
解决numpy或者pandas读取csv文件时总是编码报错的问题?
这里大家在新建csv文件时不建议直接右键通过其他文件(如excel,word等文件)更改后缀名来新建csv文件,这样会导致读取时总是报错。一.改变encoding=’‘的值,比如GBK,UTF-16,gb18030等见下图。这个时候我们需要判断一下文件的编码格式,利用python的chardet库。二,改变各种常用的编码都不对,这时考虑csv文件的格式属性是否正确。然后运行会报错(还有其他编码错误
·
1.pandas读取csv文件:
import pandas as pd
DatFrame=pd.read_csv('你的csv文件',encoding='utf-8')
print(DatFrame)2.numpy 读取csv文件:
import numpy as np
DatFrame=np.getfromtxt('你的csv文件',encoding='utf-8',delimiter=',',skip_header=True)
print(DatFrame)然后运行会报错(还有其他编码错误,这里就不列举了)
![]()
一.改变encoding=’‘的值,比如GBK,UTF-16,gb18030等见下图
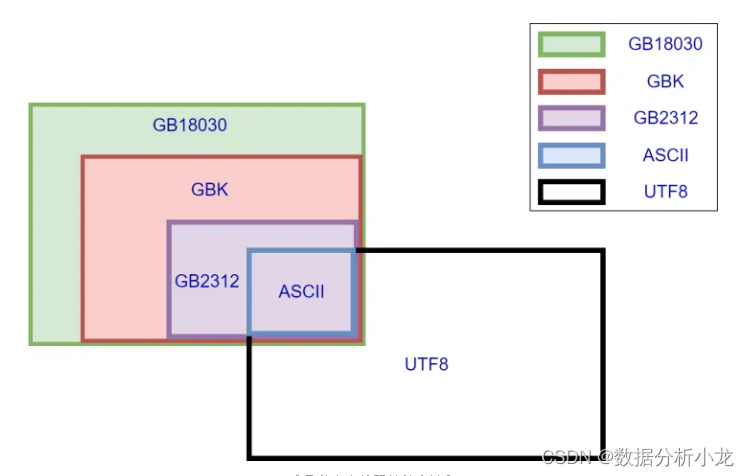
改图转自腾讯 - 知乎 (zhihu.com),这里应该能就解决很多问题
二,改变各种常用的编码都不对,这时考虑csv文件的格式属性是否正确
这个时候我们需要判断一下文件的编码格式,利用python的chardet库
import chardet
with open('你的csv文件', 'rb') as f:#该方法也适用于其他文件类型的编码判断
result = chardet.detect(f.read())
print(result)
encoding = result['encoding']
print(encoding)如果这时你的结果是
![]()
说明你创建csv文件方式不对,创建csv文件建议按照正确的创建方式:
- 打开excel,点击文件-开始
- 新建空白工作薄,编辑数据(也可以不编辑)
- 另存为csv文件
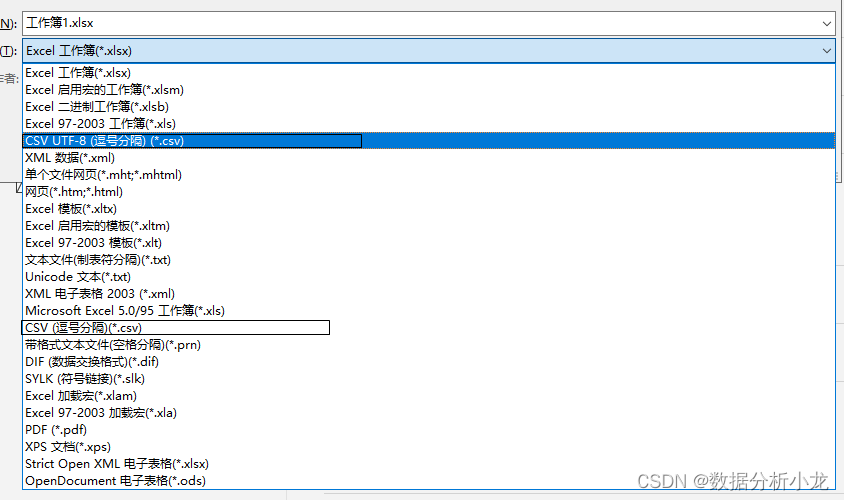
这里大家在新建csv文件时不建议直接右键通过其他文件(如excel,word等文件)更改后缀名来新建csv文件,这样会导致读取时总是报错。//但是通过txt文件更改后缀名却不会报错
//其他细节可以自行搜索,不再阐述。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)