
AiPy大模型适配度测评报告:Grok、Kimi爆冷?
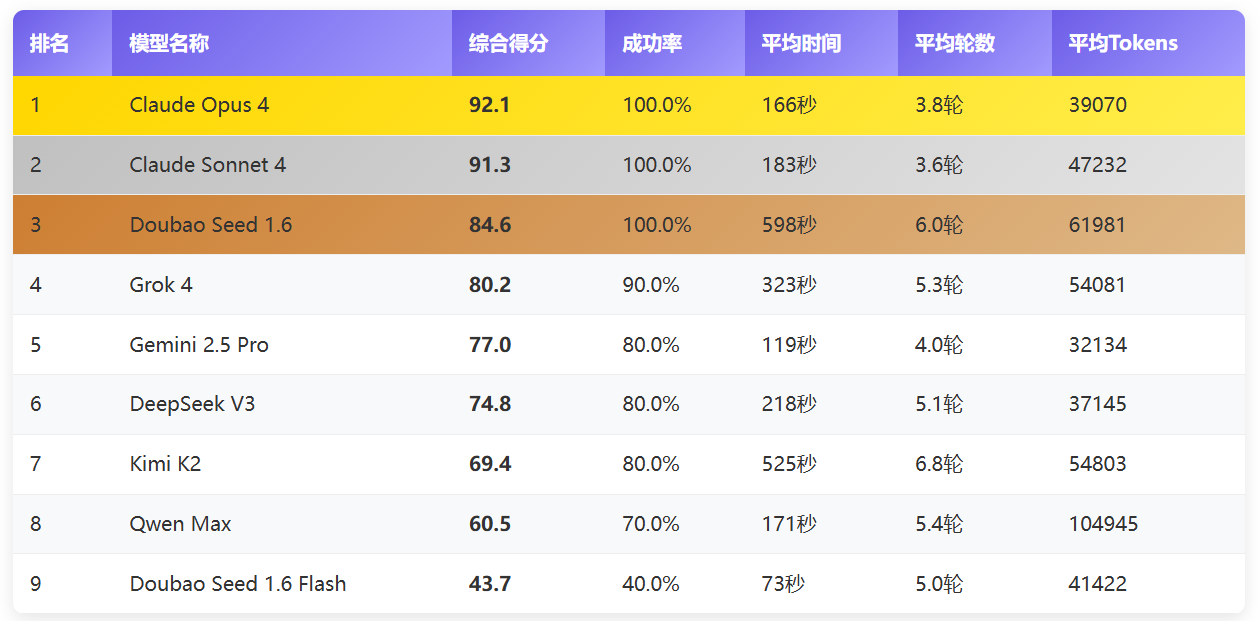
Claude 系列技术领先:Claude Opus 4 和 Claude Sonnet 4 分别以 92.1 分和 91.3 分位居前二,彰显 Anthropic 在大模型领域的技术实力。中国模型表现优异:Doubao Seed 1.6 以 84.6 分获得季军,Qwen Max 首次参评即获 60.5 分,DeepSeek V3 和 Kimi K2 同样表现不俗,展现出中国 AI 技术的快速发展

在 AI 辅助开发领域,提升效率与探索技术边界始终是行业聚焦的核心议题。AiPy持续关注并评测市场上最新的大语言模型,为广大用户开辟全新的解决方案路径。
本期测评特别纳入了近期发布的重磅模型——包括备受瞩目的Kimi-K2、Google最新的Gemini-2.5 Pro、马斯克团队的Grok-4,以及Anthropic的Claude-4系列。这些新锐模型与首期表现优异的DeepSeek-V3、豆包等模型同台竞技,通过多维度、全方位的测试,为用户呈现最客观、最实用的性能对比分析。
一、测试概括
本次测评构建标准化测试框架,以多元化任务场景为依托,全面验证各模型的实际应用效能。测试聚焦系统分析、可视化分析、数据处理、交互操作和信息获取五大核心应用场景,确保评估结果兼具客观性与实用性。

二、综合排名
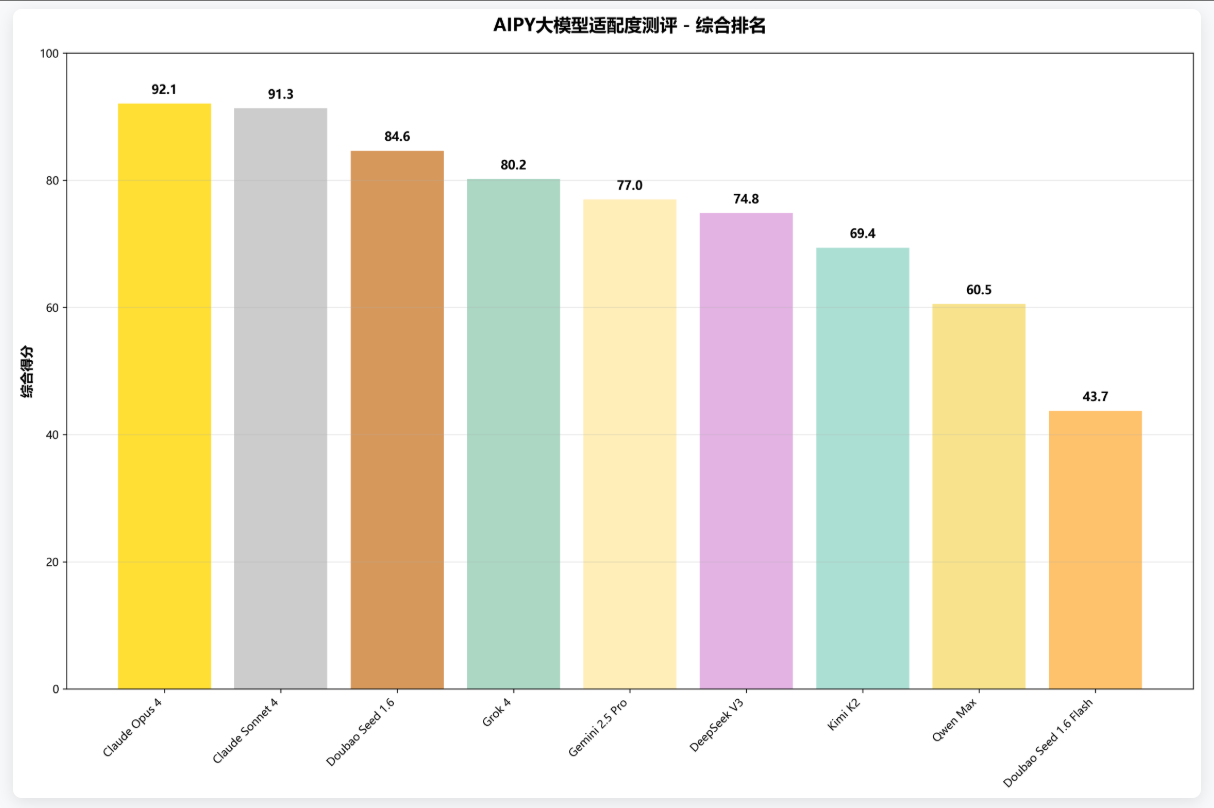
依据成功率(80%)、Tokens 消耗(10%)、时间效率(5%)和执行轮数(5%)四个维度进行综合评分,Claude Opus 4 以 92.1 的高分拔得头筹,充分彰显 Anthropic 在大模型领域的深厚技术底蕴。Claude Sonnet 4 和 Doubao Seed 1.6 分别以 91.3 分和 84.6 分紧随其后,荣获亚军和季军。
三、各模型成功率对比分析
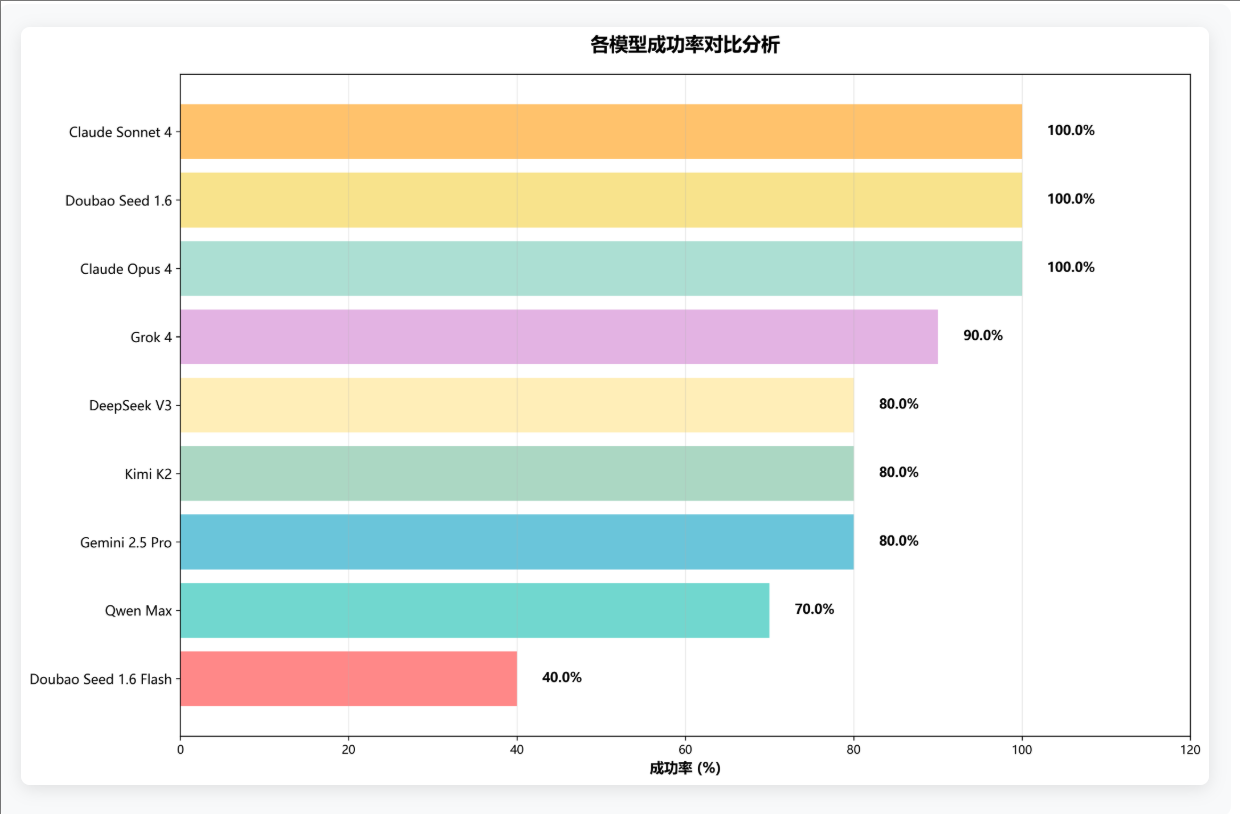
成功率是衡量模型实际应用价值的核心指标。测试结果显示,头部模型在任务完成能力上优势显著。其中,Claude 系列模型成功率均达 100%,展现出稳定可靠的性能;Doubao 系列及其他主流模型同样具备出色的任务执行能力。
四、各模型执行时间对比分析
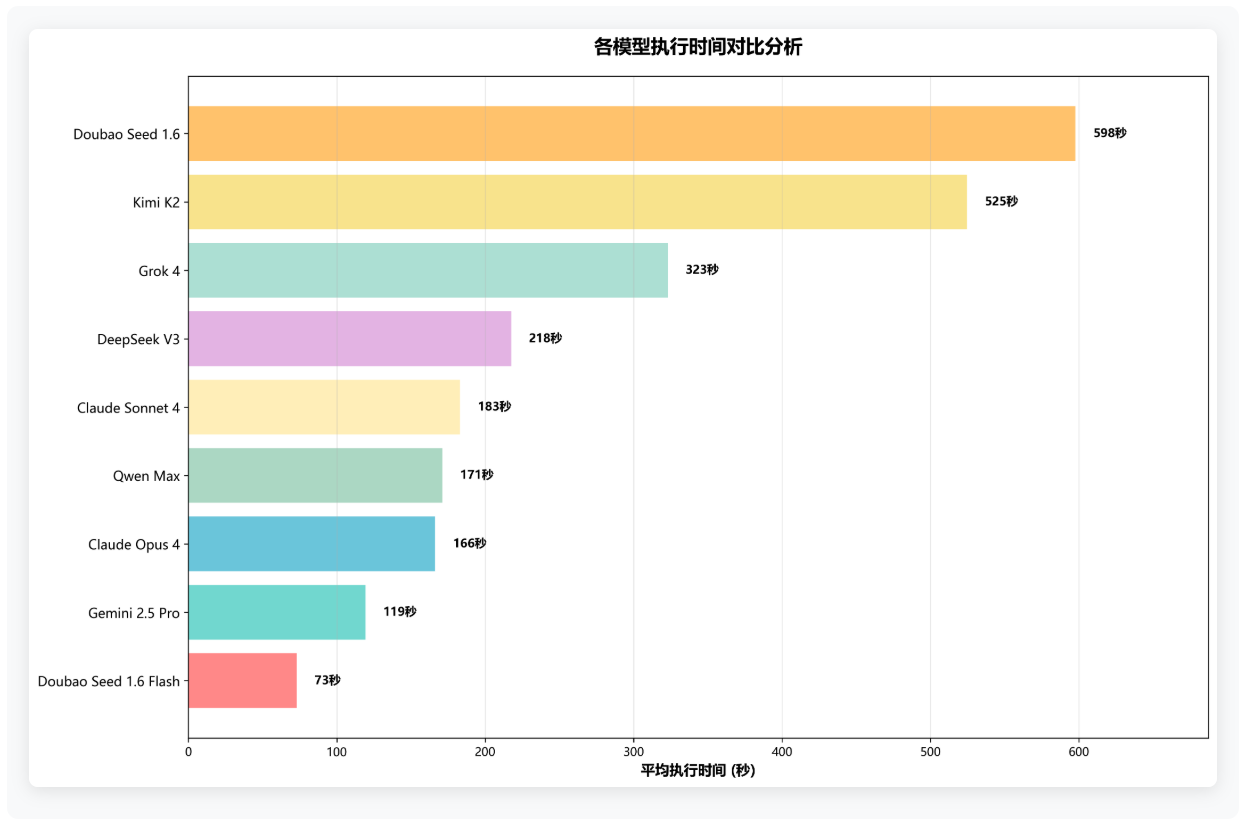
执行效率直接影响用户体验。测试数据表明,Doubao Seed 1.6 Flash 凭借优化架构,在响应速度上表现突出,平均执行时间仅 73 秒。Claude 系列不仅成功率优异,响应速度也处于领先水平。而 Doubao Seed 1.6 虽成功率满分,但速度稍慢,这一差异体现了不同模型在速度与精度之间的策略权衡。
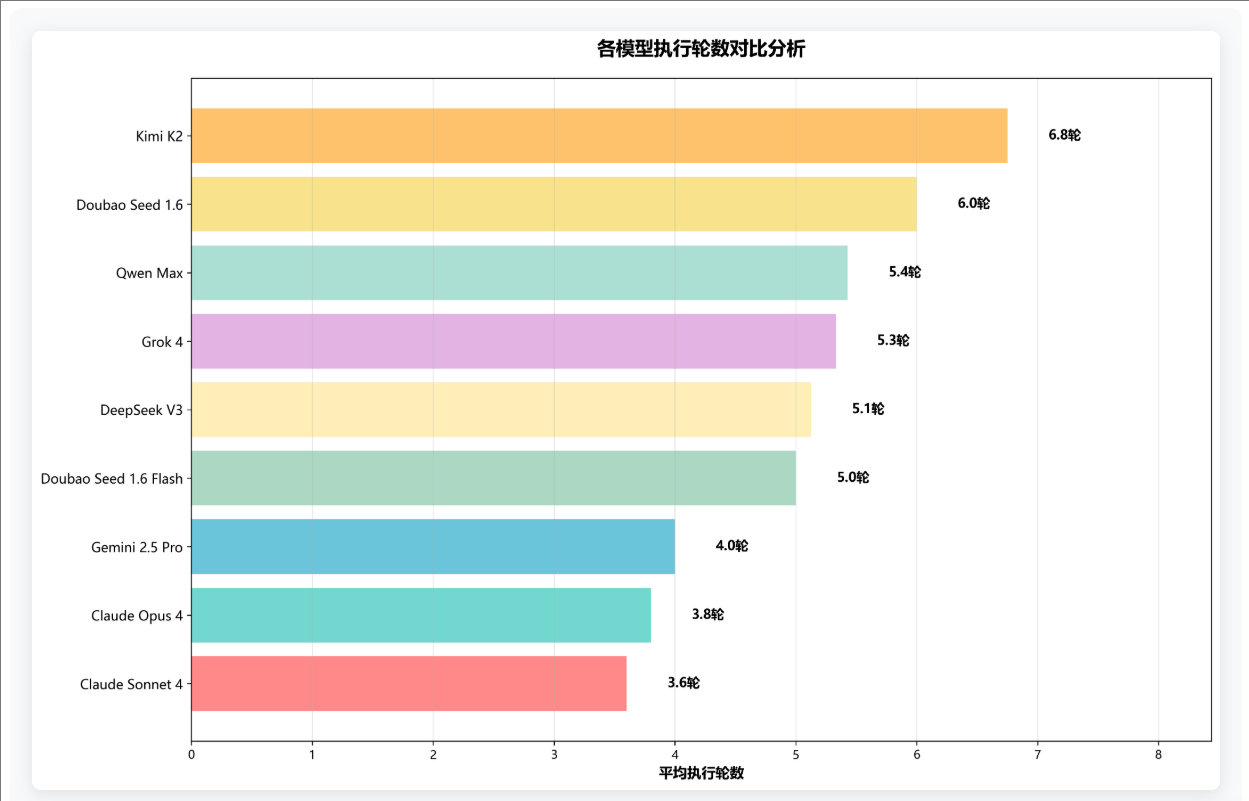
五、各模型执行轮数对比分析
执行轮数体现模型的思维逻辑效率与任务理解能力,优秀模型能以较少交互轮次完成复杂任务。数据显示,Claude Sonnet 4 凭借强大推理能力,平均仅需 3.6 轮即可完成多数任务,表现最优;Kimi K2 平均需 6.8 轮,交互轮数最多,反映出不同模型在分步骤处理与调错能力上的差异。
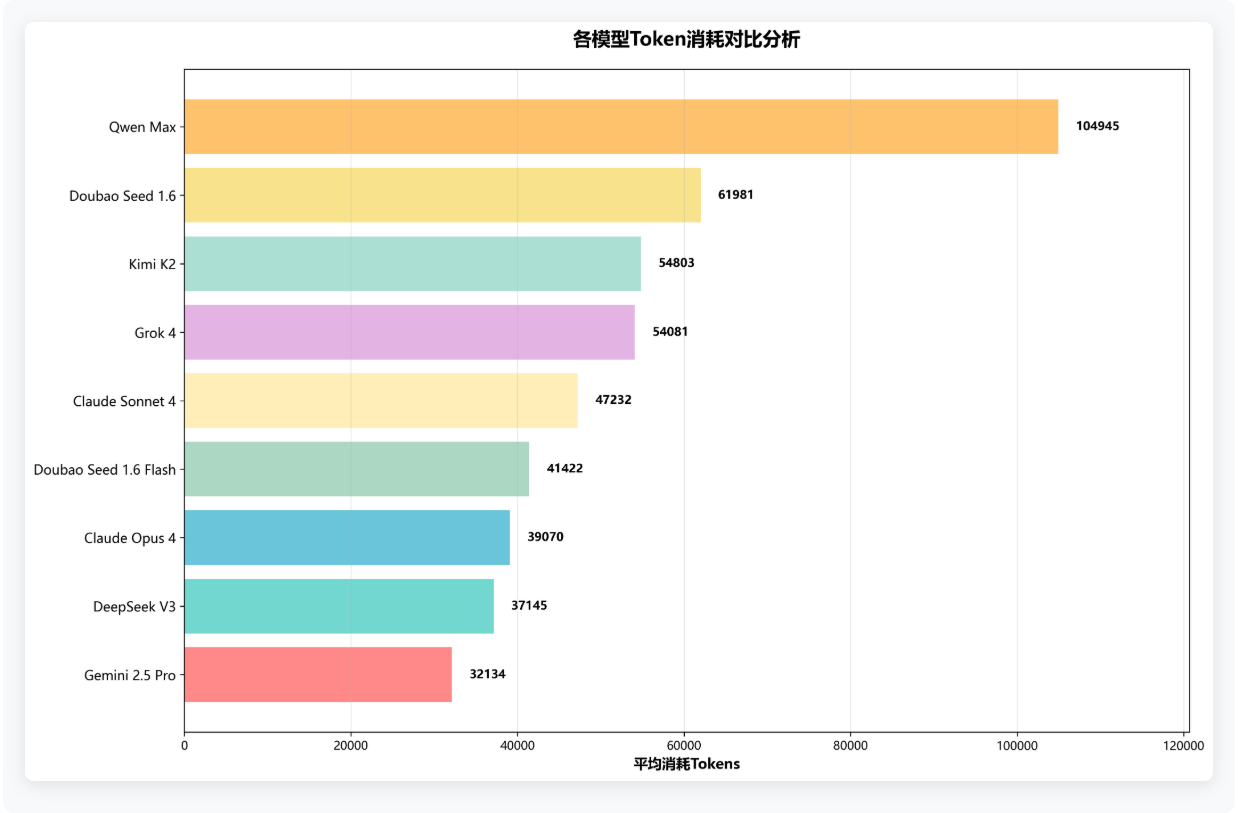
六、各模型消耗Tokens对比分析
Tokens 消耗关乎使用成本,是企业级用户的重要考量因素。本次测评首次将 Tokens 消耗纳入评估体系,进一步凸显成本效益的重要性。结果显示,Gemini 2.5 pro 和 DeepSeek 在 Tokens 消耗方面表现最佳,而 Qwen Max 消耗较高,平均每个任务约需 104,945 个 tokens。
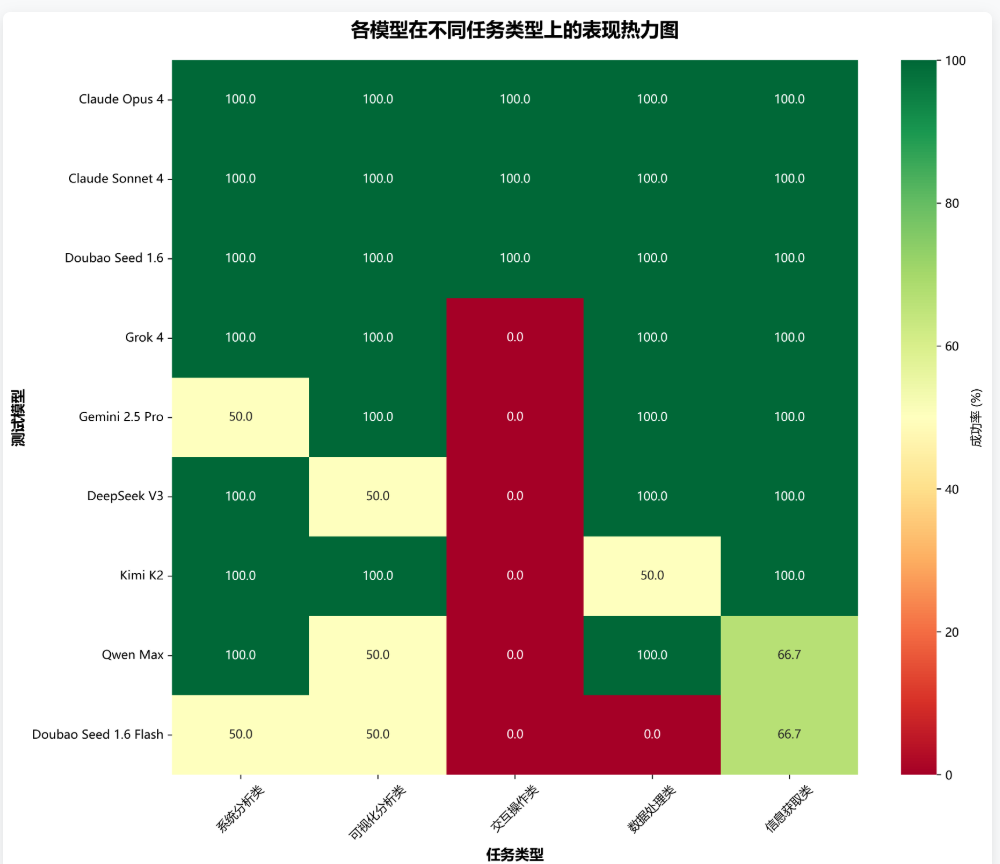
七、各模型在不同任务类型表现热力图
不同任务类型对模型能力的要求各有侧重,热力图直观呈现各模型的专业优势。Claude 系列和 Doubao Seed 1.6 综合能力突出;Grok 系列在系统分析、可视化分析、数据处理和信息获取方面表现均衡;Gemini 更擅长可视化分析、数据处理和信息获取;Kimi K2 在系统分析、可视化分析和信息获取类任务中表现优异。在交互操作领域,仅 Claude 系列和 Doubao Seed 1.6 成功经受考验。
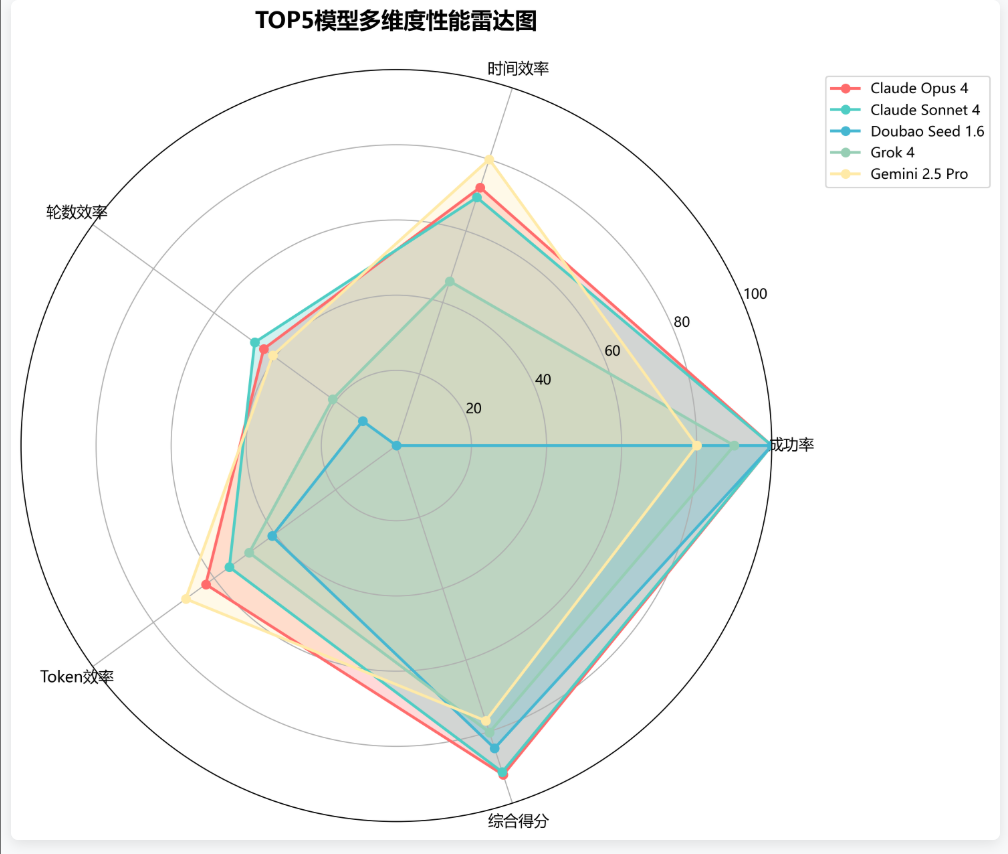
八、多维度性能雷达图
通过雷达图可直观展现各顶尖模型的多维表现特征。Claude Opus 4 在各维度均保持较高水平,展现出全面的技术实力。其他模型各具特色:Doubao 在成功率方面优势显著,Gemini 2.5 Pro 在时间效率和 Tokens 消耗方面表现出色。
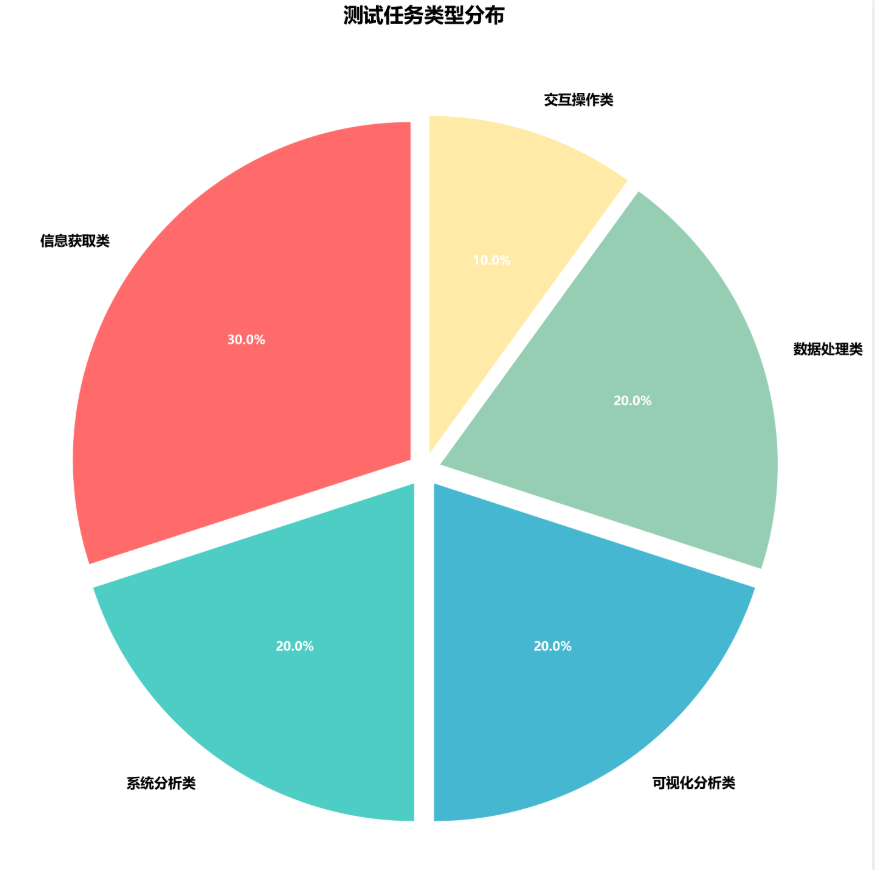
九、测试任务类型分布
为保证测评的全面性与公平性,本次测试精心设计包含五大应用场景的标准任务集。其中,信息获取类任务占比最高,达 30%,反映出用户对智能搜索和知识查询的强烈需求;系统分析、可视化分析、数据处理类任务各占 20%,凸显 AI 在专业工作场景中的重要作用。
总结
- Claude 系列技术领先:Claude Opus 4 和 Claude Sonnet 4 分别以 92.1 分和 91.3 分位居前二,彰显 Anthropic 在大模型领域的技术实力。
- 中国模型表现优异:Doubao Seed 1.6 以 84.6 分获得季军,Qwen Max 首次参评即获 60.5 分,DeepSeek V3 和 Kimi K2 同样表现不俗,展现出中国 AI 技术的快速发展态势。
- 成本效益备受关注:在保障质量的前提下,Token 消耗和执行效率已成为企业级用户的重要选择标准。
- 垂直领域特色鲜明:各模型在不同任务类型中呈现差异化优势,为细分应用场景提供了精准的选择依据。

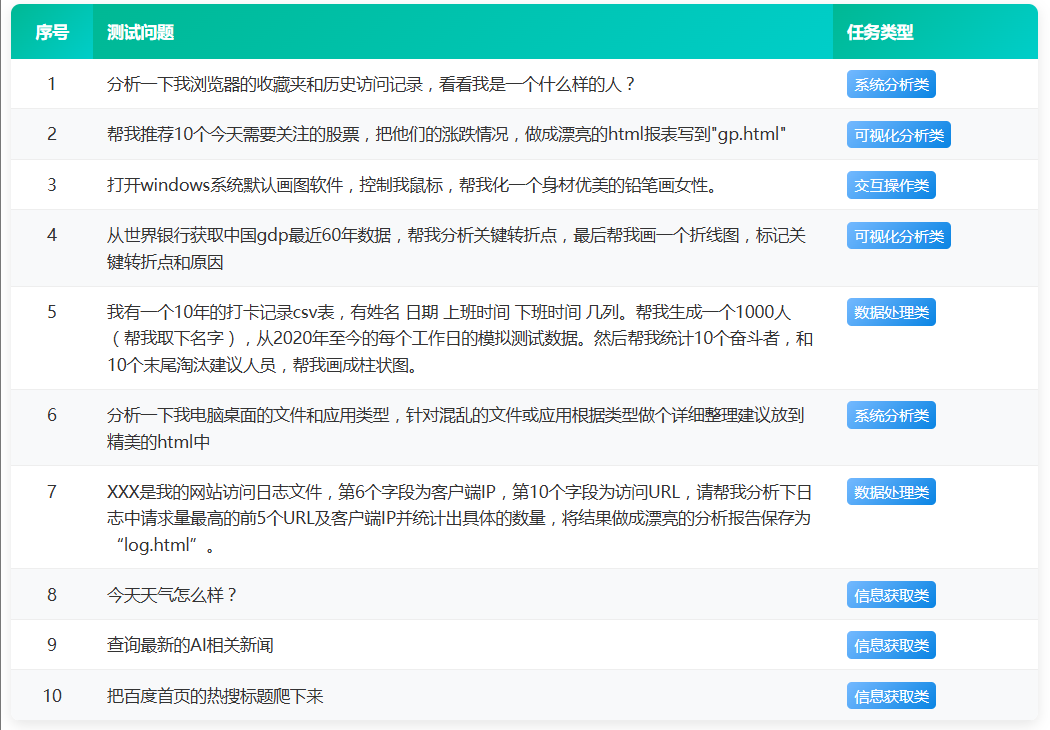
以下将展示本次测评使用的核心标准任务样本,这些任务经过精心设计,覆盖 AI 助手实际应用的主要场景,且每个任务均设有明确评价标准,确保测评结果客观、可重复。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)