
Python数据分析全流程实战:统计运算、可视化与SQLite数据库集成
本文以Python为核心工具,深入剖析pandas统计运算、分组聚合及matplotlib可视化技术,结合SQLite数据库实现数据高效管理。通过学生成绩分析案例,演示如何计算各科成绩极值、均值、及格率,存储至Excel与数据库,并利用饼图、折线图、散点图多维度展现数据规律,呈现从数据清洗、统计分析到可视化呈现与持久化存储的完整流程,为数据分析实践提供可复用的方法论与代码范例。
目录
- 前言
- 一、统计运算
- 二、分组与聚合
- 2.1 groupby
- 2.2 agg
- 三、数据可视化
- 3.1 plot
- 3.2 hist
- 四、数据库介绍
- 4.1 概念
- 4.2 分类
- 4.2.1 关系型数据库
- 4.2.2 非关系型数据库
- 4.3 sqlite特点
- 4.4 sqlite的数据类型
- 4.5 SQLite约束
- 五、表的创建与管理
- 5.1 创建表
- 5.2 删除表
- 5.3 修改表
- 5.3.1 修改表名
- 5.3.2 增加字段
- 六 、SQL语句
- 6.1 插入操作
- 6.2 删除操作
- 6.3 修改操作
- 6.4 查找操作
- 七、数据库软件工具
- 7.1 Python使用SQLite
- 7.2 常见函数
- 八、综合项目
- 总结
前言
书接上文
一、统计运算
count ( axis = 0 , numeric_only = False )功能:用于计算 DataFrame 中非 NaN 值的数量
参数:axis:统计的方向,0:按列,1:按行
sum(axis=0, skipna=True, numeric_only=False, min_count=0)
功能:用于计算 DataFrame 中数值的总和
参数:axis: 统计的方向,0:按列,1:按行
skipna: 布尔值,默认为 True,则在计算总和时会忽略 NaN 值。
numeric_only: 布尔值,默认为 False。如果为 True,则只对数值列进行求和,忽略非数值列。
min_count: int,默认为 0。这个参数指定了在计算总和之前,至少需要非 NaN 值的最小数量。如果某个分组中的非 NaN 值的数量小于 `min_count`,则结果为 NaN。
mean(axis=0, skipna=True, numeric_only=False, **kwargs)
功能:用于计算 DataFrame 中数值的平均值
min(axis=0, skipna=True, numeric_only=False, **kwargs)
功能:用于计算 DataFrame 中数值的最小值
max(axis=0, skipna=True, numeric_only=False, **kwargs)
功能:用于计算 DataFrame 中数值的最大值。
var(axis=0, skipna=True, ddof=1, numeric_only=False, **kwargs)
功能:用于计算 DataFrame 中数值的方差
std(axis=0, skipna=True, ddof=1, numeric_only=False, **kwargs)
功能:用于计算 DataFrame 中数值的标准差
quantile(q=0.5, axis=0, numeric_only=False, interpolation='linear', method='single')
功能:计算 DataFrame 中数值的分位数。
describe(percentiles=None, include=None, exclude=None)
功能:生成DataFrame中数值列的统计摘要,会返回一个DataFrame
返回值:包括计数、平均值、标准差、最小值、25%分位数、50%分位数(中位数)、75%分位数和最大值等。
value_counts(subset=None, normalize=False, sort=True, ascending=False, dropna=True)
功能:用于计算Series中各个值出现的频率或个数的一个方法。
参数:subset:可选参数,用于指定要进行计算操作的列名列表。如果未指定,则对整个DataFrame的所有列进行操作。
normalize:布尔值,默认为False。如果设置为True,则返回每个值的相对频率,而不是计数。
sort:布尔值,如果设置为True,则结果将按计数值降序排序。
ascending:布尔值,当`sort=True`时,此参数指定排序顺序。如果设置为True,则结果将按计数值升序排序。
dropna:布尔值,如果设置为True,则在计数之前排除缺失值。
# 导入 pandas 库并使用 pd 作为别名
import pandas as pd
# 创建包含缺失值(None)的原始数据(注意:实际应使用 np.nan 表示数值型缺失值)
data = [[95, None, 88], [None, 98, 77], [77, 88, 99]]
columns = ["语文", "数学", "英语"] # 定义列名
index = ["张三", "李四", "王五"] # 定义行索引(学生姓名)
# 创建 DataFrame 对象(表格数据结构)
df = pd.DataFrame(data, columns=columns, index=index)
print(df) # 打印原始数据表格(自动对齐,NaN 表示缺失值)
print()
# 统计每列非空值的数量(默认排除NaN)
print(df.count()) # 注意数学列有2个有效值,其他列有3个
print()
# 统计语文列各数值的出现次数(包含NaN时需要指定 dropna=False)
print(df.value_counts("语文")) # 显示95和77各出现1次,NaN不计数
print()
# 计算每列的总和(自动跳过NaN)
print(df.sum()) # 语文:95+77=172,数学:98+88=186,英语:88+77+99=264
print()
# 计算每列的平均值(默认跳过NaN)
print(df.mean()) # 语文:172/2=86,数学:186/2=93,英语:264/3=88
print()
# 获取每列的最小值
print(df.min()) # 语文77,数学88,英语77
print()
# 获取每列的最大值
print(df.max()) # 语文95,数学98,英语99
print()
# 计算每列的方差(样本方差,自由度为n-1)
print(df.var())
print()
# 计算每列的标准差
print(df.std()) # 方差的平方根
print()
# 计算分位数:25%(第一四分位)、50%(中位数)、75%(第三四分位)
print(df.quantile([0.25, 0.5, 0.75])) # 生成分位数统计表
print()
# 生成描述性统计汇总(包含计数、均值、标准差、最小值、四分位数、最大值)
print(df.describe()) # 快速查看数据分布
print()D:\python_huanjing\.venv1\Scripts\python.exe C:\Users\98317\PycharmProjects\study_python\study_1\study.py
语文 数学 英语
张三 95.0 NaN 88
李四 NaN 98.0 77
王五 77.0 88.0 99
语文 2
数学 2
英语 3
dtype: int64
语文
77.0 1
95.0 1
Name: count, dtype: int64
语文 172.0
数学 186.0
英语 264.0
dtype: float64
语文 86.0
数学 93.0
英语 88.0
dtype: float64
语文 77.0
数学 88.0
英语 77.0
dtype: float64
语文 95.0
数学 98.0
英语 99.0
dtype: float64
语文 162.0
数学 50.0
英语 121.0
dtype: float64
语文 12.727922
数学 7.071068
英语 11.000000
dtype: float64
语文 数学 英语
0.25 81.5 90.5 82.5
0.50 86.0 93.0 88.0
0.75 90.5 95.5 93.5
语文 数学 英语
count 2.000000 2.000000 3.0
mean 86.000000 93.000000 88.0
std 12.727922 7.071068 11.0
min 77.000000 88.000000 77.0
25% 81.500000 90.500000 82.5
50% 86.000000 93.000000 88.0
75% 90.500000 95.500000 93.5
max 95.000000 98.000000 99.0
进程已结束,退出代码为 0二、分组与聚合
2.1 groupby
DataFrame . groupby ( by = None , axis = 0 , level = None , as_index = True , sort = True , group_keys = True , observed = False , dropna = True )功能:用于将数据分组,并允许对这些分组进行操作
参数:by:是一个键(列名)、键的列表或函数,用于分组
axis:用于分组的轴
返回值:是一个 DataFrameGroupBy 对象,是一个可以对分组数据进行进一步操作的对象
DataFrameGroupBy.get_group(分组名)
功能:根据分组名获取分组后的数据
# 导入 pandas 库并使用 pd 作为别名(数据处理常用库)
import pandas as pd
# 创建包含分组数据和数值的字典
data = {
'Abc' : ['A', 'B', 'A', 'B', 'C', 'A', 'C', 'B'], # 分组标签列
'Value1': [10, 20, 30, 40, 50, 60, 70, 80], # 第一组数值数据
'Value2': [1, 2, 3, 4, 5, 6, 7, 8] # 第二组数值数据
}
# 将字典转换为 DataFrame 数据结构(二维表格)
df = pd.DataFrame(data)
print("原始数据集:")
print(df)
print() # 打印空行分隔输出
# 按 'Abc' 列进行分组,返回分组对象(此时尚未进行计算)
ret = df.groupby("Abc")
# 对分组后的数据执行求和计算并输出
print("按 Abc 分组求和结果:")
print(ret.sum())
print()
# 获取并输出 'A' 组的所有数据
print("Abc=A 的分组数据:")
print(ret.get_group("A"))
print()D:\python_huanjing\.venv1\Scripts\python.exe C:\Users\98317\PycharmProjects\study_python\study_1\study.py
原始数据集:
Abc Value1 Value2
0 A 10 1
1 B 20 2
2 A 30 3
3 B 40 4
4 C 50 5
5 A 60 6
6 C 70 7
7 B 80 8
按 Abc 分组求和结果:
Value1 Value2
Abc
A 100 10
B 140 14
C 120 12
Abc=A 的分组数据:
Abc Value1 Value2
0 A 10 1
2 A 30 3
5 A 60 6
进程已结束,退出代码为 02.2 agg
DataFrame . agg ( func = None , axis = 0 , * args , ** kwargs )功能:用于对数据进行聚合操作
参数:func:可以是一个函数、函数列表或函数字典。用于指定聚合操作。
axis:0,表示按行聚合;如果设置为 1,则按列聚合。
# 导入 pandas 库并使用 pd 作为别名(用于数据操作和分析的核心库)
import pandas as pd
# 创建包含分组数据和数值的字典
data = {
'Value1': [10, 20, 30, 40, 50, 60, 70, 80], # 第一组数值数据,共8个元素
'Value2': [1, 2, 3, 4, 5, 6, 7, 8] # 第二组数值数据,共8个元素
}
# 使用字典数据创建 DataFrame 对象(二维表格型数据结构)
df = pd.DataFrame(data)
# 打印原始 DataFrame(默认显示前5行和后5行,共8行数据)
print(df)
print() # 打印空行分隔不同输出结果
# 使用 agg 方法进行聚合计算:对所有列应用求和操作
# 输出结果形式为 Series 对象,显示每列的总和
print(df.agg('sum'))
print()
# 对每列同时应用多个聚合函数:最大值、总和、最小值
# 输出结果形式为 DataFrame,行索引为聚合函数名,列名为原始列名
print(df.agg(["max", "sum", "min"]))
print()
# 对指定列应用不同的聚合函数:Value1列求和,Value2列取最大值
# 使用字典格式指定 {列名: 聚合函数} 的映射关系
# 输出结果形式为 Series 对象,只包含指定的列和对应的聚合结果
print(df.agg({"Value1": "sum", "Value2": "max"}))D:\python_huanjing\.venv1\Scripts\python.exe C:\Users\98317\PycharmProjects\study_python\study_1\study.py
Value1 Value2
0 10 1
1 20 2
2 30 3
3 40 4
4 50 5
5 60 6
6 70 7
7 80 8
Value1 360
Value2 36
dtype: int64
Value1 Value2
max 80 8
sum 360 36
min 10 1
Value1 360
Value2 8
dtype: int64
进程已结束,退出代码为 0三、数据可视化
用于绘制 DataFrame 数据图形,它允许用户直接从 DataFrame 创建各种类型的图表,而不需要使用其他绘图库(底层实际上使用了 Matplotlib)。
3.1 plot
DataFrame.plot(*args, **kwargs)
功能:绘制各种线图
参数:kind: 图表类型,可以是以下之一:
'line': 折线图(默认)
'bar': 柱状图
'barh': 水平柱状图
'hist': 直方图
'box': 箱线图
'kde': 核密度估计图
'area': 面积图
'pie': 饼图
'scatter': 散点图
'hexbin': 六边形箱图
ax: Matplotlib 轴对象,用于在指定的轴上绘制图表。如果不提供,则创建新的轴对象。
subplots:是否绘制子图,True绘制子图
figsize: 图表的尺寸,格式为 `(width, height)`,单位为英寸。
use_index: 是否使用 pandas 的索引作为 x 轴标签。默认为 `True`。
title: 图表的标题。
grid: 是否显示网格线。默认为 `False`。
legend: 是否显示图例。默认为 `True`。
xticks: x 轴的刻度位置。
yticks: y 轴的刻度位置。
xlim: x 轴的范围,格式为 `(min, max)`。
ylim: y 轴的范围,格式为 `(min, max)`。
color: 绘制颜色,可以是单个颜色或颜色列表。
label: 图例标签。
# 导入数据处理和分析库pandas,并使用pd作为别名
import pandas as pd
# 导入科学计算库numpy(虽然在本代码中未实际使用),使用np作为别名
import numpy as np
# 导入数据可视化库matplotlib的pyplot模块,使用plt作为别名
import matplotlib.pyplot as plt
# 创建一个包含示例数据的DataFrame对象
# DataFrame是pandas中用于存储表格数据的二维数据结构
df = pd.DataFrame(
{
'A': [1, 2, 3, 4, 5], # 创建名为A的列,包含5个整数值
'B': [10, 20, 30, 40, 50], # 创建名为B的列,数值是A列数值的10倍
'C': [100, 200, 300, 400, 500] # 创建名为C的列,数值是A列数值的100倍
}
)
# 使用DataFrame的内置绘图方法绘制图表
# 默认会绘制所有数值列的折线图(x轴为索引,y轴为各列数值)
df.plot()
# 显示绘制好的图表
# 这个命令会弹出一个包含图表的GUI窗口,在脚本中必须调用才能显示图像
plt.show()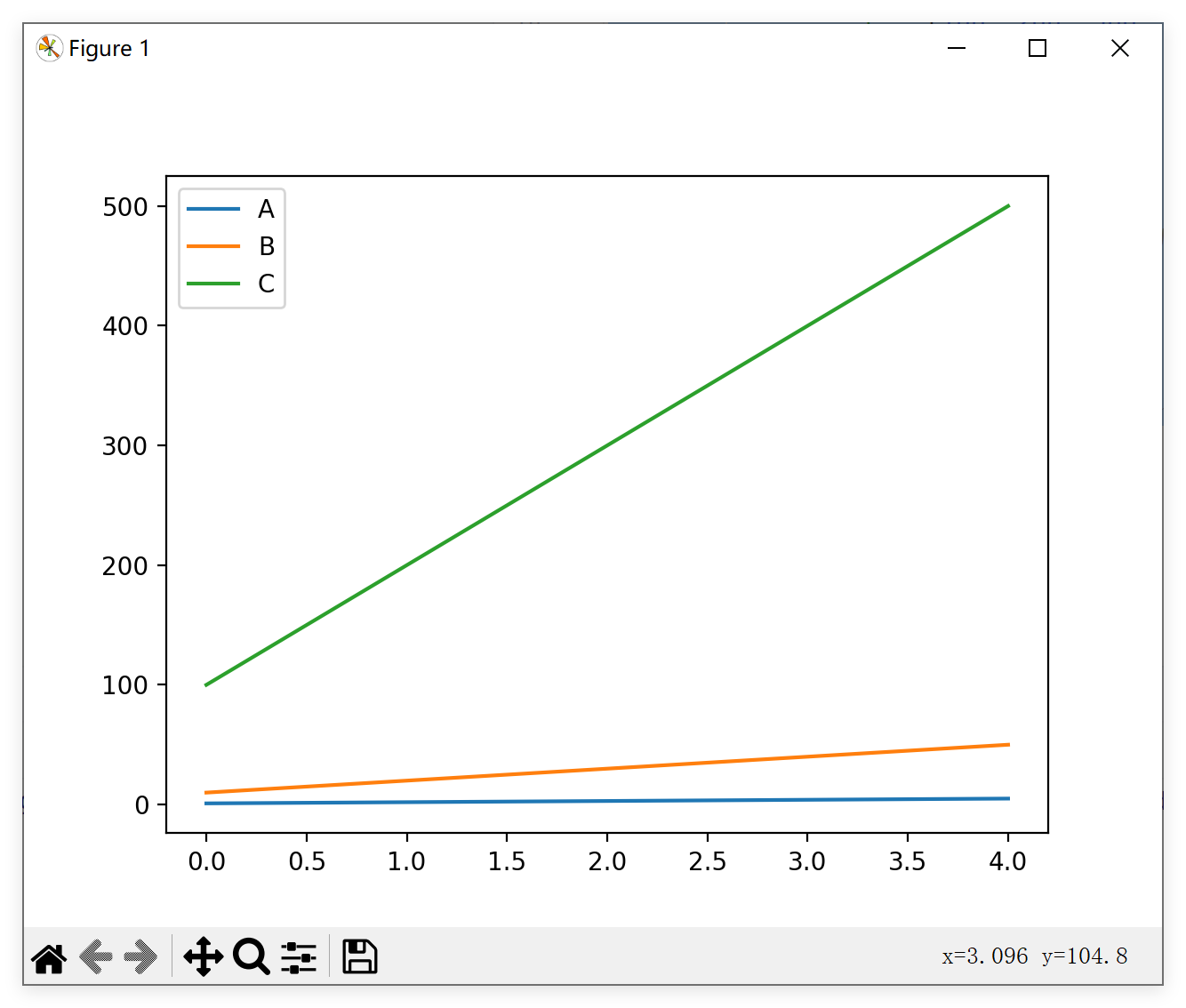
3.2 hist
DataFrame.hist(column=None,by=None, grid=True, xlabelsize=None, xrot=None, ylabelsize=None, yrot=None, ax=None, sharex=False, sharey=False,figsize=None, layout=None,bins=10, backend=None, legend=False, **kwargs)
功能:绘制Series数据直方图
参数:column:可选。用于指定要绘制直方图的列
by: 如果不是None,则将数据分组并分别绘制每个组的直方图。
grid: 布尔值,默认为True,表示是否在直方图上显示网格线。
xlabelsize: int或str,用于设置x轴标签的字体大小。
xrot: int或float,用于设置x轴标签的旋转角度。
ylabelsize: int或str,用于设置y轴标签的字体大小。
yrot: int或float,用于设置y轴标签的旋转角度。
ax: matplotlib的Axes对象,如果指定了,直方图将绘制在该Axes上。
sharex: 布尔值,默认为 False。如果为 True,并且绘制多个直方图,则所有直方图共享相同的 x 轴
sharey: 布尔值,默认为 False。如果为 True,并且绘制多个直方图,则所有直方图共享相同的 y 轴
figsize: 元组,用于设置直方图的大小,格式为 (width, height)。
bins: int或序列,用于设置直方图的柱子数量或具体的边界。
backend: 用于指定绘图后端,通常Pandas会使用matplotlib。
legend: 布尔值,默认为False,表示是否在直方图上显示图例。
**kwargs: 其他关键字参数,将被传递给matplotlib的`hist`函数
四、数据库介绍
4.1 概念
数据库(Database)是结构化存储数据的集合,用于高效管理、检索和操作数据。它提供了一种系统化的方式存储信息,并通过软件工具支持数据的增删改查、事务处理、安全控制等功能。
4.2 分类
4.2.1 关系型数据库
特点:基于表格(行和列)存储数据,支持 SQL 语言,强调 ACID 特性(原子性、一致性、隔离性、持久性)
代表:Oracle、MySQL、SQL server、Sqlite
4.2.2 非关系型数据库
特点:灵活的数据模型,支持非结构化/半结构化数据,扩展性强,牺牲部分一致性换取性能。
代表:Redis、MongoDB、HBase
4.3 sqlite特点
- 一种轻量级的开源数据库,文件小运行速度快
- 主要用于本地数据存储,无需独立服务器
- SQLite是以文件进行存储的,数据库文件格式为.db
- python内置sqlite3,无需安装第三方库
4.4 sqlite的数据类型
大多数数据库都使用严格的静态类型(静态类型意味着数据的类型是在定义数据结构(如表结构)时就确定好的),值的类型通过列来决定。SQLite使用的是动态类型系统,值的数据类型只与值本身有关。
以下是SQLite的存储类:
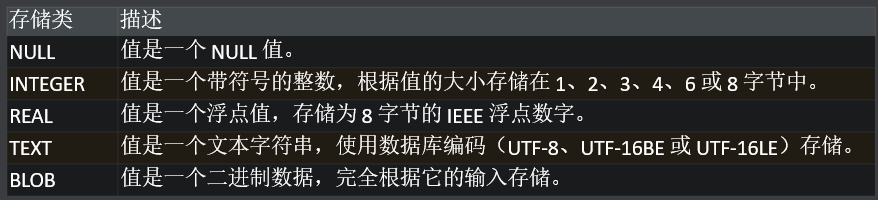
4.5 SQLite约束

例子:在创建一个表时的结构
CREATE TABLE nb(
mid INTEGER UNIQUE,
name TEXT NOT NULL,
age INTEGER CHECK(age>=18),
sex TEXT DEFAULT('男女'),
home TEXT PRIMARY KEY,
job TEXT DEFAULT '无业游民'
);五、表的创建与管理
5.1 创建表
语法格式:
CREATE TABLE table_name(
column1 datatype PRIMARY KEY(one or more columns),
column2 datatype,
column3 datatype,
.....
columnN datatype,
);例子:
CREATE TABLE IF NOT EXISTS COMPANY(
ID INTEGER PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INTEGER NOT NULL,
SALARY REAL
);补充:IF NOT EXISTS的作用在创建表之前检查表是否已经存在。如果表已经存在,那么 SQL 语句不会执行创建操作,也不会报错;如果表不存在,则会正常创建表。
5.2 删除表
语法格式:
DROP TABLE table_name;
5.3 修改表
5.3.1 修改表名
语法格式如下:
ALTER TABLE [旧表名] RENAME TO [新表名]
5.3.2 增加字段
语法格式如下:
ALTER TABLE [表名] ADD COLUMN [列名] [数据类型] [默认值]例子:
ALTER TABLE COMPANY ADD COLUMN address TEXT DEFAULT '银荷大厦';注意:SQLite不支持修改和删除字段,如果要删除或修改,只能通过重新建表的方式
六 、SQL语句
6.1 插入操作
SQLite的插入操作有两种基本语法格式:
格式一:给所有的字段添加数据
INSERT INTO TABLE_NAME VALUES (value1,value2,,...valueN);例子:
INSERT INTO COMPANY VALUES (7, 'James', 24, 10000.00 );格式二:指定字段添加数据
INSERT INTO TABLE_NAME [(column1,...columnN)] VALUES (value1,...valueN);例子:
INSERT INTO COMPANY (ID,NAME)VALUES (6, 'Kim');6.2 删除操作
语法格式如下:
DELETE FROM table_name WHERE [condition];例子:
# 删除所有记录
DELETE FROM COMPANY;
# 删除ID=7的记录
DELETE FROM COMPANY WHERE ID = 7;
# 删除ID=7且AGE<20的记录
DELETE FROM COMPANY WHERE ID = 7 AND AGE < 20;补充:ADN/OR运算符
两个运算符被称为连接运算符
AND 运算符允许在一个 SQL 语句的 WHERE 子句中存在多个条件。使用 AND 运算符时,只有当所有条件都为真(true)时,整个条件为真(true)。例如,只有当 condition1 和 condition2 都为真(true)时,[condition1] AND [condition2] 为真(true)
OR 运算符也用于结合一个 SQL 语句的 WHERE 子句中的多个条件。使用 OR 运算符时,只要当条件中任何一个为真(true)时,整个条件为真(true)。例如,只要当 condition1 或 condition2 有一个为真(true)时,[condition1] OR [condition2] 为真(true)
6.3 修改操作
语法格式如下:
UPDATE table_name SET column1 = value1,...,columnN = valueN
WHERE [condition];例子:
# 把所有的AGE字段的值都改为20
UPDATE COMPANY SET AGE = 20
# 把条件ID=6的AGE和SALARY字段进行修改
UPDATE COMPANY SET AGE = 20, SALARY = 4000 WHERE ID = 6;6.4 查找操作
语法格式有二种如下:
格式一:查找所有字段
SELECT * FROM table_name;格式二:只查找指定的字段
SELECT column1, column2, columnN FROM table_name;例子:
# 查找所有
SELECT * FROM COMPANY;
# 查找表中字段为ID、NAME、SALARY的信息
SELECT ID, NAME, SALARY FROM COMPANY;
# 查找条件ID=7的字段
SELECT * FROM COMPANY WHERE ID = 7;七、数据库软件工具
windows下使用SQLiteSpy工具,可以查看数据库、执行SQL指令
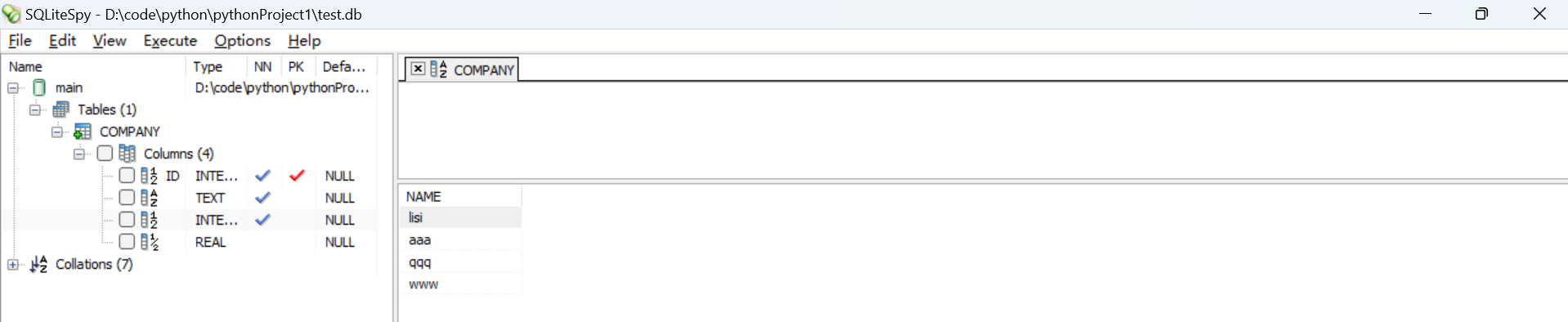
7.1 Python使用SQLite
使用前先导入库import sqlite3
7.2 常见函数
Connection = sqlite3.connect(database)
功能:打开一个到 SQLite 数据库文件 database 的连接
参数:database:数据库文件名,以.db为后缀
返回值:一个连接对象Connection
Cursor = connection.cursor([cursorClass])
功能:通过连接对象获得游标对象
返回值:一个游标对象,用于执行具体的 SQL 操作
cursor.execute(sql [, optional parameters])
功能:执行SQL语句,可以被参数化
参数:sql:SQL语句,当用占位符?时需要有第二个参数
optional parameters:占位符具体的数据,用列表或元组表示
cursor.executemany(sql, seq_of_parameters)
功能:对 seq_of_parameters 中的所有参数或映射执行一个 SQL 命令
参数:sql:SQL语句
seq_of_parameters:占位符具体的多个数据,用列表或元组表示
connection.commit()
功能:提交当前的事务,如果未调用该方法,那么对数据库操作是无效的
即:执行SQL的增删改查操作时必须调用commit
cursor.fetchall()
功能:获取查询结果集中所有的行
返回值:返回一个包含一条或多条记录的列表
cursor.close()
功能:关闭游标操作
connection.close()
功能:关闭数据库连接补充:游标是一种用于数据库操作的数据选择工具,用于执行具体的 SQL 操作
示例代码
import sqlite3 as sq
# 打开一个到 SQLite 数据库文件的连接
con = sq.connect("./test.db")
# 通过连接对象获得游标对象
curses = con.cursor()
# 创建表
sql = """
CREATE TABLE IF NOT EXISTS COMPANY(
ID INTEGER PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INTEGER NOT NULL,
SALARY REAL
);
"""
# 执行SQL语句
curses.execute(sql)
# 插入操作
# 方式一:
sql = """
INSERT INTO COMPANY VALUES(
1, 'zhangsan', 19, 4000
);
"""
# curses.execute(sql)
# 方式二:插入一条数据,被参数化
# 参数化,参数1:用?进行占位 参数2:占位符对应的数据
# data = ['lisi', 20, 5000]
# curses.execute("INSERT INTO COMPANY VALUES(2,?,?,?)", data)
# 方式三:插入多条数据
# data = [[1, 'lisi', 20], [2, 'zhangsan', 30]]
# curses.executemany("INSERT INTO COMPANY (ID, NAME, age) VALUES(?,?,?);", data)
# 删除数据
# curses.execute("DELETE FROM COMPANY WHERE age<20;")
# 修改数据
# curses.execute("UPDATE COMPANY SET age=30 WHERE SALARY>2000;")
# 查找数据
curses.execute("SELECT * FROM COMPANY;")
val = curses.fetchall()
# print(val)
for row in val:
print(row)
# 提交
con.commit()
# 关闭游标
curses.close()
# 关闭连接
con.close()八、综合项目
根据给定的学生成绩进行数据统计与分析,基本功能如下:
计算每门课程的最高分、最低分、平均分、及格率
将以上数据存储在当前excel的一个新的sheet中
将以上数据存储在数据库中
根据每门课程的及格率绘制饼图进行呈现
根据C语言成绩的前5名绘制其成绩走势折线图
import pandas as pd
import matplotlib.pyplot as plt
import sqlite3 as sql
import warnings
warnings.filterwarnings("ignore") #忽略警告
exc_c = pd.read_excel("学生成绩信息表.xlsx") #c基础表
exc_shu = pd.read_excel("学生成绩信息表.xlsx", sheet_name=1) #数据结构表
exc_32 = pd.read_excel("学生成绩信息表.xlsx", sheet_name=2) #STM32表
exc_cjia = pd.read_excel("学生成绩信息表.xlsx", sheet_name=3) #C++表
exc_huizong = pd.read_excel("学生成绩信息表.xlsx", sheet_name=4) #汇总表
#c语言的最高分、最低分、平均分、及格率
excl = pd.DataFrame(exc_c) #将c基础表转换为DataFrame格式
cj = excl.loc[:, "考试成绩"] #提取c语言考试成绩列
cmax = cj.max() #求c语言考试成绩的最大值
cmin = cj.min() #求c语言考试成绩的最小值
cmean = cj.mean() #求c语言考试成绩的平均值
#求c语言考试成绩及格率
excl_shu = pd.DataFrame(exc_shu) #将数据结构表转换为DataFrame格式
c_pass = excl.loc[(excl["考试成绩"] >= 60), "考试成绩"] #c语言考试成绩及格人数
c_pass = len(c_pass) / len(cj) * 100 #c语言考试成绩及格率
#数据结构最高分、最低分、平均分、及格率
shu = excl_shu.loc[:, "考试成绩"] #提取数据结构考试成绩列
shumax = shu.max() #求数据结构考试成绩的最大值
shumin = shu.min() #求数据结构考试成绩的最小值
shumean = shu.mean() #求数据结构考试成绩的平均值
shu_pass = excl_shu.loc[(exc_shu["考试成绩"] >= 60), "考试成绩"] #数据结构考试成绩及格人数
shu_pass = len(shu_pass) / len(shu) * 100 #数据结构考试成绩及格率
#STM32最高分、最低分、平均分、及格率
stm32 = pd.DataFrame(exc_32) #将STM32表转换为DataFrame格式
stm32 = stm32.loc[:, "考试成绩"] #提取STM32考试成绩列
stm32max = stm32.max() #求STM32考试成绩的最大值
stm32min = stm32.min() #求STM32考试成绩的最小值
stm32mean = stm32.mean() #求STM32考试成绩的平均值
stm32_pass = exc_32.loc[(exc_32["考试成绩"] >= 60), "考试成绩"] #STM32考试成绩及格人数
stm32_pass = len(stm32_pass) / len(stm32) * 100 #STM32考试成绩及格率
#C++最高分、最低分、平均分、及格率
cjia = pd.DataFrame(exc_cjia) #将C++表转换为DataFrame格式
cjia = cjia.loc[:, "考试成绩"] #提取C++考试成绩列
cjiamax = cjia.max() #求C++考试成绩的最大值
cjiamin = cjia.min() #求C++考试成绩的最小值
cjiamean = cjia.mean() #求C++考试成绩的平均值
cjia_pass = exc_cjia.loc[(exc_cjia["考试成绩"] >= 60), "考试成绩"] #C++考试成绩及格人数
cjia_pass = len(cjia_pass) / len(cjia) * 100 #C++考试成绩及格率
#汇总表最高分、最低分、平均分、及格率
data = [[cmax, cmin, cmean, c_pass], [shumax, shumin, shumean, shu_pass], [stm32max, stm32min, stm32mean, stm32_pass],
[cjiamax, cjiamin, cjiamean, cjia_pass]] #填入的数据
col = ["最高分", "最低分", "平均分", "及格率"] #设置列名
index = ["C语言", "数据结构", "STM32", "C++"] #设置行名
df = pd.DataFrame(data, index=index, columns=col) #创建汇总表的内容
with pd.ExcelWriter(
"学生成绩信息表.xlsx", mode="a", if_sheet_exists='replace'
) as writer: #保存的前置内容,用来追加
df.to_excel(writer, sheet_name="汇总") #保存为excel文件
#将学生成绩信息表中的数据保存到数据库中
con = sql.connect("学生成绩汇总.db") #创建数据库连接
cur = con.cursor() #创建游标
data = pd.read_excel("学生成绩信息表.xlsx", sheet_name="汇总") #读取数据
data.to_sql("汇总", con, if_exists="replace") #将数据保存到数据库中
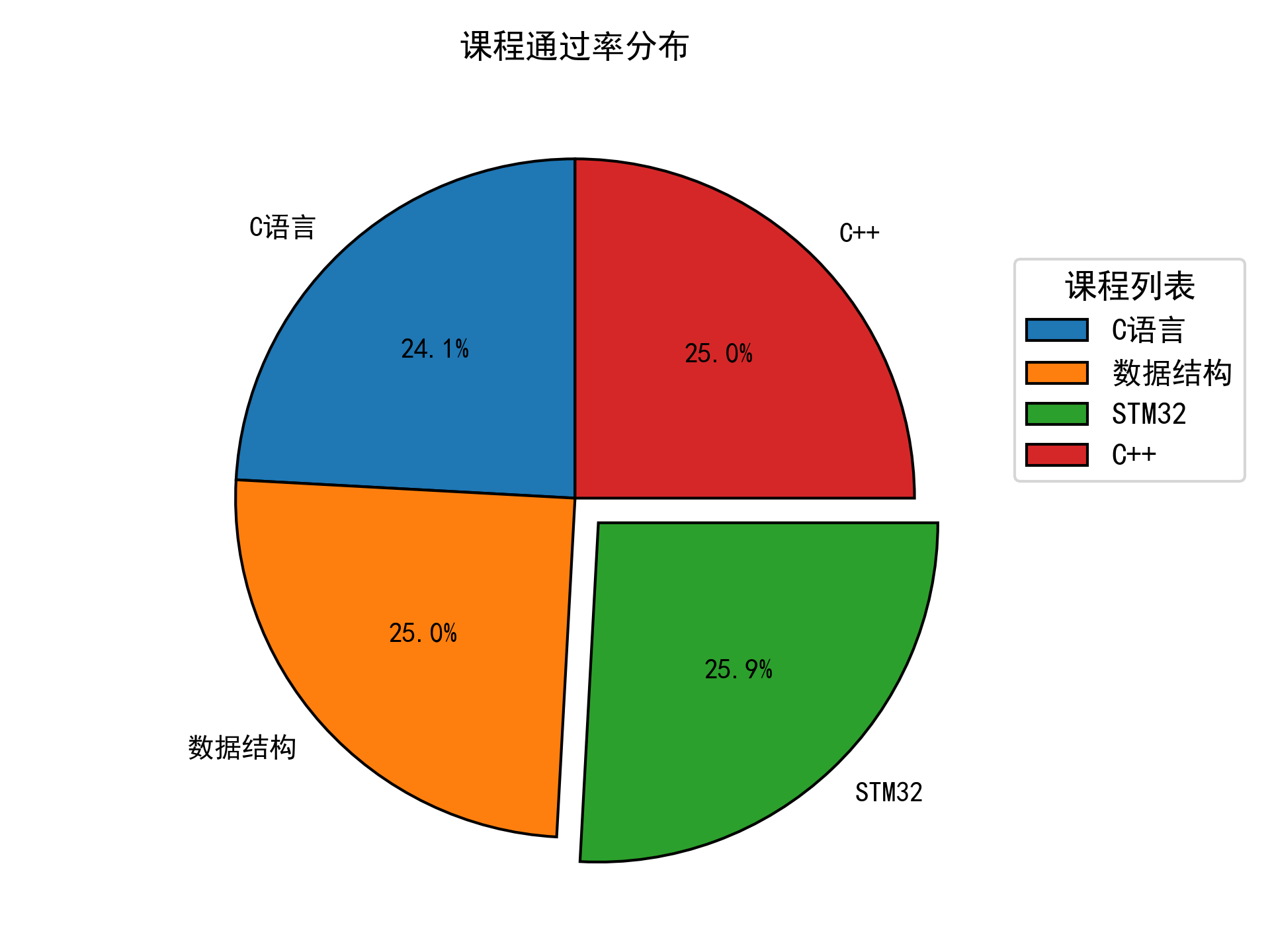
#对每门成绩的及格率绘制饼图
# 设置字体类型能支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 设置显示负数异常
plt.rcParams['axes.unicode_minus'] = False
labels = ["C语言", "数据结构", "STM32", "C++"] #设置标签
sizes = [c_pass, shu_pass, stm32_pass, cjia_pass] #设置大小
explode = (0, 0, 0.1, 0) #设置突出显示
plt.pie(
sizes, explode=explode, labels=labels, startangle=90, wedgeprops={'linewidth': 1, 'edgecolor': 'black'},
autopct='%1.1f%%'
) #绘制饼图
plt.legend(
title="课程列表",
loc='upper left',
bbox_to_anchor=(1, 0.8), # 图例位置调整
title_fontsize=12,
fontsize=11
)
plt.title("课程通过率分布") #设置标题
plt.tight_layout()
plt.savefig("课程通过率饼图.png", dpi=300) #保存图片
plt.pause(2) #显示饼图
plt.close()
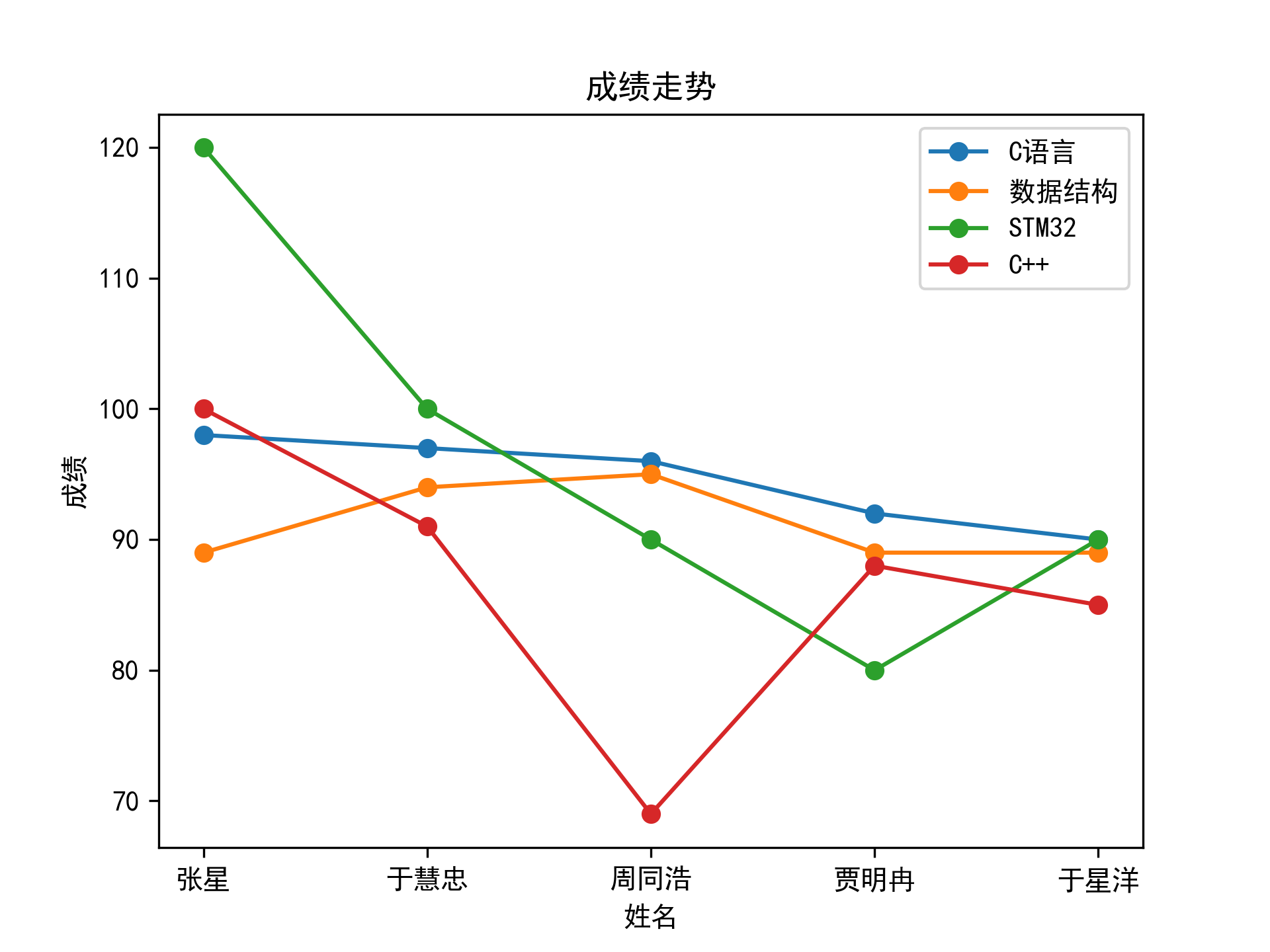
#根据C语言成绩的前5名绘制其成绩走势折线图
#对c语言成绩进行排序
cp = cj.sort_values(ascending=False) #对c语言成绩进行降序排序
c = cp.head(5) #取前5名
datac = c.index #提取成绩排名的前缀
datashu = excl_shu.loc[datac, "考试成绩"]
data32 = exc_32.loc[datac, "考试成绩"]
datacjia = exc_cjia.loc[datac, "考试成绩"]
cn = excl.loc[datac, "姓名"]
#设置折线图
plt.plot(cn, c, label="C语言", marker='o')
plt.plot(cn, datashu, label="数据结构", marker='o')
plt.plot(cn, data32, label="STM32", marker='o')
plt.plot(cn, datacjia, label="C++", marker='o')
plt.legend() #显示图例
plt.xlabel("姓名") #设置x轴标签
plt.ylabel("成绩") #设置y轴标签
plt.title("成绩走势") #设置标题
plt.savefig("成绩走势折线图.png", dpi=300) #保存图片
plt.pause(2) #显示饼图
plt.close()
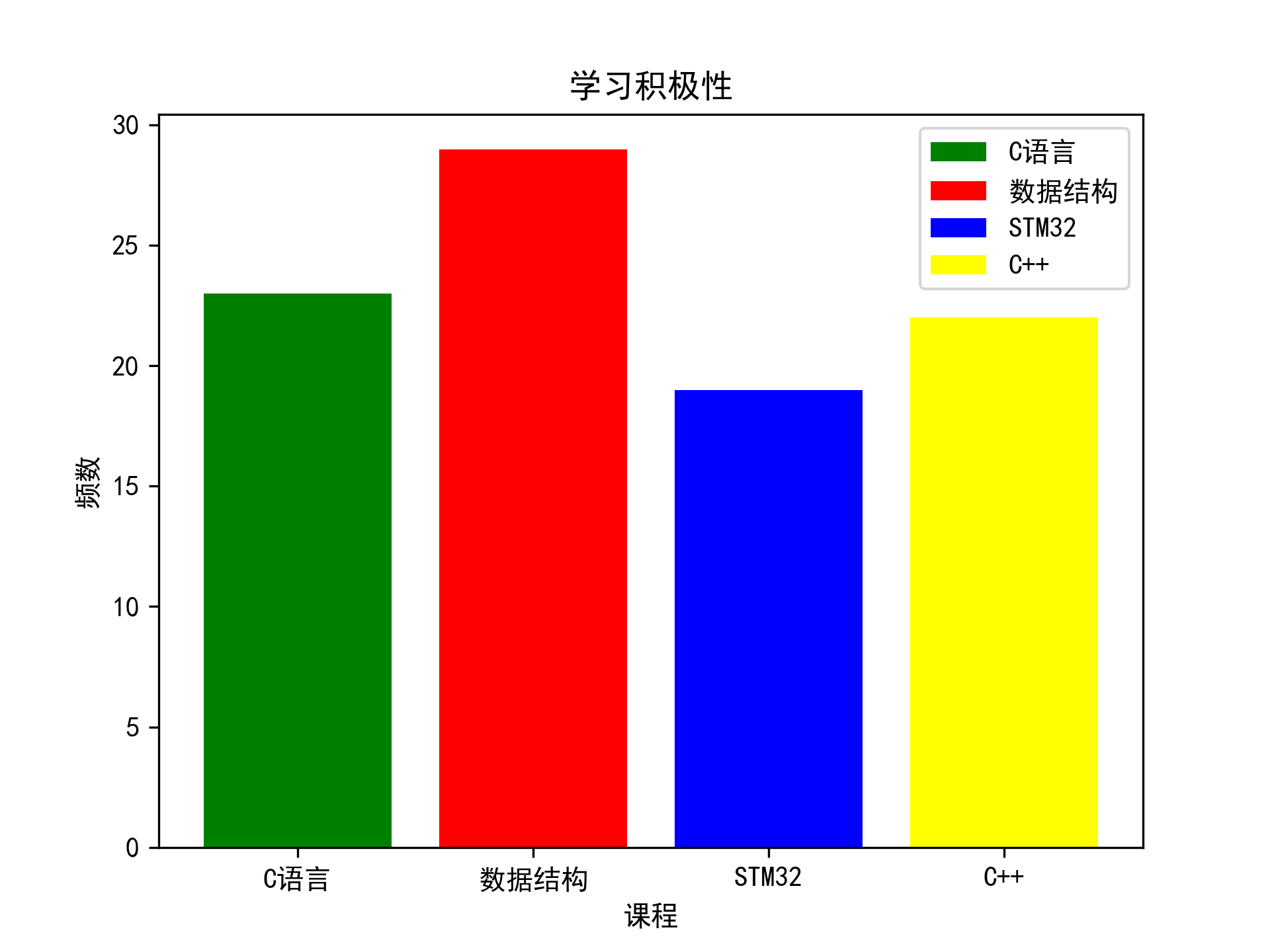
#查看学生的学习积极性
#设置字体类型能支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 设置显示负数异常
plt.rcParams['axes.unicode_minus'] = False
cx = excl["学习积极性"].value_counts() #提取学习积极性的频数
sx = excl_shu["学习积极性"].value_counts() #提取学习积极性的频数
stx = exc_32["学习积极性"].value_counts() #提取学习积极性的频数
ccx = exc_cjia["学习积极性"].value_counts() #提取学习积极性的频数
data = ["C语言", "数据结构", "STM32", "C++"]
data1 = [cx["A"], sx["A"], stx["A"], ccx["A"]]
plt.bar(data, data1, color=['green', 'red', 'blue', 'yellow'], label=data) #绘制柱状图
plt.xlabel("课程") #设置x轴标签
plt.ylabel("频数") #设置y轴标签
plt.title("学习积极性") #设置标题
plt.legend()
plt.savefig("学习积极性.png", dpi=300) #保存图片
plt.pause(2) #显示饼图
plt.close()
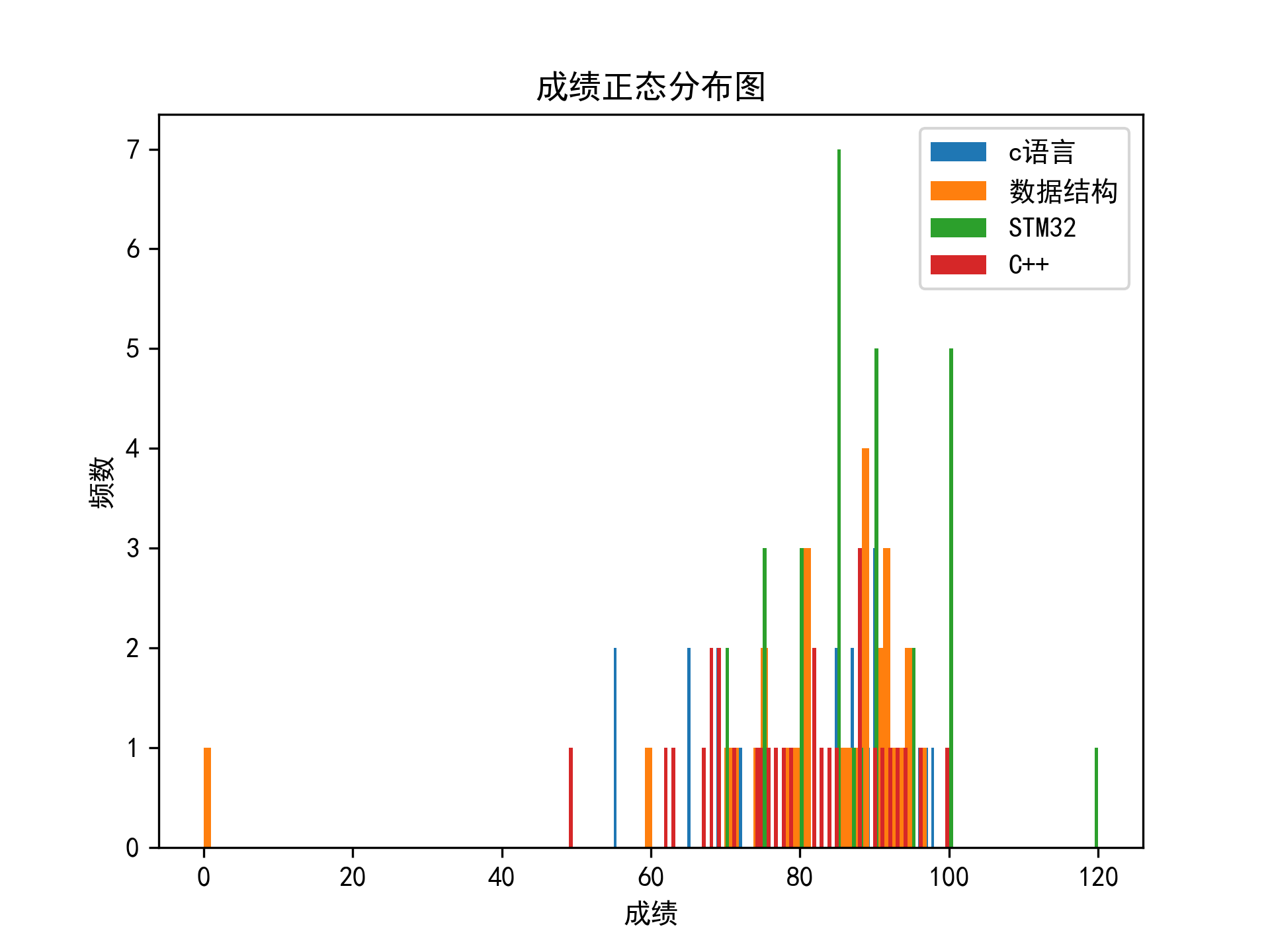
#绘制c语言成绩的正态分布图
# 设置字体类型能支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 设置显示负数异常
plt.rcParams['axes.unicode_minus'] = False
#绘制正态分布图
plt.hist(cj, bins=100, label="c语言")
plt.hist(shu, bins=100, label="数据结构")
plt.hist(stm32, bins=100, label="STM32")
plt.hist(cjia, bins=100, label="C++")
plt.legend()
plt.xlabel("成绩") #设置x轴标签
plt.ylabel("频数") #设置y轴标签
plt.title("成绩正态分布图") #设置标题
plt.savefig("成绩正态分布图.png", dpi=300) #保存图片
plt.pause(2) #显示饼图
plt.close()
"""
————————————绘制总图——————————————
"""
#对每门成绩的及格率绘制饼图
plt.subplot(2, 2, 1)
# 设置字体类型能支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 设置显示负数异常
plt.rcParams['axes.unicode_minus'] = False
labels = ["C语言", "数据结构", "STM32", "C++"] #设置标签
sizes = [c_pass, shu_pass, stm32_pass, cjia_pass] #设置大小
explode = (0, 0, 0.1, 0) #设置突出显示
plt.pie(
sizes, explode=explode, labels=labels, startangle=90, wedgeprops={'linewidth': 1, 'edgecolor': 'black'},
autopct='%1.1f%%'
) #绘制饼图
plt.legend(
title="课程列表",
loc='upper left',
bbox_to_anchor=(1, 0.8), # 图例位置调整
title_fontsize=12,
fontsize=11
)
plt.title("课程通过率分布") #设置标题
plt.tight_layout()
#根据C语言成绩的前5名绘制其成绩走势折线图
plt.subplot(2, 2, 2)
#对c语言成绩进行排序
cp = cj.sort_values(ascending=False) #对c语言成绩进行降序排序
c = cp.head(5) #取前5名
datac = c.index #提取成绩排名的前缀
datashu = excl_shu.loc[datac, "考试成绩"]
data32 = exc_32.loc[datac, "考试成绩"]
datacjia = exc_cjia.loc[datac, "考试成绩"]
cn = excl.loc[datac, "姓名"]
#设置折线图
plt.plot(cn, c, label="C语言", marker='o')
plt.plot(cn, datashu, label="数据结构", marker='o')
plt.plot(cn, data32, label="STM32", marker='o')
plt.plot(cn, datacjia, label="C++", marker='o')
plt.legend(fontsize=6) #显示图例
plt.xlabel("姓名") #设置x轴标签
plt.ylabel("成绩") #设置y轴标签
plt.title("成绩走势") #设置标题
plt.subplot(2, 2, 3)
#查看学生的学习积极性
#设置字体类型能支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 设置显示负数异常
plt.rcParams['axes.unicode_minus'] = False
cx = excl["学习积极性"].value_counts() #提取学习积极性的频数
sx = excl_shu["学习积极性"].value_counts() #提取学习积极性的频数
stx = exc_32["学习积极性"].value_counts() #提取学习积极性的频数
ccx = exc_cjia["学习积极性"].value_counts() #提取学习积极性的频数
data = ["C语言", "数据结构", "STM32", "C++"]
data1 = [cx["A"], sx["A"], stx["A"], ccx["A"]]
plt.bar(data, data1, color=['green', 'red', 'blue', 'yellow'], label=data) #绘制柱状图
plt.xlabel("课程") #设置x轴标签
plt.ylabel("频数") #设置y轴标签
plt.title("学习积极性") #设置标题
plt.legend(fontsize=6)
#绘制c语言成绩的正态分布图
plt.subplot(2, 2, 4)
# 设置字体类型能支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 设置显示负数异常
plt.rcParams['axes.unicode_minus'] = False
#绘制正态分布图
plt.hist(cj, bins=100, label="c语言")
plt.hist(shu, bins=100, label="数据结构")
plt.hist(stm32, bins=100, label="STM32")
plt.hist(cjia, bins=100, label="C++")
plt.legend()
plt.xlabel("成绩") #设置x轴标签
plt.ylabel("频数") #设置y轴标签
plt.title("成绩正态分布图") #设置标题
plt.tight_layout()
plt.savefig("学生成绩分析.png", bbox_inches='tight', dpi=300) #保存图片
plt.show()
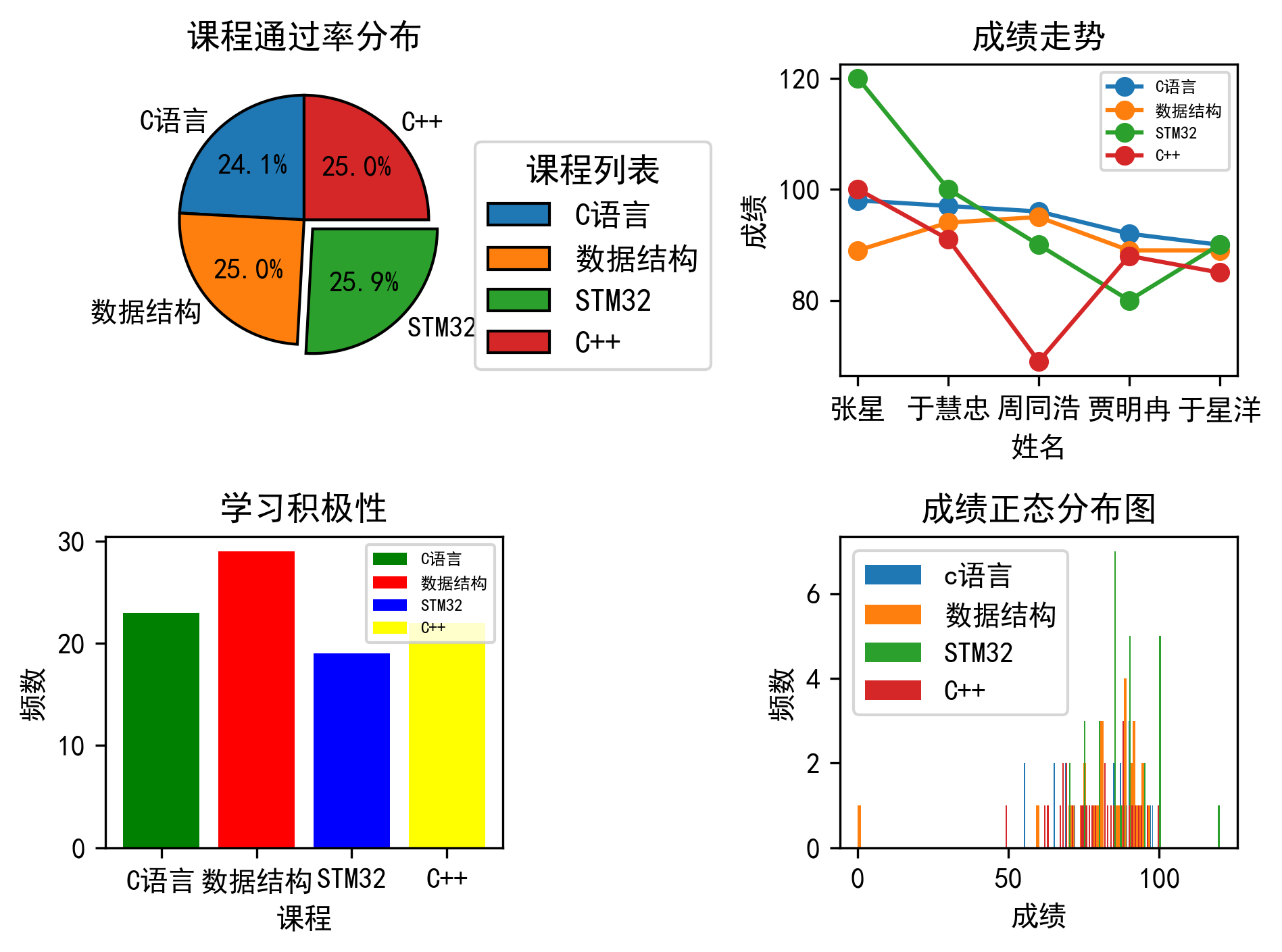
总结
本文系统讲解了使用Python进行数据统计、分组聚合及可视化的全流程技术,结合pandas库实现数据清洗、统计运算(如计数、求和、均值、方差、分位数等),利用groupby与agg完成高效分组聚合,并借助matplotlib绘制折线图、饼图等直观呈现数据分布。针对数据存储与管理,详细解析SQLite轻量级数据库的特性、数据类型及SQL操作(增删改查),通过Python代码示例演示表创建、数据插入、查询及事务处理。最后通过综合案例实战,整合Excel数据解析、多维度统计指标计算、数据库持久化存储及动态可视化图表生成,完整展现从数据处理到分析决策的技术闭环,为读者提供一站式数据分析解决方案。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 30
30 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)