
【0样本起手做多标签分类任务】2——模型架构
介绍了一种[可插拔]的分类模型结构,仍然是Transformer模型结构的一种简单改进,实现简单,实践操作简单,维护方便。
重申一下前面提过的痛点
- 基于IM(即时通讯)系统的消息分类对并发的要求极高,单独使用大型模型不仅成本巨大,而且响应时间(RT)可能无法满足要求。
- 在零样本启动的情况下,小模型难以迅速达到高精度,影响系统的整体性能。
- 随着需求的不断变化,无论是大模型还是小模型,都需要具备灵活升级和可插拔的能力,以适应新的场景和需求。
前面也提到为了应对这种情况,要使用小模型过滤流量+大模型做判断的 组合技。
本章单独介绍一下,为了满足灵活升级和可插拔的需求,用于过滤流量的小模型大概长什么样
模型架构
适用于文本多标签分类的模型架构,说到底还是在Transformer 模型外面套了两层 MLP(多层感知机)来实现。针对0样本启动的多标签分类任务,我在细节上做了些小改动,而这些改动的目标一致,就是让这个 “Transformer + MLP” 的组合变得可插拔——[可以快速新增或删除某类,所有标签不需要同时训练/更新,不需要共享每个标签的数据集]。
那要实现可插拔,得满足几个要点:
一、有个共享的表征模型底座;
二、对于多标签分类任务,每个标签对应的多个 MLP 能并行运算;
三、不同标签对应的 MLP 参数要互不干扰。
第一个要点很容易实现,共享表征底座就是使用 BGE/Stella 这类在表征相似上已经训练到很高水平模型,这样可以保证基座提供的句子表征足够强。
要实现第二点,方法是让多个标签任务共享一个权重矩阵(W matrix)。为了同时实现第三点,让它们之间不互相影响,我们把权重矩阵的形状设置为 [n_cls, dim_in, dim_out]。这样一来,就可以先针对每个标签单独训练一个使用权重矩阵 [1, dim_in, dim_out] 的模型,等每个标签对应的模型都训练好了,再把它们合并起来就行。
细节方面还有两个小变化:
- 我们采用了时间序列的预测方案,具体操作是先生成 placeholder(占位符),然后利用这个 placeholder 作为 Q(查询向量),而句子的表征序列则作为 K(键向量)和 V(值向量),以此来执行交叉注意力运算(cross-attention)。当经过 cross_attention(交叉注意力)层之后,便会进入前面提到的可合并的 MLP 层。这样,需要训练多少个标签,就生成多少个placeholder。
- 对于每个标签对应的hidden_state,我们单独进行 RMSNorm(根均方归一化)操作。
另外,合并这个动作就是利用变量名列表和位置index做了个定向赋值。(在后面的MergeModule里展示了怎么写)
模型架构图
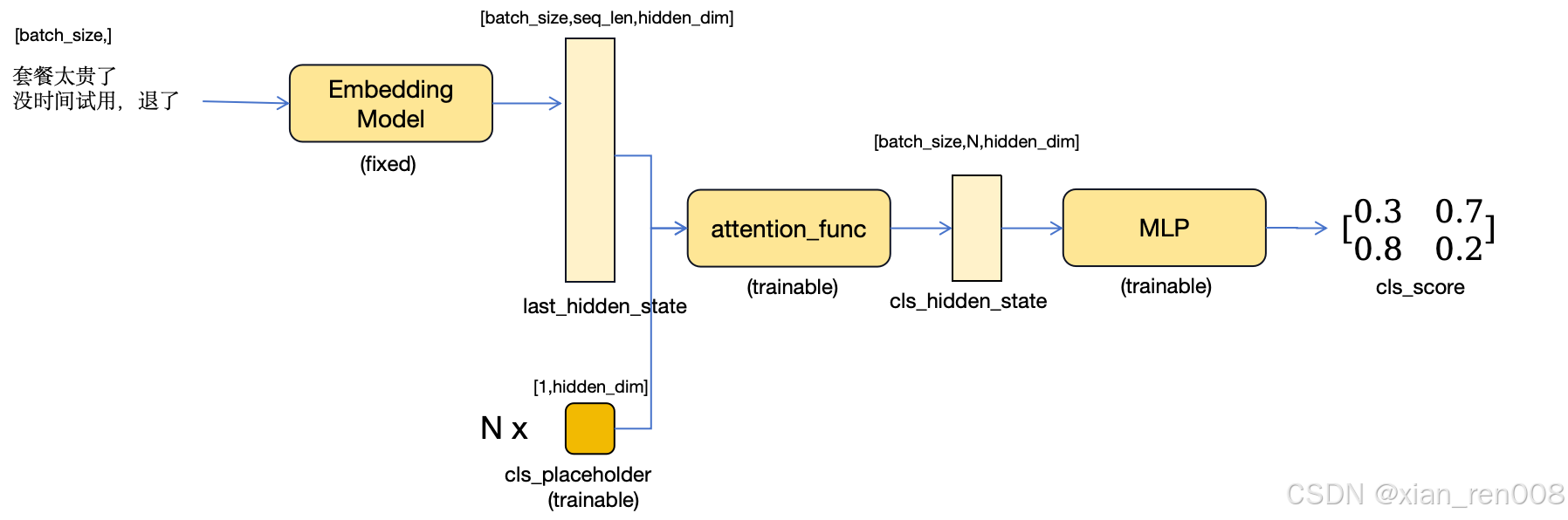
上图展示了一个有两个句子的小batch流入模型之后的Inference过程:
- 句子先通过Embedding Model获得一个没有pooling的句子表征,也就是表征模型的last_hidden_state 作为后面几层的输入, shape 是 [batch_size, seq_len, hidden_dim]
- cls_placeholder 作为Q, 输入的last_hidden_state 作为K和V,进行attention运算,形成一个 shape为[batch_size, n_cls , hidden_dim] 的输出,被称为 cls_hidden_state。(这里n_cls 是指有多少个分类任务,比如图上n_cls=2,就是两个标签)
- cls_hidden_state 经过一个两层的MLP每层中间都执行常规的norm和activation,最后每个样本生成N个标签对应的score。
在训练的过程中,只要每次都只训练一个n_cls=1的模型,后面合并就可以实现各个标签在训练过程相互独立,同时在推理过程中可以并行执行又互不影响。
代码
结构
class MergeModule(nn.Module):
def __init__(self,n_cls,hidden_dim=512):
super().__init__()
self.n_cls=n_cls
self.hidden_dim=hidden_dim
# 这就是cls_placeholder
self.place_holder=nn.ModuleList([nn.Embedding(1,hidden_dim) for x in range(self.n_cls)])
# 这里扩增的维度倍数是3,但具体扩增几倍看任务需要,不用纠结
self.proj1_weight=nn.Parameter(torch.ones(self.n_cls,hidden_dim,hidden_dim*3))
self.proj2_weight=nn.Parameter(torch.ones(self.n_cls,hidden_dim*3,1))
## 下面两个split_rmsnorm对应的是2层MLP中每一层使用的norm
self.split_rmsnorm1=SplitRMSNorm(self.hidden_dim*self.n_cls,self.n_cls)
self.split_rmsnorm2=SplitRMSNorm(self.hidden_dim*2*self.n_cls,self.n_cls)
self._init_params()
MergeModule 的关键步骤
def merge_modules(input_module_lst, output_module):
"""input_module_lst: 分开训练的单标签模型权重组成的list
output_model: 用n_cls=N N是标签数,生成的初始模型。
"""
shape_match_lst = [
"proj1_weight",
"proj2_weight",
"split_rmsnorm1.weight",
"split_rmsnorm2.weight",
]
itm_match_lst = ["place_holder.{num}.weight"]
for i in range(len(input_module_lst)):
for k in shape_match_lst:
output_module.state_dict()[k][i : i + 1] = input_module_lst[i].state_dict()[
k
]
for i in range(len(input_module_lst)):
for k in itm_match_lst:
output_module.state_dict()[k.format(**{"num": i})] = input_module_lst[
i
].state_dict()[k.format(**{"num": 0})]
return output_module

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 35
35 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)