
Flink 流程处理和批处理开发
流处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,然后立刻通过网络传输到下一个节点,由下一个节点继续处理。批处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,并不会立刻通过网络传输到下一个节点,当缓存写满,就持久化到本地硬盘上,当所有数据都被处理完成后,才开始将处理后的数据通过网络传输到下一个节点。Error:(18, 33) coul
流处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,然后立刻通过网络传输到下一个节点,由下一个节点继续处理。
批处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,并不会立刻通过网络传输到下一个节点,当缓存写满,就持久化到本地硬盘上,当所有数据都被处理完成后,才开始将处理后的数据通过网络传输到下一个节点。
Flink的执行引擎采用了一种十分灵活的方式,同时支持了这两种数据传输模型:
- Flink以固定的缓存块为单位进行网络数据传输,用户可以通过设置缓存块超时值指定缓存块的传输时机。如果缓存块的超时值为0,则Flink的数据传输方式类似上文所提到流处理系统的标准模型,此时系统可以获得最低的处理延迟
- 如果缓存块的超时值为无限大,则Flink的数据传输方式类似上文所提到批处理系统的标准模型,此时系统可以获得最高的吞吐量
- 同时缓存块的超时值也可以设置为0到无限大之间的任意值。缓存块的超时阈值越小,则Flink流处理执行引擎的数据处理延迟越低,但吞吐量也会降低,反之亦然。通过调整缓存块的超时阈值,用户可根据需求灵活地权衡系统延迟和吞吐量
一、流处理系统
流处理Streaming
• StreamExecutionEnvironment
• DataStreaming
需求 通过socket实时产生一些单词,使用flink实时接收数据,对指定时间窗口内(例如:2秒)的数据进行聚合 统计,并且把时间窗口内计算的结果打印出来
代码:
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.socketTextStream("192.168.221.131", 9001)
import org.apache.flink.api.scala._
val wordCount = text.flatMap(_.split(" "))//将每一行数据根据空格切分单词
.map((_,1)) //每一个单词转换为tuple2的形式(单词,1)
.keyBy(tup=>tup._1) //官方推荐使用keyselector选择器选择数据
.timeWindow(Time.seconds(2)) //时间窗口为2秒,表示每隔2秒钟计算一次接收到的数
.sum(1)
wordCount.print().setParallelism(1)
//执行程序
env.execute("SocketWindowWord")
}在服务器上输出nc - l 9001,如图所示,然后启动项目
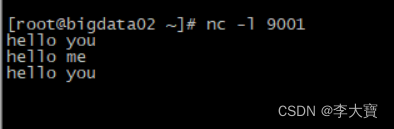
数据hello you hello me hello you
idea控制台可以看到如下效果

二、批处理系统
批处理Streaming
• ExecutionEnvironment
需求:统计指定文件中单词出现的总次数
代码:
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val inputPath="hdfs://192.168.221.131:9000/hello.txt"
val outPath="hdfs://192.168.221.131:9000/out082001"
val text = env.readTextFile(inputPath)
import org.apache.flink.api.scala._
val wordCount= text.flatMap(_.split(" "))
.map((_,1)).groupBy(0).sum(1).setParallelism(1)
wordCount.writeAsCsv(outPath,"\n","") //指定行分割符和字段分割符
env.execute("BatchWordCount")
}结果:
三、异常处理
3.1 flink编译报错
错误信息:Error:(18, 33) could not find implicit value for evidence parameter of type org.apache.flink.api.common.typeinfo.TypeInformation[String]

解决方法:
推荐的做法是在代码中引入以下包:
import org.apache.flink.streaming.api.scala._
但是没有解决问题,最后发现是Scala版本问题。自己的idea的scala版本和pom.xml中的不一致!!!
我的版本为 2.11.12
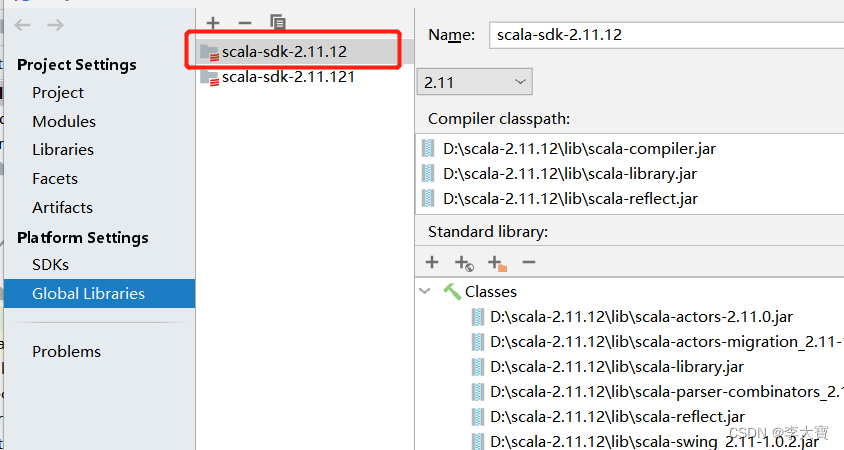
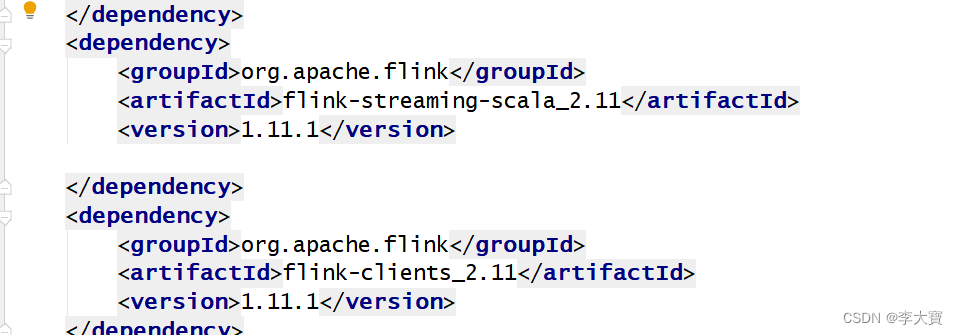
然后看下pom.xml文件,flink对应的scala版本是2.12系列,所以报错。flink对应的scala版本是2.11系列即可解决问题,如下图所示
3.2 启动异常
异常信息:
Exception in thread "main" java.lang.RuntimeException: java.util.concurrent.ExecutionException: org.apache.flink.runtime.client.JobSubmissionException: Failed to submit job.
Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Could not find a file system implementation for scheme 'hdfs'. The scheme is not directly supported by Flink and no Hadoop file system to support this scheme could be loaded. For a full list of supported file systems, please see https://ci.apache.org/projects/flink/flink-docs-stable/ops/filesystems/.
解决方法:在pom文件引入
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
</dependency>
即可解决问题

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)