
使用Python爬取链家二手房信息并保存到MongoDB与MySQL
在本教程中,我们将学习如何使用Python爬取链家网站的二手房信息,并将爬取的数据保存到两种不同的数据库:MongoDB和MySQL。这个过程将包括网页数据的抓取、数据解析、存储到数据库中,并展示如何在实际项目中应用这些技术。
使用Python爬取链家二手房信息并保存到MongoDB与MySQL 🏡💻
在本教程中,我们将学习如何使用Python爬取链家网站的二手房信息,并将爬取的数据保存到两种不同的数据库:MongoDB和MySQL。这个过程将包括网页数据的抓取、数据解析、存储到数据库中,并展示如何在实际项目中应用这些技术。
准备环境
确保您的环境中安装了以下库:
requests:用于发送HTTP请求。lxml:用于解析HTML文档。pymongo:用于操作MongoDB数据库。pymysql:用于操作MySQL数据库。
可以通过以下命令安装这些库:
pip install requests lxml pymongo pymysql
爬取链家二手房信息
我们将使用requests库来获取链家网站的二手房列表页面的HTML内容,然后利用lxml和XPath来解析需要的数据。
获取网页HTML
首先,定义一个方法来发送GET请求,获取二手房列表页面的HTML内容:
def get_html(self, url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
解析HTML
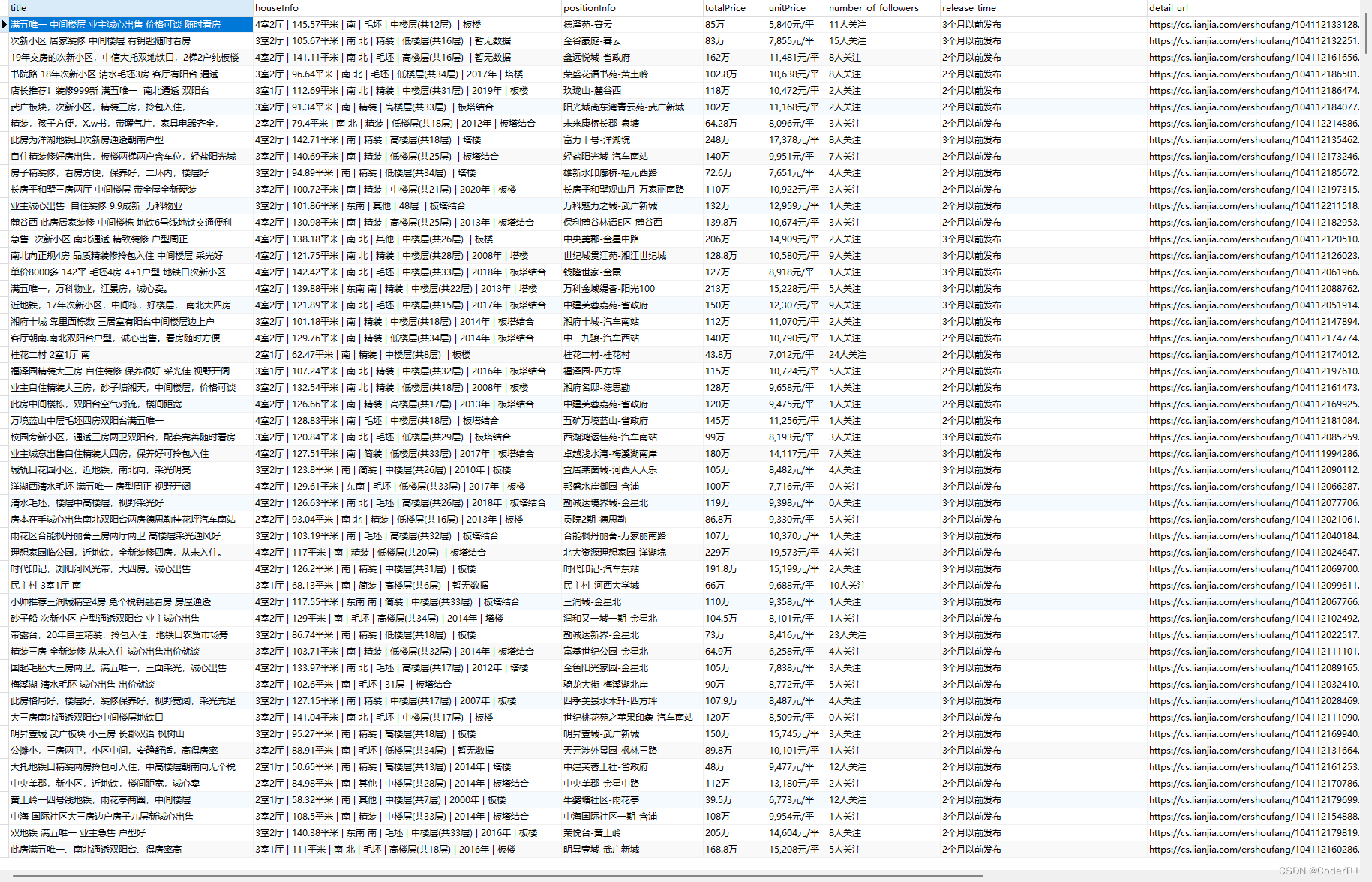
解析HTML,提取我们需要的二手房信息:
def parse_html(self, html):
ret = []
if html:
data = etree.HTML(html)
li_list = data.xpath('//ul[@class="sellListContent"]/li')
for li in li_list:
title = li.xpath('.//div[@class="title"]/a/text()')[0]
houseInfo = li.xpath('.//div[@class="houseInfo"]/text()')[0]
positionInfo = '-'.join(li.xpath('.//div[@class="positionInfo"]/a/text()'))
totalPrice = li.xpath('.//div[@class="totalPrice totalPrice2"]/span/text()')[0] + '万'
unitPrice = li.xpath('.//div[@class="unitPrice"]/span/text()')[0]
followInfo = li.xpath('.//div[@class="followInfo"]/text()')[0]
number_of_followers = followInfo.split('/')[0].strip()
release_time = followInfo.split('/')[1].strip()
detail_url = li.xpath('.//div[@class="title"]/a/@href')[0]
dic = {
'title': title,
'houseInfo': houseInfo,
'positionInfo': positionInfo,
'totalPrice': totalPrice,
'unitPrice': unitPrice,
'number_of_followers': number_of_followers,
'release_time': release_time,
'detail_url': detail_url
}
ret.append(dic)
return ret
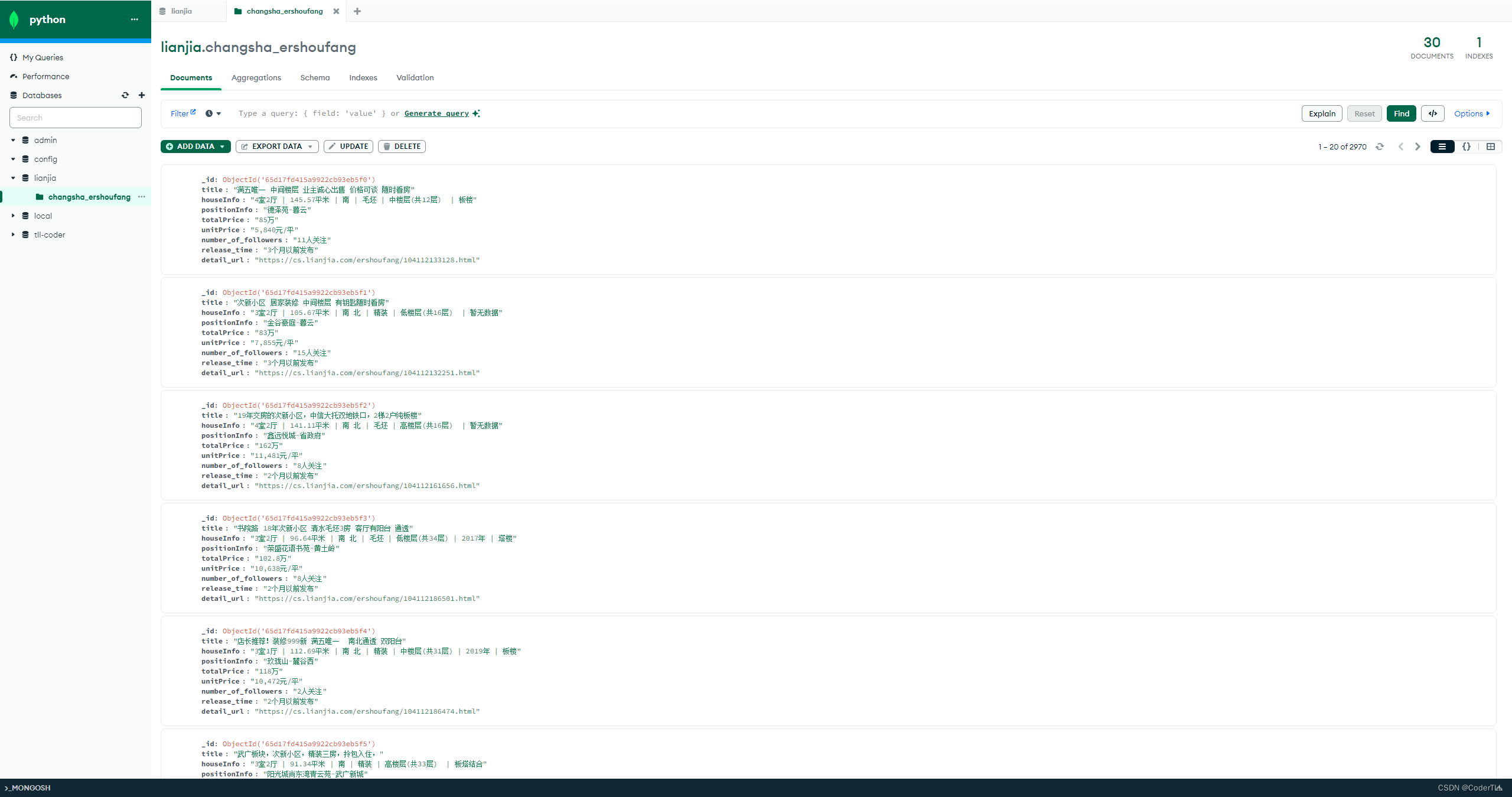
保存数据到MongoDB
我们使用pymongo库将解析后的数据保存到MongoDB中:
def save_mongo(self, list_data):
try:
mongoDB = self.client['lianjia']
collection = mongoDB['changsha_ershoufang']
collection.insert_many(list_data)
print("数据成功保存到MongoDB")
except Exception as e:
print(f"保存到MongoDB时发生错误: {e}")
保存数据到MySQL
使用pymysql库将相同的数据保存到MySQL数据库中。首先,确保你的MySQL服务器正在运行,并且已经创建了相应的数据库和表。
def insert(self, list_data):
try:
cursor = self.db.cursor()
sql = "INSERT INTO changsha_ershoufang (id, title, houseInfo, positionInfo, totalPrice, unitPrice, number_of_followers, release_time, detail_url, create_time) VALUES (%s, %s, %s, %s, %s, %s, %s
, %s, %s, %s)"
for data in list_data:
values = (
str(uuid.uuid4()), data['title'], data['houseInfo'], data['positionInfo'], data['totalPrice'],
data['unitPrice'], data['number_of_followers'], data['release_time'], data['detail_url'],
datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
)
cursor.execute(sql, values)
self.db.commit()
print("数据成功保存到MySQL")
except Exception as e:
print(f"保存到MySQL时发生错误: {e}")
self.db.rollback()
执行爬虫
最后,通过实例化上面定义的爬虫类并调用相应的方法来执行爬虫,爬取链家二手房信息,并将数据保存到MongoDB和MySQL数据库中。
if __name__ == '__main__':
spider = LianjiaSpiderMongoDB()
spider.saveAll() # 爬取并保存数据到MongoDB
LianjiaSpiderMySQL().saveAll() # 爬取并保存数据到MySQL
结论
通过本教程,我们学习了如何使用Python爬取网页数据,解析HTML,并将提取的数据保存到MongoDB和MySQL数据库中。这些技能对于数据抓取和持久化存储非常重要,可以应用于各种数据收集和分析项目中。
希望本教程能够帮助你理解和掌握使用Python进行数据爬取和存储的基本方法。继续探索和实践,你将能够解决更多复杂的数据处理问题。
获取完整代码
以上是使用Python爬取链家二手房信息并保存到MongoDB与MySQL的基本流程和代码示例。为了获取更详细的代码实现,包括所有的函数定义和错误处理,请访问以下GitHub仓库:
在这个仓库中,你将找到本教程相关的完整代码,以及更多有用的Python学习资源。这将帮助你更好地理解如何在实际项目中使用Python进行网络爬虫开发和数据持久化。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)