
人工智能语言识别技术之核心技术!
隐马尔科夫模型(Hidden Markov Model)的应用是语音识别技术领域的重大突破。首先由Baum提出相关数学推理,然后Labiner等人进行了不断的深入研究,最后卡内基梅隆大学的李开复实现了Sphinx,这是第一个基于隐马尔科夫模型的非特定人大词汇量连续语音识别系统。目前,主流的大词汇量语音识别系统多采用统计模式识别技术。典型的基于统计模式识别方法的语音识别系统由以下5个基本模块构成。(
隐马尔科夫模型(Hidden Markov Model)的应用是语音识别技术领域的重大突破。
首先由Baum提出相关数学推理,然后Labiner等人进行了不断的深入研究,最后卡内基梅隆大学的李开复实现了Sphinx,这是第一个基于隐马尔科夫模型的非特定人大词汇量连续语音识别系统。
目前,主流的大词汇量语音识别系统多采用统计模式识别技术。典型的基于统计模式识别方法的语音识别系统由以下5个基本模块构成。

(1)信号处理及特征提取模块。模块从输入信号中提取可供声学模型处理的特征,利用一些信号处理技术降低环境噪声、信道、说话人等因素的影响。
(2)统计声学模型。典型系统多采用基于一阶隐马尔科夫模型进行建模。
(3)发音词典。发音词典包含系统所能处理的词汇集及其发音。发音词典实际提供了声学模型建模单元与语言模型建模单元间的映射。
(4)语言模型。语言模型对系统所针对的语言进行建模,目前各种系统普遍采用的还是基于统计的N元文法及其变体。
(5)解码器。根据声学、语言模型及词典,寻找能够以最大概率输出该输入信号的词串。我们从数学角度来了解一下上述模块之间的关系。首先,统计语音识别的最基本问题是给定输入信号或特征序列、符号集(词典),求解符号串,使得

通过贝叶斯公式,上式可以改写为:
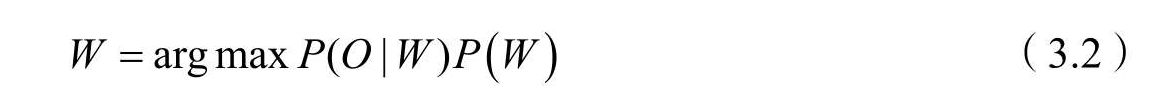
输入串O,P(O)是确定的,省略它并不会对上式的最终结果造成影响。因此,上面的公式可以用来表示一般的语音识别所讨论的问题,所以将它称为语音识别的基本公式。
好啦,这次的分享就到这里,我们下期再见!欢迎在评论区补充和留言。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)