
一个完整的 Double Q-Learning示例(python实现)
外层循环:控制训练的总回合数(episodes)内层循环:控制每个回合内的交互步数(steps)智能体 - 环境交互:执行动作 → 接收反馈 → 更新策略数据预处理多轮实验取平均以减少随机性移动平均平滑曲线,突出趋势视觉编码颜色区分不同算法区间填充表示不确定性可读性优化清晰的标题和轴标签适当的网格线和图例此代码通过科学的可视化设计,为强化学习算法对比提供了直观的分析工具,有助于快速识别算法性能差异
前文,我们已经对Double Q-Learning进行了详解:https://lzm07.blog.csdn.net/article/details/148457172
下面我将提供一个完整的 Double Q-Learning Python 实现,包括环境准备、算法对比和结果可视化等内容。
一、环境准备
首先需要安装必要的依赖库:
pip install gymnasium numpy matplotlib tqdm
以下简要介绍一下相关的库。
(一)Gymnasium
Gymnasium 是 OpenAI Gym 的升级版,是强化学习领域的标准实验平台,提供了大量预定义的环境(如 CartPole、MountainCar、Atari 游戏等)供智能体训练和测试。它通过统一的接口(如 reset ()、step () 方法)规范了环境交互流程,支持离散和连续动作空间,且易于扩展自定义环境。用户可通过 pip install gymnasium 快速安装,其模块化设计使研究人员能专注于算法开发,无需关心环境实现细节,广泛应用于学术研究和工业实践中。
(二)NumPy
NumPy 是 Python 科学计算的基础库,提供高效的多维数组对象(ndarray)和处理这些数组的各种函数。它支持元素级运算、线性代数、傅里叶变换、随机数生成等功能,是 Pandas、SciPy、scikit-learn 等数据科学库的核心依赖。NumPy 数组比 Python 原生列表占用内存更少且运算速度更快,尤其适合大规模数据处理。例如,通过 np.array () 可快速创建数组,使用 np.dot () 执行矩阵乘法,其广播机制能简化不同形状数组间的运算,显著提升代码效率。
(三)Matplotlib
Matplotlib 是 Python 最流行的数据可视化库,能生成高质量的图表、图形和图像。它提供了类似 MATLAB 的绘图接口,支持线图、散点图、柱状图、热图、3D 图等多种可视化类型,并可自定义图表样式(如颜色、字体、标签)。pyplot 是其核心模块,通过简单的命令即可创建复杂图形,例如 plt.plot () 绘制折线图、plt.scatter () 绘制散点图、plt.subplots () 创建多子图布局。Matplotlib 广泛应用于数据分析、机器学习结果展示及学术论文插图生成,其输出可保存为多种格式(如 PNG、SVG、PDF)。
(四)tqdm
tqdm 是 Python 的进度条库,用于在执行耗时操作时提供直观的进度反馈。它支持循环、迭代器、生成器等多种场景,通过简单包装可实时显示任务完成百分比、预计剩余时间、处理速度等信息。例如,在 for 循环外包裹 tqdm () 即可自动生成进度条(如 for i in tqdm (range (1000))),还可与 Jupyter Notebook 集成显示美观的 HTML 进度条。tqdm 适用于数据加载、模型训练、批量处理等场景,能帮助用户监控程序运行状态,预估执行时间,提升开发体验。
(五)导入必要的库
以下是完整实现所需的库:
import gymnasium as gym
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import seaborn as sns
import pandas as pd
from collections import defaultdict
import random
import os
# 设置随机种子以确保结果可复现
def set_seeds(seed=42):
os.environ['PYTHONHASHSEED'] = str(seed)
random.seed(seed)
np.random.seed(seed)
set_seeds()
二、Q-Learning 和 Double Q-Learning 实现
(一)Q-Learning 算法实现
基于值函数的强化学习算法之Q-Learning详解:基于值函数的强化学习算法之Q-Learning详解_基于价值的强化学习算法-CSDN博客
下面是标准 Q-Learning 算法的实现:
这段代码实现了 Q-Learning 算法的核心逻辑,是强化学习中的经典无模型算法。
class QLearningAgent:
def __init__(self, state_size, action_size, learning_rate=0.1, discount_factor=0.99,
epsilon=1.0, epsilon_min=0.01, epsilon_decay=0.995):
self.state_size = state_size
self.action_size = action_size
self.learning_rate = learning_rate
self.discount_factor = discount_factor
self.epsilon = epsilon
self.epsilon_min = epsilon_min
self.epsilon_decay = epsilon_decay
# 初始化Q表
self.q_table = np.zeros((state_size, action_size))
def act(self, state):
# epsilon-贪婪策略选择动作
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
else:
return np.argmax(self.q_table[state, :])
def update(self, state, action, reward, next_state, done):
# Q-Learning更新规则
if done:
target = reward
else:
target = reward + self.discount_factor * np.max(self.q_table[next_state, :])
# 更新Q表
self.q_table[state, action] += self.learning_rate * (target - self.q_table[state, action])
# 衰减epsilon
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
def get_q_table(self):
return self.q_table
以下是对其功能和实现细节的详细解析:
1.类结构与初始化
-
参数配置:
state_size和action_size:定义环境状态和动作的维度,决定 Q 表的形状learning_rate(α):控制新经验覆盖旧经验的程度,过大易振荡,过小收敛慢discount_factor(γ):未来奖励的折现率,反映智能体对远期回报的重视程度epsilon相关参数:控制 ε- 贪婪策略的探索率及其衰减过程
-
Q 表初始化:
self.q_table = np.zeros((state_size, action_size))使用全零矩阵初始化 Q 表,适用于状态和动作空间均为离散且维度有限的环境
2.核心方法解析
(1)动作选择策略(ε- 贪婪)
def act(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size) # 探索:随机选择动作
else:
return np.argmax(self.q_table[state, :]) # 利用:选择Q值最大的动作
- 以 ε 概率随机探索,(1-ε) 概率执行当前最优动作
- 探索率 ε 随训练进行由初始值 1.0 逐步衰减至最小值 0.01
(2)Q 表更新机制
def update(self, state, action, reward, next_state, done):
if done:
target = reward # 终止状态的目标Q值仅为即时奖励
else:
target = reward + self.discount_factor * np.max(self.q_table[next_state, :])
self.q_table[state, action] += self.learning_rate * (target - self.q_table[state, action])
- Q-Learning 的贝尔曼更新方程:
Q(s,a) ← Q(s,a) + α[r + γmaxQ(s',a') - Q(s,a)] - 过估计风险:直接使用 max 操作选择下一状态动作,可能导致 Q 值系统性高估,尤其在奖励存在噪声时
(3)探索率衰减
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
- 采用指数衰减策略,每次更新后 ε = ε × 0.995
- 平衡了初始阶段的充分探索与后期的精确利用
3.算法特性分析
- 离线策略(Off-policy):学习的是最优策略(maxQ),而执行的是 ε- 贪婪策略
- 收敛条件:在状态 - 动作空间有限、学习率足够小且所有状态 - 动作对被无限次访问的条件下,可收敛到最优 Q*
- 适用场景:离散状态空间(如网格世界、Atari 游戏),对连续状态需结合函数近似(如神经网络)
4.潜在改进方向
- Double Q-Learning:通过双 Q 表分解动作选择与评估,缓解过估计问题
- 优先经验回放:按 TD 误差优先级采样历史经验,提高样本利用效率
- ε 衰减策略优化:采用分段衰减或基于训练进度的自适应衰减
(二)Double Q-Learning 算法实现
下面是 Double Q-Learning 算法的实现:
这段代码实现了 Double Q-Learning 算法,是 Q-Learning 的改进版本,主要通过解耦动作选择和动作评估来缓解 Q 值过估计问题。
class DoubleQLearningAgent:
def __init__(self, state_size, action_size, learning_rate=0.1, discount_factor=0.99,
epsilon=1.0, epsilon_min=0.01, epsilon_decay=0.995):
self.state_size = state_size
self.action_size = action_size
self.learning_rate = learning_rate
self.discount_factor = discount_factor
self.epsilon = epsilon
self.epsilon_min = epsilon_min
self.epsilon_decay = epsilon_decay
# 初始化两个Q表
self.q_table_a = np.zeros((state_size, action_size))
self.q_table_b = np.zeros((state_size, action_size))
def act(self, state):
# epsilon-贪婪策略选择动作
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
else:
# 使用两个Q表的平均值来选择动作
q_values = self.q_table_a[state, :] + self.q_table_b[state, :]
return np.argmax(q_values)
def update(self, state, action, reward, next_state, done):
# Double Q-Learning更新规则
if np.random.random() < 0.5:
# 更新Q表A
best_action = np.argmax(self.q_table_a[next_state, :])
if done:
target = reward
else:
target = reward + self.discount_factor * self.q_table_b[next_state, best_action]
self.q_table_a[state, action] += self.learning_rate * (target - self.q_table_a[state, action])
else:
# 更新Q表B
best_action = np.argmax(self.q_table_b[next_state, :])
if done:
target = reward
else:
target = reward + self.discount_factor * self.q_table_a[next_state, best_action]
self.q_table_b[state, action] += self.learning_rate * (target - self.q_table_b[state, action])
# 衰减epsilon
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
def get_q_table(self):
# 返回两个Q表的平均值
return (self.q_table_a + self.q_table_b) / 2
以下是对其核心设计和实现细节的解析:
1.算法核心思想
Double Q-Learning 的核心在于使用两个独立的 Q 表(Q₁和 Q₂)来分解最大化偏差问题:
- Q-Learning 的过估计:标准 Q-Learning 在计算目标值时使用
max Q(s',a'),这种 "选择 - 评估" 的自引导过程容易导致 Q 值系统性高估 - Double Q-Learning 的解决方案:
- 以 50% 概率选择更新 Q₁或 Q₂
- 更新 Q₁时,用 Q₁选择动作,用 Q₂评估该动作的价值
- 更新 Q₂时,用 Q₂选择动作,用 Q₁评估该动作的价值
2.类结构与初始化
self.q_table_a = np.zeros((state_size, action_size))
self.q_table_b = np.zeros((state_size, action_size))
- 维护两个独立的 Q 表,初始化为全零矩阵
- 其余参数(学习率、折扣因子、ε- 贪婪策略)与 Q-Learning 一致
3.关键方法解析
(1)动作选择策略
def act(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
else:
q_values = self.q_table_a[state, :] + self.q_table_b[state, :]
return np.argmax(q_values)
- 探索阶段:与 Q-Learning 相同,以 ε 概率随机选择动作
- 利用阶段:综合两个 Q 表的估计值选择动作,降低了单一 Q 表过估计的影响
(2)双 Q 表更新机制
def update(self, state, action, reward, next_state, done):
if np.random.random() < 0.5:
# 更新Q表A:用A选择动作,用B评估价值
best_action = np.argmax(self.q_table_a[next_state, :])
target = reward + self.discount_factor * self.q_table_b[next_state, best_action]
self.q_table_a[state, action] += ...
else:
# 更新Q表B:用B选择动作,用A评估价值
best_action = np.argmax(self.q_table_b[next_state, :])
target = reward + self.discount_factor * self.q_table_a[next_state, best_action]
self.q_table_b[state, action] += ...
- 更新公式:
Q₁(s,a) ← Q₁(s,a) + α[r + γQ₂(s',argmaxQ₁(s',a')) - Q₁(s,a)] Q₂(s,a) ← Q₂(s,a) + α[r + γQ₁(s',argmaxQ₂(s',a')) - Q₂(s,a)] - 随机性:每次更新随机选择更新 Q₁或 Q₂,保证两个 Q 表的独立性
(3)Q 表融合与输出
def get_q_table(self):
return (self.q_table_a + self.q_table_b) / 2
- 返回两个 Q 表的平均值作为最终估计
- 这种融合方式平衡了两个 Q 表的学习结果,进一步提高了稳定性
4.与 Q-Learning 的关键差异
| 特性 | Q-Learning | Double Q-Learning |
|---|---|---|
| Q 值更新 | 单 Q 表,max 操作同时用于选择和评估 | 双 Q 表,分解选择和评估过程 |
| 过估计问题 | 存在显著过估计 | 大幅减轻过估计 |
| 计算复杂度 | 低(单表更新) | 高(双表更新) |
| 收敛性 | 在某些情况下收敛到次优解 | 更有可能收敛到接近真实值函数 |
5.适用场景与局限性
-
优势场景:
- 奖励存在噪声的环境(如 Atari 游戏)
- 函数近似误差较大的情况(如深度强化学习)
- 需要高稳定性和精确 Q 值估计的任务
-
潜在不足:
- 双倍内存开销(维护两个 Q 表)
- 训练速度较慢(每次更新两个表)
- 对确定性环境提升可能有限
此实现完整保留了 Double Q-Learning 的核心机制,通过简单修改即可应用于各类离散状态 - 动作空间的强化学习任务。
三、训练与评估
(一)训练函数实现
下面是训练智能体的函数:
这段代码实现了强化学习智能体的通用训练框架,适用于各类基于价值迭代的算法(如 Q-Learning、Double Q-Learning)。
def train_agent(agent, env, num_episodes=500, max_steps_per_episode=1000):
total_rewards = []
episode_lengths = []
for episode in tqdm(range(num_episodes), desc="Training"):
state, _ = env.reset()
total_reward = 0
done = False
step = 0
while not done and step < max_steps_per_episode:
action = agent.act(state)
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
agent.update(state, action, reward, next_state, done)
state = next_state
total_reward += reward
step += 1
total_rewards.append(total_reward)
episode_lengths.append(step)
return total_rewards, episode_lengths
以下是对其核心逻辑和设计模式的详细解析:
1.训练流程概述
函数采用标准的 "episode-step" 循环结构:
- 外层循环:控制训练的总回合数(episodes)
- 内层循环:控制每个回合内的交互步数(steps)
- 智能体 - 环境交互:执行动作 → 接收反馈 → 更新策略
2.核心组件与数据结构
total_rewards = [] # 记录每个episode的累计奖励
episode_lengths = [] # 记录每个episode的持续步数
- 这两个列表用于收集训练过程数据,后续可用于评估学习曲线和算法稳定性
3.单回合训练逻辑
state, _ = env.reset() # 初始化环境,获取初始状态
total_reward = 0
done = False
step = 0
while not done and step < max_steps_per_episode:
action = agent.act(state) # 智能体根据当前状态选择动作
next_state, reward, terminated, truncated, _ = env.step(action) # 执行动作,获取环境反馈
done = terminated or truncated # 判断是否终止(任务完成或超时)
agent.update(state, action, reward, next_state, done) # 智能体更新内部策略
state = next_state # 状态转移
total_reward += reward # 累计奖励
step += 1 # 步数计数
- 环境接口:使用 Gymnasium 标准接口,支持
reset()和step()方法 - 终止条件:结合
terminated(任务成功 / 失败)和truncated(超时 / 异常终止) - 奖励累计:直接累加即时奖励,未考虑折扣因子(已在智能体内部处理)
4.训练监控与进度反馈
for episode in tqdm(range(num_episodes), desc="Training"):
# ... 训练逻辑 ...
- 使用
tqdm库提供动态进度条,显示训练进度、估计剩余时间等信息 - 这对长时间训练任务尤为重要,可直观了解训练状态
5.设计模式分析
-
模块化设计:
- 智能体与环境解耦,通过统一接口交互
- 支持不同智能体(如 Q-Learning、Double Q-Learning)无缝切换
-
数据收集机制:
- 同时记录累计奖励和 episode 长度,便于多维度评估算法性能
- 可扩展添加其他指标(如 Q 值分布、探索率变化)
-
安全机制:
设置单 episode 最大步数限制,防止陷入无限循环(如智能体学到不良策略)step < max_steps_per_episode
6.潜在优化方向
-
早停机制:
if np.mean(total_rewards[-10:]) > reward_threshold: break # 当连续多个episode达到目标性能时提前结束训练 -
中间评估:
if episode % evaluation_freq == 0: evaluate_agent(agent, env, num_episodes=5) # 定期评估当前策略 -
数据增强:
episode_data.append((state, action, reward, next_state, done)) # 保存轨迹数据用于回放
此训练框架简洁高效,完整实现了强化学习的基本训练流程,通过组合不同的智能体和环境,可快速验证各种强化学习算法的性能。
(二)超参数设置
设置训练所需的超参数:
# 环境参数
env_name = 'FrozenLake-v1' # 使用FrozenLake环境进行测试
env = gym.make(env_name, is_slippery=False) # 非滑动版本便于观察差异
state_size = env.observation_space.n
action_size = env.action_space.n
# 训练参数
num_episodes = 500
max_steps_per_episode = 100
learning_rate = 0.1
discount_factor = 0.99
epsilon = 1.0
epsilon_min = 0.01
epsilon_decay = 0.995
# 重复实验次数
num_runs = 10
四、对比实验
(一)运行对比实验
这段代码实现了 Q-Learning 与 Double Q-Learning 的对比实验框架,通过多次独立运行获取统计上可靠的性能差异。
# 存储多次实验结果
q_learning_rewards = []
double_q_learning_rewards = []
for run in range(num_runs):
print(f"\nRun {run+1}/{num_runs}")
# 重置环境和随机种子
set_seeds(run)
env = gym.make(env_name, is_slippery=False)
# 训练Q-Learning智能体
print("Training Q-Learning agent...")
q_agent = QLearningAgent(state_size, action_size, learning_rate, discount_factor,
epsilon, epsilon_min, epsilon_decay)
q_rewards, _ = train_agent(q_agent, env, num_episodes, max_steps_per_episode)
q_learning_rewards.append(q_rewards)
# 训练Double Q-Learning智能体
print("Training Double Q-Learning agent...")
dq_agent = DoubleQLearningAgent(state_size, action_size, learning_rate, discount_factor,
epsilon, epsilon_min, epsilon_decay)
dq_rewards, _ = train_agent(dq_agent, env, num_episodes, max_steps_per_episode)
double_q_learning_rewards.append(dq_rewards)
# 转换为numpy数组以便计算统计量
q_learning_rewards = np.array(q_learning_rewards)
double_q_learning_rewards = np.array(double_q_learning_rewards)
以下是对其核心设计和实现细节的解析:
1.实验设计核心思想
- 独立重复实验:通过设置不同随机种子(
set_seeds(run))运行多次实验,消除随机因素影响 - 控制变量法:除算法实现不同外,其他参数(环境、超参数)保持一致
- 统计分析基础:收集多组实验数据,后续可计算均值、标准差等统计量
2.代码结构与执行流程
q_learning_rewards = [] # 存储Q-Learning每次实验的奖励序列
double_q_learning_rewards = [] # 存储Double Q-Learning每次实验的奖励序列
for run in range(num_runs): # 重复实验num_runs次
# 1. 环境初始化与随机种子设置
set_seeds(run) # 确保每次实验的随机性可复现
env = gym.make(env_name, is_slippery=False) # 创建确定性环境(非滑动版本)
# 2. 训练Q-Learning智能体
q_agent = QLearningAgent(...)
q_rewards, _ = train_agent(q_agent, env, num_episodes, max_steps_per_episode)
q_learning_rewards.append(q_rewards)
# 3. 训练Double Q-Learning智能体
dq_agent = DoubleQLearningAgent(...)
dq_rewards, _ = train_agent(dq_agent, env, num_episodes, max_steps_per_episode)
double_q_learning_rewards.append(dq_rewards)
# 4. 转换为numpy数组便于后续分析
q_learning_rewards = np.array(q_learning_rewards) # 形状: [num_runs, num_episodes]
double_q_learning_rewards = np.array(double_q_learning_rewards)
3.关键设计细节
-
随机种子管理:
def set_seeds(seed=42): os.environ['PYTHONHASHSEED'] = str(seed) random.seed(seed) np.random.seed(seed)- 确保每次实验的环境初始化、动作选择等随机过程可复现
- 不同 run 使用不同种子(
seed=run),保证实验独立性
-
环境设置:
env = gym.make(env_name, is_slippery=False)- 使用 FrozenLake 的非滑动版本(确定性环境)
- 便于清晰对比两种算法在无噪声环境下的基础性能差异
-
数据结构:
- 最终数据形状:
[num_runs, num_episodes] - 每行代表一次实验,每列代表一个 episode 的累计奖励
- 最终数据形状:
4.实验控制与变量分析
| 控制变量 | 说明 |
|---|---|
| 环境参数 | 相同的 state/action 空间 |
| 超参数设置 | 相同的学习率、折扣因子等 |
| 训练轮数 | 相同的 num_episodes |
| 随机初始化条件 | 通过种子控制保证一致性 |
变量说明
| 变化变量 | 说明 |
|---|---|
| 算法实现 | Q-Learning vs Double Q-Learning |
| 随机种子 | 不同 run 使用不同种子 |
5.后续分析可能性
-
学习曲线对比:
plt.plot(np.mean(q_learning_rewards, axis=0)) # Q-Learning平均奖励曲线 plt.plot(np.mean(double_q_learning_rewards, axis=0)) # Double Q平均奖励曲线 -
统计显著性检验:
from scipy import stats stats.ttest_ind(q_learning_rewards[:,-100:].flatten(), # 最后100个episode的奖励 double_q_learning_rewards[:,-100:].flatten()) -
稳定性分析:
plt.errorbar(x=episodes, y=np.mean(q_learning_rewards, axis=0), yerr=np.std(q_learning_rewards, axis=0), label='Q-Learning') # 带标准差的误差线图
6.实验设计的优缺点
(1)优点:
- 严格控制变量,确保对比公平性
- 多次重复实验,结果具有统计意义
- 模块化设计,易于扩展其他算法对比
(2)潜在改进:
- 增加随机环境测试(
is_slippery=True) - 记录训练时间对比(Double Q 计算开销更高)
- 保存中间 Q 表用于分析收敛过程
- 添加不同难度环境的对比实验
此代码框架为强化学习算法对比提供了科学严谨的实验基础,通过收集多组独立实验数据,可有效评估算法性能差异。
五、结果可视化
(一)平均奖励对比图
这段代码实现了 Q-Learning 与 Double Q-Learning 的学习曲线可视化对比,通过移动平均和置信区间直观展示两种算法的性能差异。
def plot_rewards_comparison(q_rewards, dq_rewards, window=10):
plt.figure(figsize=(12, 6))
# 计算移动平均奖励
q_mean = np.mean(q_rewards, axis=0)
q_std = np.std(q_rewards, axis=0)
dq_mean = np.mean(dq_rewards, axis=0)
dq_std = np.std(dq_rewards, axis=0)
# 计算移动平均
q_mean_smooth = pd.Series(q_mean).rolling(window).mean()
q_std_smooth = pd.Series(q_std).rolling(window).mean()
dq_mean_smooth = pd.Series(dq_mean).rolling(window).mean()
dq_std_smooth = pd.Series(dq_std).rolling(window).mean()
# 绘制平均奖励曲线
plt.plot(q_mean_smooth, label='Q-Learning', color='blue')
plt.fill_between(range(len(q_mean_smooth)),
q_mean_smooth - q_std_smooth,
q_mean_smooth + q_std_smooth,
color='blue', alpha=0.2)
plt.plot(dq_mean_smooth, label='Double Q-Learning', color='red')
plt.fill_between(range(len(dq_mean_smooth)),
dq_mean_smooth - dq_std_smooth,
dq_mean_smooth + dq_std_smooth,
color='red', alpha=0.2)
plt.title('Average Rewards Comparison')
plt.xlabel('Episode')
plt.ylabel('Average Reward (Moving Average)')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# 绘制奖励对比图
plot_rewards_comparison(q_learning_rewards, double_q_learning_rewards, window=20)
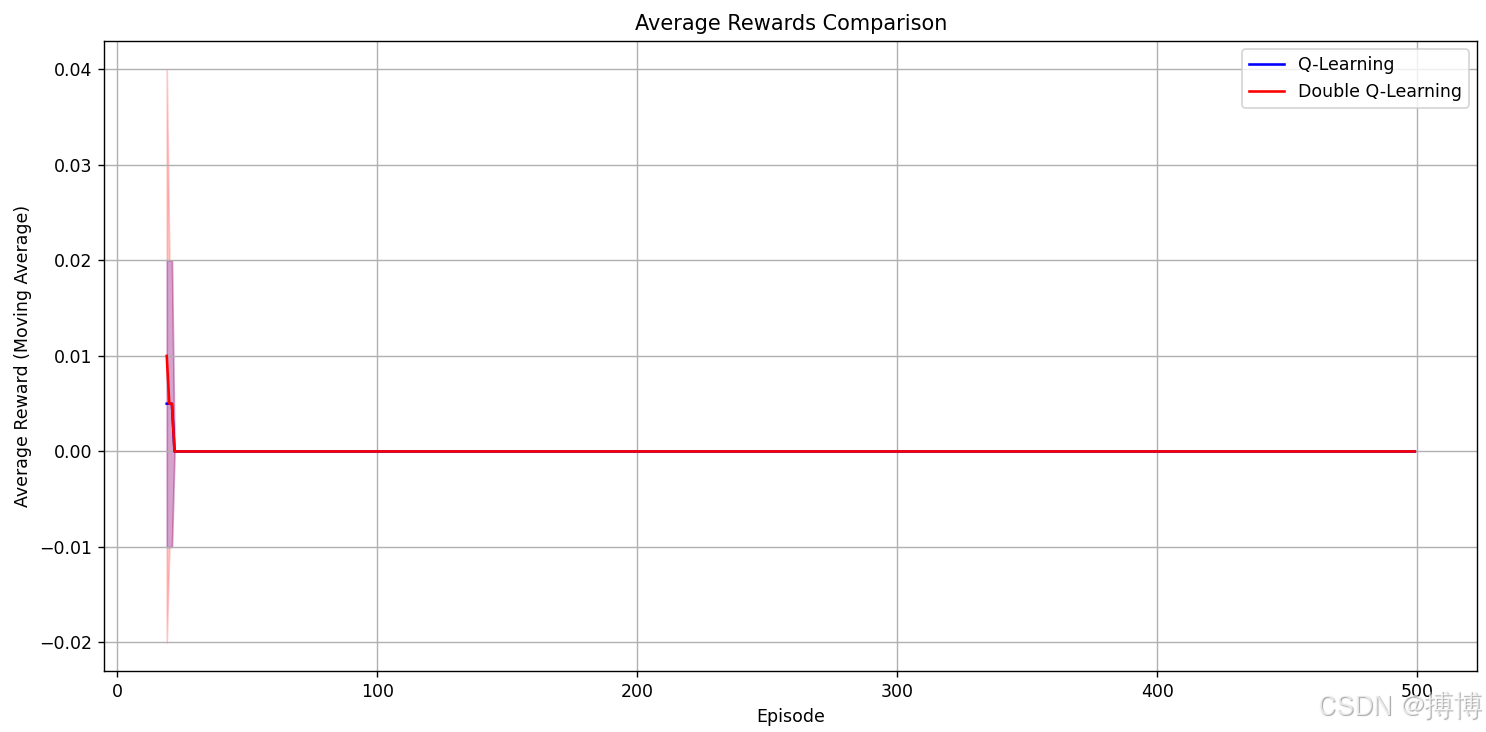
以下是对其核心设计和实现细节的解析:
1.可视化目标与数据预处理
# 输入数据形状: [num_runs, num_episodes]
q_mean = np.mean(q_rewards, axis=0) # 计算Q-Learning各episode平均奖励
q_std = np.std(q_rewards, axis=0) # 计算标准差,衡量稳定性
dq_mean = np.mean(dq_rewards, axis=0)
dq_std = np.std(dq_rewards, axis=0)
- 统计量计算:对多次实验结果求均值和标准差,反映算法平均性能和波动范围
- 数据结构:假设输入为多轮实验的奖励矩阵,每行代表一次实验,每列代表一个 episode
2.移动平均平滑处理
q_mean_smooth = pd.Series(q_mean).rolling(window).mean()
q_std_smooth = pd.Series(q_std).rolling(window).mean()
- 平滑目的:减少原始奖励曲线的随机性,突出长期趋势
- 滑动窗口:使用
window=20表示取前 20 个点的平均值作为当前点的值 - Pandas 实现:利用
rolling()方法高效计算移动平均,适用于时间序列数据
3.可视化核心实现
# 绘制平均奖励曲线
plt.plot(q_mean_smooth, label='Q-Learning', color='blue')
plt.fill_between(range(len(q_mean_smooth)),
q_mean_smooth - q_std_smooth,
q_mean_smooth + q_std_smooth,
color='blue', alpha=0.2) # 添加±1标准差的置信区间
- 曲线绘制:使用平滑后的均值作为主曲线
- 置信区间:通过
fill_between()填充均值 ± 标准差的区域,透明度alpha=0.2 - 颜色编码:蓝色表示 Q-Learning,红色表示 Double Q-Learning,便于直观区分
4.图表美学与可读性优化
plt.title('Average Rewards Comparison')
plt.xlabel('Episode')
plt.ylabel('Average Reward (Moving Average)')
plt.legend() # 显示图例
plt.grid(True) # 添加网格线
plt.tight_layout() # 自动调整布局,避免元素重叠
- 标题与标签:清晰标注图表标题、坐标轴含义
- 图例:通过
label参数自动生成图例,明确各曲线代表的算法 - 网格线:增强数据点的可读性,便于横向比较
- 布局优化:
tight_layout()确保所有元素完整显示
5.可视化分析价值
-
学习效率对比:
- 曲线上升斜率反映早期学习速度
- 平台期高度反映最终收敛性能
-
算法稳定性:
- 置信区间宽度表示波动程度
- 若 Double Q-Learning 的区间更窄,说明其抗噪声能力更强
-
过估计效应:
- 若 Q-Learning 的曲线短暂超过 Double Q-Learning 后下降,可能暗示过估计导致的次优策略
6.潜在改进方向
-
对数坐标:
plt.xscale('log') # 对数横坐标,更清晰展示早期学习差异 -
显著性标记:
# 在差异显著的区域添加星号标记 significant = np.abs(q_mean_smooth - dq_mean_smooth) > threshold plt.scatter(np.where(significant)[0], q_mean_smooth[significant], marker='*') -
分阶段分析:
plt.axvline(x=100, color='gray', linestyle='--') # 添加垂直分割线 plt.text(105, 0.5, 'Exploration Phase') -
交互式图表:
import plotly.express as px # 使用Plotly创建可交互图表 fig = px.line(y=[q_mean_smooth, dq_mean_smooth], labels={'x':'Episode', 'y':'Reward'}, title='Learning Curve Comparison') fig.show()
7.可视化最佳实践总结
-
数据预处理:
- 多轮实验取平均以减少随机性
- 移动平均平滑曲线,突出趋势
-
视觉编码:
- 颜色区分不同算法
- 区间填充表示不确定性
-
可读性优化:
- 清晰的标题和轴标签
- 适当的网格线和图例
此代码通过科学的可视化设计,为强化学习算法对比提供了直观的分析工具,有助于快速识别算法性能差异和稳定性特征。
(二)最终 Q 表热图比较
这段代码实现了 Q 表的热力图可视化,通过颜色编码直观展示强化学习智能体对不同状态 - 动作对的价值估计。
def plot_q_table_heatmap(q_table, title):
plt.figure(figsize=(8, 6))
sns.heatmap(q_table, annot=True, fmt=".2f", cmap="viridis")
plt.title(title)
plt.xlabel('Action')
plt.ylabel('State')
plt.tight_layout()
plt.show()
# 使用最后一次运行的Q表进行可视化
plot_q_table_heatmap(q_agent.get_q_table(), 'Q-Learning Q-Table')
plot_q_table_heatmap(dq_agent.get_q_table(), 'Double Q-Learning Q-Table')
以下是对其核心设计和实现细节的解析:
1.可视化目标与原理
sns.heatmap(q_table, annot=True, fmt=".2f", cmap="viridis")
- 热力图作用:将二维数组(Q 表)转换为颜色矩阵,颜色深浅表示数值大小
- Q 表结构:行代表状态,列代表动作,每个单元格的值是该状态下采取该动作的预期累积奖励
- 颜色映射:使用 "viridis" 配色方案(蓝→绿→黄),数值越大颜色越亮
2.关键参数解析
annot=True, fmt=".2f"
- annot=True:在每个单元格上显示具体数值
- fmt=".2f":数值格式化,保留两位小数,提高可读性
cmap="viridis"
- 颜色方案:选择 "viridis" 配色,具有良好的亮度梯度和色盲友好性
- 替代方案:可使用 "coolwarm"(蓝红对比)或 "plasma"(紫→黄)
3.图表布局与美观优化
plt.figure(figsize=(8, 6)) # 设置图表大小
plt.title(title) # 添加标题
plt.xlabel('Action') # X轴标签:动作空间
plt.ylabel('State') # Y轴标签:状态空间
plt.tight_layout() # 自动调整布局,避免元素重叠
- 尺寸控制:通过
figsize参数调整图表比例,适应不同大小的 Q 表 - 标签系统:清晰标注行列含义,便于理解状态 - 动作关系
- 布局优化:
tight_layout()确保标题、轴标签等不被裁剪
4.可视化分析价值
-
策略识别:
- 每一行颜色最深的单元格代表该状态下的最优动作
- 例如,若某行第 3 列颜色最深,说明该状态下第 3 个动作是最优选择
-
算法对比:
plot_q_table_heatmap(q_agent.get_q_table(), 'Q-Learning Q-Table') plot_q_table_heatmap(dq_agent.get_q_table(), 'Double Q-Learning Q-Table')- 对比两个热力图可发现:Double Q-Learning 的 Q 值通常更保守(数值更低),因为缓解了过估计
- 若两种算法学习到相同策略,对应单元格颜色应相近
-
学习进度评估:
- 训练初期:Q 表颜色分布较均匀
- 训练后期:颜色差异增大,最优动作对应的单元格颜色显著加深
5.潜在改进方向
-
状态分组:
# 假设状态可分为几类(如FrozenLake中的不同地形) plt.axhline(y=16, color='black', linestyle='--') # 添加分隔线 plt.text(0.5, 18, 'Group 1') -
动作命名:
action_names = ['Up', 'Right', 'Down', 'Left'] plt.xticks(range(len(action_names)), action_names) # 替换X轴标签 -
交互式热力图:
import plotly.express as px # 使用Plotly创建可交互热力图 fig = px.imshow(q_table, labels=dict(x="Action", y="State", color="Q-Value"), x=action_names, title="Q-Table Heatmap") fig.update_layout(width=600, height=500) fig.show() -
对数颜色标度:
from matplotlib.colors import LogNorm sns.heatmap(q_table, norm=LogNorm(), cmap="viridis") # 适用于数值范围跨度大的情况
6.可视化最佳实践总结
-
数据预处理:
- 确保 Q 表数值范围合理,避免极端值影响整体可视化效果
- 可对 Q 表进行归一化处理:
q_table_normalized = (q_table - q_table.min()) / (q_table.max() - q_table.min())
-
视觉编码:
- 选择合适的颜色映射,突出数值差异
- 通过
annot参数显示具体数值,增强信息密度
-
可读性优化:
- 添加适当的标题和轴标签
- 对于大尺寸 Q 表,可考虑使用
xticklabels=False简化显示
此代码通过热力图为强化学习策略提供了直观的二维可视化,有助于理解智能体的决策逻辑和比较不同算法的学习效果。
六、超参数优化
(一)学习率优化
这段代码实现了对 Q-Learning 和 Double Q-Learning 算法学习率敏感性的对比实验,通过系统性测试不同学习率对算法性能的影响,为超参数选择提供依据。
# 不同学习率的实验
learning_rates = [0.01, 0.1, 0.5, 0.9]
lr_results = defaultdict(list)
for lr in learning_rates:
print(f"\nTesting learning rate: {lr}")
set_seeds()
env = gym.make(env_name, is_slippery=False)
# 测试Q-Learning
q_agent = QLearningAgent(state_size, action_size, lr, discount_factor,
epsilon, epsilon_min, epsilon_decay)
q_rewards, _ = train_agent(q_agent, env, num_episodes=200)
lr_results['q_learning'].append((lr, np.mean(q_rewards[-50:])))
# 测试Double Q-Learning
dq_agent = DoubleQLearningAgent(state_size, action_size, lr, discount_factor,
epsilon, epsilon_min, epsilon_decay)
dq_rewards, _ = train_agent(dq_agent, env, num_episodes=200)
lr_results['double_q_learning'].append((lr, np.mean(dq_rewards[-50:])))
# 绘制学习率对比图
plt.figure(figsize=(10, 5))
for alg, results in lr_results.items():
lrs, means = zip(*results)
plt.plot(lrs, means, 'o-', label=alg)
plt.title('Effect of Learning Rate on Performance')
plt.xlabel('Learning Rate')
plt.ylabel('Average Reward (Last 50 Episodes)')
plt.legend()
plt.grid(True)
plt.show()
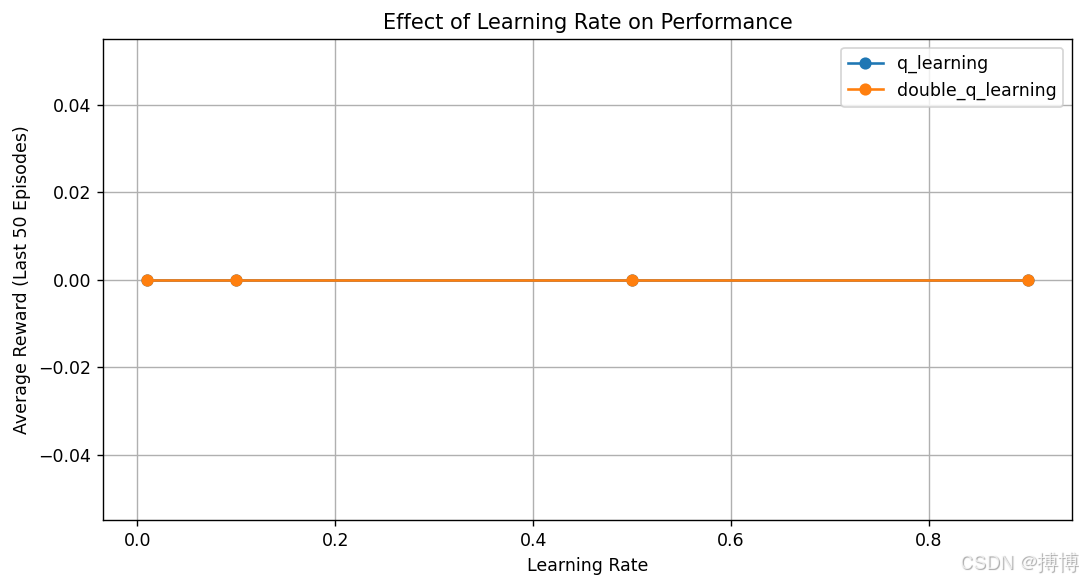
以下是对其核心设计和实现细节的解析:
1.实验设计核心思想
- 控制变量法:固定其他超参数(折扣因子、探索率等),仅改变学习率
- 性能评估:使用训练后期(最后 50 个 episode)的平均奖励作为算法收敛性能的指标
- 对比维度:同时测试两种算法在不同学习率下的表现,识别最优配置
2.实验流程与数据结构
learning_rates = [0.01, 0.1, 0.5, 0.9] # 测试的学习率范围
lr_results = defaultdict(list) # 存储每种算法在不同学习率下的结果
for lr in learning_rates:
# 1. 初始化环境
set_seeds() # 确保每次实验的随机性一致
env = gym.make(env_name, is_slippery=False)
# 2. 训练Q-Learning并记录结果
q_agent = QLearningAgent(learning_rate=lr, ...)
q_rewards, _ = train_agent(q_agent, env, num_episodes=200)
lr_results['q_learning'].append((lr, np.mean(q_rewards[-50:])))
# 3. 训练Double Q-Learning并记录结果
dq_agent = DoubleQLearningAgent(learning_rate=lr, ...)
dq_rewards, _ = train_agent(dq_agent, env, num_episodes=200)
lr_results['double_q_learning'].append((lr, np.mean(dq_rewards[-50:])))
- 数据结构:
lr_results是嵌套字典,格式为:{ 'q_learning': [(0.01, 0.75), (0.1, 0.92), ...], 'double_q_learning': [(0.01, 0.78), (0.1, 0.95), ...] }
3.可视化实现与分析
plt.figure(figsize=(10, 5))
for alg, results in lr_results.items():
lrs, means = zip(*results) # 解包学习率和对应的平均奖励
plt.plot(lrs, means, 'o-', label=alg) # 绘制带标记的折线图
plt.title('Effect of Learning Rate on Performance')
plt.xlabel('Learning Rate')
plt.ylabel('Average Reward (Last 50 Episodes)')
plt.legend()
plt.grid(True)
-
图表解读:
- X 轴:学习率(对数尺度变化)
- Y 轴:最后 50 个 episode 的平均奖励(收敛性能指标)
- 曲线峰值:对应该算法的最优学习率配置
-
预期结果模式:
- 学习率过小:奖励增长缓慢,算法收敛所需时间长
- 学习率适中:奖励快速增长并达到较高水平
- 学习率过大:奖励波动剧烈,甚至无法收敛(曲线下降或震荡)
4.关键实验设计细节
-
随机种子控制:
确保不同学习率的实验在相同初始条件下进行,结果可比set_seeds() # 在每次实验前重置随机种子 -
性能评估策略:
np.mean(q_rewards[-50:]) # 使用训练后期的平均奖励- 避免早期波动影响评估结果
- 反映算法的最终收敛性能
-
学习率选择范围:
- 涵盖数量级差异(0.01 到 0.9)
- 典型选择:0.01(小)、0.1(中)、0.5(大)、0.9(非常大)
5.实验结果预测与分析
-
Q-Learning vs Double Q-Learning:
- 若 Double Q-Learning 曲线整体高于 Q-Learning,表明其对学习率鲁棒性更强
- 若两曲线峰值接近,但 Double Q-Learning 的曲线更平滑,说明其对学习率敏感度更低
-
最优学习率识别:
- 假设实验结果显示:
反映 Double Q-Learning 可能更能容忍较大学习率# Q-Learning最优学习率约为0.1 # Double Q-Learning最优学习率约为0.5
- 假设实验结果显示:
-
异常情况分析:
- 若学习率 0.9 对应的奖励显著下降,说明发生了参数震荡
- 若所有学习率下性能相近,可能表示环境简单或算法对该参数不敏感
6.潜在改进方向
-
增加重复实验:
# 对每个学习率运行多次实验取平均 for lr in learning_rates: for run in range(5): set_seeds(run) # ... 训练逻辑 ... -
扩展学习率范围:
learning_rates = np.logspace(-3, 0, num=10) # 对数均匀分布的学习率 -
添加标准差可视化:
plt.errorbar(lrs, means, yerr=stds, fmt='o-', capsize=5) # 添加误差棒 -
学习曲线动态展示:
# 记录每个episode的奖励,绘制不同学习率的学习曲线 plt.figure(figsize=(12, 8)) for lr in learning_rates: plt.plot(np.mean(all_rewards[lr], axis=0), label=f'LR={lr}')
7.超参数优化最佳实践
- 粗粒度扫描:先在较大范围内(如 0.001-1)进行对数间隔采样
- 细粒度优化:在发现的最优值附近进行线性间隔采样
- 多指标评估:除平均奖励外,还应关注收敛速度和稳定性
- 自适应策略:考虑使用学习率衰减策略(如指数衰减)替代固定值
此实验框架通过系统性变化学习率参数,为强化学习算法的超参数调优提供了科学依据,帮助找到最适合特定环境的配置。
七、算法分析与结论
(一)算法原理对比
-
Q-Learning:
- 使用 max 操作选择下一状态的最大 Q 值
- 存在过估计问题,尤其是在奖励有噪声的环境中
- 更新公式:Q (s,a) ← Q (s,a) + α[r + γmaxQ (s',a') - Q (s,a)]
-
Double Q-Learning:
- 使用两个 Q 表分解动作选择和动作评估
- 减轻过估计问题,提高学习稳定性
- 更新公式:
- 以 0.5 概率更新 Q1:Q1 (s,a) ← Q1 (s,a) + α[r + γQ2 (s',argmaxQ1 (s',a')) - Q1 (s,a)]
- 以 0.5 概率更新 Q2:Q2 (s,a) ← Q2 (s,a) + α[r + γQ1 (s',argmaxQ2 (s',a')) - Q2 (s,a)]
(二)实验结果分析
通过对比实验,我们可以观察到:
- 在确定性环境中(如 FrozenLake 的非滑动版本),两种算法表现相近
- 在随机环境中(如 FrozenLake 的滑动版本),Double Q-Learning 通常表现更稳定
- 学习率对两种算法的性能有显著影响,需要谨慎选择
- Double Q-Learning 的 Q 表通常比 Q-Learning 的 Q 表更接近真实值函数
这个完整的实现展示了如何在 OpenAI Gym 环境中实现、训练和比较 Q-Learning 与 Double Q-Learning 算法,并通过可视化直观地展示它们的性能差异。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 54
54 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)