
python实现LDA主题分类模型
python实现LDA主题分类模型
·
LDA(Latent Dirichlet Allocation)是一种常用的主题模型,它可以帮助我们从大量文本数据中发现隐藏的主题信息。需要的库
import pandas as pd
import matplotlib.pyplot as plt
import jieba
import jieba.posseg as pseg
from gensim.corpora import Dictionary
from gensim.models import LdaModel
import os
import re
import pyLDAvis.gensim_models
ScenicSpotReviewAnalysis类
class ScenicSpotReviewAnalysis:
def __init__(self, data_path, stopwords_path):
self.data_path = data_path # txt路径
self.stopwords = self._load_stopwords(stopwords_path) # 停用词
self.all_texts = self._load_data() # 加载数据
self.dictionary = None # 初始化词典
self.corpus = None # 初始化语料库
def _load_stopwords(self, path):
# 加载停用词
with open(path, encoding="utf8") as f:
stopwords = f.read().split("\n")
stopwords.append("\n")
# 添加要排除的特定词语
extra_stopwords = ['地方', '总体', '真的', '建议','小时','一座','建议']
stopwords.extend(extra_stopwords)
return stopwords
def _load_data(self):
# 加载评论数据并预处理
all_texts = {}
for pathdir in os.listdir(self.data_path):
if not pathdir.endswith(".DS_Store"):
subfilepath = os.path.join(self.data_path, pathdir)
month_text = []
if os.path.isdir(subfilepath):
for file in os.listdir(subfilepath):
filepath = os.path.join(subfilepath, file)
with open(filepath, encoding="utf-8") as f:
text = f.read()
text = "".join(re.findall(r'[\u4e00-\u9fa5]+', text)) # 提取中文
words = jieba.lcut(text) # 分词
valid_words = [word for word in words if word not in self.stopwords]
month_text.append(" ".join(valid_words))
all_texts[pathdir] = month_text
return all_texts
def filter_pos(self, target_texts):
filtered_texts = []
for sentence in target_texts:
filtered_words = []
words = pseg.cut(sentence)
for word, flag in words:
# 仅保留名词和形容词,且单词长度大于1
if (flag.startswith('n') or flag.startswith('a')) and len(word) > 1:
filtered_words.append(word)
filtered_texts.append(' '.join(filtered_words))
return filtered_texts
def train_lda_models(self, texts, num_topics_range):
self.dictionary = Dictionary(texts)
self.corpus = [self.dictionary.doc2bow(tmp) for tmp in texts]
for num_topics in num_topics_range:
lda_model = LdaModel(corpus=self.corpus, num_topics=num_topics, id2word=self.dictionary, passes=20)
lda_model.save(f'./lda_{num_topics}_{len(texts)}.model')
# 生成困惑度曲线图
def plot_perplexity(self, num_topics_range):
x_list, y_list = [], []
for num_topics in num_topics_range:
try:
lda_model = LdaModel.load(f'./lda_{num_topics}_{len(self.corpus)}.model')
perplexity = lda_model.log_perplexity(self.corpus)
x_list.append(num_topics)
y_list.append(perplexity)
except Exception as e:
print('Error:', e)
plt.plot(x_list, y_list)
plt.xlabel('Num Topics')
plt.ylabel('Perplexity Score')
plt.show()
# elbow_point = x_list[y_list.index(min(y_list))]
# print("建议的主题个数为:", elbow_point)
def visualize_topics(self, num_topics):
lda_model = LdaModel.load(f'./lda_{num_topics}_{len(self.corpus)}.model')
top_topics = lda_model.top_topics(self.corpus)
avg_topic_coherence = sum([t[1] for t in top_topics]) / num_topics
vis = pyLDAvis.gensim_models.prepare(lda_model, self.corpus, self.dictionary, mds='tsne', sort_topics=False)
pyLDAvis.save_html(vis, "LDA.html")
return vis
执行
if __name__ == '__main__':
data_path = "./景点评论数据/景点评论数据/txt"
stopwords_path = "./stopwords.txt"
analysis = ScenicSpotReviewAnalysis(data_path, stopwords_path)
phase_1 = analysis.all_texts['P1']
num_topics_range = range(1, 16)
# 对每个文档应用filter_pos处理
filtered_phase_1 = [analysis.filter_pos([doc])[0] for doc in phase_1]
analysis.train_lda_models([a.split() for a in filtered_phase_1], num_topics_range)
analysis.plot_perplexity(num_topics_range)
vis = analysis.visualize_topics(3) # 输出几个主题
代码运行之后会输出一张困惑度曲线图,用以确定最佳主题个数,找出变化率开始显著下降的点,这个点通常被称为肘点.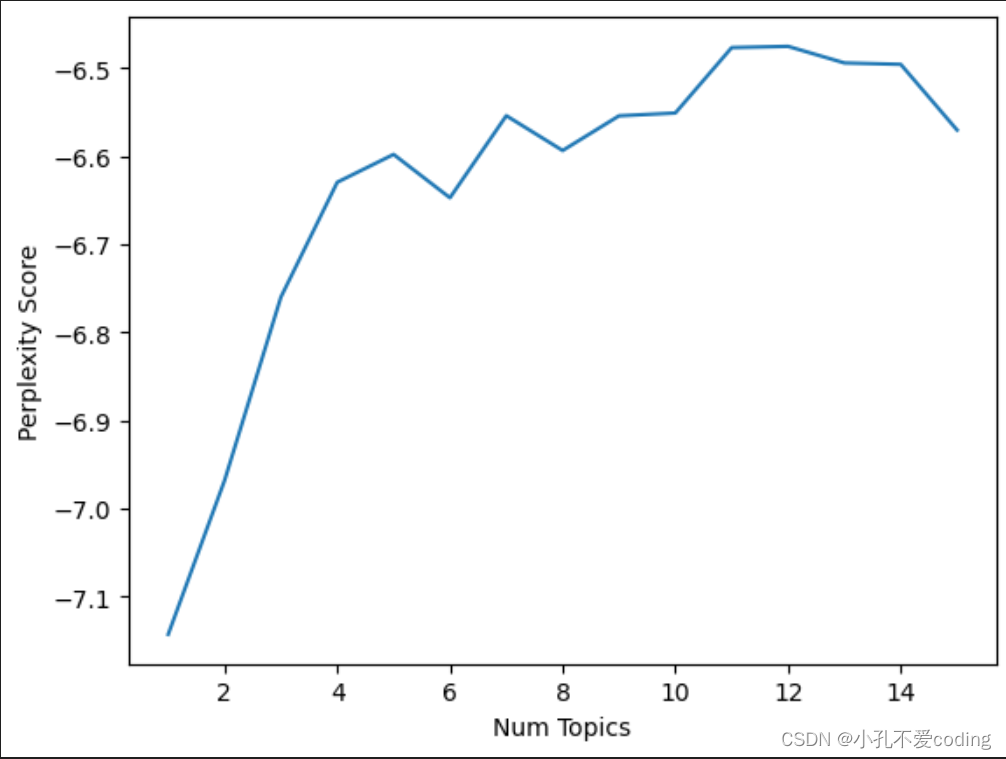
可视化图保存在LDA.html中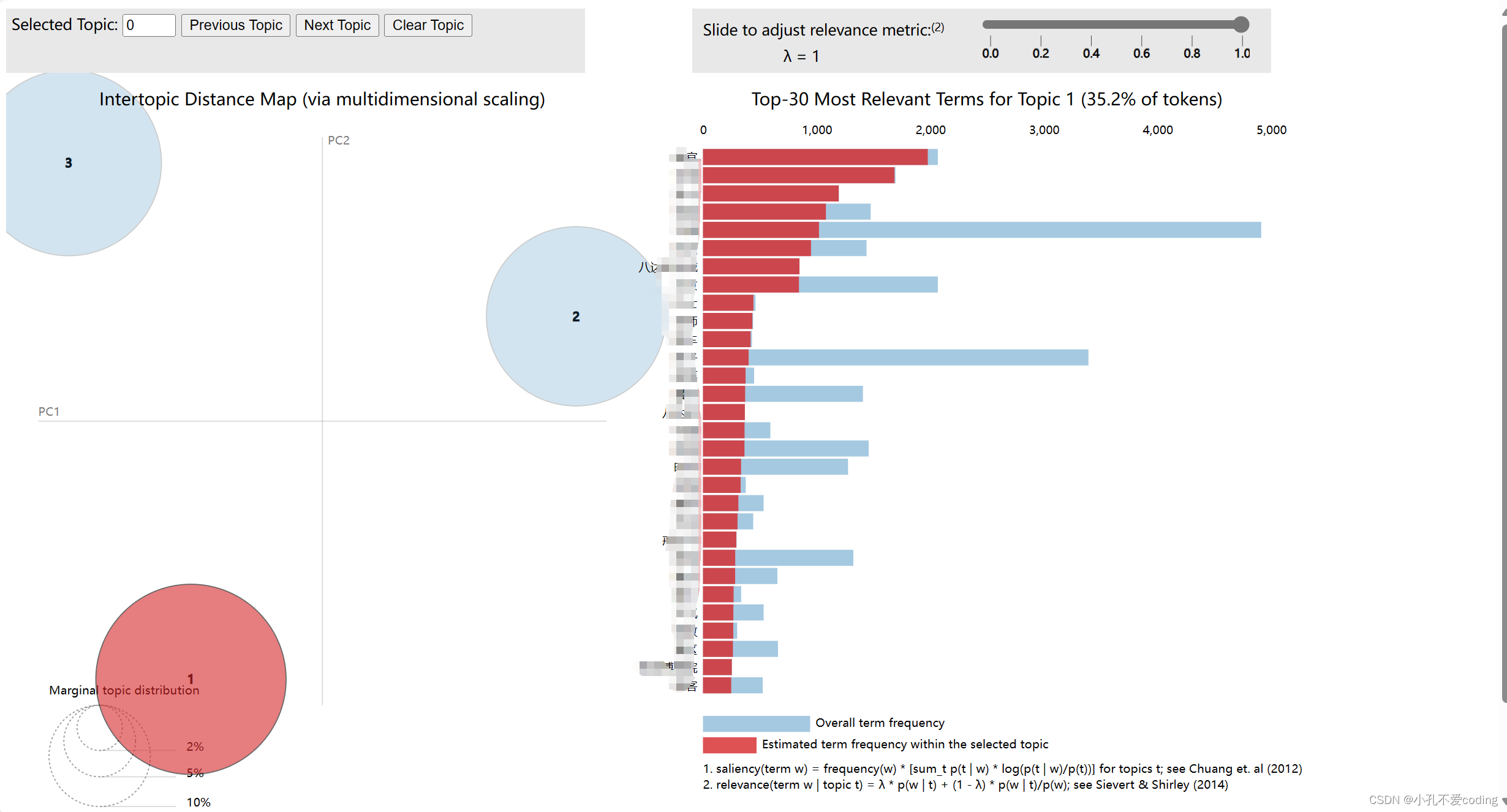

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)