
Flask搭建服务(四):gunicorn使得http服务并发执行
gunicorn是一个python Wsgi http server,只支持在Unix系统上运行,来源于Ruby的unicorn项目。Gunicorn使用prefork master-worker模型(在gunicorn中,master被称为arbiter),能够与各种wsgi web框架协作。gunicorn的文档是比较完善的,这里也有部分中文翻译。
背景:
经过前面一二三文章的范例,现在服务搭建好了,一个裸奔的服务,以及上线。对线上服务,我们必须考虑下服务的性能。如果多个请求发过来,可能会发生进程堵塞,然后服务挂掉,那么我们希望能该服务可以并发请求。
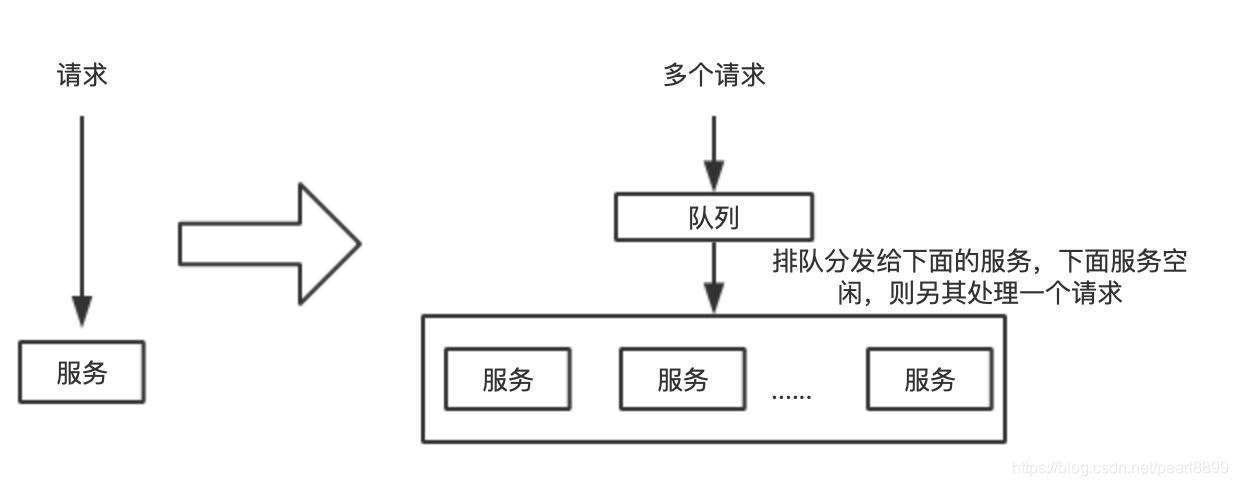
解决:
使用gunicorn。
gunicorn是一个python Wsgi http server,只支持在Unix系统上运行,来源于Ruby的unicorn项目。Gunicorn使用prefork master-worker模型(在gunicorn中,master被称为arbiter),能够与各种wsgi web框架协作。gunicorn的文档是比较完善的,这里也有部分中文翻译。
1.gunicorn是什么
Gunicorn 是一个 unix 上被广泛使用的高性能的 Python WSGI UNIX HTTP Server。和大多数的 web 框架兼容,并具有实现简单,轻量级,高性能等特点。
Gunicorn是一个WSGI HTTP服务器,python自带的有个web服务器,叫做wsgiref,Gunicorn的优势在于,它使用了pre-fork worker模式,gunicorn在启动时,会在主进程中预先fork出指定数量的worker进程来处理请求,gunicorn依靠操作系统来提供负载均衡,推进的worker数量是(2*$num_cores)+1
我们知道,python是单线程的语言,当进程阻塞时,后续请求将排队处理。所用pre-fork worker模式,极大提升了服务器请求负载。
2.gunicorn怎么用
flask+gunicorn,下面记录一下gunicorn的配置使用。
安装gunicorn
pip install gunicorn
gunicorn -h # 查看使用的命令gunicorn启动一个flask的应用程序
# app.py
from flask import Flask
def create_app():
app = Flask(__name__)
return app
app = create_app()
@app.route('/')
def index():
return 'hello world!'
if __name__ == '__main__':
app.run() 在flask的项目的目录下启动:
# -w 4 ——worker个数
-b 0.0.0.0:8000 ——bind,IP和端口号
第一个app指的是app.py文件,第二个指的是flask应用的名字
gunicorn -w 4 -b 0.0.0.0:8000 app:appgunicorn的参数详解
常用的就是上面的-w、 -b
gunicorn配置项可以通过gunicorn的启动命令行中设定,也可以通过配置文件指定。强烈建议使用一个配置文件。
配置项如下:
server socket
bind:监听地址和端口。
backlog:服务器中在pending状态的最大连接数,即client处于waiting的数目。超过这个数目, client连接会得到一个error。建议值64-2048。
worker 进程
workers:worker进程的数量。建议值2-4 x $(NUM_CORES), 缺省为1。
worker_class:worker进程的工作方式。 有 sync, eventlet, gevent, tornado, gthread, 缺省值sync。
threads:工作进程中线程的数量。建议值2-4 x $(NUM_CORES), 缺省值1。此配置只适用于gthread 进程工作方式, 因为gevent这种使用的是协程工作方式。
worker_connections:客户端最大同时连接数。只适用于eventlet, gevent工作方式。
max_requests:worker重启之前处理的最大requests数, 缺省值为0表示自动重启disabled。主要是防止内存泄露。
max_requests_jitter:抖动参数,防止worker全部同时重启。
timeout:通常设为30。
graceful_timeout:接收到restart信号后,worker可以在graceful_timeout时间内,继续处理完当前requests。
keepalive:server端保持连接时间。
security
limit_request_line:http request line最大字节数。值范围0-8190, 0表示无限制。
limit_request_field:http request中 header字段数的最大值。缺省为100,最大32768。
limit_request_field_size:http request header字段最大字节数。0表示无限制。
调试
reload:当代码有修改时,自动重启workers。适用于开发环境。
reload_extra_files:扩展reload配置,增加templates,configurations等文件修改监控。
spew:跟踪程序执行的每一行。
check_config:检查配置。
server 机制
sendfile:系统底层拷贝数据方式,提供performance。
chdir:在app加载之前,进入到此目录。
daemon:应用是否以daemon方式运行。
raw_env:key=value, 传递环境参数。
pidfile:pid存储文件路径。
worker_tmp_dir:临时工作目录。
user:指定worker进程的运行用户名。
group:指定worker进程运行用户所在组。
umask:gunicorn创建文件的缺省权限。
pythonpath:附加到python path的目录列表。
日志:accesslog
访问日志文件路径。
access_log_format:日志格式。 例如 %(h)s %(l)s %(u)s %(t)s "%(r)s" %(s)s %(b)s "%(f)s" "%(a)s" 。
errorlog:错误日志路径。
loglever:日志级别。debug, info, warning, error, critical.
capture_output:重定向stdout/stderr到error log file。
logger_class:日志实现类。缺省gunicorn.glogging.Logger 。
logconfig:日志配置文件。同python标准日志模块logging的配置。
以配置文件的方式启动
# gunicorn.conf
# 并行工作进程数
workers = 4
# 指定每个工作者的线程数
threads = 2
# 监听内网端口5000
bind = '127.0.0.1:5000'
# 设置守护进程,将进程交给supervisor管理
daemon = 'false'
# 工作模式协程
worker_class = 'gevent'
# 设置最大并发量
worker_connections = 2000
# 设置进程文件目录
pidfile = '/var/run/gunicorn.pid'
# 设置访问日志和错误信息日志路径
accesslog = '/var/log/gunicorn_acess.log'
errorlog = '/var/log/gunicorn_error.log'
# 设置日志记录水平启动gunicorn
运行环境linux系统,不支持window系统
gunicorn -c gunicorn.conf app:app参考:
1.使用例子:https://www.cnblogs.com/cwp-bg/p/8780204.html
2.读了源码:https://www.cnblogs.com/xybaby/p/6296974.html
3.ab压测对比(无gunicorn VS 有gunicorn):https://zhuanlan.zhihu.com/p/102716258
4.gunicorn是什么:https://www.leiue.com/what-is-gunicorn-green-unicorn

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)