
Python进阶笔记(二):自动化处理文件
该博客详细介绍了 Python 中多个与文件和数据处理相关的模块及操作。首先是 os 模块和 os.path 模块,包括 os 模块介绍、操作目录相关函数,以及 os.path 模块操作目录相关函数和获取文件时间相关的函数(如 os.path.getatime () 等)。接着阐述文件读写,涵盖文件读操作、写操作、常用打开模式、文件对象常用方法以及文件路径(相对路径和绝对路径)。在组织文件方面,介
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。
点击跳转:人工智能从入门到精通教程
本文电子版获取方式:
「Python进阶…处理文件.pdf」,复制整段内容,打开最新版「夸克APP」即可获取。
链接:https://pan.quark.cn/s/054740fbfa31
一. os模块和os.path模块
1.1 os模块介绍
OS:Operating System 操作系统
- 1、os模块是python内置的与操作系统功能和文件系统相关的模块,该模块中的语句的执行结果通常与操作系统有关,在不同的操作系统上运行,得到的结果可能不一样。
- 2、os模块与os.path模块用于对目录或文件进行操作
例:打开记事本
执行代码就自动打开
# 打开记事本
import os
os.system('notepad.exe')

和Win+R再输入notepad再回车,结果一样
例:打开计算器
# 打开计算器
import os
os.system('calc.exe')

例:启动QQ
# 直接调用可执行文件
# 启动QQ
import os
os.startfile('D:\\Program Files\\Tencent\\QQ\\Bin\\qq.exe')

1.2 os模块操作目录相关函数
| 函数名 | 使用方法 |
|---|---|
| getcwd() | 返回当前工作目录 |
| listdir(path) | 返回指定路径下的文件和目录信息 |
| mkdir(path[,mode]) | 创建单层目录,如该目录已存在抛出异常 |
| makedirs(path) | 递归创建多层目录,如该目录已存在抛出异常,注意:'E:\a\b’和’E:\a\c’并不会冲突 |
| rmdir(path) | 删除单层目录,如该目录非空则抛出异常 |
| removedirs(path1/path2…) | 递归删除目录,从子目录到父目录逐层尝试删除,遇到目录非空则抛出异常 |
| chdir(path) | 将path设置为当前工作目录 |
| remove(path) | 删除文件 |
| rename(old, new) | 将文件old重命名为new |
| system(command) | 运行系统的shell命令 |
| walk(top) | 遍历top路径以下所有的子目录,返回一个三元组:(路径, [包含目录], [包含文件]) |
| 以下是支持路径操作中常用到的一些定义,支持所有平台 | |
| os.curdir | 指代当前目录(‘.’) |
| os.pardir | 指代上一级目录(‘…’) |
| os.sep | 输出操作系统特定的路径分隔符(Win下为’\‘,Linux下为’/') |
| os.linesep | 当前平台使用的行终止符(Win下为’\r\n’,Linux下为’\n’ |
| os.name | 指代当前使用的操作系统(包括:‘posix’, ‘nt’, ‘mac’, ‘os2’, ‘ce’, ‘java’) |
os.getcwd():获取当前工作目录
import os
print(os.getcwd())
C:\Users\zdb\PycharmProjects\untitled
os.chdir() :设置设置当前工作目录
os.listdir(): 列举指定目录中的文件名
(’.‘表示当前目录,’…'表示上一级目录)
import os
print(os.getcwd()) #获取当前工作目录
os.chdir('E:\\') #改变工作目录
print(os.getcwd())
print(os.listdir('E:\\')) #把目录中的所有文件列举出来
C:\Users\zdb\PycharmProjects\untitled
E:\
['$RECYCLE.BIN', 'abc.txt', 'BaiduNetdiskDownload', 'DTLFolder', 'QLDownload', 'qqpcmgr_docpro', 'qycache', 'shuzizhong', 'System Volume Information', 'text.txt', 'WanyxGames', 'work', 'Youku Files', '江西理工大学-Ver6.0.0(20170419)Windows(通用版).exe']
mkdir(path) :创建单层目录,如该目录已存在抛出异常
os.mkdir('E:\\A') #E潘中创建文件夹A
os.mkdir('E:\\A\\B') #A里面建立B

makedirs(path):创建多级目录
### makedirs(path)
创建多级目录

remove(path) :删除文件
os.remove('E:\\A\\B\\text.txt') #删除text.txt
rmdir(path):删除单层目录,如该目录非空则抛出异常
os.rmdir('E:\\A\\B') #删除B
rmmovedirs(path):删除多级目录
import os
os.removedirs('A/B/C')
os.curdir 指代当前目录(’.’)
import os
print(os.curdir) #显示当前目录
print(os.listdir(os.curdir)) #显示上一级目录
.
['.idea', 'A_1.txt', 'A_2.txt', 'A_3.txt', 'B_1.txt', 'B_2.txt', 'B_3.txt', 'temp.py', 'venv']
1.3 os.path模块操作目录相关函数
| 函数名 | 使用方法 |
|---|---|
| abspath(path) | 用于获取文件或目录的绝对路径 |
| exists(path) | 判断指定路径(目录或文件)是否存在,存在返回True |
| join(path, name) | 将目录与目录或者文件名拼接起来 |
| splitext(path) | 分离文件名与扩展名,返回(f_name, f_extension)元组 |
| basename(path) | 从一个目录中提取文件名 |
| dirname(path) | 从一个路径中提取文件路径,不包括文件名 |
| isdir(path) | 同于判断是否为路径 |
| split(path) | 分割文件名与路径,返回(f_path, f_name)元组。如果完全使用目录,它也会将最后一个目录作为文件名分离,且不会判断文件或者目录是否存在 |
| getsize(file) | 返回指定文件的尺寸,单位是字节 |
| getatime(file) | 返回指定文件最近的访问时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算) |
| getctime(file) | 返回指定文件的创建时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算) |
| getmtime(file) | 返回指定文件最新的修改时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算) |
| 以下为函数返回 True 或 False | |
| isabs(path) | 判断指定路径是否为绝对路径 |
| isfile(path) | 判断指定路径是否存在且是一个文件 |
| islink(path) | 判断指定路径是否存在且是一个符号链接 |
| ismount(path) | 判断指定路径是否存在且是一个挂载点 |
| samefile(path1, paht2) | 判断path1和path2两个路径是否指向同一个文件 |
os.path.relpath(patj, start):返回从start到path的相对路径的字符串
os.path.abspath():返回文件的绝对路径
import os.path
print(os.path.abspath('temp.py'))
C:\Users\zdb\PycharmProjects\untitled\temp.py
os.path.exists(path):判断文件是否存在
# 判断文件是否存在,存在为True
import os.path
print(os.path.exists('temp.py'), os.path.exists('111.py'))
True False
os.path.join() :合成路径
import os.path
print(os.path.join('E:\\Python', 'temp.py'))
E:\Python\temp.py
例2
import os
print(os.path.join('A','B','C')) #合成工作路径名
print(os.path.join('C:','A','B','C'))
print(os.path.join('C:\\','A','B','C'))
A\B\C
C:A\B\C
C:\A\B\C
basename(path) :去掉目录路径,单独返回文件名
import os
print(os.path.basename('E:\\A\\B\\C\\abc.avi')) #只显示文件名
abc.avi
dirname(path) :去掉文件名,单独返回目录路径
import os
print(os.path.dirname('E:\\A\\B\\C\\abc.avi')) #只显示工作路径
E:\A\B\C
os.path.split(path) :分割文件名与路径,返回(f_path, f_name)元组。如果完全使用目录,它也会将最后一个目录作为文件名分离,且不会判断文件或者目录是否存在
import os
print(os.path.split('E\\A\\abc.avi')) #分割文件名与路径
print(os.path.split('E\\A\\B')) #将最后一个目录作为文件名分割下来
('E\\A', 'abc.avi')
('E\\A', 'B')
splitext(path) :分离文件名与扩展名,返回(f_name, f_extension)元组
import os
print(os.path.splitext('E\\A\\abc.avi')) #分离文件名与文件后缀
('E\\A\\abc', '.avi')
ismount(path) :判断指定路径是否存在且是一个挂载点
import os
print(os.path.ismount('E:\\'))
print(os.path.ismount('E:\\A'))
True
False
课堂案例
例:获取当前目录里的所有.py文件
import os
path = os.getcwd() # 获取当前工作目录
lst = os.listdir(path) # 列举当前目录的所有文件,放在列表中
for filename in lst: # 遍历列表中的所有文件
if filename.endswith('.py'): # 如果是.py文件
print(filename) # 就输出
alien_invasion.py
all_events.py
ball.py
car.py
electric_car.py
game_functions.py
glass.py
main.py
name_function.py
pizza.py
settings.py
survey.py
temp.py
1.4 os.path.getatime() 、os.path.getctime()、os.path.getmtime()
os.path.getatime(file) :访问时间
- 返回指定文件最近的访问时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算)
oa.path.getctime(file):创建时间
- 返回指定文件的创建时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算)
oa.path.getmtime(file) :修改时间
- 返回指定文件最新的修改时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算)
import os
print(os.path.getatime('E:\\abc.txt')) #返回访问时间
print(os.path.getctime('E:\\abc.txt')) #返回创建时间
print(os.path.getmtime('E:\\abc.txt')) #返回修改时间
1591704113.4222739
1591704113.4222739
1591704113.4222739
用time模块的gmtime()或localtime()函数换算
import time
import os
print(time.gmtime(os.path.getatime('E:\\abc.txt')))
print(time.localtime(os.path.getmtime('E:\\abc.txt')))
time.struct_time(tm_year=2020, tm_mon=6, tm_mday=9, tm_hour=12, tm_min=19, tm_sec=41, tm_wday=1, tm_yday=161, tm_isdst=0)
time.struct_time(tm_year=2020, tm_mon=6, tm_mday=9, tm_hour=20, tm_min=19, tm_sec=41, tm_wday=1, tm_yday=161, tm_isdst=0)
二. 文件读写
2.1 文件读操作
读取文本时,python将其中的所有文本都解读为字符串
语法规则:file = open(filename [,mode,encoding])
- file:被创建的文件对象
- open:创建文件对象的函数
- filename:要创建或打开的文件名称
- mode:打开默认为只读
- encoding:默认文本文件中字符的编写格式为gbk
例:读取磁盘文件的内容
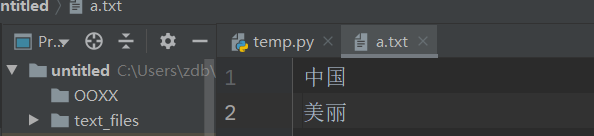
file = open('a.txt', 'r') # 只读形式打开a.txt
print(file.readlines()) # 逐行读取,返回列表,每行为以列表元素
file.close() # 打开之后都要关闭
['中国\n', '美丽']
方法二,效果一样,且不需close
with open('a.txt', 'r') as file: # 默认为只读,'r'其实可以省略
print(file.readlines())
2.2 文件写操作
例:新文件中写入一行
filename = "abc.txt"
with open(filename, 'w') as file_object:
file_object.write("zdb\n")
例:追加到旧文件中写入
filename = "abc.txt"
with open(filename, 'a') as file_object:
file_object.write("zzz\n") #在上面原有文件里追加一行数据
2.3 常用的文件打开模式
按文件中数据的组织形式,文件分为以下两大类
- 文本文件:存储的是普通“字符文本”,默认为unicode字符集,可以使用记本事程序打开
- 二进制文件:把数据内容用“字节”进行存储,无法用记事本打开,必须使用专用的软件打开,举例:mp3音频文件,jpg图片,doc文档等
| 打开模式 | 执行操作 |
|---|---|
| ‘r’ | 以只读方式打开文件(默认) |
| ‘w’ | 以写入的方式打开文件,会覆盖已存在的文件 |
| ‘x’ | 如果文件已经存在,使用此模式打开将引发异常 |
| ‘a’ | 以写入模式打开,如果文件存在,则在末尾追加写入 |
| ‘b’ | 以二进制模式打开文件,不能单独使用,需要与其它模式一起使用,如rb,wb |
| ‘t’ | 以文本模式打开(默认) |
| ‘+’ | 以读写模式打开,不能单独使用,需要与其它模式一起使用,如a+ |
| ‘U’ | 通用换行符支持 |
‘w’
1、open以写入的方式打开一个不存在的文件,便能创建一个新文件
file = open('b.txt', 'w')
file.write('helloworld')
file.close()

2、再次以写入的形式写进创建好的文件,便覆盖文件的内容
file = open('b.txt', 'w')
file.write('python')
file.close()

例2:
这里有两种打开文件的方法,同时两种写入文件的方法
# 一,使用print方式进行输出()
fp = open('text.txt', 'w')
print('奋斗成就更好的你', file=fp) # 这里也可以f.write()
fp.close()
"""第二种方式,使用文件读写操作"""
with open('text1.txt', 'w') as file:
file.write('奋斗成就更好的你')
‘a’
把上述代码的’w’改成’a’,再运行一次,便在原来的基础上追加,所以结果显示两个python
file = open('b.txt', 'a')
file.write('python')
file.close()

但如果原来没有这个文件,便创建,如以下代码在不存在的c文件中写入
file = open('c.txt', 'a')
file.write('python')
file.close()

‘b’
这里进行图片的赋值,原图片为win.png,复制后命名为copy.png
# 进行图片的复制
src_file = open('win.png', 'rb') # 原文件,二进制读
target_file = open('copy.png', 'wb') # 目标文件,二进制写
target_file.write(src_file.read()) # 原文件读出,写入目标文件
target_file.close() # 关闭两个文件
src_file.close()
结果如下:
2.4 文件对象的常用方法
| 文件对象方法 | 执行操作 |
|---|---|
| read([size]) | 从文件中读取size个字节或字符的内容返回。若省略[size],则读取到文件末尾,即一次读取文件所有内容 |
| readline() | 从文本文件中读取一行内容 |
| readlines() | 把文本文件中每一行都作为独立的字符串对象,并将这些对象放入列表返回 |
| write(str) | 将字符串str内容写入文件 |
| wirtelines(s_list) | 将字符串列表s_list写入文本文件,不添加换行符 |
| seek(offset[,whence]) | 把文件指针移动到新的位置,offset表示相对于whence的位置;offset为正往结束方向移动,为负往开始方向移动。whence不同的值代表不同含义:0:从文件头开始计算(默认值);1:从当前位置开始计算;2:从文件尾开始计算 |
| tell() | 返回文件指针的当前位置 |
| truncate([size=file.tell()]) | 截取文件到size个字节,默认是截取到文件指针当前位置 |
| flush() | 把缓冲区的内容写入文件,但不关闭文件 |
| close() | 关闭文件 |
read():读出
file = open('a.txt', 'r')
print(file.read())

readline():读一行
file = open('a.txt', 'r')
#print(file.read())
print(file.readline())

readlines():将每一行元素作为独立字符串,放入列表当中
file = open('a.txt', 'r')
#print(file.read())
#print(file.readline())
print(file.readlines())
['中国\n', '美丽']
write():写入
file = open('c.txt', 'w')
file.write('hello')
file.close()

writelines():将字符串列表s_list写入文本文件,不添加换行符
file = open('c.txt', 'a')
lst = ['java', 'go', 'python']
file.writelines(lst)
file.close()

seek()
file = open('a.txt', 'r')
file.seek(2) # 一个中文两个字节,跳过了国字
print(file.read())
print(file.tell()) # 中国,回车,美丽总共10字节
file.close()
国
美丽
10
tell()
file = open('b.txt', 'r')
print(file.read())
print(file.tell()) # 中国,回车,美丽总共10字节
file.close()
pythonpython
12
flush()
file = open('d.txt', 'a')
file.write('hello')
file.flush() # 后面可以继续写内容
file.write('world')
file.close() # 后面不可以写代码

encoding=‘utf-8’
f = open('C:\\Users\\zdb\\Desktop\\abc.txt', encoding='utf-8')
#encoding='utf-8' 防止乱码加上去的
print(f)
print(f.read()) #对的,读,并输出
<_io.TextIOWrapper name='C:\\Users\\zdb\\Desktop\\abc.txt' mode='r' encoding='utf-8'>
abcdefg
例2
file_name = input('请输入需要打开的文件名:')
f = open(file_name)
print('文件的内容是:')
for each_line in f:
print(each_line)

with open(‘a.txt’, ‘r’) as file::这样就不需要关闭文件那一行代码了
with open('a.txt', 'r') as file:
print(file.read())
中国
美丽
例2
with open('win.png', 'rb') as file: # 以二进制读打开
with open('copy.png', 'wb') as target_file: # 以二进制写打开
target_file.write(file.read()) # 目标文件写入原文件被读的
2.5 文件路径:相对路径、绝对路径
相对路径:只能读取到同一目录里面的文件
- 1、text_files与主程序在一个目录
- 2、读取text_file里面的pi_digits.txt
- 3、主程序代码如下
with open('text_files\pi_digits.txt') as file_object:
#open接受一个参数:要打开的文件的名称
#关键字with在不需要访问文件后将其关闭
contents = file_object.read()
#read读取这个文件的全部内容,并将其作为长串字符存储在变量contents中
print(contents) #打印输出
绝对路径:读取系统任何地方的文件
f = open('C:\\Users\\zdb\\Desktop\\abc.txt', encoding='utf-8')
#encoding='utf-8' 防止乱码加上去的
print(f)
print(f.read()) #对的,全输出
例2
f = open('C:\\Users\\zdb\\Desktop\\abc.txt', encoding='utf-8')
#f.seek(0,0)
lines = list(f)
for each_line in lines:
print(each_line.rstrip()) #rstrip去掉\n
abcdefg
123
456
三. 组织文件
3.1 shutil模块复制、移动、删除、改名文件\文件夹
1. 复制文件:shutil.copy()
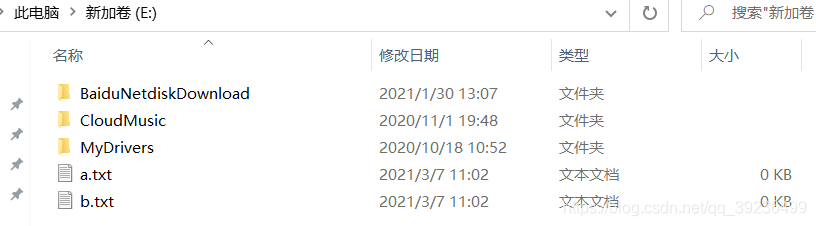
例:源文件在桌面,名为a.txt
import shutil, os
os.chdir('C:\\Users\\zdb\\Desktop\\') # 设置工作路径
shutil.copy('C:\\Users\\zdb\\Desktop\\a.txt', 'E:\\') # 复制到E盘
shutil.copy('C:\\Users\\zdb\\Desktop\\a.txt', 'E:\\b.txt') # 重新命名为b.txt
2. 复制文件夹:shutil.copytree()
例:源文件在桌面上,a文件夹里面有个a.txt
import shutil, os
os.chdir('C:\\Users\\zdb\\Desktop\\')
shutil.copytree('C:\\Users\\zdb\\Desktop\\a', 'E:\\b') # 复制到E盘文件夹命名为b

3. 移动文件:shutil.move()
例1:源文件在a下a.txt,E盘有个空文件夹b
import shutil, os
os.chdir('C:\\Users\\zdb\\Desktop\\')
shutil.move('C:\\Users\\zdb\\Desktop\\a\\a.txt', 'E:\\b') # 把TXT移动到E盘b文件夹

例2:移动文件,且重命名:桌面有a\a.txt,把它移动到E盘b文件夹,且重命名为b.txt(实现改名)
注意:若目标文件b夹不存在会报错
import shutil, os
os.chdir('C:\\Users\\zdb\\Desktop\\')
shutil.move('C:\\Users\\zdb\\Desktop\\a\\a.txt', 'E:\\b\\b.txt') # 把TXT移动到E盘b文件夹,且重命名b

3. 删除文件
- 用os.unlink(path)将删除path处的文件
- 用os.rmdir(path)将删除path处的文件夹。该文件夹必须为空
- 用shutil.rmtree(path)将删除path处的文件夹。文件夹中所有文件也删除
注意:删除不可逆,不要轻易删除,最好先打印输出一遍要删除的文件,防止删错文件
import os
for filename in os.listdir():
if filename.endswith('.rxt'):
print(filename)
#os.unlink(filename)
- shutil.rmtree()函数删除不可逆,但是使用send2trash模块可以删除到回收站,而不是永久删除跳过回收站
import send2trash
file = open('C:\\Users\\zdb\\Desktop\\a.txt', 'a') # 创建a.txt
file.write('abc123') # 写入数据
file.close() # 关闭文件
send2trash.send2trash('C:\\Users\\zdb\\Desktop\\a.txt') #删除到回收站

例:遍历目录树
import os
# os.walk()返回三个值:
# 当前文件夹名称的字符串
# 当前文件夹中子文件夹的字符串的列表
# 当前文件夹中文件的字符串的列表
for folderName, subfolders, filenames in os.walk("c:\\delicious"):
print("The current folder is " + folderName)
for subfolder in subfolders:
print("Subfolders of " + folderName + ": " + subfolder)
for filename in filenames:
print("FILE INSIDE " + folderName + ": " + filename)
3.2 处理压缩文件:读取、解压、创建
1. 读取zip文件
要读取zip文件,就要先创建一个ZipFile对象,用zipfile.ZipFile()函数创建
例:example压缩包中有a文件夹和c.txt文件,a文件夹下还有a.txt和b.txt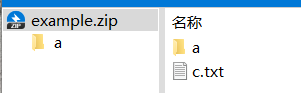
import zipfile, os
os.chdir('C:\\Users\\zdb\\Desktop\\')
example_zip = zipfile.ZipFile('example.zip')
print(example_zip.namelist()) # 输出文件名列表
file = example_zip.getinfo('c.txt')
print(file.file_size) # 输出源文件大小
print(file.compress_size) # 输出压缩后文件大小
example_zip.close()
['a/', 'a/a.txt', 'a/b.txt', 'c.txt']
0
0
2. 从zip文件中解压缩
- ZipFile对象的extractall()方法从zip文件中解压缩所有文件和文件夹,放到当前工作目录中
import zipfile, os
os.chdir('C:\\Users\\zdb\\Desktop\\')
example_zip = zipfile.ZipFile('example.zip')
example_zip.extractall()
example_zip.close()
解压前:
解压后如下:压缩包不会消失
- example_zip.extract()可解压单个文件,第一个参数指定需解压的文件;第二个参数指定路径
import zipfile, os
os.chdir('C:\\Users\\zdb\\Desktop\\')
example_zip = zipfile.ZipFile('example.zip')
example_zip.extract('c.txt', 'C:\\Users\\zdb\\Desktop\\') # 将c.txt解压到桌面
example_zip.close()
3. 创建和添加到zip文件
- 要创建压缩文件需要用写的形式打开文件,write()写入,第一个参数表示需要压缩的文件,第二个参数是“压缩类型”参数。
import zipfile, os
os.chdir('C:\\Users\\zdb\\Desktop\\')
new_zip = zipfile.ZipFile('new.zip', 'w')
new_zip.write('c.txt', compress_type=zipfile.ZIP_DEFLATED) # 把c.txt添加到new_zip里面
new_zip.close()
四. 处理xlsx
工作簿基本介绍:
- 一个工作簿扩展名为.xlsx
- 每个工作簿可以包含多个表
- 列名ABCD、行名1234
4.1 openpyxl介绍
安装:pip install openpyxl
openpyxl中有三个不同层次的类,Workbook是对工作簿的抽象,Worksheet是对表格的抽象,Cell是对单元格的抽象,每一个类都包含了许多属性和方法。
操作Excel的一般场景:
- 打开或者创建一个Excel需要创建一个Workbook对象
- 获取一个表则需要先创建一个Workbook对象,然后使用该对象的方法来得到一个Worksheet对象
- 如果要获取表中的数据,那么得到Worksheet对象以后再从中获取代表单元格的Cell对象
Workbook对象提供的部分属性如下:
- active:获取当前活跃的Worksheet
- worksheets:以列表的形式返回所有的Worksheet(表格)
- read_only:判断是否以read_only模式打开Excel文档
- encoding:获取文档的字符集编码
- properties:获取文档的元数据,如标题,创建者,创建日期等
- sheetnames:获取工作簿中的表(列表)
import openpyxl
wb = openpyxl.load_workbook('C:\\Users\\zdb\\Desktop\\test.xlsx')
print('workbook的常见属性:------------------')
print('当前活跃的worksheet为:', wb.active)
print('表格有:', wb.worksheets)
print('是否为只读打开:', wb.read_only)
print('编码格式为:', wb.encoding)
print('文档的标题、创建者、创建日期为:', wb.properties)
print('工作簿中的表:', wb.sheetnames)
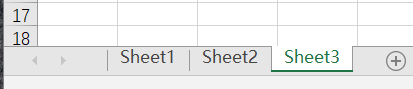
workbook的常见属性:------------------
当前活跃的worksheet为: <Worksheet "Sheet3">
表格有: [<Worksheet "Sheet1">, <Worksheet "Sheet2">, <Worksheet "Sheet3">]
是否为只读打开: False
编码格式为: utf-8
文档的标题、创建者、创建日期为: <openpyxl.packaging.core.DocumentProperties object>
Parameters:
creator='zdb', title=None, description=None, subject=None, identifier=None, language=None, created=datetime.datetime(2015, 6, 5, 18, 19, 34), modified=datetime.datetime(2021, 3, 8, 2, 52, 52), lastModifiedBy='zdb', category=None, contentStatus=None, version=None, revision=None, keywords=None, lastPrinted=None
工作簿中的表: ['Sheet1', 'Sheet2', 'Sheet3']
Workbook提供的方法如下:
- get_sheet_names:获取所有表格的名称(新版已经不建议使用,通过Workbook的sheetnames属性即可获取)
- get_sheet_by_name:通过表格名称获取Worksheet对象(新版也不建议使用,通过Worksheet[‘表名‘]获取)
- get_active_sheet:获取活跃的表格(新版建议通过active属性获取)(已经不可用)
- remove_sheet:删除一个表格
- create_sheet:创建一个空的表格
- copy_worksheet:在Workbook内拷贝表格
常用的Worksheet方法如下:
- iter_rows:按行获取所有单元格,内置属性有(min_row,max_row,min_col,max_col)
- iter_columns:按列获取所有的单元格
- append:在表格末尾添加数据
- merged_cells:合并多个单元格
- unmerged_cells:移除合并的单元格
Cell对象比较简单,常用的属性如下:
- row:单元格所在的行
- column:单元格坐在的列
- value:单元格的值
- coordinate:单元格的坐标
4.2 获取工作簿中所有表名
import openpyxl
wb = openpyxl.load_workbook('C:\\Users\\zdb\\Desktop\\test.xlsx')
print(wb.get_sheet_names())
['Sheet1', 'Sheet2', 'Sheet3']
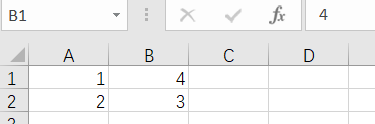
4.3 读取列表元素
import openpyxl
wb = openpyxl.load_workbook('C:\\Users\\zdb\\Desktop\\test.xlsx')
sheet = wb.get_sheet_by_name('Sheet1')
print(sheet['A1'].value)
print(sheet.cell(row=2, column=2).value)
4.4 遍历Excel
import openpyxl
wb = openpyxl.load_workbook('C:\\Users\\zdb\\Desktop\\test.xlsx')
sheet = wb.get_sheet_by_name('Sheet1')
for r in sheet:
for j in r:
print(j.value)
print('......')
1
4
......
2
3
......
4.5 获取行列数
import openpyxl
wb = openpyxl.load_workbook('C:\\Users\\zdb\\Desktop\\test.xlsx')
sheet = wb.get_sheet_by_name('Sheet1')
print(sheet.max_row)
print(sheet.max_column)
2
2
4.6 获取活跃worksheet
import openpyxl
wb = openpyxl.load_workbook('C:\\Users\\zdb\\Desktop\\test.xlsx')
sheet = wb.active # 获取当前活跃的worksheet
print(sheet)
sheet.title = 'abc' # sheet重命名
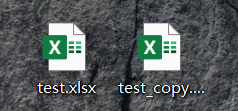
wb.save('C:\\Users\\zdb\\Desktop\\test_copy.xlsx') # 保存覆盖
<Worksheet "Sheet1">
4.7 创建、删除工作表
import openpyxl
wb = openpyxl.load_workbook('C:\\Users\\zdb\\Desktop\\test.xlsx')
print(wb.get_sheet_names()) # 显示表名
wb.create_sheet(index=0, title='First sheet') # 创建表
print(wb.get_sheet_names())
wb.remove_sheet(wb.get_sheet_by_name('Sheet1')) # 删除表
print(wb.get_sheet_names())
['Sheet1']
['First sheet', 'Sheet1']
['First sheet']
4.8 创建xlsx,将值写入工作表
import openpyxl
wb = openpyxl.Workbook() # 创建xlsx
sheet = wb.create_sheet("mySheet") # 创建工作表
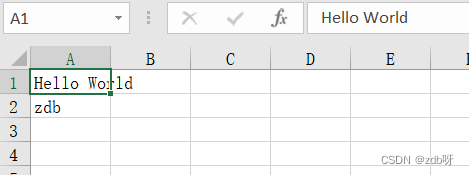
sheet['A1'] = "Hello World"
sheet.cell(row=2, column=1).value = "zdb"
wb.save('test.xlsx')
注意:所有的更变之后记得调用save()方法保存变更结果
4.9 项目:更新一个电子表格
import openpyxl
"""更新某些产品的售价"""
wb = openpyxl.load_workbook("productSales.xlsx")
sheet = wb.get_sheet_by_name("Sheet")
# 新价格表
PRICE_UPDATES = {"Garlic" : 3.07,
"Celery" : 1.19,
"Lemon" : 1.27}
for rowNum in range(2, sheet.max_row + 1):
produceName = sheet.cell(row=rowNum, column=1).value
if produceName in PRICE_UPDATES:
sheet.cell(row=rowNum, column=2).value = PRICE_UPDATES[produceName]
wb.save('updateProduceSales.xlsx') # 保存新文件
五. 处理CSV
- CSV文件是简化的电子表格,保存为纯文本文件
- 逗号分隔单元格
- 值没有类型,所有东西都是字符串
- 没有字体大小和颜色的设置
- 没有多个工作表
- 不能指定单元格的宽度和高度
- 不能合并单元格
- 不能嵌入图像和图表
5.1 读操作
import csv, os
os.chdir('C:\\Users\\zdb\\Desktop\\')
exampleFile = open('test1.csv', encoding='utf-8')
exampleReader = csv.reader(exampleFile)
exampleData = list(exampleReader)
print(exampleData)
print(exampleData[1][1]) # 第一行第一列,从第0行开始
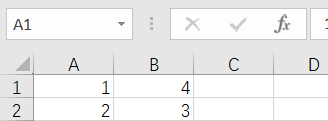
[['\ufeff1', '4'], ['2', '3']]
3
5.2 写操作
import csv, os
os.chdir('C:\\Users\\zdb\\Desktop\\')
outFile = open('output.csv', 'w', newline='') # 写形式打开文件
outputWriter = csv.writer(outFile)
outputWriter.writerow(['a', 'b', 'c', 'd'])
outputWriter.writerow((['e', 'f', 'g', 'h']))
outFile.close() # 关闭文件

注意:newline关键字必不可少,忘记则行距将有两倍
5.3 项目:从多个csv文件中删除比表头
import csv, os
# 从多个csv文件中删除第一行
os.makedirs("headerRemoved", exist_ok=True)
for csvFilename in os.listdir('.'): # 遍历每个csv文件
if not csvFilename.endswith('.csv'):
continue
print("Remove header from " + csvFilename + '...')
csvRows = [] # 创建新的csv文件副本,不包含第一行
csvFileObj = open(csvFilename)
readerObj = csv.reader(csvFileObj)
for row in readerObj:
if readerObj.line_num == 1:
continue
csvRows.append(row)
csvFileObj.close()
# 生成没有第一行的新文件
csvFileObj = open(os.path.join('headerRemoved', csvFilename), 'w', newline='')
csvWriter = csv.writer(csvFileObj)
for row in csvRows: # 写入每一行
csvWriter.writerow(row)
csvFileObj.close()
六. 处理PDF
6.1 从pdf提取文本
import PyPDF2
pdfFileObj = open("myPDF.pdf", 'rb')
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
print(pdfReader.numPages) # pdf文件的页数
pageObj = pdfReader.getPage(0)
print(pageObj.extract_text()) # 输出第0页的文本内容
6.2 解密pdf
import PyPDF2
pdfFileObj = open("myPDF.pdf", 'rb')
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
print(pdfReader.isEncrypted) # True则为加密文件
pdfReader.decrypt('mima') # 输入解密密码
pageObj = pdfReader.getPage(0)
print(pageObj.extract_text())
6.3 创建pdf文件
模块不允许直接编辑PDF,必须创建一个新的PDF,然后从已有的文档拷贝内容。
- 打开一个或多个已有的PDF文件,得到PdfFileReader对象
- 创建一个新的PdfFileWriter对象
- 将页面从PdfFileReader对象拷贝到PdfFileWriter对象中
- 最后,利用PdfFileWriter对象写入输出的PDF
import PyPDF2
"""两个pdf文件合成一个新的PDF文件,并保存"""
pdf1File = open('1.pdf', 'rb') # 二进制读
pdf2File = open('2.pdf', 'rb')
pdf1Reader = PyPDF2.PdfFileReader(pdf1File)
pdf2Reader = PyPDF2.PdfFileReader(pdf2File)
pdfWriter = PyPDF2.PdfFileWriter() # 创建一个新的PdfFileWriter对象
for pageNum in range(pdf1Reader.numPages):
pageObj = pdf1Reader.getPage(pageNum)
pdfWriter.addPage(pageObj)
for pageNum in range(pdf2Reader.numPages):
pageObj = pdf2Reader.getPage(pageNum)
pdfWriter.addPage(pageObj)
pdfOutputFile = open('fin.pdf', 'wb')
pdfWriter.write(pdfOutputFile)
pdfOutputFile.close()
pdf1File.close()
pdf2File.close()
6.4 旋转页面
import PyPDF2
minutesFile = open("1.pdf", 'rb')
pdfReader = PyPDF2.PdfFileReader(minutesFile, strict=False)
page = pdfReader.getPage(0)
page.rotateClockwise(90)
pdfWriter = PyPDF2.PdfFileWriter()
pdfWriter.addPage(page)
resultPdfFile = open("rotatedPage.pdf", 'wb')
pdfWriter.write(resultPdfFile)
resultPdfFile.close()
minutesFile.close()

6.5 叠加页面
import PyPDF2
"""在第一页添加水印"""
minutesFile = open("1.pdf", 'rb')
pdfReader = PyPDF2.PdfFileReader(minutesFile, strict=False)
page = pdfReader.getPage(0)
pdfWatermarkReader = PyPDF2.PdfFileReader(open("watermark.pdf", 'rb'))
page.mergePage(pdfWatermarkReader.getPage(0))
pdfWriter = PyPDF2.PdfFileWriter()
pdfWriter.addPage(page)
for pageNum in range(1, pdfReader.numPages):
pageObj = pdfReader.getPage(pageNum)
pdfWriter.addPage(pageObj)
resultPdfFile = open("watermarkedCover.pdf", 'wb')
pdfWriter.write(resultPdfFile)
minutesFile.close()
resultPdfFile.close()
6.6 加密pdf
import PyPDF2
pdfFile = open("meetingminutes.pdf", 'rb')
pdfReader = PyPDF2.PdfFileReader(pdfFile)
pdfWriter = PyPDF2.PdfFileWriter()
for pageNum in range(pdfReader.numPages):
pdfWriter.addPage(pdfReader.getPage(pageNum))
pdfWriter.encrypt("mima")
resultPdf = open("encrytedminutes.pdf", 'wb')
pdfWriter.write(resultPdf)
resultPdf.close()
6.7 项目:从多个PDF中合并选择的页面
import PyPDF2, os
# 1.获取所有pdf文件
pdfFiles = []
for filename in os.listdir('.'):
if filename.endswith('.pdf'):
pdfFiles.append(filename)
# 2.排序
pdfFiles.sort(key=str.lower)
# 3.为输出文件创建PdfFileWriter对象
pdfWriter = PyPDF2.PdfFileWriter()
for filename in pdfFiles:
pdfFileObj = open(filename, 'rb')
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
for pageNum in range(1, pdfReader.numPages):
pageObj = pdfReader.getPage(pageNum)
pdfWriter.addPage(pageObj)
pdfOutput = open("allminutes.pdf", 'wb')
pdfWriter.write(pdfOutput)
pdfOutput.close()
七. 处理docx
pip install python-docx
7.1 读取完整文本
例:读取Word文档
import docx
doc = docx.Document('demo.docx')
print(len(doc.paragraphs))
print(doc.paragraphs[0].text)
print(doc.paragraphs[1].text)
print(doc.paragraphs[1].runs)
print(doc.paragraphs[1].runs[0].text)
print(doc.paragraphs[1].runs[1].text)
print(doc.paragraphs[1].runs[2].text)
例:从.docx文件中取得完整的文本
import docx
def getText(filename):
doc = docx.Document(filename)
fullText = []
for para in doc.paragraphs:
fullText.append(para.text)
return '\n'.join(fullText)
print(getText('demo.docx'))
7.2 写入docx文档
import docx
doc = docx.Document()
doc.add_paragraph("Hello world!")
doc.save("helloworld.docx")

例2
import docx
doc = docx.Document()
doc.add_paragraph("Hello world!")
paraObj1 = doc.add_paragraph("This is a second paragraph.")
paraObj2 = doc.add_paragraph("This is a yet another paragraph.")
paraObj1.add_run(" This text is being added to the second paragraph.")
doc.save("newHelloworld.docx")

7.3 添加标题
import docx
doc = docx.Document()
doc.add_paragraph("Hello world!", 'Title')
doc.save("helloworld.docx")

例2
import docx
doc = docx.Document()
doc.add_heading("Header 0", 0)
doc.add_heading("Header 1", 1)
doc.add_heading("Header 2", 2)
doc.add_heading("Header 3", 3)
doc.add_heading("Header 4", 4)
doc.save("headings.docx")

八. 处理JSON
8.1 存取操作
例:存
import json
numbers = [1, 3, 5, 7, 9]
filename = "numbers.json"
with open(filename, 'w') as f_obj:
json.dump(numbers, f_obj)
例:取
import json
filename = "numbers.json"
with open(filename) as f_obj:
numbers = json.load(f_obj)
print(numbers)
[1, 3, 5, 7, 9]

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)