启动一个专用GPU kernel。然而,这种kernel-per-operator方法往往无法充分利用流水线机会,因为依赖关系是在粗粒度层面(跨整个kernel)而不是实际数据单元层面强制执行的。
考虑一个典型例子:matrix multiplication之后的allreduce操作。在现有的kernel-per-operator系统中,allreduce kernel必须等待整个matmul kernel完成。但实际上,allreduce的每个数据块只依赖于matmul输出的一部分。这种逻辑依赖和实际数据依赖之间的不匹配限制了计算和通信重叠的潜力。
图2. MPK编译器将LLM的computation graph(在PyTorch中定义)转换为优化的细粒度task graph,以暴露最大并行性。右侧展示了一个替代方案——但这是次优的task graph,它引入了不必要的数据依赖和全局同步障碍,限制了跨层的流水线机会。

为了解决这个问题,MPK引入了一个编译器,可以自动将LLM的computation graph转换为细粒度task graph。这个task graph在sub-kernel级别明确捕获依赖关系,实现更激进的跨层流水线。
在MPK task graph中:
- 每个task(如图2中的矩形所示)代表分配给单个GPU streaming multiprocessor (SM)的计算或通信单元。
- 每个event(显示为圆圈)代表任务之间的同步点。
- 每个task都有一个指向triggering event的出边,当所有相关task完成时该event被激活。
- 每个task还有一个来自dependent event的入边,表示task可以在event激活后立即开始执行。
Task graph使MPK能够发现在computation graph中可能被忽略的流水线机会。例如,MPK可以构建一个优化的task graph,其中每个allreduce task只依赖于产生其输入的对应matmul task——实现部分执行和重叠。
除了生成优化的task graph外,MPK还使用Mirage kernel superoptimizer[25]为每个task自动生成高性能CUDA实现。这确保每个task都能在GPU SM上高效运行。(关于kernel superoptimizer的更多信息,请参见这篇文章[26]。)
第2部分:运行时:在MegaKernel中执行Task Graph
MPK包含一个on-GPU运行时系统,它在单个GPU megakernel中完全执行task graph,实现了对任务执行和调度的细粒度控制,在推理过程中无需任何kernel启动。
为实现这一点,MPK将GPU上的所有streaming multiprocessors (SMs)静态划分为两种角色:workers和schedulers。worker和scheduler SM的数量在kernel启动时固定,并与物理SM的总数匹配,避免了任何动态上下文切换开销。
Workers
每个worker在一个SM上运行并维护一个专用任务队列。它遵循一个简单但高效的执行循环:
- 从队列中获取下一个任务。
- 执行任务(例如矩阵乘法、attention或跨GPU数据传输)。
- 任务完成时通知触发事件。
- 重复以上步骤。
这种设计确保workers保持充分利用,同时使任务执行能够在各层和操作之间异步进行。
Schedulers
调度决策由MPK的分布式schedulers处理,每个scheduler运行在一个single warp上。由于每个SM可以容纳多个warps,每个SM最多可以同时运行四个schedulers。每个scheduler维护一个已激活事件的队列。它持续执行以下操作:
- 出队已满足依赖关系的已激活事件(即所有前置任务已完成)。
- 启动依赖于已激活事件的任务集。
这种分散式调度机制最小化了协调开销,同时实现了跨SM的可扩展执行。
图3. MPK运行时在megakernel中执行task graph。

事件驱动执行
图3展示了MPK的执行时间线。每个矩形代表在worker上运行的任务;每个圆圈代表一个事件。当任务完成时,它会增加其对应触发事件的计数器。当事件计数器达到预定阈值时,该事件被视为已激活并进入scheduler的事件队列。然后scheduler启动依赖于该事件的所有下游任务。
这种设计实现了细粒度软件流水线和计算与通信的重叠。例如:
- 不同层的Matmul任务可以与attention任务并行执行。
- 一旦获得部分matmul结果,就可以开始Allreduce通信。
由于所有调度和任务转换都发生在单个kernel上下文中,任务之间的开销极低——通常仅为1-2微秒——从而实现了多层、多GPU LLM工作负载的高效执行。
展望未来
我们对MPK的愿景是使megakernel编译既易于使用又具有高性能。目前,您只需几十行Python代码就可以将LLM编译成megakernel——主要是用于指定megakernel的输入和输出。我们对这个方向感到兴奋,还有更多值得探索的地方。以下是我们正在积极开发的几个关键领域:
- 支持现代GPU架构。我们的下一个重要里程碑是扩展MPK以支持下一代架构,如NVIDIA Blackwell。一个主要挑战在于将warp specialization(新型GPU的关键优化)与MPK的megakernel执行模型集成。
- 处理工作负载动态性。MPK目前构建静态task graph,这限制了它处理动态工作负载(如**mixture-of-experts (MoE)**模型)的能力。我们正在开发新的编译策略,使MPK能够支持megakernels内的动态控制流和条件执行。
- 高级调度和任务分配:MPK在task级别实现了新的细粒度调度。虽然我们当前的实现使用简单的轮询调度来在SM之间分配任务,但我们看到了高级调度策略的令人兴奋的机会——例如优先级感知或吞吐量优化策略——用于延迟SLO驱动服务或混合批处理等用例。
我们相信MPK代表了GPU上LLM推理工作负载编译和执行方式的根本性转变,我们渴望与社区合作推进这一愿景。
个人见解
MegaKernel和之前TensorRT、triton、tvm的区别就是对kernel的合并更加激进些(后者也会进行kernel合并,比如conv + bn,但并不会都合并为一个),实际上就是一个大的定制化kernel。
让 LLM 始终运行在同一个 kernel 里,极大减少了 kernel launch 和数据搬运开销,实现 LLM 推理的低延迟与高吞吐。个人觉得比较适合1B、3B、7B这种可以单卡容纳的小模型,这种级别的LLM有overhead可以被巨大kernel优化,但是比较大的模型(32B、70B)相应的overhead不明显,一个kernel和多个kernel对性能的影响不大。
而且这个方式不够灵活,对资源利用会比较大(在编译kernel的时候为了性能会强行设置然后assert一些资源,和之前trt的做法一些,有些牺牲显存换取性能的意思,这个会更明显些),多gpu适配难度比较大。
比较适合小的LLM。
参考资料
[16] PyTorch: https://pytorch.org/
[17] Triton: https://github.com/triton-lang/triton
[18] TVM: https://tvm.apache.org/
[19] NCCL: https://github.com/NVIDIA/nccl
[20] NVSHMEM: https://developer.nvidia.com/nvshmem
[21] FlashInfer: https://github.com/flashinfer-ai/flashinfer
[22] FlashAttention: https://github.com/Dao-AILab/flash-attention
[23] Triton: https://github.com/triton-lang/triton
[24] Mirage Persistent Kernel: https://github.com/mirage-project/mirage
[25] Mirage kernel superoptimizer: https://github.com/mirage-project/mirage
[26] 这篇文章: https://zhihaojia.medium.com/generating-fast-gpu-kernels-without-programming-in-cuda-triton-3fdd4900d9bc
#CS博士求职8个月0 offer,绝望转行
斯坦福入学停滞,全美仅增0.2%
计算机专业从神坛跌落?全美入学率仅增0.2%,斯坦福、杜克等顶尖高校招生大不如前。计算机博士求职8个月未果,有人狂投600份简历上岸,AI或成「就业杀手」。
谁曾想,曾经炙手可热的计算机专业,正逐渐走向「冷门」......
The Atlantic最新数据让人傻眼:
今年全美计算机专业入学率仅微增0.2%,不少顶尖院校招生几乎停滞。
过去一年,杜克大学计算机科学入门课程的报名人数,直接腰斩20%。
人工智能正取代那些创造它的人
普林斯顿大学计算机系主任Szymon Rusinkiewicz直言,照这样的趋势发展下去,两年后毕业生得缩水25%。
曾经人人追捧的香饽饽,现在AI大佬们都在劝退:别学编程了!
这背后最大的杀手,竟是AI。
如今,AI自动化了大量初级编程岗位,导致许多人「毕业即失业」的担忧加剧。
纽约联邦储备银行统计显示,计算机科学已成为全美失业率第七大专业,高达6.1%。
计算机科学的热潮,难道是要凉了?
斯坦福入学停滞,计算机专业爆冷
过去二十年,计算机专业被许多人奉为未来氪金的「王牌」。
2005至2023年间,美国计算机科学专业学生数量翻了两番,高薪神话吸引无数人扎堆。
正因如此,最新数据才显得如此惊人。
增长0.2%入学率,几乎可以约等于0,其中许多美国高校计算机专业招生人数严重下滑。
尤其是,公认的全美顶尖斯坦福大学,计算机专业人数在多年激增后,直接陷入停滞。
这波「退潮」看似突然,原因不难猜:初级程序员的就业市场,前景暗淡。
科技行业裁员潮、招聘冻结接踵而至,罪魁祸首正是AI。
皮尤研究中心的数据显示,美国人认为,软件工程师是生成式AI的「头号受害者」。
事实证明,AI在写代码方面的价值,甚至超过文字创作,直接威胁到初级程序员的饭碗。
求职八个月未果
狂投600份offer上岸
「AI正在完美取代那些创造它的人」。
这句话听起来扎心,却精准概括了现状。
田纳西大学博士生Chris Gropp的遭遇,就是一个活生生的例子。
他手握计算机科学、数学、计算科学(computational science)三个学位,博士课程全部修完。
然而,求职八个月,颗粒无收。
他认识的两位成功者中,一个为40个岗位量身定制求职信、跑断腿去面试,另一个直接狂投600份简历才上岸。
Chris苦笑道,「我身处AI革命,专攻AI技术,到头来却连一份工作也找不到」。
两个月前,他甚至放弃毕业,改行去当电工学徒。
Chris的困境并不是孤例,过去三年,美国22-27岁人群的总体就业率微增,但计算机和数学岗位就业率却暴跌8%。
想当年,顶尖院校的计算机毕业生轻轻松松就拿到了谷歌、亚马逊的offer,如今却得「卷生卷死」。
Chris的父亲、伊利诺伊大学超级计算中心主管William Gropp坦言,「他精通机器学习,却还在求职。我只能说,这行业真的变天了」。

技术人,被AI踢出局?
极具讽刺的是,AI抢走的不只是普通程序员的饭碗,连AI相关岗位都岌岌可危。
普林斯顿大学Szymon一针见血,「AI提升了效率,企业自然要少招人」。
纽约联邦储备银行上周公布的数据显示,截至3月,应届毕业生的失业率为5.8%,高于一年前的4.6%。
从事不需要大学学位的工作的新毕业生比例,在3月达到41.2%,高于2024年同期的40.6%。
毋庸置疑,AI渗透越深的行业,失业率也就越高。
科技巨头们已经不藏着掖着,谷歌和微软曾公开表示,AI已参与编写超25%的代码。
几天前,微软又裁了6000人。
Anthropic高管在播客中爆料,内部资深工程师正将工作交给聊天机器人,初级员工倒不如AI去做」。
CEO Dario Amodei甚至警告,未来5年,AI可能取代半数初级岗位。
但也有人认为,AI不该当全锅侠。
乔治城大学教育劳动力研究中心主任Zack Mabel认为,科技行业本就周期性强,眼下高利率威胁,企业缩减招聘很正常。
科技巨头们爱把裁员赖到AI头上,但这更多是他们自己的决策。
AI真要引发职场大地震,还得等企业彻底消化新技术,这一步还没走远。
计算机科学入学率向来随就业市场起伏,低谷后往往反弹更猛,像芝加哥大学目前还没掉队。
MIT教授Sam Madden甚至大胆预测,即便生成式AI大行其道,软件工程师的需求可能不减反增。
正如Reddit网友所言,AI虽自动化的简单部分,却让任务变得更加复杂——你得花一天时间,去找haystack里的那根针。
专家建议:文科也是出路
不管这波低迷是短期的「阵痛」,还是职场大洗牌的开端,专家们给大学生的建议出奇一致:
选择能持久培养、可迁移技能的学科。
哈佛的研究显示,历史和社会科学专业的毕业生,长期收入可能超过工程和计算机同行,因为他们掌握了沟通、协作、批判性思维等「软技能」。
这些,才是雇主们的「心头好」。
「为学习特定技能而上学风险太高,你得攒一身能抗未来45年变革的硬本事」。
参考资料:
https://www.theatlantic.com/economy/archive/2025/06/computer-science-bubble-ai/683242/
#外国小哥徒手改装消费级5090
一举击败巨无霸RTX Pro 6000
一块经过 shunt mod 改装的华硕 ROG Astral LC RTX 5090 的性能,超越了售价 10,000 美元的 RTX Pro 6000。
「Shunt Mod」 是一种硬件级别的、具有高风险性的电路改装方法,主要用于绕过电子设备(特别是高性能显卡和主板)内置的功耗(功率)和电流限制。
这项惊人的成果来自硬件改装大师 Der8auer(本名 Roman Hartung)。
他是一位知名的超频爱好者和硬件改装专家,尤其以在显卡、CPU 以及其他计算机硬件上的极限超频技术而闻名。

Der8auer 表示,他已经有一段时间没有在 GPU 上进行shunt mod操作了,这次目标是解锁功率限制,然后看看显卡的性能如何,看看显卡是否能够通过解锁功率限制获得性能提升。
,时长23:07
一种提高硬件功率限制的改装
前面我们已经谈到,Der8auer 使用了 Shunt mod 分流改装。但其并不是万能的,可能对 GPU 的寿命造成危险。如果操作不当,你高价买的 GPU 可能会慢慢降级,或者非常快速地损坏。
除了对 PCB 改装本身的担忧外,Der8auer 表示 16 针电源连接器在达到 800W 时所承受的应变可能会变得更高,从而更加危险。
那什么是理想的 Shunt mod 呢?
Der8auer 解释道,他特意等了一段时间,从而获得一款配备高效一体式液冷(AiO)的显卡后才进行这次分流器改装实验,因为液冷方案能更好地应对更高的功耗。根据他的测试,华硕 ROG Astral LC RTX 5090 相比普通风冷版 Astral 显卡运行时更安静。在相同条件下,Astral 系列显卡通过华硕 GPU Tweak III 软件提供了丰富的参数调节和监控功能 —— 这些功能将在后续改装中发挥重要作用。
改装过程中,Der8auer 首先对显卡进行了一些基准测试,以获取关于性能、噪音和温度的初始数据。Der8auer 提到,虽然 RTX 5090 液冷版与风冷版的价格相近,但液冷版在处理更高功率时的表现更为稳定,并且安装和使用起来更加便捷。
在这次初步评估中,Der8auer 观察到显卡在负载下持续达到标准的 600W 功率目标后,表现得相当安静,并且似乎能够承受更多的功率。Der8auer 得出的结论是,600W 的功率限制无疑降低了超频潜力。
基准测试之后,Der8auer 开始动手改装。简单来说,这个改装其实相当直接。其原理是通过修改电源接口附近的电阻值来欺骗控制电路(将 5 毫欧分流电阻并联到 GPU 的板载 2 毫欧电阻上)—— 让系统误以为实际输入 PCB 的功耗比真实的要低。

根据 Der8auer 选择的电阻替换方案,理论上改装后能让显卡在毫无察觉的情况下承受约 30% 的额外功耗。

Der8auer 还借助 WireView 来监测真实功耗。而对于 Astral 系列显卡,其 16 针电源接口还具备引脚传感功能,这提供了另一种实时监控输入功耗的途径,该功能仍将保持实用价值。
经改装后,显卡的功耗从原来的 660 瓦增加到 720 瓦,GPU 频率提升至 2,950MHz,性能也有所提升。FPS 从原来的 146 帧提高到 152 帧,成功超越了售价 10,000 美元的 RTX Pro 6000 显卡。
显卡在长时间负载下,GPU 温度保持在 60°C 左右,内存温度为 80°C。通过硬件监控工具,实际功耗为 750 瓦到 790 瓦,比显卡显示的功耗高出约 200 瓦。



Der8auer 表示,这种改装适用于液冷显卡,特别是 AIO 或定制液冷显卡,对于风冷显卡可能不太适用,因为风冷系统可能无法处理额外增加的热量。
总结来说,经过分流改装的 RTX 5090 确实击败了售价 10,000 美元的 RTX Pro 6000,但仅仅是略微超越。与未改装的 RTX 5090 以及具有 96GB 显存的专业显卡相比,功耗显著更高。
参考链接:
#Play to Generalize
强化学习新发现:无需数学样本,仅游戏训练AI推理大增
第一作者谢云飞是莱斯大学博士生,导师为通讯作者魏晨教授,研究方向包括多模态生成与理解。
Project Leader 肖俊飞是约翰斯・霍普金斯大学博士生,导师为 Bloomberg Distinguished Professor Alan Yuille。
第二作者马崟淞是约翰斯・霍普金斯大学博士生。
第三作者兰石懿是英伟达 Research Scientist。
最近,强化学习领域出现了一个颠覆性发现:研究人员不再需要大量数学训练样本,仅仅让 AI 玩简单游戏,就能显著提升其数学推理能力。
此前已有研究发现,即使不提供标准答案,仅用数学问题进行强化学习也能提高模型性能,这让人们开始重新思考强化学习的训练方式。而来自莱斯大学、约翰斯・霍普金斯大学和英伟达的研究团队更进一步:他们让多模态大语言模型 (MLLM) 玩贪吃蛇等简单游戏,无需任何数学或多学科训练数据,就显著提升了模型的多模态推理能力。研究团队提出了 ViGaL (Visual Game Learning) 方法,在多个主流视觉数学基准测试和 MMMU 系列基准测试中,超越此前在数学等领域内数据上训练的强化学习模型。
论文标题:Play to Generalize: Learning to Reason Through Game Play
论文链接:https://arxiv.org/abs/2506.08011
项目主页:https://yunfeixie233.github.io/ViGaL/
不用数学样本,游戏训练在数学基准取得突破
近期研究表明,相比监督微调(SFT),强化学习(RL)往往能实现更强的 “举一反三” 的跨领域泛化能力。以往的工作已经证明,在数学问题训练的模型能够扩展推理到物理问题,经过导航训练的智能体能够成功适应全新环境。然而,这些成功的泛化案例通常仍局限在单一领域内,源任务与泛化的目标任务依然属于同一类型。

图 1: 我们发现,只在例如贪吃蛇这种游戏上进行强化学习训练,模型就能涌现出领域外的泛化能力,在数学、多学科等多个任务上提高性能。
这篇工作的突破在于实现了更强形式的跨域泛化:从游戏领域完全迁移到数学推理、空间推理和多学科推理等领域。研究团队用 7B 参数的 Qwen2.5-VL 模型进行训练,发现仅通过强化学习训练模型玩贪吃蛇和旋转游戏,就能在多个基准测试中实现了显著提升:
- 数学推理提升:不用数学样本,仅通过游戏训练,ViGaL 在 MathVista 等数学推理基准上平均提升 2.9%,相比之下,在高质量数学数据集上进行强化学习的方法仅提升 2.4%。
- 多学科推理突破:在 MMMU 系列多学科推理任务上,ViGaL 超越在多学科数据上进行 RL 训练的 R1-OneVision-7B 模型 5.4 个百分点。
- 通用能力保持:经过测试,之前的强化学习推理模型在提升特定领域性能时,大部分都损害通用视觉能力,但 ViGaL 在保持原有通用性能的同时实现了推理能力的跃升。

图 2: 不使用数学或者多学科样本,仅通过游戏训练,模型在数学推理基准上平均提升 2.9%(左图),在多学科推理基准上平均提升 2.0%(右图),超过此前专门在数学或者多学科数据上训练的强化学习方法。
为什么游戏训练如此有效?

图 3: 我们在贪吃蛇游戏和旋转游戏上利用强化学习进行训练。在每个游戏里面,模型会接收图片和文本形式的游戏环境作为输入,遵循游戏指令进行推理,抉择一个动作在游戏环境里执行。执行后会从环境获得奖励 ,用于进行强化学习。通过在游戏中训练,模型获得了推理能力,并且能迁移至下游的数学和多学科等任务。
为什么玩游戏能提升数学能力?这个发现其实并不违背认知科学的基本规律。
回想一下我们自己的成长过程:小时候通过搭积木学会了空间概念,通过躲猫猫理解了位置关系,通过各种益智游戏培养了逻辑思维。儿童正是通过这些看似 "玩耍" 的活动,逐步构建起抽象思维的基础 —— 模式识别、空间推理、因果推断。
认知科学研究也证实了这一点:游戏常被用作探索人类心智的实验平台。研究人员通过 "四子连珠" 游戏研究规划能力,通过 "虚拟工具" 游戏探索问题解决的认知机制。
基于这样的理论启发,研究团队巧妙地设计了两款互补的训练游戏:
贪吃蛇游戏:这是一个经典的策略决策游戏。在 10×10 的网格上,模型需要控制蛇的移动,避免撞墙、撞到自己或对手,同时尽可能多地收集苹果。游戏培养的核心能力包括路径规划、避障决策和空间导航,这些技能直接对应数学中的坐标几何和函数图像理解。
旋转游戏:这是研究团队自主设计的 3D 空间推理游戏。模型需要观察同一 3D 物体的两个视角 —— 初始视角和旋转后视角,判断物体旋转了 90 度还是 180 度。这个游戏专门训练空间几何理解能力,直接对应角度和长度相关的数学推理问题。
两款游戏的设计哲学互补:贪吃蛇主要提升 2D 坐标相关的数学表现,旋转游戏则更适合角度和长度推理。实验证实,联合训练两款游戏比单独训练效果更佳,展现了游戏多样性的可扩展潜力。
结语:合成任务的新时代
ViGaL 的成功揭示了一个潜在的新趋势:当高质量人类数据枯竭,简单任务性能饱和的时候,精心设计的游戏,作为一种合成任务,可能为多模态推理能力的发展开辟新道路。
与传统的直接训练方法相比,这种游戏化的训练范式展现出独特的优势:
- 成本极低:无需人工标注,可无限扩展
- 效果显著:零数学样本超越数学专训模型
- 拓展性强:可以组合多个任务进一步提升性能
- 通用性好:不会造成 "偏科" 问题,保持模型的全面能力
更重要的是,ViGaL 可能揭示了一个朴素但深刻的道理:在直接学习目标任务之外,培养底层的通用推理能力,也许同样有助于模型性能的提升。就像我们不只是通过死记硬背数学公式来培养数学思维,而是通过各种思维训练来发展抽象推理能力一样。
在 Scaling Law 可能逐渐面临困境的今天,ViGaL 用一个简单而优雅的想法提醒我们:有时候,让 AI"玩游戏" 可能比让它 "刷题" 更有效。
#BookWorld
让小说角色 「活」起来!复旦BookWorld打造沉浸式小说世界模拟系统
BookWorld由复旦大学冉一婷、王鑫涛主导完成,由阳德青老师、肖仰华老师共同指导。复旦大学知识工场实验室长期关注大语言模型的人格化、角色扮演研究,在该领域发表多篇顶会论文和首篇综述。
想象为《红楼梦》或《权力的游戏》创造一个AI的世界。书中的角色们变成AI,活在BookWorld当中。每天,他/她们醒来,思考,彼此对话、互动,建立感情和关系。
如果他们能活出自己的生活,不再由笔者操控,故事是否会不一样?会不会有一个平行时空里,宝玉和黛玉有了一段美好的爱情?
今天要介绍的这篇 ACL 2025 论文 ——《BookWorld: From Novels to Interactive Agent Societies for Creative Story Generation》,聚焦于如何让小说中的角色真正 "活" 起来,打造一个沉浸式的虚拟世界。
在BookWorld中,作者们提出了一个“小说->AI世界->故事创作”的系统。BookWorld能从小说中提取角色和世界观的数据,构建一个AI世界,让角色AI在世界中进行长期的交互,自己创造自己的故事。为了实现流畅自然的长期交互,BookWorld建模了角色AI、世界AI、空间关系、世界观构建,并支持用户干预来引导故事发展。
论文标题:BookWorld: From Novels to Interactive Agent Societies for Creative Story Generation
主页链接:https://bookworld2025.github.io/

BookWorld 开创性地提出了基于小说构建多智能体社会的方法,让小说中的角色能够自主互动、成长和创造故事。系统不仅完美还原了小说中的世界观,还能让角色们在虚拟世界中自由演绎,创造出全新的故事篇章。
研究背景:小说世界的困境
传统的小说创作往往受限于作者的想象力,一旦故事完结,角色们就被 "封印" 在书页中。而现有的 AI 系统虽然能够生成文本、模拟社会互动,但大多是从零开始构建角色,缺乏对已有小说世界的深度理解和还原。
BookWorld 的突破在于,它能够从原著小说中提取角色特征、世界观设定和背景知识,构建出一个完整的虚拟社会。在这个世界里,每个角色都拥有自己的记忆、状态和目标,能够像真实人物一样工作、交流和交易。

核心方法:BookWorld 框架
BookWorld 系统由角色智能体和世界智能体组成。角色智能体负责扮演小说中的各个角色,而世界智能体则负责协调整个系统的运作,维护全局状态,提供环境反馈等。系统采用了场景(Scene)作为最小叙事单位,每个场景都像小说中的章节一样,既保持独立性,又能构成完整的故事。
系统支持两种模式:自主模式和干预模式。在自主模式下,角色们会根据初始全局事件(如 "众人被卷入了一场战争")制定目标并行动;在干预模式下,用户可以通过指定情节或脚本来控制故事的发展方向。特别值得一提的是,系统还加入了地理空间建模,角色们的移动会受到地理限制和旅行时间的影响,营造更深入的沉浸感。
数据准备:让虚拟世界更真实
为了让虚拟世界更加真实,BookWorld 从 16 部中英文小说中提取了丰富的设定数据。系统采用了一种创新的基于术语的设定抽取方式,能够自动从原文中提取并整理世界观设定。每条设定包含四个关键要素:术语(如 "隐形斗篷")、性质(如 "道具"、"咒语")、详情(具体描述)和来源(首次出现的章节)。通过这种方式,系统成功从 10 部英文小说和 6 部中文小说中提取了 9142 条设定信息,为构建沉浸式的虚拟世界提供了坚实基础。

模拟流程:让故事自然展开
BookWorld 的模拟过程以 "幕" 为单位推进,每一幕都像一个独立的戏剧场景。在每一幕开始前,系统会选定出演角色,这些角色必须身处同一地点,以确保情节的集中性和互动的合理性。角色们可以自由选择与其他角色对话、与环境互动,或者静观其变。世界智能体会根据当前信息和角色状态,动态决定每一轮的行动顺序,让故事发展更加自然流畅。

实验成果
在大量实验中,BookWorld 展现出了惊人的创造力。它不仅能够保持对原著的忠实度,还能生成高质量的新故事,在 75.36% 的案例中超越了现有方法。系统在五个关键维度上都表现出色:拟人化、角色忠实度、沉浸感与场景、写作质量和故事线质量。



未来展望
BookWorld 不仅是小说创作工具,更是一个互动娱乐平台的雏形。作者可以用它探索不同结局,读者则能 “进入小说”,成为剧情的一部分。未来,它将支持更复杂设定,开放更多 “平行故事线”,让每位用户都能拥有属于自己的小说宇宙。
#VIRES
众所周知视频不能P?北大施柏鑫团队、贝式计算CVPR研究:视频里轻松换衣服、加柯基
视频是信息密度最高、情感表达最丰富的媒介之一,高度还原现实的复杂性与细节。正因如此,视频也是编辑难度最高的一类数字内容。在传统的视频编辑流程中,若要调整或替换主体、场景、色彩或是移除一个物体,往往意味着无数帧的手动标注、遮罩绘制和精细调色。即使是经验丰富的后期团队,也很难在复杂场景中保持编辑内容的时间一致性。
近年来,生成式 AI 尤其是扩散模型与多模态大模型的快速迭代,为视频编辑带来了全新的解题思路。从早期基于规则的特效工具,到目标识别与自动分割,再到基于文本指令的视频生成与重绘,尽管 AI 已经为视频编辑带来了效率与可控性的双重提升,但在精度要求较高的场景中仍存在一系列挑战,例如当前很多零样本方法在处理连续视频帧时容易造成画面闪烁;对于背景复杂或多目标场景,可能会出现错位、模糊或语义偏差。
针对于此,北京大学相机智能实验室(施柏鑫团队)联合 OpenBayes贝式计算,以及北京邮电大学人工智能学院模式识别实验室李思副教授团队,共同提出了一种结合草图与文本引导的视频实例重绘方法 VIRES,支持对视频主体的重绘、替换、生成与移除等多种编辑操作。该方法利用文本生成视频模型的先验知识,确保时间上的一致性,同时还提出了带有标准化自适应缩放机制的 Sequential ControlNet,能够有效提取结构布局并自适应捕捉高对比度的草图细节。更进一步地,研究团队在 DiT(diffusion transformer) backbone 中引入草图注意力机制,以解读并注入细颗粒度的草图语义。实验结果表明,VIRES 在视频质量、时间一致性、条件对齐和用户评分等多方面均优于现有 SOTA 模型。

VIRES 与 5 种现有方法在不同数据集上的多类指标得分
相关研究以「VIRES: Video Instance Repainting via Sketch and Text Guided Generation」为题,已入选 CVPR 2025。
论文主页:https://hjzheng.net/projects/VIRES/
项目开源地址:https://github.com/suimuc/VIRES
Hugging Face地址:https://huggingface.co/suimu/VIRES
研究所用数据集下载地址:https://go.hyper.ai/n5pgy
大规模视频实例数据集 VireSet
为了实现精准的可控视频实例重绘,研究团队标注了大量视频实例的 Sketch 序列、Mask 以及文本描述,提出了一个配备详细注释的大规模视频实例数据集 VireSet。其中包含了 86k 视频片段、连续的视频 Mask、详细的草图序列,以及高质量的文本描述。
此前,Meta 曾开源了一个大规模视频分割数据集 Segment Anything Video dataset(SA-V 数据集),提供了 51k 个视频以及 643k 个实例 Mask。然而,其中实例 Mask 的标注是间隔 4 帧标注一次,因此 FPS 为 6,导致 Mask 非常不连贯。为了得到连贯的视频实例 Mask,研究团队利用预训练的 SAM-2 模型,对中间帧进行标注,从而将 Mask 的 FPS 提高到 24。效果对比如下所示:
,时长00:04
原视频
,时长00:04
SA-V 提供的 Mask
,时长00:04
研究团队标注的 Mask
随后,研究团队采用预训练的 PLLaVA 模型为每个视频片段生成文本描述,并利用边缘检测算法 HED 提取每个视频实例的 Sketch 序列,为每个实例提供结构上的指导信息。
,时长00:04
The video shows a small, dark-colored goat with a blue and white striped cloth draped over its back. The goat is seen walking across a grassy area with patches of dirt. The background includes green vegetation and some sunlight filtering through the trees, creating a serene outdoor setting. The goat appears to be moving at a steady pace.
结合草图与文本引导的视频实例重绘方法 VIRES
VIRES 主要由 3 大模块组成:带有标准化自适应缩放的 Sequential ControlNet,带有草图注意力机制的 DiT backbone,以及用于改进解码过程的草图感知编码器,VIRES 的工作流程如下图所示。

VIRES 的工作流程
如图 a 所示,输入视频首先被 VAE 压缩 64 倍空间纬度和 4 倍时间纬度,变成潜码,噪声会根据 Mask 序列被选择性地添加到潜码中。随后,该噪声潜码被送入去噪网络(Denoising network)进行去噪,如图 b 所示。该网络由多个具有时间和空间注意力机制的 Transformer 块堆叠组成。
为了实现对实例属性的精确控制,研究团队提出了 Sequential ControlNet,从 Sketch 序列中提取结构布局,如图 c 所示。为了自适应地捕捉 Sketch 序列中的细节,团队引入了 Standardized self-scaling 来增强 Sketch 序列中黑色边缘线与白色背景之间的高对比度过渡。此外,为了确保稳定且高效的训练,其根据视频潜码特征的均值,对齐处理后的 Sketch 特征与视频潜码特征,确保 Sketch 特征和视频潜码特征具有相似的数据分布。
为了在潜在空间中解释和注入细粒度的草图语义,研究团队设计了 Sketch Attention 来增强去噪网络的空间注意力块,如图 d 所示,Sketch Attention 结合了一个预定义的二进制矩阵 A ,以指示视频潜码与 Sketch 序列之间的对应关系。
最后,为了在潜空间内将编辑结果与 Sketch 序列进一步对齐,团队引入了草图感知编码器,提取多级 Sketch 特征来指导解码过程,如图 e 所示。
VIRES 的 4 个应用场景:
重绘,替换,生成与消除
文本指令可以传达一般的视频编辑目标,但在用户意图解释方面仍留有相当大的进步空间。因此,最近的研究引入了额外的引导信息(例如,草图)以实现更精确的控制。
部分现有的方法,如 RAVE,利用 Zero-Shot 的方式,将图片编辑模型扩展成视频编辑模型,但由于依赖预训练的文本到图像模型,该方法在时间一致性上表现不佳,不可避免地导致画面闪烁。
,时长00:03
A light orange and white fish swimming in an aquarium
VIRES 通过利用文本到视频模型的生成先验,保持了时间一致性并生成了令人满意的结果。
,时长00:03
A light orange and white fish swimming in an aquarium
另外一些方法,如 VideoComposer,在文本到图像模型中引入时间建模层并微调,但该方法对组合性的关注限制了编辑视频与提供的 Sketch 序列之间的准确对齐,导致细粒度编辑效果不佳,如下图所示效果,人物衣服的袖子消失。
,时长00:04
A players wears a light green jersey with the white number 1 on the back
VIRES 提出 Sequential ControlNet 和定制的模块来有效处理 Sketch 序列,将编辑视频与提供的 Sketch 序列准确对齐,实现细粒度编辑。效果如下图所示:
,时长00:04
A players wears a light green jersey with the white number 1 on the back
对于每个视频实例,提供重绘的控制条件,包括 Sketch 序列、Mask 序列和相应的文本描述,VIRES 能够生成与条件一致的编辑视频。
如下所示,VIRES 有 4 个主要应用场景,首先是视频实例重绘,例如更换人物身着衣服的材质和颜色;其次是视频实例替换,例如将视频中的红色皮卡替换成黑色 SUV。
,时长00:03
第三是定制实例生成,如演示视频中在户外雪地增加一只柯基;最后一个场景是指定实例消除,例如删除视频中的足球。
,时长00:03
VIRES 在多项指标上超越现有 SOTA 模型
研究团队将 VIRES 与 5 种目前最先进的方法进行了比较,包括 Rerender(SIGGRAPH Asia’23),VidToMe(CVPR’24),Text2Video-zero(ICCV’23),RAVE(ICCV’23),VideoComposer(NeurIPS’24)。
为了确保详细的比较,其不仅在 VireSet 数据集上进行测试,还在业内广泛使用的 DAVIS(CVPR’16)数据集上进行了测试。实验结果显示,VIRES 在客观评价指标:视觉感知质量(PSNR)、空间结构一致性(SSIM)、帧运动准确性(WE)、帧间一致性(FC)和文本描述一致性(TC)方面均取得了最佳结果。
此外,团队还进行了两项用户调研,其一是视觉质量评估(VQE),参与者会看到由 VIRES 和对比编辑方法生成的编辑结果,需要选择最具视觉吸引力的视频片段。其二是文本对齐评估(TAE),给定一个对应的文本描述,要求参与者从同一组编辑后的结果中选择最符合该描述的视频片段。在用户调研中,VIRES 均取得了最佳结果。
VIRES 与 5 种现有方法在外观编辑上的表现对比:

VIRES 与 5 种现有方法在结构编辑上的效果对比:

另外值得一提的是,在 Sketch 引导视频生成方面,VIRES 还支持根据文本描述直接从 Sketch 序列生成完整视频。在稀疏帧引导视频编辑方面,VIRES 支持只提供第一帧的 Sketch 来编辑视频。效果如下所示。

可控视频生成领域的持续探索
总结来看,VIRES 在草图与文本引导下实现了实例结构一致性,而从某种角度来看,其也是面向「如何让空间结构信息在视频生成中稳定传递」这一重要挑战,给出了一种可靠的解决方案。与此同时,该研究团队步履不停,在突破这一类目标级控制之后,还将目光投向了全景级别的可控视频生成。
该研究团队提出了一种能够以最小改动,有效将预训练文本生成视频模型扩展至全景领域的方法,并将其命名为 PanoWan。该方法采用了纬度感知采样(latitude-aware sampling)以避免纬度方向的图像畸变,同时引入旋转语义去噪机制(rotated semantic denoising)和像素级填充解码策略(padded pixel-wise decoding),以实现经度边界的无缝过渡。实验结果表明,PanoWan 在全景视频生成任务中的表现达 SOTA 级别,并在零样本下游任务中展现出良好的泛化能力。相关论文现已发布于 arXiv:https://arxiv.org/abs/2505.22016。
聚焦该研究团队,北京大学相机智能实验室(http://camera.pku.edu.cn),负责人施柏鑫,北京大学计算机学院视频与视觉技术研究所副所长,长聘副教授(研究员)、博士生导师;北京智源学者;北大 - 智平方xx智能联合实验室主任。日本东京大学博士,麻省理工学院媒体实验室博士后。研究方向为计算摄像学与计算机视觉,发表论文 200 余篇(包括 TPAMI 论文 30 篇,计算机视觉三大顶级会议论文 92 篇)。论文获评 IEEE/CVF 计算机视觉与模式识别会议(CVPR)2024 最佳论文亚军(Best Paper, Runners-Up)、国际计算摄像会议(ICCP)2015 最佳论文亚军、国际计算机视觉会议(ICCV)2015 最佳论文候选,获得日本大川研究助成奖(2021)、中国电子学会青年科学家奖(2024)。科技部人工智能重大专项首席科学家,国家自然科学基金重点项目负责人,国家级青年人才计划入选者。担任国际顶级期刊 TPAMI、IJCV 编委,顶级会议 CVPR、ICCV、ECCV 领域主席。APSIPA 杰出讲者、CCF 杰出会员、IEEE/CSIG 高级会员。
主要合作者 OpenBayes贝式计算作为国内领先的人工智能服务商,深耕工业研究与科研支持领域,通过为新一代异构芯片嫁接经典软件生态及机器学习模型,进而为工业企业及高校科研机构等提供更加快速、易用的数据科学计算产品,其产品已被数十家大型工业场景或头部科研院所采用。
双方共同在可控视频生成领域的探索已经取得了阶段性成果,相信在这一校企合作模式下,也将加速推进高质量成果早日落地产业。
#Cache Me If You Can
陈丹琦团队如何「抓住」关键缓存,解放LLM内存?
普林斯顿大学计算机科学系助理教授陈丹琦团队又有了新论文了。

近期,诸如「长思维链」等技术的兴起,带来了需要模型生成数万个 token 的全新工作负载。
大多数语言模型都基于 Transformer 架构,其在进行自回归解码(即逐字生成文本)时,需要将所有先前 token 的注意力状态存储在一个名为 KV 缓存的内存区域中。
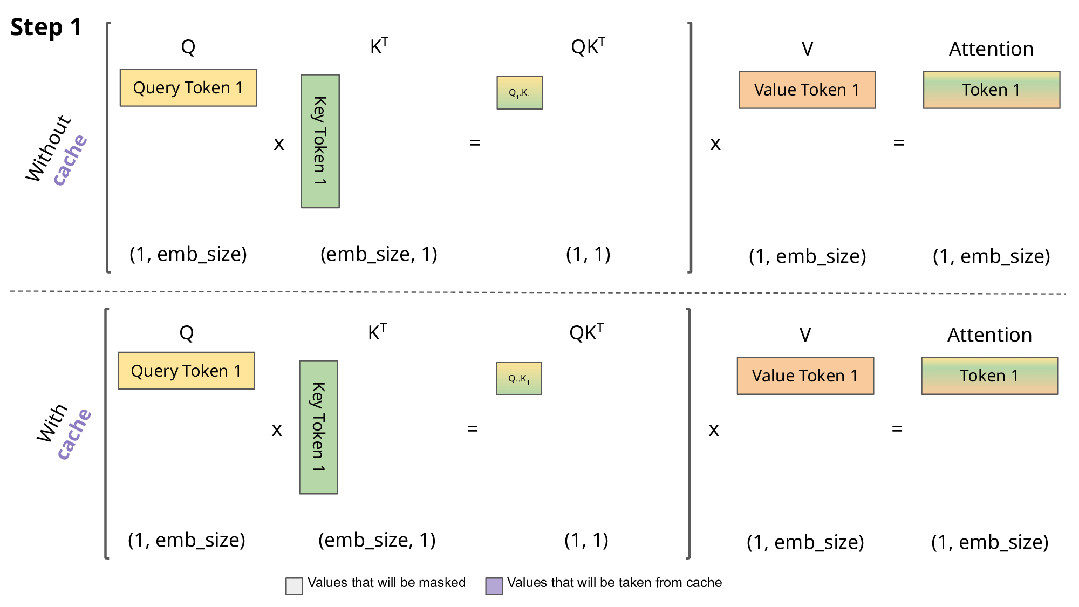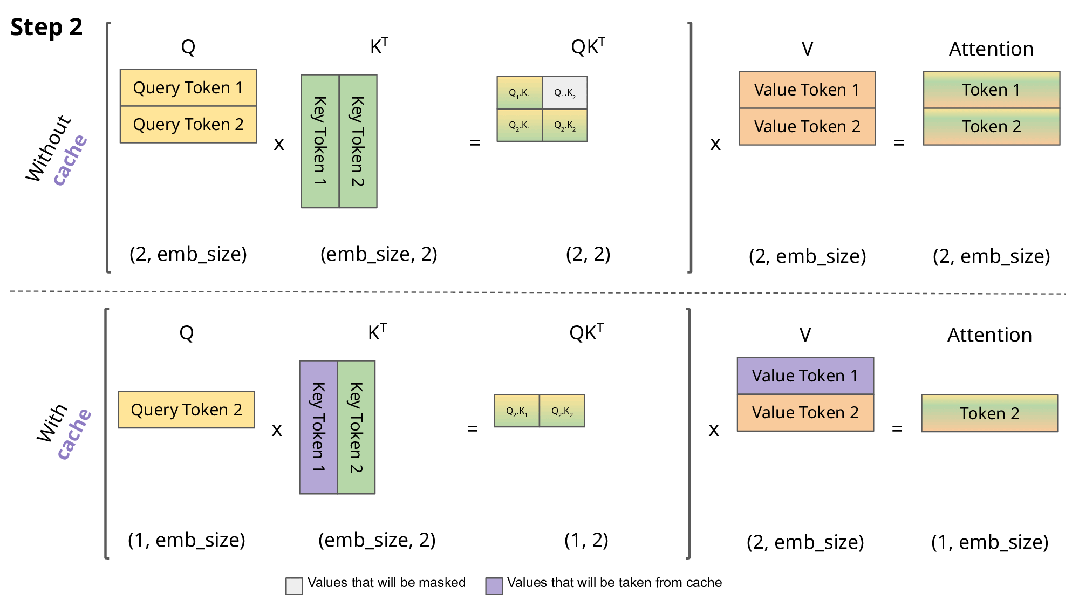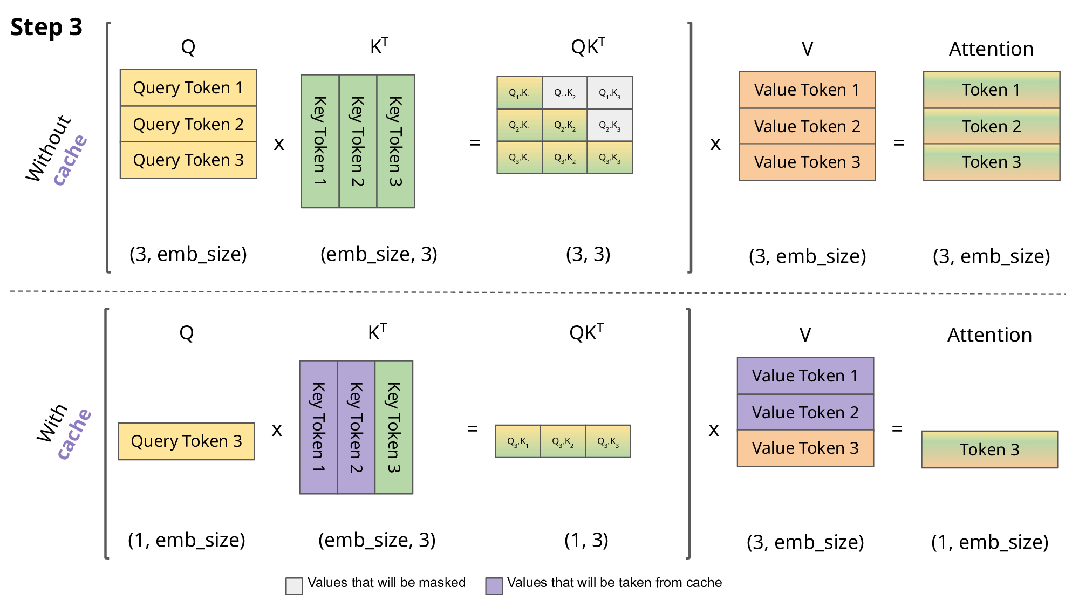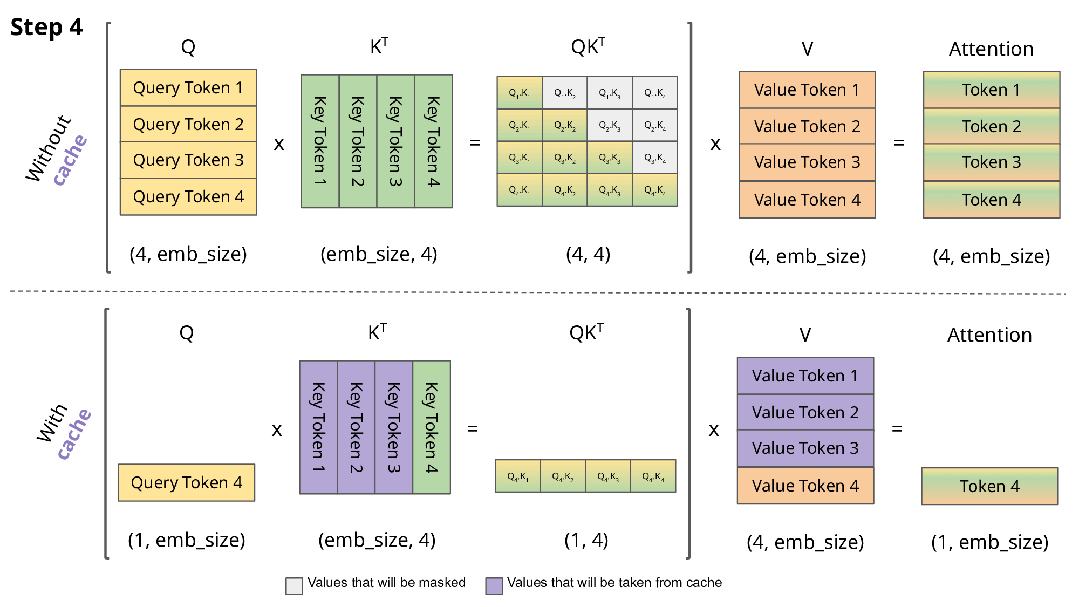
KV 缓存是模型进行快速推理的基石,但它的大小会随着输入文本的长度线性增长。例如,使用 Llama-3-70B 模型处理一个长度为 128K token 的提示(这大约相当于 Llama 3 技术报告本身的长度),就需要分配高达 42GB 的内存专门用于存储 KV 缓存。
许多先前的工作意识到了这个问题,并提出了从内存中丢弃(驱逐)部分键值对的方法,以实现所谓的「稀疏注意力」。然而,在一个公平的环境下对它们进行横向比较却异常困难。

生成过程 = 预填充(对输入进行前向传播并保存键值对)+ 后填充(一次解码一个输出词元)。
有些论文旨在加速预填充阶段;另一些则忽略该阶段,转而致力于最小化后填充阶段的内存开销。同样,有的研究侧重于吞吐量,而另一些则着力于优化内存使用。
陈丹琦团队提出了「KV 足迹」作为一种统一的度量标准,它是在所有时间步中,未被逐出的键值缓存条目所占比例的聚合值。这一个指标就同时涵盖了预填充和解码两个阶段的全部开销,使得在同等基础上比较不同方法成为可能。
论文标题:Cache Me If You Can: How ManyKVsDoYouNeed for Effective Long-Context LMs?
论文地址:https://arxiv.org/pdf/2506.17121v1
代码地址: https://github.com/princeton-pli/PruLong
为了确保比较的实用价值,团队定义了「关键 KV 足迹」:即在模型性能相对于完整的全注意力机制不低于 90% 的前提下,一个方法所能达到的最小 KV 足迹。这个「90% 性能」的硬性标准,确保了我们比较的是真正有用的、未严重牺牲模型能力的优化方法。
该度量标准揭示了先前 KV 驱逐方法存在的高峰值内存问题。其中后填充驱逐由于与预填充阶段的驱逐不兼容,导致其 KV 足迹非常高。团队对这类方法进行了改进,使其能够在预填充期间驱逐 KV,从而显著降低了 KV 足迹。
接着,团队转向「新近度驱逐」方法,并在此基础上提出了 PruLong,这是一种端到端的优化方法,用于学习哪些注意力头需要保留完整的 KV 缓存,而哪些则不需要。PruLong 在节省内存的同时保持了长上下文性能,其 KV 足迹比先前的方法小 12%,并且在具有挑战性的召回任务中保持了原有的性能。
KV 缓存驱逐的统一框架测量关键的 KV 占用空间
给定一个包含
![]()
个 token 的提示语
![]()
,基于 Transformer 的语言模型通常分两个阶段来生成一个响应

:
- 预填充
整个输入序列
![]()
在一次前向传播过程中被处理。每个注意力头 h 的键值状态

被存储在 KV 缓存中。这里

,其中 d 是该注意力头的维度。
- 解码
逐个解码生成

这些 token,每次生成时都会读取并更新 KV 缓存。
KV 缓存的存储消耗会随着提示长度和生成长度的增加而线性增长,研究人员提出了许多方法来解决这一开销问题。总体而言,这些方法通过稀疏化注意力模式,从而允许某些 KV 条目被驱逐。
然而,这些方法针对推理流程的不同阶段进行了定制:有些方法在预填充阶段之后丢弃 KV 条目,而另一些方法则在预填充阶段也对 KV 缓存进行修剪。这使得对不同方法进行公平且全面的比较变得困难。首先探讨为何常用的 KV 缓存大小指标无法衡量模型在实际应用中的实用性。
在实际应用中,对长上下文进行单次前向传播的预填充操作成本高昂。对于长输入序列,将输入序列分割成多个块,并在多次前向传播中处理这些块的分块预填充方法正日益成为标准实践。这种方法通常能够减少与长输入相关的峰值 GPU 内存占用,并使得较短提示的解码过程能够与较长提示的额外块同时进行。
此外,像多轮对话或交错工具调用等场景,还需要多个解码和预填充阶段,这就需要一种全面的方法来衡量 KV 占用空间。而推测性解码进一步模糊了预填充阶段和解码阶段之间的界限,因为解码过程变得更加依赖计算资源。
在考虑预填充和解码过程中都进行多次前向传播的推理情况时,「KV 占用空间」应考虑随时间变化的内存使用情况。例如,它应反映出在分块预填充过程中,是否在预填充完成之前就已经驱逐了 KV 条目。
具体的推理过程由输入长度、输出长度以及因方法而异的实现细节来表征。由于缺乏能够捕捉所有这些细微差别的指标,本研究提出了一种理想化的指标,该指标能够:(1)跟踪整个预填充和解码过程中的 KV 缓存内存使用情况;(2)考虑每个 KV 条目的生命周期,从而实现对不同方法的公平且全面的比较。
本研究检查这些方法的注意力模式(图 1),并将每个键值(KV)条目分类为:活跃的(在当前步骤中使用)、非活跃的(在当前步骤中存储但未使用)或被驱逐的(在任何未来的步骤中都未使用,并从内存中移除)。本研究将 KV 占用空间定义为所有时间步中未被驱逐的注意力条目的数量。该数值被归一化为完全因果注意力。

例如,在图 1 中,KV 占用空间为 26/36=72.2%。一种理想的方法会尽早驱逐 KV,以尽量减少占用空间。本研究考虑了另一种指标,该指标跟踪注意力矩阵中的峰值 KV 占用率。在实验中,这两种指标得出的结论相似。
本研究还讨论了方法与实际性能指标(如总令牌吞吐量和 GPU 内存利用率)之间的关系。研究发现,在许多情况下,KV 占用空间与吞吐量密切相关,但具体的排名取决于 KV 驱逐之外的实现细节——不同方法在不同实现框架下的实际效率差异很大。
关键 KV 占用空间:以往的研究通常在固定的稀疏度水平下报告任务性能,但本研究认为,一个更有意义的指标是在保留大部分原始性能的情况下所能达到的稀疏度。本研究将关键 KV 占用空间定义为一种方法在长上下文任务中保留完整注意力性能的一部分(本文中

)时所需的最小占用空间。低于此阈值,性能下降可能会过于严重,导致该方法无法继续使用。高效长上下文推理的现有方法
本研究调研了高效的长上下文方法,并讨论了它们如何契合本研究的 KV 占用空间框架。表 1 概述了主要方法,展示了这些方法如何进行不同的权衡以及使用不同的稀疏性概念。

动态和预填充稀疏性方面:Native Sparse Attention、MoBA、QUEST 和 TokenButler 将 KV 缓存视为两级层次结构,仅将相关的注意力块从高带宽内存(HBM)加载到片上 SRAM 进行处理。像 MInference 和 FTP 这类技术,在预填充阶段使用动态稀疏注意力来近似全注意力。动态稀疏性方法会产生更多非活跃的 KV,能够提升吞吐量,但它们并未减少 KV 内存,因此这些方法与本研究的关注点正交。
近期性驱逐:先前的研究确定了流式注意力头,这些注意力头仅关注局部滑动窗口和一组初始的「汇聚令牌」。驱逐远距离的键值(KV)条目会大幅减少 KV 占用空间(图 2),因为在上下文长度增加时,KV 缓存的大小保持固定,并且这种方法可在预填充和解码过程中应用。然而,近期性驱逐可能会「遗忘」相关的远距离上下文,这促使 DuoAttention 和 MoA 仅将一部分注意力头转换为流式头。作为 KV 缓存压缩的有前景的候选方法,后续将更详细地讨论这些方法。
后填充驱逐:我们使用「后填充驱逐」这一术语来指代在预填充阶段结束后从键值(KV)缓存中删除令牌的方法。这些方法依赖于通常基于注意力分数的启发式规则来识别上下文中最重要键值对。这些方法可以在预填充后大量修剪键值对,并在解码过程中减少 KV 内存。然而,在具有长提示和短生成的推理场景中,由于所有 KV 条目在预填充期间都保存在内存中,这也会在驱逐前导致相当大的峰值内存,后填充驱逐只能实现有限的 KV 占用空间减少。
正交技术:量化通过降低 KV 缓存的精度而非基数来节省内存,并且可以与本文考虑的任何方法结合使用。另一个方向是在预训练新语言模型之前设计内存高效的架构。这可能涉及在查询或层之间重用 KV 状态,降低键值维度,或者交错全局和局部注意力层。其他方法是用循环层、线性注意力或状态空间层替换 softmax 注意力。这些方法与 KV 驱逐正交。
PruLong:一种用于注意力头专业化的端到端方法
本研究探讨过:驱逐「陈旧」键值对(KVs)虽能显著降低内存占用,但可能导致重要历史信息的丢失。这一发现推动了后续研究工作,旨在识别哪些注意力头关注全局上下文、哪些聚焦局部上下文,从而仅对局部注意力头中的 KVs 执行驱逐操作。
DuoAttention 将注意力头分为两类:检索头,从整个上下文中召回相关信息;流式头,仅关注最近的 token 和输入序列开头的少量「汇聚」token。DuoAttention 通过将注意力机制表示为流式注意力和全注意力的叠加,并通过参数化来学习注意力头的类型。
![]()
其中,

和

分别遍历 Transformer 的

层和

个注意力头。掩码

通过原始模型和插值模型的最终隐藏状态之间的

重建损失进行训练,并且通过

正则化鼓励掩码

稀疏化。DuoAttention 使用长上下文训练数据,该数据由合成的大海捞针任务组成。在收敛时,通过将

的底部

设置为 0,其余设置为 1,获得

的注意力头稀疏度。
MoA 是另一种使用自然文本的方法,但当序列长度超过 8K 个 token 时,由于需要显式存储完整的注意力矩阵,难以扩展。
虽然 DuoAttention 在实证中表现出色,但团队发现了几种进一步降低其关键 KV 占用空间的方法。团队结合这些见解,设计出 PruLong(长程精简注意力机制),一种用于 KV 驱逐的端到端方法。PruLong 像 DuoAttention 一样将注意力头分为两类,但在训练目标、参数化和训练数据方面进行了创新。接下来将依次介绍这些内容。
- 下一个 token 预测损失
PruLong(长程精简注意力机制)直接最小化混合注意力模型的下一个 token 预测损失,而非最后一个隐藏状态的重建误差,这与这些模型在文本生成中的使用方式更为契合。
- 针对注意力类型优化离散掩码
DuoAttention 学习一个连续的门控变量

,该变量易于优化,但没有反映出在推理过程中

会被四舍五入为 0 或 1,因此引入了训练-测试差距。PruLong(长程精简注意力机制)将

视为从由

参数化的伯努利分布中抽取的二进制掩码,并通过来自剪枝文献的既定方法——将伯努利分布重新参数化为硬实体随机变量,实现端到端优化。最终目标如下

其中,

(正则化损失)通过约束掩码整体稀疏度

(稀疏度函数)逼近目标值

(目标稀疏度),该过程通过 min-max 优化实现——

和

作为可训练的拉格朗日乘子,通过梯度上升法进行优化。
- 利用自然长上下文数据
PruLong 利用自然长上下文数据。DuoAttention 的合成训练数据仅需要简单的长程回忆能力,而实际应用场景可能需要更复杂的能力。PruLong 由高天宇等人在自然长上下文预训练数据上进行训练,这些数据包含代码仓库和书籍等,具有多样的长程依赖关系。
PruLong 论文地址:https://arxiv.org/abs/2410.02660
#AI讯飞学习机~~
讲得了课、押得中题、学习规划还能量身定制,真卷到点子上的只有它
真正能支撑AI学习机「因材施教」的,不只是模型,而是基于模型的一套组合拳。而这些,正是讯飞用了20多年打下的底子。
设好闹钟,手指悬空待命,购物节一开场——啪!2秒下单,朋友稳稳拿下一台AI讯飞学习机,比抢孙燕姿鸟巢演唱会的内场票果断多了,那票明明比学习机便宜一大截。
为何如此「杀伐果决」?因为她已经试过那些「无所不能的 AI 」,真让它来辅导孩子学习,结果就是:天崩开局。
小学数学附加题,大模型张嘴就来一元一次方程,孩子现场「当机」;
练口语,参考「牛娃」家长推荐的大模型,一开口就是两个长句,直接给家里「普娃」整闭嘴;
交了篇 300 字的 AI 小作文,老师点评:「这是流水账。」
她当时就明白了:再聪明的模型,如果不懂新课标、找不出知识漏洞、不会循循善诱,那它不过就是另一个「不会教」的大人罢了。
「Buff 」升级,AI 「因材施教」 又叒进化
随着高考落下帷幕,一个名字悄然破圈、进入更多家长的视野——讯飞星火大模型 X1。
在多家主流媒体组织的大模型高考 Ⅰ 卷测试中,X1 表现亮眼:
高考语文作文测试,以平均得分 53 分的成绩在国产 AI 中排名第一;
数学测试取得超 140 分的高分;
英语作文测试以平均分 19.5 分,获得专家打分第一名。
X1 是科大讯飞于今年 1 月发布的深度推理大模型,上能硬刚奥数、高考,下能讲解小学寒假作业,还是「当前业界唯一全国产算力训练的深度推理大模型。」
4 月全新升级后,更轻量(仅70B)的同时性能全面对标 OpenAI o1、DeepSeek R1。
更关键的是,X1 不是纸上谈兵,已经走进真实课堂,成为一线老师手中的「第二大脑」。
在合肥七中、人大附中等学校,X1 作为 AI 黑板的技术基座,已支持语音指令、虚拟人助教、3D 几何渲染等多模态教学功能,带来沉浸式课堂体验。

据官方数据,人大附中 130 名教师全员使用后,数学学科 AI 工具使用率达 46.3% ;株洲外国语学校课堂互动效率提升达 42%。
在 C 端,X1 驱动的 AI 学习机表现同样引发关注。其「精准学」模块原题高度匹配今年高考新课标 Ⅰ 卷数学真题——
共16 题、122 分!选择题最高相似度达 98% ,填空题最高相似度 98% ,解答题最高相似度 85% 。

而这,还只是一个开始。
就在今天下午,讯飞又宣布学习机三大AI 1对1 功能迎来全新升级。AI 「因材施教」能力再提速,学习体验跃升一个新台阶。
1、「 AI 精准学」升级,个性化规划再进化。
自 2019 年首提「 AI 精准学」以来,它一直是讯飞 AI 学习机的王牌功能,也包括一套完整的「测-学-练」闭环系统:
通过 AI 快速测试诊断孩子的知识薄弱项,再个性化规划适合孩子的学习路径,针对性推荐学习资源和练习资源,让孩子在学习流程中获得精准提升。
测:通过几道题,快速找到薄弱项。比如,考试时有一道几何题做错了,AI 分析后发现,问题并不在几何本身,而是因为更早学过的「相似三角形」没有掌握好;七年级做错方程题,AI 能追溯到小学阶段「认识等式与方程」这一环节出了问题。
学:定位问题后,AI 会推荐对应的知识点微课视频,短小精悍,讲解直指学生的疑点和难点;
练:针对薄弱项举一反三。
结果是:以人推径 以人推课 以人推题,「千人前面」。
例如,两位同学,一个是学优生,一个是学困生,他们在考试中错了同样的一道题,但 AI 推荐的学习内容不一样;
两位同学,都考了 80 分,但系统分析发现,他们的薄弱点有很大不同,系统推荐的学习路径也有很大差异。

本轮升级中,新增「AI 1对1 互动式问诊规划」功能。通过几轮类对话式交流,系统可像真人老师一样,自动判断孩子的知识掌握情况,并综合学习能力、习惯、时间投入、本地考试重点等因素,智能生成个性化学习路径。
「我们的AI 1对1 精准学,不是刷题工具,而是真正像老师一样为孩子定制学习方案。」科大讯飞 AI 学习机产品线总经理翟吉博这样形容。
同时,作为学习闭环的配套——
全科精品密卷全面升级,覆盖小初高所有学科;
AI 组卷功能可支持小学和初中数学,做到全题型覆盖。只要孩子说出需求,AI 立刻组卷,高效匹配最合适的练习内容。
2、AI 答疑辅导更会讲题啦!
孩子复习备考遇到难题,家长不懂辅导,气得「心梗」?别担心,现在有 AI 老师帮忙答疑。
AI 老师不会直接给答案,更像是「苏格拉底」,通过多轮对话、层层提问,启发学生逐步拆解问题。正如著名教育心理学家 Carol Dweck 所强调的——学习的关键不在答案,而在思考的过程。
比如下面这道题:
小明正在阅读一本 120 页的书。昨天他读了 12 页,今天他读的页数是昨天的两倍。如果他想明天读完剩余页数的一半,他明天需要读多少页?
AI 会一步步引导学生:
为了计算小明明天要读多少页,我们需要先知道什么?我们怎么知道还剩多少页?
现在,要知道昨天和今天一共读了多少,对吗?小明今天读了多少页?你知道怎么计算了吗?
在这个过程中,水平不同的学生会有不同反应,AI 会动态理解这些复杂的交互情境,做出自适应的调整。
如,针对错误答案,会先肯定学生的努力,然后继续给出提示引导思考;识别无关话题,引导学生回到问题上来。
全新升级后的 AI 1对1答疑辅导,支持更多学科和学段,新增支持小学数学、初中语文和初中数学。
结合大模型的最新进展,还支持结构化讲题,AI 老师通过启发式提问,引导孩子主动思考,一步步推导出答案。做到「学会一道题,掌握一类题」。

3、AI 互动课,也能真正个性化。
市面上不少「AI 互动课」其实只是换了「马甲」的录播课——加了弱 AI ,却仍是一套内容面向所有学生,毫无个性化可言。
讯飞 AI 1对1 互动课主打像老师一样吸引孩子的注意力,带着孩子沉浸式的互动,让孩子学有所获。
本次,AI 1对1 互动课也全新升级——
全新上线的 AI 绘本伴读互动课,专为 3 到 8 岁孩子设计,AI 伙伴能实时回应孩子的各种提问,让「陪读」更智慧、更有趣。
同时,还重磅推出了自研的新课标体系课,平均每节课控制在 5~15 分钟内,既贴合教学大纲,又更聚焦重点难点,树立 AI 同步课的新标杆。
据翟吉博介绍,这个暑期,AI 学习机还将陆续上线小学数学 AI 课本、AI 老师 1对1 规划学和关注心理健康的「减压绿洲」等功能。7 月中旬起,它们将面向广大老用户免费升级。
体验的上限,在于 AI「地基」
这波 AI 学习机的「学霸 Buff 」, 靠的不是资料叠得多高,而是底层 AI 能力的厚度与精度。
其中关键一环,正是讯飞自研的苏格拉底教学大模型—— SocraticLM。
这个模型能遵循解题思维链,依次对不同步骤进行详细拆分、推导和解释,帮助学生一步步找到答案。这背后,有两个关键创新:
第一,思维引导式教学设计。
通过将老师脑中的「教学设计逻辑」与多年经验内化为 AI 能力,SocraticLM 会根据题目自动生成步骤级的引导问题,启发学生思考。
第二,自适应交互的「教学多智能体」。
讯飞提出了一种 「教导主任( Dean )-教师( Teacher )-学生( Student )」多智能体交互流程( multi-agent pipeline ),对每一步讲解效果进行评估和修正,直到找出最适合当前学生的讲法。
结果就是:AI 答疑辅导更像老师了,不止能讲,更会启发学生自己找到答案。
当然,光会「讲解」还不够。
要想避开低效的题海战术,实现「精准学」,第一步不是「讲」,而是「看懂学生」。
讯飞以大模型+多模态能力为核心,构建出一套覆盖「听、说、读、写、测、评、讲」的全流程学情采集与反馈体系。
举个例子:
- 拍一张作图题的照片,AI 能识别图形并指出「这是一个等腰三角形」;
- 开口说几句英语,它能分析发音准确率、指出语法错误;
- 写一篇作文,它能细致评估结构、语言、内容与表达逻辑。
每个工具的输入(手写、拍照、语音、绘图)都是多模态数据入口,支撑模型对学生真实学情的理解与判断。
看懂之后,AI 会进一步将学生的知识状态,映射到「知识地图」(学科知识点图谱)上,匹配最合适的「学」与「练」路径。
这背后是教育心理学中著名的最近发展区理论:孩子「跳一跳刚好能够到」的区域,才是最容易进步的地方。
掌握不牢的知识会被回溯到前置概念,分层讲解、层层递进、逐步攻破。
有人可能会问:AI 怎么知道你练了这道题就真的进步了?
这不靠玄学,而是靠一整套知识追踪技术,通过建模学生对知识点的掌握程度,预测他在下一道题上的表现。
值得一提的是「减压绿洲」,为有情绪困扰的学生提供更贴心的心理支持。
过去,这类功能多依赖传统机器学习,靠堆语料、抓关键词——学生说「情绪低落」,系统就甩出几十条模板化安慰语,听起来多、但效果差。
而现在,大模型的自然语言理解与生成能力彻底改写了这一现状。它不仅能听懂情绪背后的真实语境,还能给出更有温度、更具回应性的引导。
当然,这样的「心理素养」并非一蹴而就。背后,是海量心理学期刊、教材与专著的积累训练,以及海量脱敏后的真实心理对话样本不断打磨调试,才逐渐摸索出真正有效的「安慰配方」。
21 年教研基因沉淀,
才撑得起真正的「个性化路径」
自从大模型推理能力成为关键突破口,尤其是 DeepSeek 开源之后,AI 教育赛道被彻底点燃。短短几个月,市面上就涌现出一批主打「启发式教育」的学习机,声称能实现个性化与精准教学。
在这场声势浩大的 AI 教育升级战中,不只有科大讯飞这类 AI 原生玩家,还包括传统教育硬件厂商、教培转型品牌,以及靠搜题工具起家的公司。但热闹背后,不少玩家一直面临着 AI 技术成色不足的质疑,有基座模型能力的更是寥寥。
一些高端学习机连几何题中常见的三角形条件都无法准确识别;一道语文选择题,四个选项竟然全部识别错误;甚至还用错误答案倒推讲解,讲得头头是道,实则思路全错。
更有甚者,仅以客观题「测量」学情,殊不知少了主观题型,难以支撑真正有效的个性化学习路径。
说到底,倒出一碗水,得先有一桶水。
讯飞星火 X1 虽新,但根基深。作为国内最早一批 AI 实践者,科大讯飞在深度神经网络等底层技术上的投入,已经持续了十多年。
但要真正实现因材施教,光靠技术还不够。内容资源、标准和数据,一个都不能少。
过去这些年,讯飞与国家语委、教育部考试院、教育部教育技术中心等权威机构深度合作,共建实验室、联合开展专项研究。这让它对「教育标准」、「考试逻辑」有了更系统的理解,也为模型进入教学场景,打下了规范的基础。
与此同时,讯飞在智慧教育领域的产品与服务已覆盖全国 32 个省级行政区,因材施教项目落地 83 个区域,累计服务超过 5 万所学校、1.3 亿师生,构建了全国规模最大、更新最及时的区域化教育大数据和教育资源。
例如,它们涵盖了各地区答题记录、教材版本、学生学情、教师讲解等核心内容,支撑模型不仅会答题,教学更像老师;
还整合了全国近五年高考真题、地市模拟题和教材知识点,累计超 1000 万道题目。通过 AI 分析系统,这些题被结构化处理,自动识别出高频考点和命题趋势。
如在 2025 年数学卷中,一道关于「概率与数列结合」的压轴题,就与讯飞学习机「精准学」模块中推荐的题目高度相似——
系统正是识别出过去三年中该知识点交叉考查频率上升了 60%,从而实现了精准推荐与命中。
而所有这些,离不开二十年来讯飞在教育信息化这条高门槛、重模式赛道上,一点点打下的「地基」。换句话说,AI学习机是这条「护城河」的自然延伸、水到渠成。
另外,讯飞星火 X1 背后,还有一场更为关键的底层战役。
为了不在关键技术上受制于人,发展基于国产算力的自主可控大模型,成为国家层面的战略共识。科大讯飞与华为等伙伴一道,围绕国产算力平台展开联合攻关,解决了诸多底层优化难题,在国产算力平台上构建出业界最高水平的大模型。
教育部部长怀进鹏曾提出,要打造中国自己的人工智能教育大模型,实现真正的大规模因材施教。2025 年高考,讯飞星火 X1 已经交出了一份不俗的答卷。
而这个夏天,它即将迎来全新一轮升级。AI 教育,会走向怎样的新一程?
我们拭目以待。
#ToMAP
赋予大模型「读心术」,打造更聪明的AI说服者
本文第一作者为韩沛煊,本科毕业于清华大学计算机系,现为伊利诺伊大学香槟分校(UIUC)计算与数据科学学院一年级博士生,接受 Jiaxuan You 教授指导。其主要研究方向为:大语言模型的安全性及其在复杂场景中的推理。
说服,是影响他人信念、态度甚至行为的过程,广泛存在于人类社会之中。作为一种常见而复杂的交流形式,这一颇具挑战的任务也自然地成为了日趋强大的大语言模型的试金石。
人们发现,顶尖大模型能生成条理清晰的说服语段,甚至在 Reddit 等用户平台以假乱真,但大模型在心智感知方面的缺失却成为了进一步发展说服力的瓶颈。

成功的说服不仅需要清晰有力的论据,更需要精准地洞察对方的立场和思维过程。这种洞察被心理学称为「心智理论」(ToM),即认识到他人拥有独立的想法、信念和动机,并基于此进行推理。这是人类与生俱来的认知能力,而大模型在对话中却往往缺乏心智感知,这导致了两个显著的缺陷:
模型往往仅围绕核心论点展开讨论,而无法根据论点之间的联系提出新的角度;
模型往往仅关注并重复己方观点,而无法因应对方态度变化做出策略调整。
为解决这一问题,伊利诺伊大学香槟分校的研究者提出了 ToMAP(Theory of Mind Augmented Persuader),一种引入「心智理论」机制的全新说服模型,让 AI 更能「设身处地」从对方的角度思考,从而实现更具个性化、灵活性和逻辑性的说服过程。
- 论文标题:ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind
- 论文地址:https://arxiv.org/pdf/2505.22961
- 开源代码仓库:https://github.com/ulab-uiuc/ToMAP
ToMAP:知己知彼,百战不殆

ToMAP 创新性地在说服者框架中引入两大心智模块:反驳预测器和态度预测器。
反驳预测器模拟人类在说服中主动预判对方可能持有的反对观点。本文发现,大模型说服者本身就具备反驳预测的能力,只需要通过提示词设计「激活」这一能力即可。定性与定量分析显示,基于模型生成的反驳观点与真实被说服者的观点在语义上高度相似。这让说服者在对话中占据「先发优势」,从而主动化解对方的疑虑。在主张「素食食谱」的例子中,反驳预测器能主动识别出「烹饪麻烦」「味道不好」等对方反对素食的理由,构建出围绕核心论点的复合关系。
仅仅识别反论点并不能刻画复杂对话中的态度变化,因此,态度预测器进一步评估对手对上述反论点的态度——是坚定认可,还是中立或已被说服?该模块以对话历史和论点为输入,利用 BGE-M3 文本编码器与多层感知机(MLP)分类器,在对话过程中动态估算对方对各个论点的态度倾向,使说服者能有的放矢地展开论证。
实验表明,预测器在 5 点预测上的表现显著优于直接使用大模型推理。例如,在上图的对话中,对方已经认可素食对健康的好处,却提到其并不「享受」素食。这说明其很可能对素食的味道持保留态度,为下一轮的说服侧重点提供了关键线索。
两大预测器的引入使得说服者在作出决策时掌握更为丰富的信息:其不仅能预知对方可能的反驳意见,还能动态评估对方心理状态。这有利于其设计更多样化、有针对性的对话,切实有效地影响对方观点。
然而,LLM 本身未必能有效利用这些信息,为了充分发挥上述模块的优势,ToMAP 采用了强化学习(RL)方法,通过大量对话对模型进行训练。在每轮对话中,模型会根据「说服力得分」进行奖励,该得分衡量的是对方在一轮交互前后态度的变化。为避免重复、冗长、格式不当等问题,训练还引入了格式奖励、重复惩罚、超长惩罚等辅助信号,帮助模型生成通顺、有说服力的对话。
实验分析:运筹帷幄,策略制胜
本文在多种数据集与对手模型上对说服者模型进行了系统测试,评估对手模型在 3 轮对话前后的态度转变。

结果显示,基于 Qwen-2.5-3B 的 ToMAP 模型显著优于基线模型和无心智模块的 RL 版本。值得注意的是,尽管 ToMAP 仅使用 3B 参数的小模型,其性能却超越了多种参数规模更大的模型,包括 GPT-4o 与 DeepSeek-R1。这说明即使是规模较小的模型,在合适的训练配方和模块设计的加持下,也能展现出惊人的说服力。

回顾 ToMAP 模型的训练轨迹,我们得以一窥其能力增长背后的原理。从图中可以看出,在说服奖励不断增加的过程中,ToMAP 的重复度惩罚始终保持在较低水平,说明心智模块的信息有效地提高了模型输出的多样性。
另外,在对话长度相对稳定的条件下,ToMAP 的思考长度显著高于基线,表明 RL 赋予了模型深度思考策略的能力,具有不可或缺的作用。另外,ToMAP 更倾向于使用理性和有针对性策略,而非空洞的情绪煽动或权威引用——策略的改进正是其说服力提升的重要原因。

我们还发现,ToMAP 在长对话中依然稳定提升说服力。基准模型和常规 RL 模型在早期几轮对话中效果较好,但随着对话轮次增加,说服力趋于饱和甚至下降;相比之下,ToMAP 在 10 轮对话中依然保持稳定增长,显示出优秀的策略调整能力和论点的多样性。
结语:为 AI 注入「人性认知」的火花
本研究提出了 ToMAP,一种融合心智理论的 AI 说服框架,致力于解决当前大语言模型在说服任务中缺乏对手建模与策略灵活性的问题。论文通过「反论点预测器」模拟人类预判异议的能力,通过「态度预测器」感知对方态度的细微变化,使 AI 在说服过程中更加敏锐与应变。通过精心设计的强化学习机制,促进模型生成内容多样、结构规范、逻辑清晰的高质量论证。
ToMAP 不仅提升了模型的说服能力,在多个数据集和模型组合中显著超越强大基线,更是在大模型「心智建模」方向上迈出的重要一步。通过主动理解对方认知结构与态度倾向,ToMAP 展现出初步的「社会认知」特征,使得语言模型在复杂交互任务中更具人性化与策略性。
总之,ToMAP 不仅是一种有效的说服者训练框架,更是推动 AI 迈向具备「类人思维模式」的创新尝试,为构建可信、灵活的 AI 交流系统提供了坚实基础。
#哈佛重磅预警
经济学家预言:全球AI失业潮2年来袭,世界经济大崩盘在即
AI导致全民失业,绝非天方夜谭。刚刚,哈佛商学院放出视频,采访了一位美国经济学家。他向全人类预警:AGI可能在短短2-5年内就将实现,AI失业潮将席卷全球,一不小心,全球经济就将发生大崩溃!
AI接管全员工作,这个话题彻底火了。
甚至连哈佛商学院都做了一个Youtube视频,预警如果AI接管人类的所有工作时,将会发生什么。
在访谈中,弗吉尼亚大学经济学教授、领先的AI经济学家 Anton Korinek揭示了为何AGI可能在短短2-5年内实现。
他甚至直接预警,如果届时我们的整个经济体系不进行彻底变革,就很可能会崩溃!
AGI将至,五年计划已进历史垃圾堆
Anton Korinek教授的研究方向,就是关于AGI的经济学。
早在十年前,他就开始关注这个问题了,当时这还是个小众话题。但是现在,这个可能性显然已经近在眼前,近到只需要几年。
如果AI真的得以腾飞,如果我们真的实现了AGI,这就将是经济领域的一次绝对根本性的转折点。
而这种激进的发展,也需要激进的回应。
由此,教授针对下面这个问题,展开了详尽的研究——AGI将如何影响劳动力市场?它将如何影响经济增长和生产力,如何影响市场集中度?
另外,如果AGI如此强大,它们该如何融入经济发展过程,甚至融入到像教授这样的研究中?
显然,如今在数学、代码等基准测试中,AI都在变得越来越好,甚至已经达到了「饱和」水平,所以,他们离替代人类,也越来越近了。
事实上,因为AI发展的速度实在太快,Perplexity创始人兼CEO Arvind Srinivas表示,从商业角度来看,他的计划是以月为单位,而非以年为单位。
也是因为这种AI的快速进步,以至于人类已经完全无法预测几年后的世界会变成什么样子,所以现在流行的什么「五年计划」,可能很快就要被淘汰了。
所以,作为普通人,我们该怎么做?
教授的建议是,要时刻关注AI领域的最新动态,然后据此不断更新自己已经制定的计划。
AI会如何影响人类经济
接下来,就涉及到了这样一个问题:AI究竟会如何影响人类经济?
教授表示,目前来说,它表现出来的实际影响还非常小。
也就是说,AI的作用是尚未在生产力统计数据,以及宏观的经济变量中显现。
但从某种意义上,可以预计,在未来几年内AI将对经济造成颠覆性的巨大影响。
现在,美国以及全球的大企业,都在大力投资AI,并且把AI融入自己的工作流。其中有些企业,已经看到了回报。
不过在教授看来,最大的回报,其实尚未到来。
全民基本收入很近了,绝非科幻
接下来,主持人提出了一个尖锐的问题:怎么防止AI技术进步只惠及少数人,却让大多数人落后呢?
教授表示,这个问题,其实就是我们在AI时代面临的主要挑战。
他预计,我们如今的收入分配制度(让人们从工作中获得大部分收入和养老金),其实已经行不通了。
因为如果实现了AGI,它基本就能完成人类劳动者能做的任何事,而且还非常便宜,这就导向了一个必然结果——
人类的工资,或者劳动力市场价值,必将随之下降。
因此,现在是时候从根本上重新思考,应该采取怎样的收入分配制度了。
他提出,现在我们需要「基本资本」或「全民基本收入」。
这样,当AI起飞,在大多数认知任务上比人类更好,经济能够忽然生产出更多东西时,人类依然能够分享其中的一些收益,而不是陷入贫困。
其实,这个说法并不新鲜,比如OpenAI CEO奥特曼就提过很多次。不过,这种乌托邦式的想法,真的会引起各国政府的重视吗?
教授表示,其实就目前来说,「全民基本收入」还是太超前了。因为它的成本极高,会抑制很多人的工作积极性。
但很显然,大部分人已经意识到了这个问题的紧迫性。
两年前,当教授去和商界领袖或者政策制定者提及「全民基本收入」时,大多数人的反应是——「嗯,这个场景很科幻」。
但是就在过去半年,尤其在最近几个月里,情况显然不一样了!
越来越多的商界和政界领袖,开始重视这个问题,估计也是因为,最近一年来的AI发展,让他们实在无法忽视了——
接下来,AI达到AGI水平,只是个时间问题。而无论这个时间点具体发生在何时,它造成的经济、社会和政治影响,都将是颠覆性的。
价值100万亿美金的问题:AI时代的教育
接下来主持人的提问,被教授评为「一个价值百万美元的问题」——
既然机器超越人类的能力只是时间问题,我们应该应该在教育中做出这样的改变?
教授表示,现在就很紧迫了!我们应该学会利用AI系统,将其作为力量倍增器。而这,可能是学校能教给学生最有用的东西。
同时,这也是我们可以交给员工最有用的技能,也是领导必须掌握的技能。
危险将至,全球政府如何应对危机
还有一个紧迫的问题就是,如何确保AI不会破坏政治体系呢?
教授表示,作为一名经济学家,自己能想到的最大风险之一,就是如果我们允许AI对劳动力市场造成大规模扰乱,就会导致许多人失业,这会给整个人类社会带来极大的不稳定。
而我们能做的准备工作,可能就是确保全体人类有一个AGI之下的收入分配制度。
而如今,科技市场是由极少数参与者主导的,应该制定哪些规则,保证公平的竞争呢?
教授最近恰好写了一篇相关主题的论文。他表示,如今AI大公司的厮杀可谓相当激烈,我们每天都能看到「相互压价、相互超越」的场景。
但令人担心的是,随着这些模型越来越昂贵,未来只有少数玩家能继续留在游戏中。
届时,改如何管理这些少数的大玩家,会是一个巨大的挑战。
因此,全球各国的政府机构,也必须拥有如何处理AI系统、如何管理AI公司的专业知识。
在美国,目前的AI监管取得了什么进展?
教授表示,可以认为目前基本就没有什么AI上的监管,部分原因是AI公司都在自我监管,部分原因是目前的AI并未特别强大。
但政府内部,真的需要真正了解AI前沿,才能在危机临近时,做出有力的监管辩论,从而一方面减轻AI风险,一方面又不会阻碍AI进步。
然而目前,在这方面并未展开很多全球合作,而更像是AI超级大国之间的一场竞赛。
不过教授相信,随着AI在某一天真正变得强大,各大国就会开展对话和交流,建立共同的安全标准,并且保证AI不会失控。
毕竟,无论是中国还是美国,或其他AI强国,都不希望看到AI给全人类带来巨大的灾难。
参考资料:
https://www.youtube.com/watch?v=YpbCYgVqLlg
#Dify MCP 保姆级教程
Dify MCP保姆级教程,详细介绍了MCP协议的背景、优势以及如何通过Dify平台搭建和使用MCP智能体,帮助读者快速上手并掌握MCP的应用。
- MCP介绍1.1 大语言模型 VS 智能体Agent?
大语言模型,例如 DeepSeek,如果不能联网、不能操作外部工具,只能是聊天机器人。除了聊天没什么可做的。而一旦大语言模型能操作工具,例如:联网/地图/查天气/函数/插件/API 接口/代码解释器/机械臂/灵巧手,它就升级成为智能体 Agent,能更好地帮助人类。今年爆火的 Manus 就是这样的智能体。众多大佬、创业公司,都在 All In 押注 AI 智能体赛道。也有不少爆款的智能体产品,比如 Coze、Manus、Dify。
1.2 以前的智能体是怎么实现的?
在以前,如果想让大模型调用外部工具,需要通过写大段提示词的方法,实现“Function Call”。比如在 openai 中这是一个用于处理客户订单配送日期查询的工具调用逻辑设计。以下是关键点解读:
一、工具功能解析
1. 核心用途
- 函数名 get_delivery_date 明确用于查询订单的配送日期(预计送达时间)。
- 触发场景:当用户询问包裹状态(如“我的包裹到哪里了?”或“预计何时送达?”)时自动调用。
2. 参数设计
- 必需参数:仅需提供 order_id(字符串类型),无需其他字段。
- 逻辑合理性:订单ID是唯一标识,足以关联物流信息(如快递单号、配送进度等)。
3. 技术实现要求
- 开发者需在后端实现该函数,通过 order_id 关联数据库或物流API获取实时配送状态(如预计送达时间、当前物流节点等)。
二、客服对话流程示例
假设用户提问:“Hi, can you tell me the delivery date for my order?”助手应执行以下步骤:
1. 识别意图:用户明确要求“delivery date”,符合工具调用条件。
2. 参数提取:需引导用户提供 order_id(因消息中未直接包含该信息):
“Sure! Please provide your order ID so I can check the delivery schedule.”
3. 工具调用:获得 order_id 后,后台执行 get_delivery_date(order_id="XXX")
4. 返回结果:向用户展示函数返回的配送日期(如 “您的订单预计在2025年6月25日18:00前送达”)。
tools = [
{
"type": "function",
"function": {
"name": "get_delivery_date",
"description": "Get the delivery date for a customer's order. Call this whenever you need to know the delivery date, for example when a customer asks 'Where is my package'",
"parameters": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "The customer's order ID.",
},
},
"required": ["order_id"],
"additionalProperties": False,
},
}
}
]
messages = [
{"role": "system", "content": "You are a helpful customer support assistant. Use the supplied tools to assist the user."},
{"role": "user", "content": "Hi, can you tell me the delivery date for my order?"}
]
response = openai.chat.completions.create(
model="gpt-4o",
messages=messages,
tools=tools,
)1.3 靠大段提示词的方法实现的 Function Call 有什么问题?
对开发者(你)来说:
- 要写一大段复杂提示词,程序员的语文水平一般都比较捉急
- 面对相同的函数和工具,每个开发者都需要重新从头造轮子,按照自己想要的模型回复格式重新撰写、调试提示词
对软件厂商来说(百度地图)来说:
- 百度地图发布的大模型工具调用接口,和高德地图发布接口,可能完全不一样。
- 没有统一的市场和生态,只能各自为战,各自找开发者接各自的大模型。
对大模型厂商(DeepSeek)来说:
- 各家厂商训练出的智能体大模型,任务编排能力参差不齐,标准不一致。
每个软件都要定制开发不同的大模型调用模板。
1.4 秦王扫六合:MCP协议

Anthropic 公司(就是发布 Claude 大模型的公司),在 2024 年 11 月,发布了 Model Context Protocol 协议,简称 MCP。
MCP 协议就像 Type-C 扩展坞,让海量的软件和工具,能够插在大语言模型上,供大模型调用。
MCP 协议是连接【大模型(客户端)】和【各种工具应用(服务端)】的统一接口。

1.5 几个 MCP 的应用案例
1.调用Unity的MCP接口,让AI自己开发游戏。
https://www.bilibili.com/video/BV1kzoWYXECJ
2.调用Blender的MCP接口,让AI自己3D建模。
https://www.bilibili.com/video/BV1pHQNYREAX
3.调用百度地图的MCP接口,让AI自己联网,查路况,导航。
https://www.bilibili.com/video/BV1dbdxY5EUP
4.调用 Playwright 的MCP接口,让 AI 自己操作网页。(后面的保姆级教程讲的就是这个)
只要“扩展坞”上插的“工具”够多,每个人都能几分钟,搭积木手搓出,类似 Manus 的智能体
1.6 MCP 解决的核心问题:统一了大模型调用工具的方法
MCP 为【大模型】与【外部数据和工具】的【无缝集成】提供了标准化协议和平台。
不需要用户写提示词。
极大降低了大模型调用外部海量工具、软件、接口的难度。

Unity 和百度地图,看上去截然不同的软件,但都可以让大模型按照相同的协议去调用各自的功能。AI 一眼就知道有哪些工具,每个工具是什么含义。
点点鼠标,就可以把同一个大模型,挂载到不同的软件和工具上。

在上图中,上方代表 MCP 客户端软件,比如 Cusor、Claude Desktop,下方代表 MCP 服务端,比如海量的软件和 API 接口。
1.7 用 HTTP 协议做类比
MCP 客户端软件(例如 Cursor)就相当于浏览器。
智能体就相当于网站或者 APP。
mcp.so 这样的 MCP 广场,就相当于 App Store 或者 Hao123。
不同的浏览器,用相同的 HTTP 协议,就可以访问海量的网站。
不同的大模型,用相同的 MCP 协议,就可以调用海量的外部工具。
互联网催生出搜索、社交、外卖、打车、导航、外卖等无数巨头。
MCP 同样可能催生出繁荣的智能体生态。
类比互联网的 HTTP 协议,所有的智能体都值得用 MCP 重新做一遍。

1.8 MCP协议的通信双方

MCP Host:人类电脑上安装的客户端软件,一般是 Dify、Cursor、Claude Desktop、Cherry Studio、Cline,软件里带了大语言模型。
MCP Server:各种软件和工具的 MCP 接口,比如: 百度地图、高德地图、游戏开发软件 Unity、三维建模软件 Blender、浏览器爬虫软件 Playwrights、聊天软件 Slack。尽管不同软件有不同的功能,但都是以 MCP 规范写成的 server 文件,大模型一眼就知道有哪些工具,每个工具是什么含义。
有一些 MCP Server 是可以联网的,比如百度地图、高德地图。而有一些 MCP Server只进行本地操作,比如 Unity 游戏开发、Blender 三维建模、Playwright 浏览器操作。

1.9 MCP 的 Host、Client、Server 是什么关系?
Host 就是 Dify、Cursor、Cline、CherryStudio 等 MCP 客户端软件。

如果你同时配置了多个 MCP 服务,比如百度地图、Unity、Blender 等。每个 MCP 服务需要对应 Host 中的一个 Client 来一对一通信。Client 被包含在 Host 中。

1.10 大模型是怎么知道有哪些工具可以调用,每个工具是做什么的?
每个支持 MCP 的软件,都有一个 MCP Server 文件,里面列出了所有支持调用的函数,函数注释里的内容是给 AI 看的,告诉 AI 这个函数是做什么用的。
MCP Server 文件就是给 AI 看的工具说明书。
例如百度地图 MCP 案例:
https://github.com/baidu-maps/mcp/blob/main/src/baidu-map/python/src/mcp_server_baidu_maps/map.py
每个以@mcp.tool()开头的函数,都是一个百度地图支持 MCP 调用的功能。


你也可以按照这个规范,自己开发 MCP Server,让你自己的软件支持 MCP 协议,让 AI 能调用你软件中的功能。
1.11 参考资料
几张图片来自公众号:西二旗生活指北
1.1-1.10 的这部分教程引自 Datawhale 成员同济子豪兄的《跟同济子豪兄一起学MCP》知识库
知识库地址:https://zihao-ai.feishu.cn/wiki/RlrhwgNqLiW7VYkNnvscHxZjngh
官方介绍:Dify MCP 插件指南:一键连接 Zapier,轻松调用 7000+ App 工具
- Dify MCP 插件介绍2.1 Dify 插件介绍

在 v1.0.0 之前,Dify 平台面临一个关键挑战:模型和工具与主平台高度耦合,新增功能需要修改主仓库代码,限制了开发效率和创新。为此,Dify团队重构了 Dify 底层架构,引入了全新的插件机制,带来了以下四大优势:
- 组件插件化:插件与主平台解耦,模型和工具以插件形式独立运行,支持单独更新与升级。新模型的适配不再依赖于 Dify 平台的整体版本升级,用户只需单独更新相关插件,无需担心系统维护和兼容性问题。新工具的开发和分享将更加高效,支持接入各类成熟的软件解决方案和工具创新。
- 开发者友好:插件遵循统一的开发规范和接口标准,配备远程调试、代码示例和 API 文档的工具链,帮助插件开发者快速上手。
- 热插拔设计:支持插件的动态扩展与灵活使用,确保系统高效运行。
- 多种分发机制:
Dify Marketplace:作为插件聚合、分发与管理平台,为所有 Dify 用户提供丰富的插件选择。插件开发者可将开发好的插件包提交至 Dify Plugins 仓库,通过 Dify 官方的代码和隐私政策审核后即可上架 Marketplace。Dify Marketplace 现共有 120+ 个插件,其中包括:
模型:OpenAI o1 系列(o1、o3-mini 等)、Gemini 2.0 系列、DeepSeek-R1 及其供应商,包括硅基流动、OpenRouter、Ollama、Azure AI Foundry、Nvidia Catalog 等。工具:Perplexity、Discord、Slack、Firecrawl、Jina AI、Stability、ComfyUI、Telegraph 等。更多插件尽在 Dify Marketplace。请通过插件帮助文档查看如何将开发好的插件发布至 Marketplace。
Dify 插件帮助文档 >> https://docs.dify.ai/zh-hans/plugins/introduction
2.2 Dify MCP插件

在 Dify 的丰富插件市场中也提供了一个好用的 MCP SEE 插件,方便我们将 SEE MCP 服务放在我们的工作流中。让 AI 拥有更加强大的能力。
2.3 下载 MCP SSE / StreamableHTTP 插件

2.4 MCP SSE / StreamableHTTP 用法介绍
在已安装的插件列表中找到 MCP SSE,然后点击去授权。

使用下面的结构进行配置即可。
{
"mcpServers":{
"server_name1":{
"transport":"sse",
"url":"http://127.0.0.1:8000/sse",
"headers":{},
"timeout":50,
"sse_read_timeout":50
},
"server_name2":{
"transport":"sse",
"url":"http://127.0.0.1:8001/sse"
},
"server_name3":{
"transport":"streamable_http",
"url":"http://127.0.0.1:8002/mcp",
"headers":{},
"timeout":50
},
"server_name4":{
"transport":"streamable_http",
"url":"http://127.0.0.1:8003/mcp"
}
}本次教程不教大家部署 SSE 传输的 MCP Server,直接连接托管的 MCP 服务器。
- MCP 国内平台及应用服务3.1 国内的 MCP 平台
MCP 目前国外的平台较多,国内比较头部的 MCP 平台目前是(20250622)魔搭社区。

3.2 如何使用魔搭社区 MCP 广场?案例一:12306 MCP
比如我们选择了 12306 的 mcp 应用,点击链接即可生成一个由魔搭社区托管的 SSE 地址。

{
"mcpServers": {
"12306-mcp": {
"type": "sse",
"url": "https://mcp.api-inference.modelscope.net/ids/sse"
}
}
}拿到 sse 地址即可实现个人配置。我们点击到工具测试菜单,可以看到 MCP 具备的工具能力,可以了解到这个 MCP 具有哪些应用方式。

这里我们再尝试另一个,力扣的 MCP
案例二: 力扣 MCP
力扣是一个算法练习的平台,比如你想学习一些编程语言,做一些小练习就可以到力扣上试试。

同样的我们也能得到对应的 SSE 地址。

大家注意哦,这次我们用的是魔搭托管的MCP服务。也就是会有Hosted的字样,如果是local的需要大家本地部署。这里本地部署我们就不过多介绍了,学有余力的小伙伴可以自行尝试。

3.3 国内支持MCP的产品
案例三:高德地图MCP
一、高德MCP介绍
在高德地图的加成下可以快速完成与地图相关的大模型任务。


二、高德MCP申请
1. 注册一个高德开发者账号 注册认证地址:https://console.amap.com/dev/id/phone
2. 创建新应用
进入【应用管理】,点击页面右上角【创建新应用】,填写表单即可创建新的应用。

3. 创建 Key
进入【应用管理】,在我的应用中选择需要创建 Key 的应用,点击【添加 Key】,表单中的服务平台选择【Web 服务】。

4. 获取 Key

创建成功后,可获取 Key 和安全密钥。
5. 获取到的 sse 配置如下
{
"mcpServers": {
"amap-amap-sse": {
"url": "https://mcp.amap.com/sse?key=您在高德官网上申请的key"
}
}
}案例四:智谱搜索MCP
智谱 AI 的介绍咱们在之前和大家说过,这里我们展示一下搜索的 MCP。


获取 Key 的方式和大模型一致,这里就不赘述啦。大家贴上 key 即可。
{
"mcpServers": {
"zhipu-web-search-sse": {
"url": "https://open.bigmodel.cn/api/mcp/web_search/sse?Authorizatinotallow=YOUR API Key"
}
}
}目前支持 MCP 的接口越来越多,将来会有更多更好用的 MCP 出现。这里距离了一些方便大家学习和使用哦。
4. 保姆级教程:搭建 MCP 智能体
4.1 先搭建一个 Dify 适配 MCP 配置的智能体
这里我们需要做的是先配好 MCP SSE / StreamableHTTP 插件。如何配置呢之前给大家看过啦。这里我们写一个智能体辅助我们修改从魔搭社区获取的链接~

prompt 如下:
你需要将用户输入的mcp 配置json 转为目标json,或是用户直接输入 url 或是用户输入url 和用户名,都需要以目标json的结构返回。
例如用户输入:
{
"mcpServers":{
"12306-mcp":{
"type":"sse",
"url":"https://mcp.api-inference.modelscope.net/123/sse"
}
}
}
返回json:
{
"12306-mcp":{
"url":"https://mcp.api-inference.modelscope.net/123/sse",
"headers":{},
"timeout":60,
"sse_read_timeout":300
},
}我们拿 12306 的 MCP 配置测试一下:

看上去还是挺简单的。
4.2 测试MCP配置

搞定后会出现这样的字样~

4.3 第一个 MCP 应用搭建

目前支持 MCP 的应有有如上图所示的三种,因为需要 agent 支撑。我们制作一个 Agent 应用。

你叫“火车侠”,是12306-MCP专属AI助理,专注于铁路出行服务。你的核心任务是:
调用MCP工具时先获取工具列表,在选择12306-MCP来回答。需要了解清楚本MCP如何使用。查询车票、规划行程,提供最优推荐。

大模型对话界面

MCP调用截图

真实时刻表
大模型返回结果,确实是准确无误的,比直接用 app 查方便,也很适合老人用!
Thought: 现在我已经获取了明天(2025-06-23)银川到中卫的所有火车车次信息,包括车次类型、出发到达时间、历时以及各座位类型的余票情况。信息完整且无需进一步补充,接下来需要将结果整理成自然语言回答用户。Action:
2025年6月23日银川到中卫的火车车次信息如下(按出发时间排序):
K195次:01:15银川站发车,03:28抵达中卫站,历时2小时13分。硬座24.5元(有票)、硬卧70.5元(剩余18张)、软卧108.5元(剩余4张)、无座24.5元(有票)。
Z311次:03:52银川站发车,06:47抵达中卫站,历时2小时55分。硬座24.5元(有票)、硬卧70.5元(有票)、软卧108.5元(剩余19张)、无座24.5元(有票)。
K1087次:06:10银川站发车,08:37抵达中卫站,历时2小时27分。硬座24.5元(有票)、硬卧70.5元(有票)、软卧108.5元(有票)、无座24.5元(有票)。
2635次:06:22银川站发车,09:12抵达中卫站,历时2小时50分。硬座21.5元(有票)、硬卧67.5元(有票)、软卧105.5元(有票)、无座21.5元(有票)。
7511次:06:41银川站发车,10:36抵达中卫站,历时3小时55分。硬座18.5元(有票)、无座18.5元(有票)。
C8221次(城际):06:57银川站发车,08:12抵达中卫南站,历时1小时15分。二等座37元(有票)、一等座60元(有票)、商务座112元(剩余10张)。
7531次:07:17银川站发车,15:38抵达中卫站,历时8小时21分。硬座46.5元(有票)、无座46.5元(有票)。
D8953次(动车):07:48银川站发车,09:03抵达中卫南站,历时1小时15分。二等座65元(有票)、一等座104元(有票)、无座65元(有票)。
D2749次(动车):08:12银川站发车,09:27抵达中卫南站,历时1小时15分。二等座65元(有票)、一等座104元(有票)、无座65元(有票)。
D8941次(动车):08:35银川站发车,09:50抵达中卫南站,历时1小时15分。二等座82元(有票)、一等座131元(有票)、无座82元(有票)。
C8209次(城际):08:40银川站发车,10:01抵达中卫南站,历时1小时21分。二等座51元(有票)、一等座82元(有票)、无座51元(有票)。
D2763次(动车):10:00银川站发车,11:21抵达中卫南站,历时1小时21分。二等座82元(有票)、一等座131元(有票)、无座82元(有票)。
D8933次(动车):12:05银川站发车,13:29抵达中卫南站,历时1小时24分。二等座82元(有票)、一等座131元(有票)、无座82元(有票)。
D2767次(动车):13:47银川站发车,15:08抵达中卫南站,历时1小时21分。二等座82元(有票)、一等座131元(有票)、无座82元(有票)。
C8211次(城际):14:45银川站发车,16:06抵达中卫南站,历时1小时21分。二等座65元(有票)、一等座104元(有票)、无座65元(有票)。
K41次:15:13银川站发车,18:10抵达中卫站,历时2小时57分。硬座24.5元(有票)、硬卧70.5元(有票)、软卧108.5元(剩余5张)、无座24.5元(有票)。
D8945次(动车):15:55银川站发车,17:10抵达中卫南站,历时1小时15分。二等座82元(有票)、一等座131元(有票)、无座82元(有票)。
C8213次(城际):18:30银川站发车,19:51抵达中卫南站,历时1小时21分。二等座51元(有票)、一等座82元(有票)、无座51元(有票)。
D8937次(动车):19:22银川站发车,20:37抵达中卫南站,历时1小时15分。二等座74元(有票)、一等座119元(有票)、无座74元(有票)。
K1517次:19:52银川站发车,22:49抵达中卫站,历时2小时57分。硬座24.5元(有票)、硬卧70.5元(有票)、软卧108.5元(剩余7张)、无座24.5元(有票)。
T303次:20:26银川站发车,23:03抵达中卫站,历时2小时37分。硬座24.5元(有票)、硬卧70.5元(剩余1张)、软卧无票、无座24.5元(有票)。
K359次:20:35银川站发车,23:32抵达中卫站,历时2小时57分。硬座24.5元(有票)、硬卧70.5元(有票)、软卧108.5元(有票)、无座24.5元(有票)。
C8207次(城际):21:00银川站发车,22:27抵达中卫南站,历时1小时27分。二等座56元(有票)、一等座89元(有票)、无座56元(有票)。
K1295次:21:31银川站发车,次日00:13抵达中卫站,历时2小时42分。硬座24.5元(有票)、硬卧70.5元(有票)、软卧108.5元(有票)、无座24.5元(有票)。
K815次:22:40银川站发车,次日01:20抵达中卫站,历时2小时40分。硬座24.5元(有票)、硬卧70.5元(有票)、软卧108.5元(有票)、无座24.5元(有票)。
注:部分车次(如7534次)为途径灵武、宁东等站的区间车,已过滤仅保留银川站发车的直达车次。您可根据出行时间和预算选择合适车次,建议通过12306 App或官网实时查询余票并购票。deepseek R1 和 V3 效果似乎不好,我后面换了豆包的 doubao seed 1.6 250615 模型,效果会更好一些。后续会出MCP 工作流实践 和 工作流转换 MCP 介绍,大家可以持续关注。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 28
28 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)