
人工智能知识全面讲解:卷积神经网络
11.2.1 卷积运算因为运算能力受到了限制,所以只有运算量小的方法才有可能提取图像的特征。仔细思考我们会发现,图像特征的表现有一个很显然的特点,就是在图像中特征边缘的像素点的颜色通常都是变化较大的 。实际上我们没有必要扫描整幅图像来学习特征,只需要找到这些边缘变化大的地方就能够发现物体的特征。于是我们从数学领域寻找有没有合适的方法能够帮助我们表达像素变化较大的边缘,如果能找到这样的方法就能够通过
11.2.1 卷积运算
因为运算能力受到了限制,所以只有运算量小的方法才有可能提取图像的
特征。仔细思考我们会发现,图像特征的表现有一个很显然的特点,就是在
图像中特征边缘的像素点的颜色通常都是变化较大的 。实际上我们没有必要
扫描整幅图像来学习特征,只需要找到这些边缘变化大的地方就能够发现物体
的特征。于是我们从数学领域寻找有没有合适的方法能够帮助我们表达像素变
化较大的边缘,如果能找到这样的方法就能够通过运算直接找出物体的特征。
幸运的是,人们发现“卷积运算”能够提取图像的边缘与特征。
在第7章我们讲过神经元模型的运算过程。神经元通过运算,为每个输入
数据赋予一个权值,加权计算后求和得到输出。卷积的原理与此十分相似,在
输入信号的每个位置,叠加一个单位响应,得到输出信号。在图像数据中用一
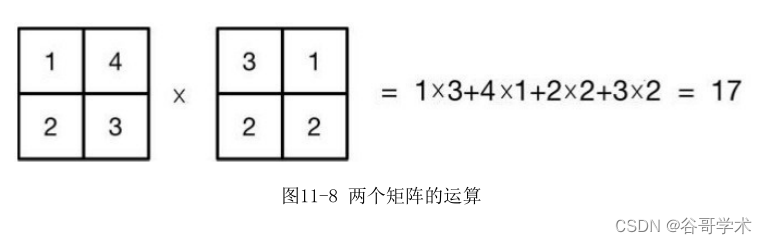
个小的矩阵作为单位响应,对一个大的矩阵求内积,即每个位置对应的数字相
乘之后的和,如图 11-8 所示,最后得出结果。通常我们把这个小矩阵称
为“卷积核”。
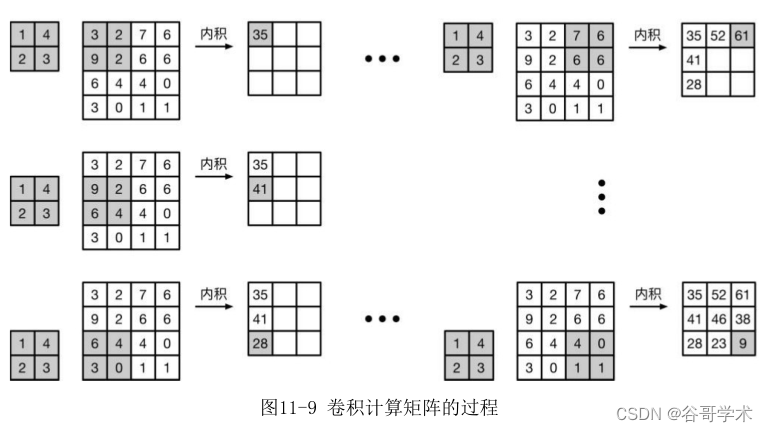
在处理灰度图像时,首先我们将两个矩阵的第一个元素对齐,先不看大矩
阵多余的部分,然后计算这两个维数相同的矩阵的内积,并将算得的结果作为
结果矩阵的第一个元素。接?来。我们将小矩阵向?滑动一个元素,从原始的
矩阵中截去不能与之对应的元素,并计算内积。重复以上步骤直到这一列所有
元素计算完为止。同时,我们需要横向滑动重复以上步骤,整个过程如图11-9
所示。
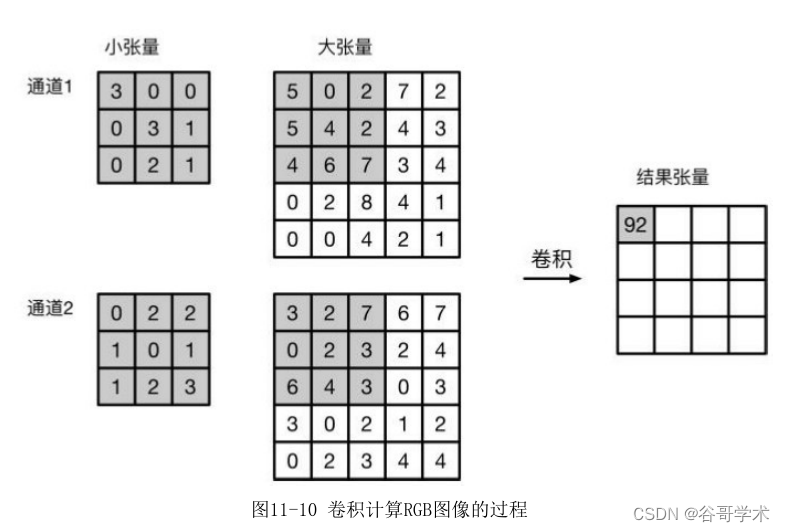
在处理RGB图像时,我们执行卷积时采用的卷积核大小不是3×3,而是
3×3×3的三阶张量,最后的3对应RGB三个颜色通道。在卷积生成图像中每个
元素为3×3×3的卷积核所对应的位置和图像所对应的位置相乘并累加所得
和,卷积核在RGB图像上依次滑动,最终生成的图像大小为4×4,如图11-10所
示。
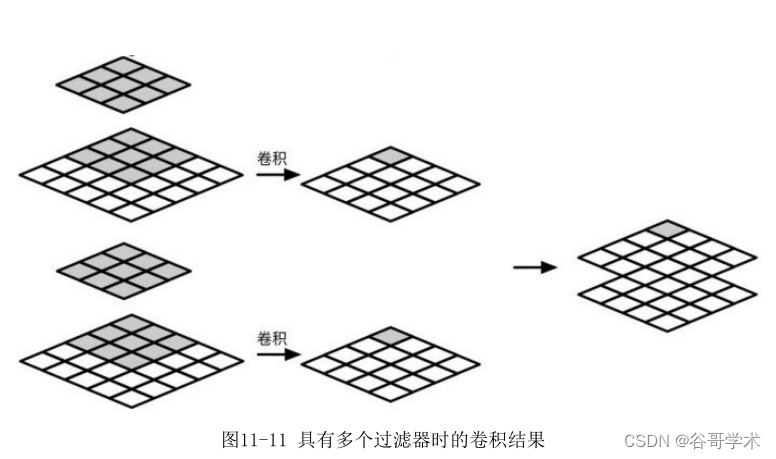
如果我们想要判断一幅图像里有没有飞机,只通过一个特征判断显然是不
够的,通常需要通过多个高级特征的组合才足以判断。一种卷积核只能表示一
种类型的特征,因此我们需要设计多个卷积核来得到不同方面的特征。卷积核
是一种超参数,需要人们长期试验汇集经验。常见的卷积核有同一化核、边缘
检测核、图像锐化核、均值模糊等。如果我们想要得到 2 个不同的特征,则
需要 2 个卷积核,最终生成的图像为4×4×2的立方体,这里的2代表采用了2
个过滤器,如图11-11所示。如果我们想要得到10个特征,那么输出的数字矩
阵为4×4×10的立方体。
卷积不但能够简化图像,降低运算量,更重要的是它能够提取图像的深层
特征。通过卷积运算,我们可以从原图像中提取边缘特征,组成一幅新的图
像。这幅新图像往往会比原图像更清?地展现图像的特质,有利于计算机的学
习与理解。在没有边缘的平坦区域,图像像素值的变化比较小,而物体边缘两
侧部分的像素会有较大的差别。通过这样的卷积运算可以提取不同的边缘特
征,去掉变化不明显的背景信息。
尽管我们采用卷积的方式构造了新的特征,但是使用该方法的模型对图像
分类的正确率并不能令人满意。原因在于这些卷积核都是人工事先定?好的,
是算法研究员根据经验设计的。随着图像分类任务越来越多样化,这种人工设
计的卷积核已经没办法满足需要了。这也是当时计算机领域面临的一个重大问
题:利用人工设计的图像特征,图像分类的准确率已经达到了“瓶颈”。
既然人为的特征已经不适用,那么我们为何不利用机器学习的思想,让计
算机自行去学习出卷积核,自己去学习构造特征的方式?因此诞生了实现自主
学习的卷积神经网络。
11.2.2 什么是卷积神经网络
对卷积神经网络的研究可追溯到 1979 年,日本学者福岛邦彦(Kunihiko
Fukushima)提出的新认知机(Neocognition)模型。在该模型中实现了现有
卷积神经网络中的部分功能,学界普遍认为是该模型启发了卷积神经网络的开
创性研究。
直到2012年,在一次图像分类比赛中,来自多伦多大学的团队首次采用了
深度神经网络的方法并取得了良好的成绩。3年后,来自微软研究院的团队提
出一种新的网络结构,即卷积神经网络,并且在图像分类这项任务上,计算机
分类的正确率首次超越人类。在图像分类的任务中,手工设计的特征往往很难
直接表达“有四条腿”或“有翅膀”这样高层次的抽象概念。然而使用卷积神
经网络学习的特征能够被计算机更好地应用,并取得了更好的分类效果。
卷积神经网络(Convolutional Neural Networks,CNN)之所以有那么强
大的能力,就是因为它能够自动从图像中学习有效的特征。其实CNN依旧是层
级网络,只是层的功能和形式发生了变化,可以说是传统神经网络为了图像识
别特意做的改进。
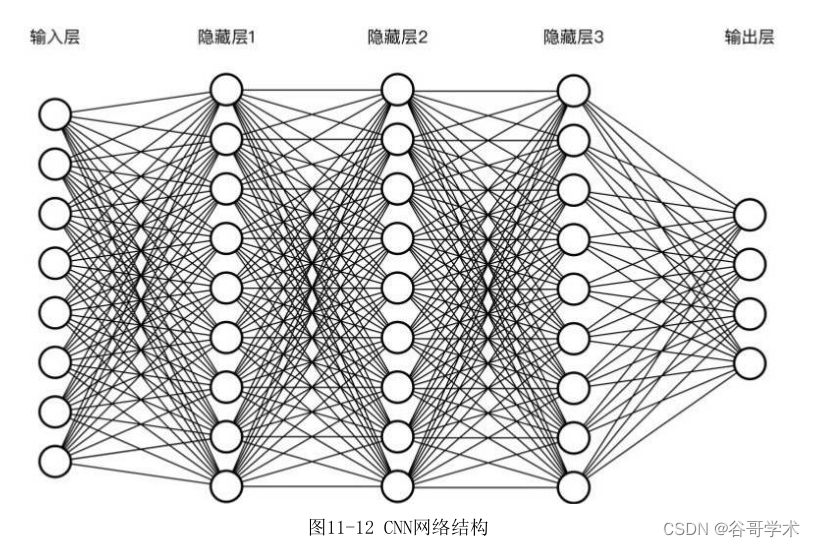
如图11-12所示,在不考虑输入层的情况?,一个典型的CNN结构为一系列
阶段的组合,其中包括若干个卷积层、激活层、池化层以及全连接层 。虽然
CNN的结构看起来比较复杂,但是其中每一层分工明确,并不难理解,如图11-
13所示。
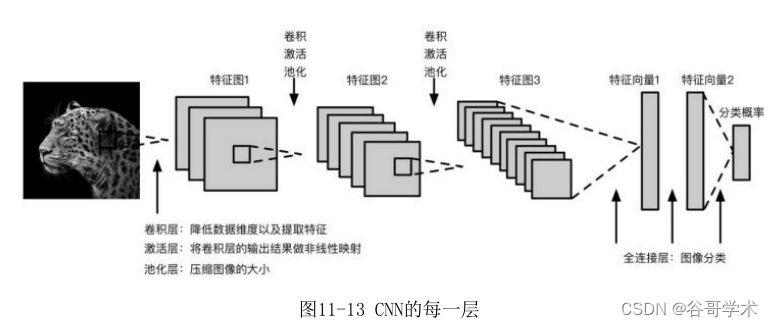
卷积层的目的是为了降低数据维度以及提取特征,激活层用于将卷积层的
输出结果做非线性映射。通过非线性的激活函数进行处理,可以模拟任何函
数,从而增强网络的表现力。池化层夹在连续的卷积层中间,用于压缩数据和
参数的数量,也就是压缩图像的大小。最后的全连接层相当于一个多层感知
机,在整个CNN中起到分类器的作用。前面几层都是为了得到更优质的特征,
最后的全连接层实现图像分类,最终完成CNN的分类目的。
1. 卷积层
卷积层是CNN的核心所在。它有两方面的特点:一方面是神经元间的连接
为局部连接;另一方面是同一层中某些神经元之间共享连接权重。
在CNN中,具体到每层神经元网络,它分别在长、宽和深三个维度上分布
神经元。深度代表通道数,通常为3。如果使用传统的BP神经网络则需要大量
的参数,原因在于每个神经元都和相邻层的神经元相连接。如果我们有一幅
100×100×3 的RGB图像,那么在设计输入层时,共需要100×100×3=30 000
个神经元,如图11-14所示。对于隐藏层的某个神经元来说,若按照BP神经网
络的模式,则这个神经元需要有30 000个权值。如果隐藏层有100个神经元,
则总共有300万个权值,计算量十分巨大。

但是现在我们已经知道这种全连接是没有必要的,因为我们判断一幅图像
中有没有飞机,可能看到“机翼”或者“机舱”这类特征即可知道,不需要看
完图像的每个部分才做出判断。如果采用局部连接的方式,则隐藏层的某个神
经元只需要与前层部分区域相连接,这个区域的大小等同于卷积核的大小。如
果我们采用 1 个大小为10×10×3的卷积核,如图11-15所示,那么每个隐藏
层神经元的前向连接个数由全连接的30 000个减少为10×10×3=300个,总共
的权值只有3万个,计算量大大降低。

以上的计算是在只有1个卷积核的情况?,如果我们想要提取更多的特
征,将卷积核增加到100个,那么原来通过局部连接减少的计算量一?子又被
抵消了。于是我们需要寻找更进一步降低权值数量的方法。
很快有人发现了共享权值的方法。我们可以把每个卷积核当作一种提取特
征的方式,这种方式与图像的位置无关。也就是说,对于同一个卷积核,它在
图像中某个部分提取到的特征也能用于其他部分。因此每个卷积核对应生成的
神经元都共享一个参数列表。基于这样的思路,我们可以把一个卷积核的所有
神经元都用相同的权值与输入层神经元相连。此时上述例子中权值的数量变为
10×10×3×1×100=3万个,计算量大大减少。
2. 激活层
前面讲过,在BP神经网络中,如果神经元与神经元的连接都是基于权值的
线性组合,那么组合之后的结果依然是线性的,这样网络的表达能力就非常有
限。因此在模型中需要设计一个非线性的激活函数,将原本的线性函数变换为
非线性函数。加入了非线性的激活函数后,神经网络才具备了非线性映射的学
习能力。同样,在 CNN中经过卷积层计算得到的结果,也是一个线性函数,因
此我们需要使用非线性的激活函数进行处理,这就是激活层的根本目的。
另外,引入激活函数还能有助于解决模型“过拟合”的问题。如果我们的
训练样本图像中大多数的桌子都是有“木纹”的或者颜色比较接近“绿色”,
那么在面对一张“铁质、黑色”的桌子时,模型就不会判定这是一张桌子,因
此我们需要采用一种“抓大放小”的策略才能保证模型的分类效果。
借助于激活函数,我们可以设置一个阈值标准,看看激活后的函数值有没
有超过这个标准。如果某一块区域的特征强度没有超过阈值,则说明这个卷积
核在这块区域提取不到特征,或者说这块区域的特征变化不明显。借此可以消
除一些影响不大的特征,让模型不再受细节?右。
非线性激活层的形式有很多,但基本形式都是先选定某种非线性函数,然
后再对输入特征图的每一个元素应用这种非线性函数,从而得到输出。目前应
用最广泛的是ReLU函数,它的函数图像如图11-16所示。
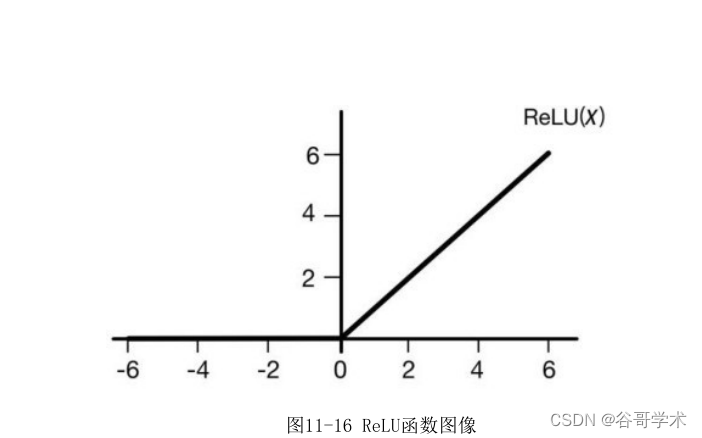
因为ReLU的计算非常简单,所以它的计算速度要比其他非线性函数快很
多,并且在实际应用中的表现效果很好,所以成为最广泛使用的激活函数。
3. 池化层
在CNN中,当卷积层提取目标的某个特征之后,通常会在相邻的两个卷积
层中间设置一个池化层。池化层的作用主要体现在两方面:一方面是对输入的
特征图进行压缩,使特征图变小,有效简化网络计算的复杂度;另一方面就是
把由小区域内获得的特征进行整合得到新特征,通过构建的新特征有效达到防
止过拟合的目的。
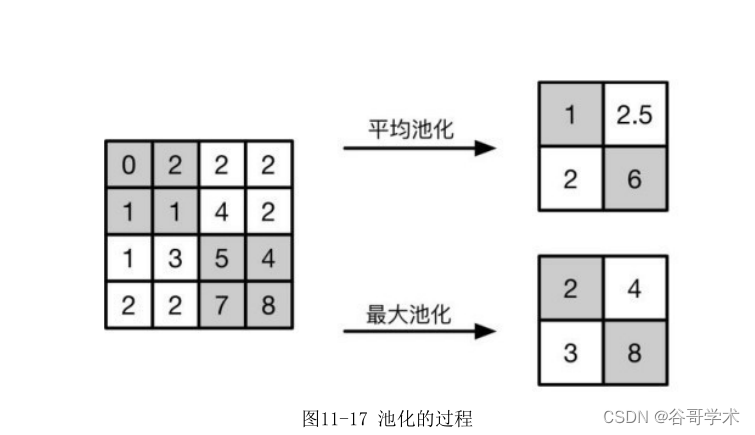
池化的方式一般有两种:一种是最大池化;另外一种是平均池化。两种方
法首先都需要将特征图按通道分开,将得到的若干个矩阵切成相同大小的正方
形区域。如图11-17所示,将一个4×4的矩阵分割成4个正方形区域,对每个区
域取最大值或平均值,并将结果组合成一个新的矩阵,就完成了池化的过程。
最后再把所有获得的结果汇总即可。
显然,经过池化后图像的分辨率会变低。虽然我们肉眼更难从这样的图像
发现特征,但是计算机的视角跟我们不同,池化后的图像对计算机不会有任何
影响,甚至能够帮助它更容易提取特征。
4. 全连接层
经过“卷积-池化-激活”以后,我们终于能够提取到带有强表现力的特征
了。最后我们还需要通过全连接层计算得出分类结果,这才算是完成了一次图
像识别的过程。前面我们提到过,全连接层实际上就是传统的多层感知机算
法,其不同于BP神经网络的地方在于它使用的激活函数不同,在此我们不再展
开?述。
虽然全连接层看起来是最简单的一个环节,但是由于全连接层的参数冗余
性,导致该层的参数总数通常占据整个神经网络一半以上的比例,稍不注意就
会在全连接层陷入过拟合的困境。因此我们在优化运算速度时,重点放在卷
积层;在进行参数优化、权值裁剪时,重点放在全连接层 。
以上就是一个CNN的运算过程,每次我们将一幅训练图像输入神经网络
中,经过逐层的计算,最终得到识别物体属于不同分类的概率。我们将预测结
果与原来的标签进行对比,如果模型的预测结果不太好我们会从最后一层开
始,逐层调整CNN的参数,使得网络能够有更好的表现。可以看到,相比传统
的机器学习算法,卷积神经网络首次实现了由计算机自己构建特征,由此突破
了原有人为特征的分类效果瓶颈,使图像识别上升到一个新的台阶。也是卷积
神经网络的出现,才使得更多识别图像的技术得以迅速发展,其中人脸识别技
术就是其中典型的代表。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 0
0 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)