
Zero-Shot Scene Reconstruction from Single Images with Deep Prior Assembly 论文解读
该论文提出了深度先验组装(deep prior assembly)框架,利用大语言模型和视觉模型的不同的多样化深度先验组装在一起,以零样本的方法从单图像中重建场景。关键思想是通过将单图像场景重建任务分解为一系列子任务,并且每个子任务均通过大模型来解决。
目录
一、概述
该论文提出了深度先验组装(deep prior assembly)框架,利用大语言模型和视觉模型的不同的多样化深度先验组装在一起,以零样本的方法从单图像中重建场景。关键思想是通过将单图像场景重建任务分解为一系列子任务,并且每个子任务均通过大模型来解决。
(1)将场景重建分解为若干问题,并利用大模型协同应用,如Grounded-SAM、Stable Diffusion等大型模型。
(2)提出了布局估计和遮挡复原的解决方案,保证布局准确,以及损坏的物品能够更加完整和准确。
(3)评估生成不同开放世界场景的性能,并且显示出SOTA性能。
二、相关工作
1、不同模态下的大模型
在自然语言处理领域,近年来大规模预训练语言模型的研究取得了重大突破,极大地推动了自然语言处理的发展。
在2D视觉领域,研究人员也将大模型的思路从语言领域转移到了2D视觉领域,取得了显著的进展。(Stable Diffusion)
在3D视觉领域,也出现了一些大模型,如用于3D分析(Uni3D)和3D物体生成的大模型,取得了优异的性能。
除了大规模的基础模型,还有一些针对特定任务的大模型,如文本到图像生成、图像分割(SAM)、深度估计(Omnidata)、图像或文本生成3D几何图形(Point·E,Shap·E)等,也取得了卓越的表现。
2、图像到场景重建
图像到场景的重建近期大多数是多视图或者密集视图的重建,一般通过深度估计来进行密集图像的特征匹配,受NeRF影响体渲染开始引入场景表示工作,另外SDF和占用场逐渐引入表面重建。
NeuRIS提出法线先验来生成室内场景重建,MonoSDF提出单视角深度估计来改善场景几何关系。
三、DeepPriorAssembly
DeepPriorAssembly(深度先验组装)有六个部分组成:实例检测和分割,实例图像增强和修复,筛选优秀图像,生成3D模型,深度估计,场景布局。
完整流程:
首先输入单张图像,通过Grounded SAM进行实例检测和分割,并获得2D掩码和实例对象裁剪后的图像。
第二步通过Stable-Diffusion来对实例图像的质量不佳,物体残缺等问题进行复原,优化,并得到一组候选对象图像。
第三步利用SAM预测的实例类别文本提示作为引导,评估生成实例和原始实例对象的余弦相似度,并用Open-Clip过滤坏的生成实例。
第四步从Top-K生成的实例图像中,使用Shap·E为该实例生成若干3D模型。
第五步使用Omnidata模型生成深度图,并且利用2D掩码提出每个所需物体的点云信息。
第六步利用类似RANSAC的配准方法和2D掩模之间距离来实现3D模型的精确放置匹配最优的锁定该物体的三维模型布局。
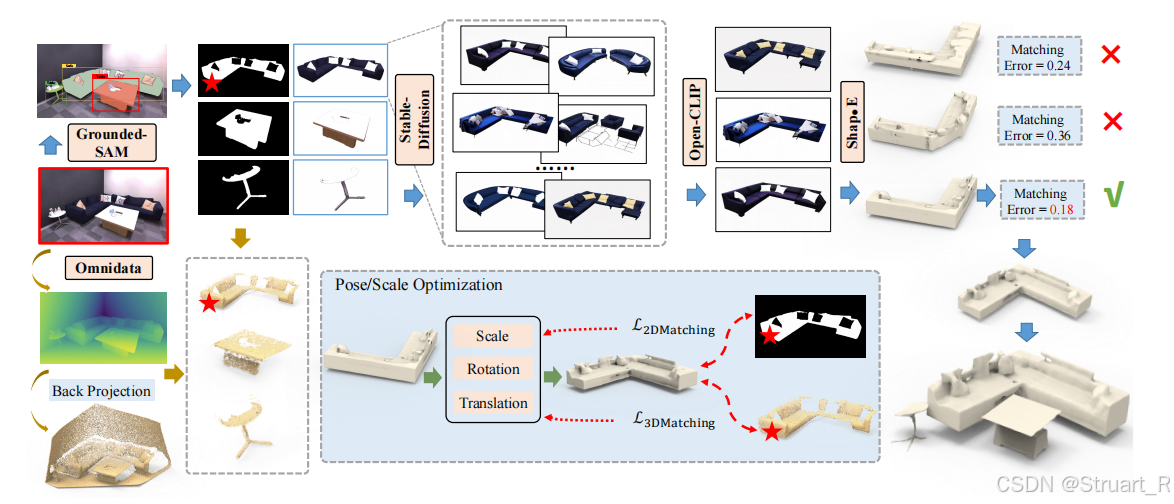
1、实例检测和分割
对于近期的分割模型,Mask R-CNN,SAM,Grouded SAM来说,Mask R-CNN训练的数据集较小,泛化性较差,SAM通过扩展参数量,加上使用更多训练集提升了预测精度,但是只能预测细粒度的掩模,缺少语义信息。该论文使用Grouded SAM,通过引入Grounding-Dino作为开放集检测器,内部使用SAM执行预测,分割,标签等任务。
通过Grounded-SAM,输入图像得到不同实例的预测掩码,预测类别
,和预测置信度
分数,对于每一个预测只保留一个置信度最高的,大于阈值的。
2、实例图像增强和修复
使用每一个物体的分割掩码对图像进行覆盖,得到实例图像
,并对实例图像进行归一化,将实例图像居中,并且将尺度缩放到原始输入图像
的最大宽度或最大高度的0.6倍。
增强的目的:提高实例图像的质量,因为原始分割出的实例图像,通常分辨率较低,且位置偏移。
之后我们将每一个实例图像使用Stable-Diffusion进行扩散修复,我们使用SAM预测的类别作为文本提示Prompt,并且引入模版优化Prompt,具体模版为“High quality,authentic style {category}”,由于SD可能会生成不可靠的预测,所以我们同时依据同一个实例对象,生成(6张)多张图像
,并且后续掉效果较差的坏样本。
修复的目的:修补图像残缺的部分,提高图像的质量,并且为后续三维生成作准备。
3、筛选优秀图像
利用Open-CLIP模型,输入生成的实例图像和相对应的预测类别文本
以及原始的实例图像和预测类别文本对,之后计算余弦相似度,选择与原始图像最相似的(Top-3)Top-K个生成图像作为最终输出。
4、生成三维模型
在单视图生成三维模型中,该论文使用单视图生成三维模型的Shap·E,这个模型预训练了数百万个非公共的三维物体,内部是一个潜在扩散模型生成NeRF的三维参数。 我们对每一个实例图像的Top-K个候选最相近2D图像作为输入,输出同样多的数量的三维重建模型
,这个模型的输出包含NeRF参数和纹理结构。
从下面这张图也可以看出来,如果不补全物体直接进行三维生成,效果会很差。
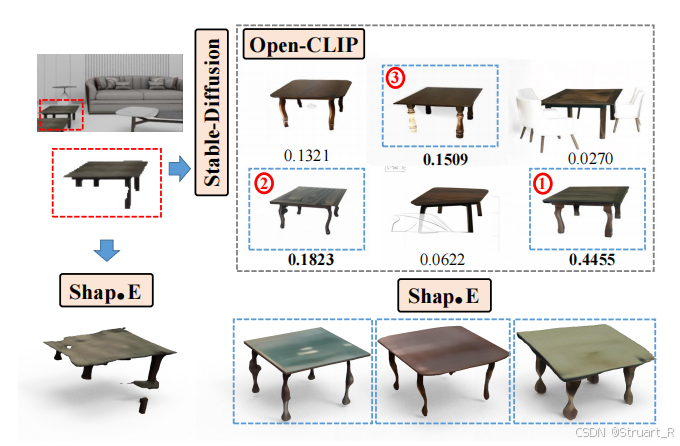
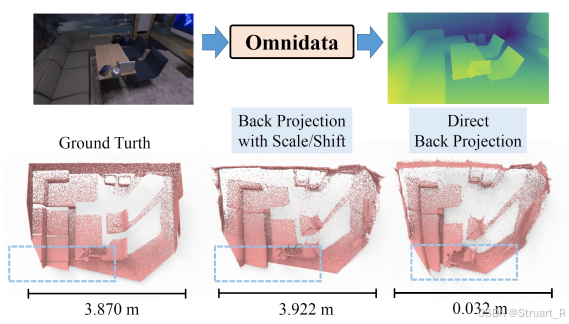
5、深度估计
首先对输入图像使用Omnidata大模型进行深度图估计,作为三维几何先验,Omnidata模型利用1400万室内、室外、场景级和对象级样本进行训练。
由于Omnidata模型估计的深度图并不是真实的3D场景深度信息,存在一定的尺度和偏移偏差,这会导致后续3D模型和场景布局过程中存在失真。所以该论文提出通过每一个场景中的一对预测深度和真实深度,在特定场景摄像机固有参数(内参
)下进行最小二乘法回归,得到偏差尺度
和偏移量
。(另外他也提到,可以用其他度量深度估计方法,来处理深度尺度和位移的关系,减少对GT的依赖)
之后将深度图进行尺度变换后,利用相机固有参数将D反投影到三维空间,实现三维场景深度点云
。
下图三个点云应该是,GT深度图,最小二乘法回归出的偏移量校正后反投影三维空间,直接将深度图反投影三维空间(存在失真)。
6、场景布局
首先从生成的三维模型中采样一些点云
,得到该模型的三维点云形式。
对于原来的三维点云通过上一部分深度估计中,深度图反投影得到相对GT的深度三维点云。
场景布局的目的就是将计算每一个实例的这两组三维点云之间的变换关系。首先建模成一个7自由度的配准任务,即平移,旋转加尺缩7个自由度,并且初始化一组7自由度参数,我们的目的是得到一组最优的
,之后得到预测的点云位置
。
为了得到这个最优的,我们采用2D匹配和3D匹配进行同时监督,计算倒角损失。
2D匹配上,一方面从掩码的区域随机采样密集二维点
,另一方面将我们从三维模型采样得到的三维点云投影到具有相机固有参数的二维点云
,计算这两者的倒角损失。
3D匹配上,由于旋转方面存在较大误差,所以使用类似RANSAC的方法,重复进行r次优化,每次使用随机的初始化旋转矩阵,之后计算三维模型生成的点云与深度图对应掩模反投影三维点
之间的倒角距离。
最后最小化损失:
![]()
有无2D匹配的配准效果差异。
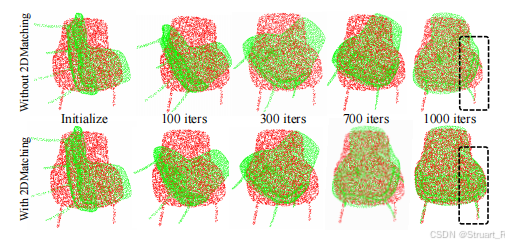
最后选择Top-K模型中能够达到的最小损失的模型,作为三维生成的最终模型。
四、数据集
-
3D-Front:
- 这是一个合成的室内3D场景数据集。
- 数据预处理由PanoRecon完成,从测试集中随机选择1000个场景图像作为单图像数据集。
- 所有图像都是平行于地面拍摄的,相机位置距离地面0.75米高度。
- 通过PanoRecon的方法获得每个图像对应的地面真值网格。
-
Replica:
- 这是一个室内场景数据集,包含8个扫描的高保真3D室内场景。
- 使用了MonoSDF提供的预处理数据,从每个场景中采样一张图像作为单图像数据集。
- 地面真值网格的获取方式与3D-Front相同。
-
BlendSwap:
- 这是一个高保真合成3D场景数据集,由Neural-RGBD收集,包含9个几何复杂的场景。
- 采集单视图图像和对应的地面真值网格,方法与Replica数据集相同。
-
ScanNet:
- 这是一个真实世界的3D场景数据集,由RGB-D相机捕获。
- 从测试集中选择7个场景,从每个场景采样一张图像作为输入。
五、基准
在论文中使用最先进的单一图像场景重建Mesh R-CNN,Total3D,PanoRecon进行比较,这三个方法均为数据驱动,并且在带有GT的3D数据集下进行训练,而我们论文以Zero-Shot的方式解决,无需任何数据驱动。
六、性能指标
CDL1:衡量生成3D场景和真实场景之间的倒角距离,越小越好。(该论文单一场景采样10k个点)
CDL1-S:单向的倒角距离,衡量3D物体和真实物体之间的倒角距离,不考虑背景,越小越好。
F-Score:衡量生成场景和真实场景的匹配程度。(不太清楚)
七、实验
1、单视角重建性能

2、合成室内数据集下的效果
在3D-Front数据集下的可视化。
该方法不仅Zero-Shot而且可以生成纹理对象效果显著。

3、合成/扫描开放世界的场景数据集下效果
在Replica和BlendSwap下的可视化。
这里考虑PanoRecon,但是发现他不能泛化到OOD。总结来说,该论文方法,在具有几何图形的物体上可以更加细致,而其他的方法生成比较粗糙的三维形状,另外其他方法也无法估计准确的布局。

4、现实世界场景数据集下效果
ScanNet数据集下效果。
这里不考虑PanoRecon是因为他不能泛化到OOD情况。 另外提到了现实场景中由于相机对焦不好,而导致生成的现实场景会出现模糊损坏。(该方法用大模型,能够稳定发挥)

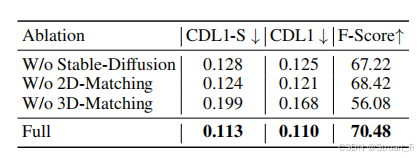
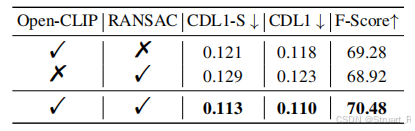
5、消融实验
测试了两个消融实验,分别对图像生成,点云匹配,筛选对象等方面进行消融
参考项目:DeepPriorAssembly

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 40
40 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)