
在 Python Requests 中使用代理
在本指南中,你将学习如何在 Python Requests 中使用代理,特别是在 网络爬虫 时,通过更改 IP 和地理位置来 绕过网站限制

促销链接 亮数据-网络IP代理及全网数据一站式服务商
在本指南中,你将学习如何在 Python Requests 中使用代理,特别是在 网络爬虫 时,通过更改 IP 和地理位置来 绕过网站限制:
- 在 Python Request 中使用代理
- 安装依赖包
- 代理 IP 地址的组成部分
- 在 Requests 中直接设置代理
- 通过环境变量设置代理
- 通过自定义方法和代理数组实现代理轮换
- 在 Python 中使用 Bright Data 的代理服务
- 总结
在 Python Request 中使用代理
安装依赖包
使用 pip install 来安装以下 Python 包,以便向网页发送请求并收集链接:
requests:用于向目标网站发送 HTTP 请求。beautifulsoup4:用于解析 HTML 和 XML 文档以提取所有链接。
代理 IP 地址的组成部分
代理服务器的三个主要组成部分包括:
- 协议(Protocol):通常为 HTTP 或 HTTPS。
- 地址(Address):可以是 IP 地址或域名。
- 端口号(Port number):范围是 0 到 65535 之间,例如
2000。
因此,一个完整的代理 IP 地址可能是:https://192.167.0.1:2000 或https://proxyprovider.com:2000。
在 Requests 中直接设置代理
本指南介绍了三种在 requests 中设置代理的方式。第一种方式是在 requests 模块内直接指定代理参数:
- 在 Python 脚本中导入 Requests 和 Beautiful Soup 包。
- 创建一个名为
proxies的字典,用于存放代理服务器信息。 - 在
proxies字典中,分别定义 HTTP 和 HTTPS 对应的代理地址。 - 定义要爬取的网页 URL,可以使用
https://www.bright.cn作为示例。 - 使用
request.get()方法发送 GET 请求到目标网页,并带上网址和proxies字典,这样返回值会存储在response变量中。 - 将
response.content和html.parser传给BeautifulSoup()用于提取网页上的链接。 - 使用
find_all("a")方法查找网页上的所有链接标签。 - 使用
link.get("href")提取每个链接的href属性。
示例代码如下:
# import packages.
import requests
from bs4 import BeautifulSoup
# Define proxies to use.
proxies = {
'http': 'http://proxyprovider.com:2000',
'https': 'https://proxyprovider.com:2000',
}
# Define a link to the web page.
url = "https://example.com/"
# Send a GET request to the website.
response = requests.get(url, proxies=proxies)
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
以上脚本运行后会输出如下结果:
通过环境变量设置代理
如果想为所有请求使用相同的代理,最好在终端窗口中设置环境变量:
export HTTP_PROXY='http://proxyprovider.com:2000'
export HTTPS_PROXY='https://proxyprovider.com:2000'
这样一来,你就可以在脚本中去掉有关代理的定义了:
# import packages.
import requests
from bs4 import BeautifulSoup
# Define a link to the web page.
url = "https://example.com/"
# Send a GET request to the website.
response = requests.get(url)
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
通过自定义方法和代理数组实现代理轮换

促销链接 亮数据-网络IP代理及全网数据一站式服务商
当网站收到来自同一个 IP 地址的大量请求时,可能会进行阻拦或封禁。通过轮换不同的代理,可以有效地应对这些限制。
具体步骤如下:
- 导入以下 Python 库:Requests、BeautifulSoup 和 Random。
- 创建一个代理列表,形式为
http://proxyserver.com:port,以便轮换使用:
# List of proxies
proxies = [
"http://proxyprovider1.com:2010", "http://proxyprovider1.com:2020",
"http://proxyprovider1.com:2030", "http://proxyprovider2.com:2040",
"http://proxyprovider2.com:2050", "http://proxyprovider2.com:2060",
"http://proxyprovider3.com:2070", "http://proxyprovider3.com:2080",
"http://proxyprovider3.com:2090"
]
- 创建一个名为
get_proxy()的自定义方法。它会用random.choice()从代理列表中随机选取一个代理,并以字典形式返回(包含 HTTP 和 HTTPS 两个键)。每次发送新请求时,都调用这个方法获取新代理:
# Custom method to rotate proxies
def get_proxy():
# Choose a random proxy from the list
proxy = random.choice(proxies)
# Return a dictionary with the proxy for both http and https protocols
return {'http': proxy, 'https': proxy}
- 创建一个循环,使用轮换代理发送多次 GET 请求。每次请求都会随机调用
get_proxy()方法来获取代理。 - 使用 BeautifulSoup 对返回的网页内容进行解析,并提取网页上的所有链接内容。
- 捕获并打印在请求过程中可能发生的异常。
完整示例代码如下:
# import packages
import requests
from bs4 import BeautifulSoup
import random
# List of proxies
proxies = [
"http://proxyprovider1.com:2010", "http://proxyprovider1.com:2020",
"http://proxyprovider1.com:2030", "http://proxyprovider2.com:2040",
"http://proxyprovider2.com:2050", "http://proxyprovider2.com:2060",
"http://proxyprovider3.com:2070", "http://proxyprovider3.com:2080",
"http://proxyprovider3.com:2090"
]
# Custom method to rotate proxies
def get_proxy():
# Choose a random proxy from the list
proxy = random.choice(proxies)
# Return a dictionary with the proxy for both http and https protocols
return {'http': proxy, 'https': proxy}
# Send requests using rotated proxies
for i in range(10):
# Set the URL to scrape
url = 'https://www.bright.cn/'
try:
# Send a GET request with a randomly chosen proxy
response = requests.get(url, proxies=get_proxy())
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
except requests.exceptions.RequestException as e:
# Handle any exceptions that may occur during the request
print(e)
在 Python 中使用 Bright Data 的代理服务
Bright Data 拥有超过 7200 万个 住宅代理 IP 以及超过 770,000 个 数据中心代理。你可以将 Bright Data 的数据中心代理 集成到 Python Requests 中。
当你注册了 Bright Data 账号后,可以按照以下步骤创建你的第一个代理:
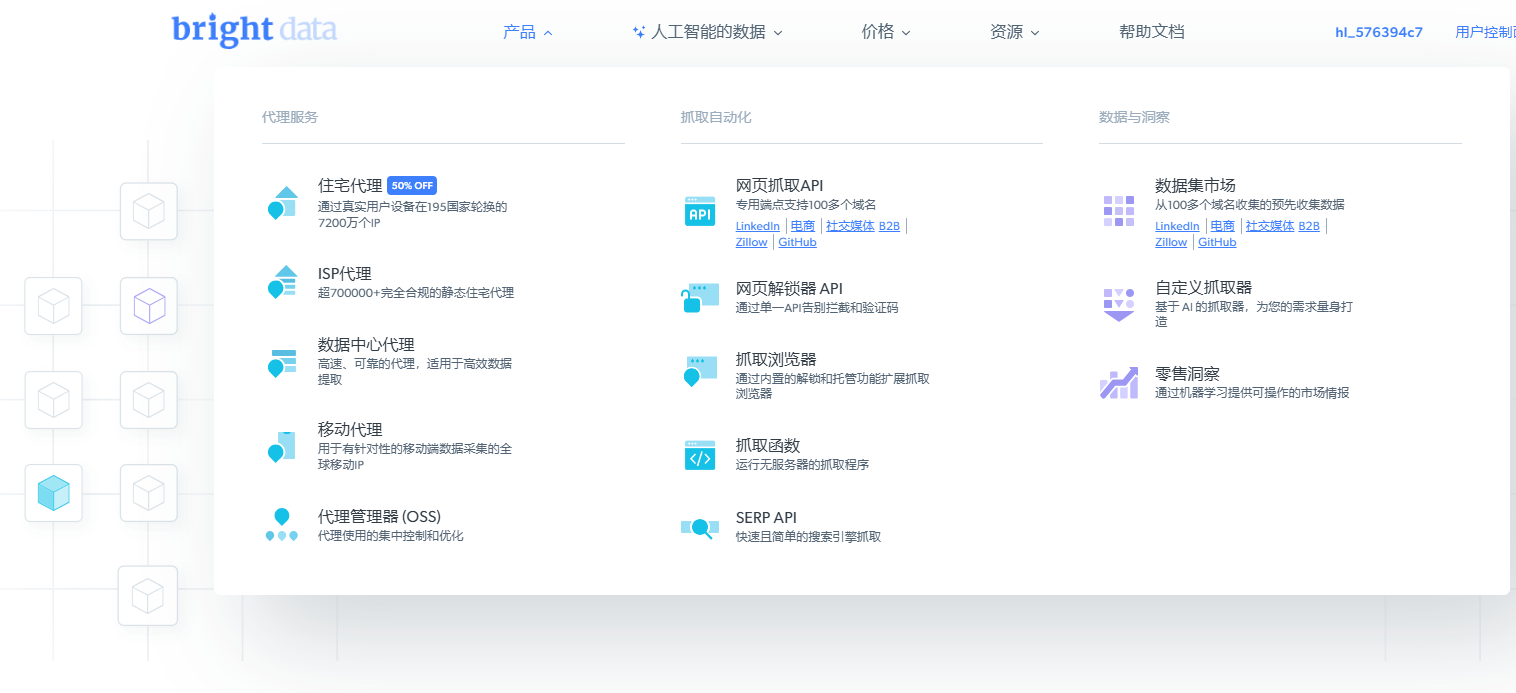
- 在欢迎页面点击 View proxy product 以查看 Bright Data 不同类型的代理服务:
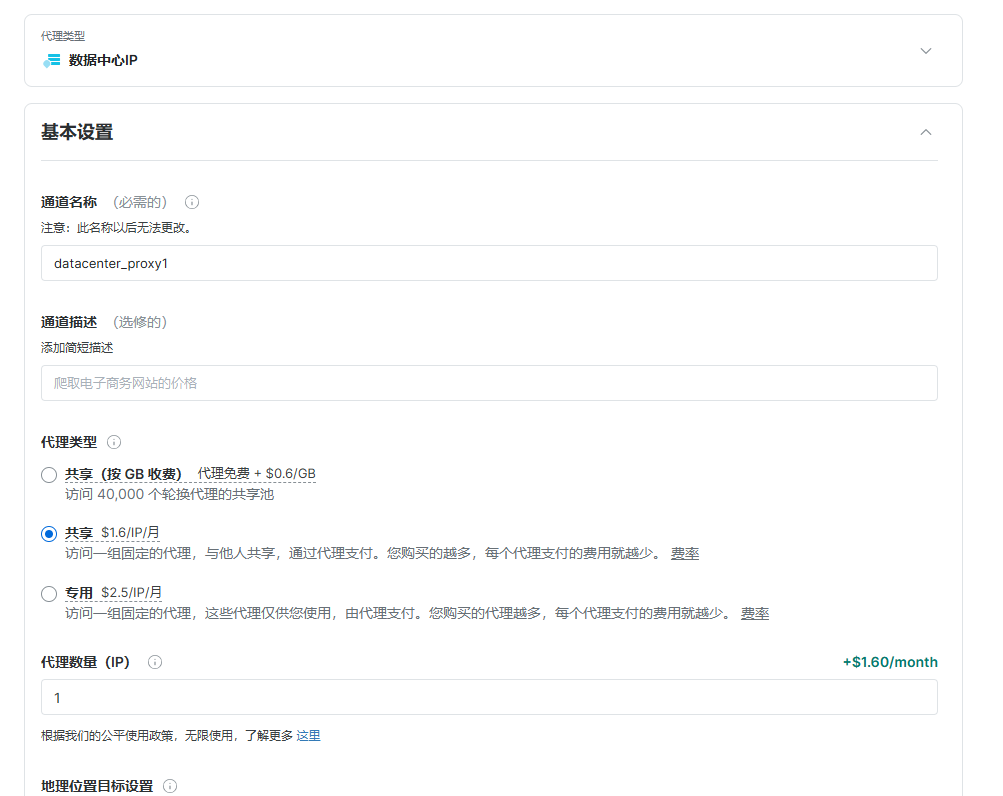
- 选择 Datacenter Proxies 来创建新的代理,然后在弹出的页面填写你的信息,并保存:
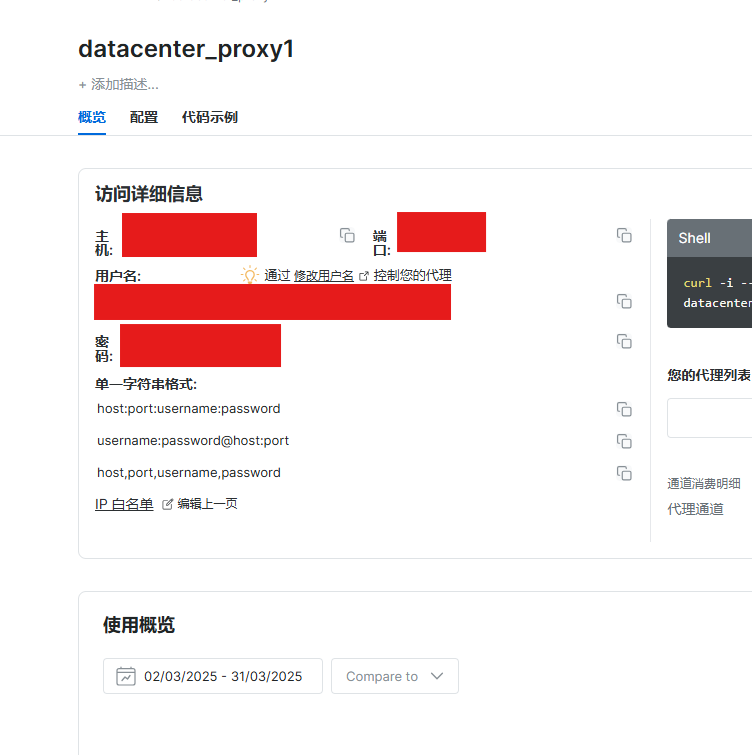
- 代理创建完成后,控制台会显示你在脚本中使用的所需参数,如主机、端口、用户名、密码等:
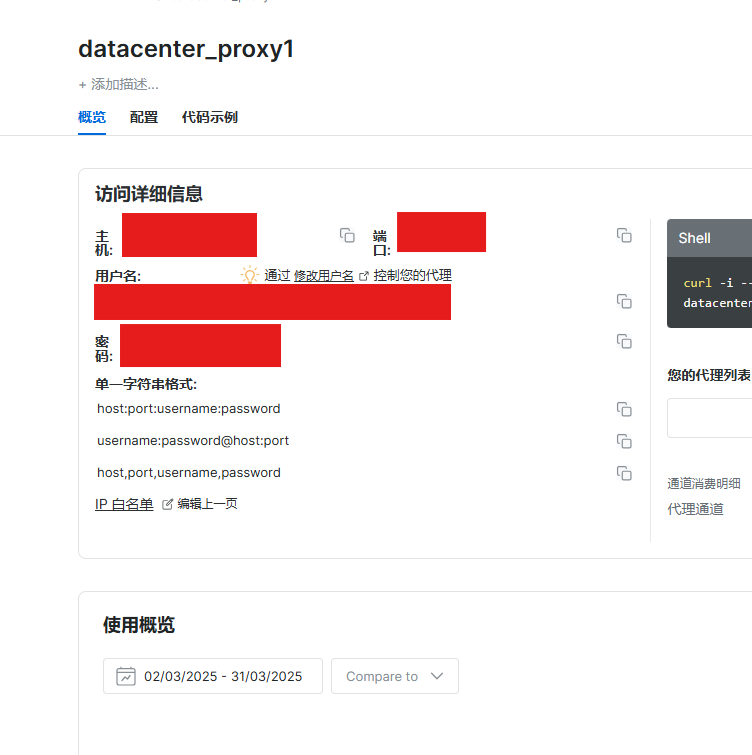
- 将这些参数复制到你的脚本中,并使用
username-(session-id)-password@host:port的格式来拼接代理 URL。
注意:
session-id是一个随机数,可以用 Python 的random库生成。
下面示例展示了如何在 Python 中使用一个来自 Bright Data 的代理:
import requests
from bs4 import BeautifulSoup
import random
# Define parameters provided by Brightdata
host = 'brd.superproxy.io'
port = 33335
username = 'username'
password = 'password'
session_id = random.random()
# format your proxy
proxy_url = ('http://{}-session-{}:{}@{}:{}'.format(username, session_id,
password, host, port))
# define your proxies in dictionary
proxies = {'http': proxy_url, 'https': proxy_url}
# Send a GET request to the website
url = "https://example.com/"
response = requests.get(url, proxies=proxies)
# Use BeautifulSoup to parse the HTML content of the website
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website
links = soup.find_all("a")
# Print all the links
for link in links:
print(link.get("href"))
运行此代码后,你就能通过 Bright Data 的 代理服务 成功地发送请求。
总结
通过 Bright Data 的 Web 平台,你可以获取到遍布全球各个国家和城市的可信代理,用于任何需要的项目。立即免费试用 Bright Data 的 代理服务 吧!

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)