
双因素方差分析之Python实例
不同教育程度的事后多重比较和性别的单独效应(结论在注释里)3:查看数据分布:通过绘制箱线图,检测是否有异常点。进行方差分析的条件检验:正态性和方差齐性检验。经检测:p值均大于0.05,符合显著性要求。2:转成DataFrame格式并查看。绘图查看两个因素之间是否存在交互作用。结论:存在双因素交互作用。
·
第一步:创建数据:
import pandas as pd
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['KaiTi']
import warnings
warnings.filterwarnings("ignore")
data = [['Male', '高中及以下', 63.0],
['Male', '高中及以下', 64.0],
['Male', '高中及以下', 60.0],
['Male', '高中及以下', 63.0],
['Male', '高中及以下', 66.0],
['Male', '高中及以下', 65.0],
['Male', '高中及以下', 61.0],
['Male', '高中及以下', 62.0],
['Male', '高中及以下', 68.0],
['Male', '大学本科', 66.5],
['Male', '大学本科', 67.0],
['Male', '大学本科', 69.5],
['Male', '大学本科', 70.0],
['Male', '大学本科', 69.0],
['Male', '大学本科', 71.5],
['Male', '大学本科', 67.0],
['Male', '大学本科', 68.5],
['Male', '大学本科', 63.5],
['Male', '研究生及以上', 88.0],
['Male', '研究生及以上', 89.0],
['Male', '研究生及以上', 86.0],
['Male', '研究生及以上', 92.0],
['Male', '研究生及以上', 90.0],
['Male', '研究生及以上', 84.0],
['Male', '研究生及以上', 91.0],
['Male', '研究生及以上', 87.0],
['Male', '研究生及以上', 88.0],
['Male', '研究生及以上', 85.0],
['Female', '高中及以下', 65.0],
['Female', '高中及以下', 66.0],
['Female', '高中及以下', 61.0],
['Female', '高中及以下', 64.0],
['Female', '高中及以下', 69.0],
['Female', '高中及以下', 70.0],
['Female', '高中及以下', 67.0],
['Female', '高中及以下', 63.0],
['Female', '高中及以下', 63.0],
['Female', '高中及以下', 66.0],
['Female', '大学本科', 70.0],
['Female', '大学本科', 71.0],
['Female', '大学本科', 66.0],
['Female', '大学本科', 69.0],
['Female', '大学本科', 74.0],
['Female', '大学本科', 73.0],
['Female', '大学本科', 72.0],
['Female', '大学本科', 68.0],
['Female', '大学本科', 65.0],
['Female', '大学本科', 64.0],
['Female', '研究生及以上', 82.0],
['Female', '研究生及以上', 83.0],
['Female', '研究生及以上', 88.0],
['Female', '研究生及以上', 91.0],
['Female', '研究生及以上', 90.0],
['Female', '研究生及以上', 86.0],
['Female', '研究生及以上', 84.0],
['Female', '研究生及以上', 80.0],
['Female', '研究生及以上', 85.0],
['Female', '研究生及以上', 76.0]]2:转成DataFrame格式并查看
df = pd.DataFrame(data, columns = ['gender', 'education', 'Index'])
print(df)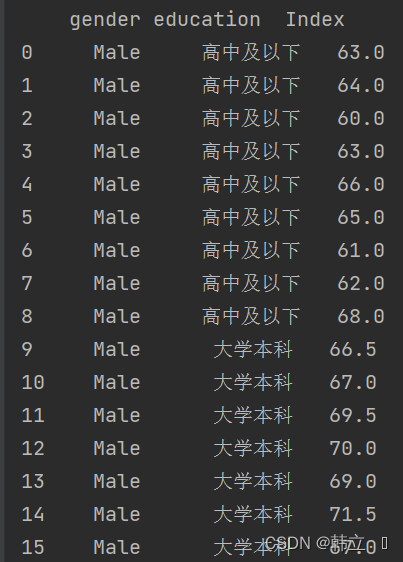
转换数据格式
df1 = pd.DataFrame()
data_list = []
for i in df.gender.unique():
for j in df.education.unique():
data = df[(df.gender == i)&(df.education == j)]['Index'].values
data_list.append(data)
df1 = df1.append(pd.DataFrame(data, columns = pd.MultiIndex.from_arrays([[i],[j]])).T)
df1 = df1.T
print(df1) 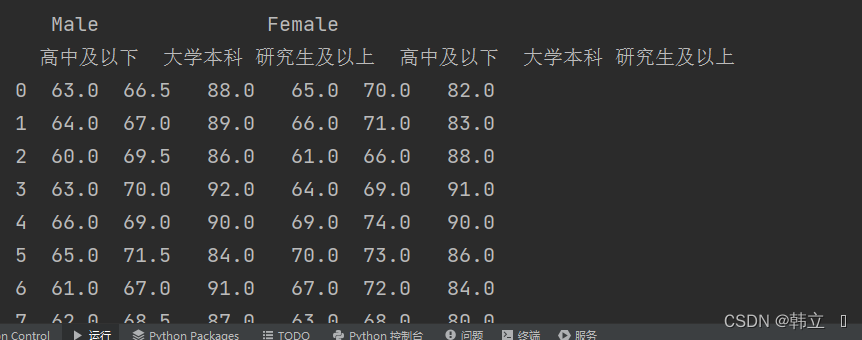
3:查看数据分布:通过绘制箱线图,检测是否有异常点
# 查看各组数量分布
print(df1.count())
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize = (12,8))
sns.boxplot(x = 'gender', y = 'Index', data = df, hue = 'education') # 传入的为DataFrame ,x, y,hue,可指定其索引
plt.show() 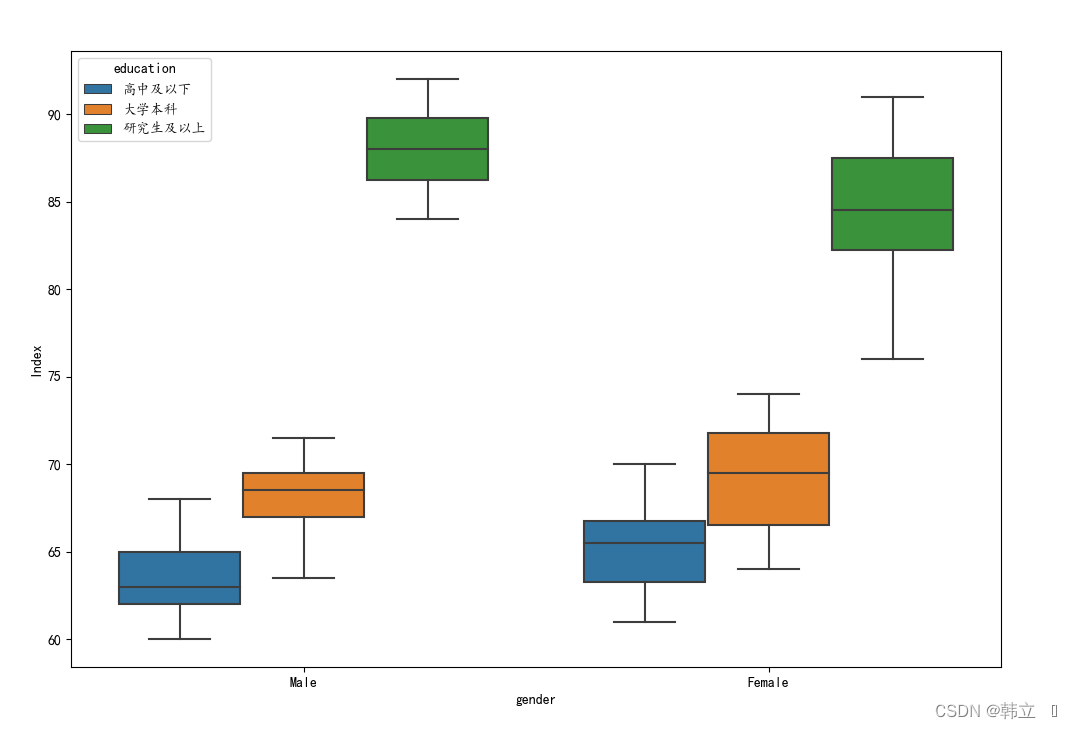
进行方差分析的条件检验:正态性和方差齐性检验。
from scipy import stats
# Shapiro-Wilk 检验(小数据量的正态分布检验) :正态检验(方差分析前提1)
sw_test_res = pd.DataFrame()
for i in df1.columns:
statistic, pvalue = stats.shapiro(df1[i].dropna())
sw_test_res[i] = [statistic, pvalue]
sw_test_res.index = ['statistic', 'p_value']
print(sw_test_res.T.round(3))
# levene test :方差齐性检验
print('基于中位数的levene test P值:', stats.levene(*data_list, center='median').pvalue) 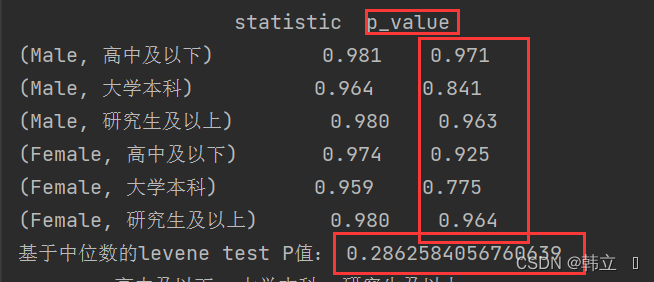
经检测:p值均大于0.05,符合显著性要求
进行交互作用判断:
# 判断交互作用
# df1.mean() # 为Series
df_mean = df1.mean().unstack().round(1) # unstack :分层索引重置方法将series换为DataFrame, 并保留数据小数点一位
df_mean.columns = ['大学本科', '研究生及以上', '高中及以下']
df_mean = df_mean[['高中及以下', '大学本科', '研究生及以上']]
print(df_mean) 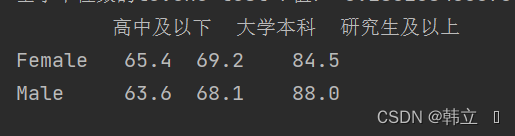
绘图查看两个因素之间是否存在交互作用
# 定义一个绘图函数
def draw_pics(data, feature):
fig, ax = plt.subplots(figsize=(8, 6))
for i in data.index:
ax.plot(data.columns, data.loc[i, :], label = i, marker='o')
ax.legend()
ax.set_title("幸福指数平均值")
ax.set_xlabel(feature, fontdict={'fontsize': 14})
ax.set_ylabel("平均值", fontdict={'fontsize': 14})
plt.show()
# 绘制不同的性别在不同的教育程度下的均值变化
draw_pics(df_mean, 'education')
# 结论:存在双因素交互作用
# 绘制不同的教育程度在不同的性别下的均值变化
draw_pics(df_mean.T, 'gender')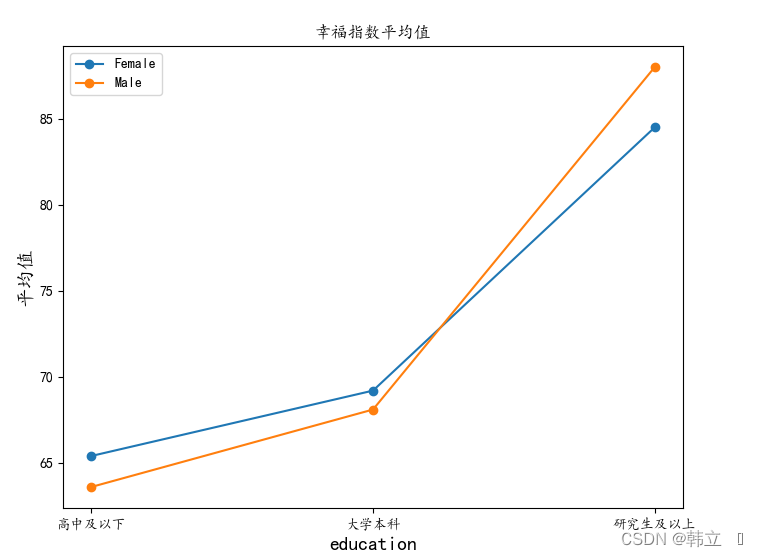
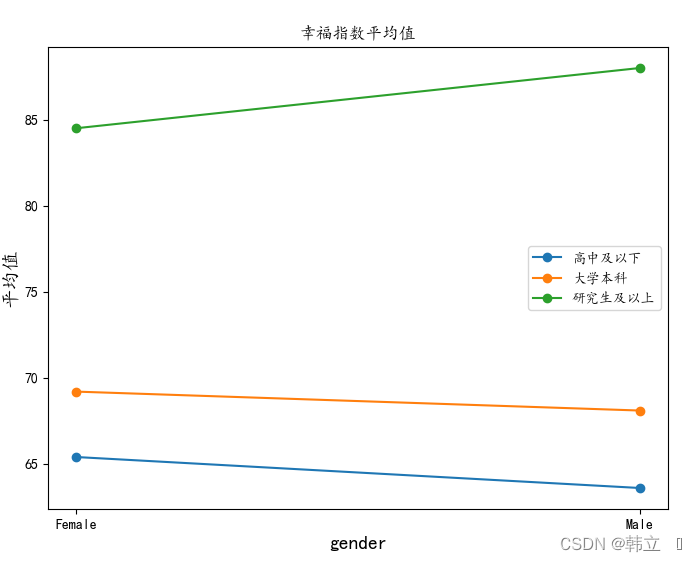
结论:存在双因素交互作用。
进行多因素方差分析(结论在注释里):
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
# 进行多因素方差分析
print(df)
anova = ols('Index ~ C(gender) + C(education) + C(gender)*C(education)',data = df).fit()
print(anova_lm(anova, typ=1))
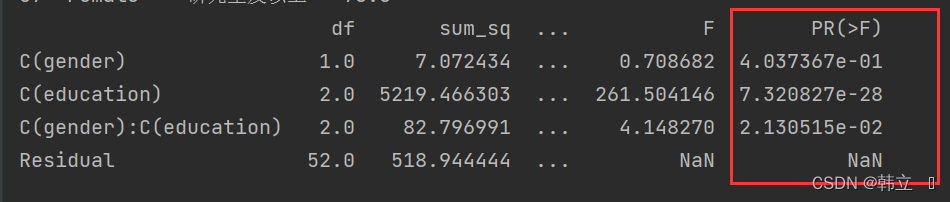
"""性别P = 0.404大于0.05,表明性别对幸福指数没有影响
教育P < 0.001,表明教育对于幸福指数有显著影响
交互项具F(2,52)=4.148,P= 0.021,有统计学意义,表明性别和受教育程度在对幸福指数的影响上存在交互作用
"""
import statsmodels.api as sm
# 不同教育程度的事后多重比较
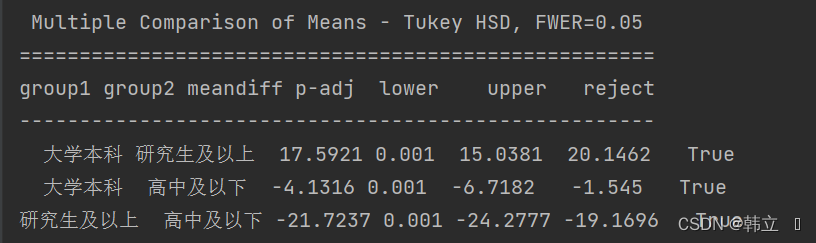
print(sm.stats.multicomp.pairwise_tukeyhsd(groups=df.education, endog=df.Index).summary())
"""大学本科学历 的幸福指数比 高中及以下学历 的人高4.13(95%CI:1.55-6.72),P=0.001;
研究生及以上学历 的幸福指数比 高中及以下学历 的人高21.72(95%CI:19.17-24.28),P<0.001;
研究生及以上学历 的幸福指数比 大学本科学历 的人高17.59(95%CI:15.04-20.15),P<0.001。
"""
不同教育程度的事后多重比较和性别的单独效应(结论在注释里)
import statsmodels.api as sm
# 不同教育程度的事后多重比较
print(sm.stats.multicomp.pairwise_tukeyhsd(groups=df.education, endog=df.Index).summary())
"""大学本科学历 的幸福指数比 高中及以下学历 的人高4.13(95%CI:1.55-6.72),P=0.001;
研究生及以上学历 的幸福指数比 高中及以下学历 的人高21.72(95%CI:19.17-24.28),P<0.001;
研究生及以上学历 的幸福指数比 大学本科学历 的人高17.59(95%CI:15.04-20.15),P<0.001。
"""
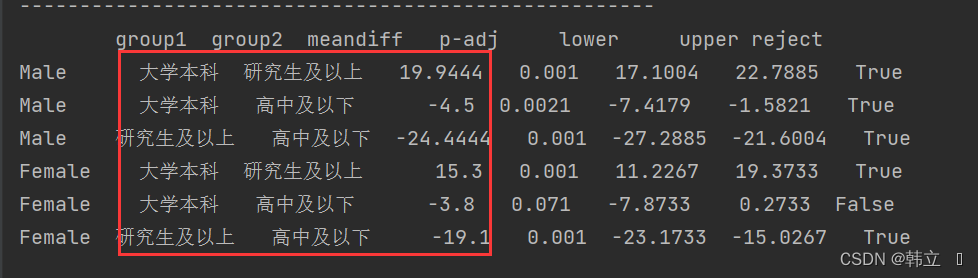
# 性别的单独效应
gender_pc_df = pd.DataFrame()
for i in df.gender.unique():
pc = sm.stats.multicomp.pairwise_tukeyhsd(groups = df.query("gender == @i").education,
endog=df.query("gender == @i").Index).summary()
pc_df = pd.DataFrame(pc, index = [i] * (df.education.nunique() + 1), )[1:]
gender_pc_df = gender_pc_df.append(pc_df)
gender_pc_df.columns = ['group1', 'group2', 'meandiff', 'p-adj', 'lower', 'upper', 'reject']
print(gender_pc_df)
"""男性中:
高中及以下学历 的幸福指数评分比 大学本科学历 的低4.50(95%CI:1.58 - 7.42),P = 0.0021;
高中及以下学历 的幸福指数评分比 研究生及以上学历 的低24.44(95%CI:21.60 - 27.29),P = 0.001。
大学本科学历 的幸福指数评分比 研究生及以上学历 的低19.94(95%CI:17.10 - 22.79),P = 0.001。
女性中:
高中及以下学历 的幸福指数评分比 大学本科学历 没有显著性差异,P = 0.071;
高中及以下学历 比 研究生及以上学历 的低19.10(95%CI:15.02 - 23.17),P = 0.001。
大学本科学历 的幸福指数评分比 研究生及以上学历 的低15.30(95%CI:11.23 - 19.37),P = 0.001。
"""

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)