
使用python2-------有关解码、打印乱码等遇到的坑
文章目录0.python2使用之前的准备工作(1)将pycharm的默认编码设置为UTF8(2)将python2的文件模板设置UTF8编码(后续每次创建python文件就不用写了)1.意外的收获,惊讶的发现2.写在前面:能不用python2尽量别用!但是,现实如果实在需要,也还是了解一些吧!0.python2使用之前的准备工作(1)将pycharm的默认编码设置为UTF8(2)将python2的文
·
文章目录
写在前面:
- 能不用python2,尽量别用!!!
- 但是,现实工作如果实在需要,还是得了解一些常见的坑!!!
0.python2使用之前的准备工作
(1)将pycharm的默认编码设置为UTF8
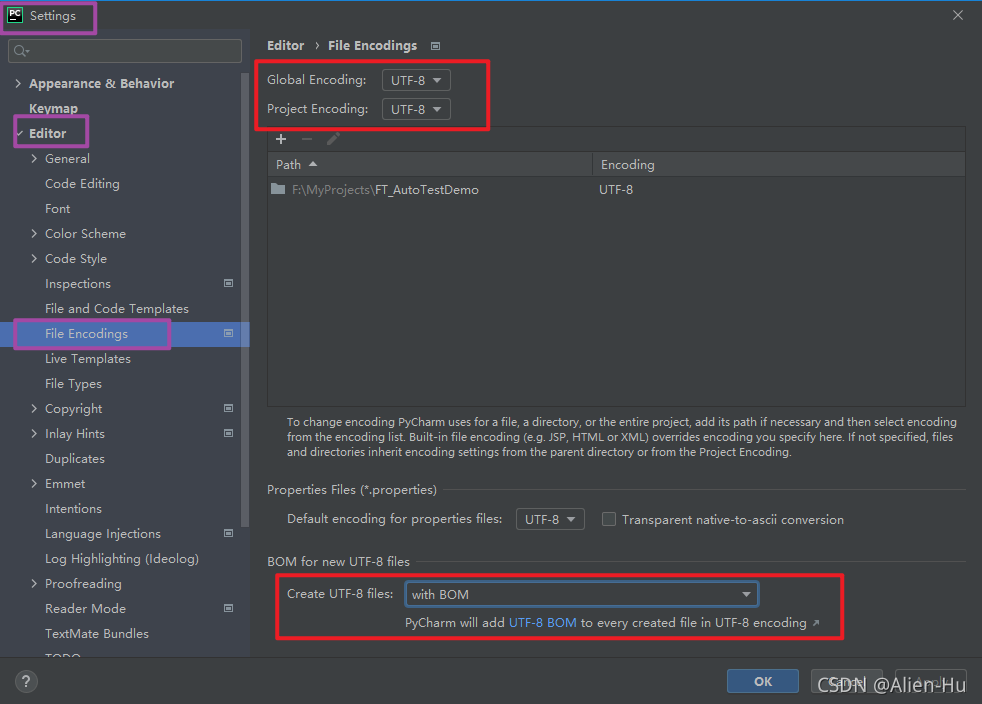
(2)将python2的文件模板设置UTF8编码(后续每次创建python文件就不用写了)
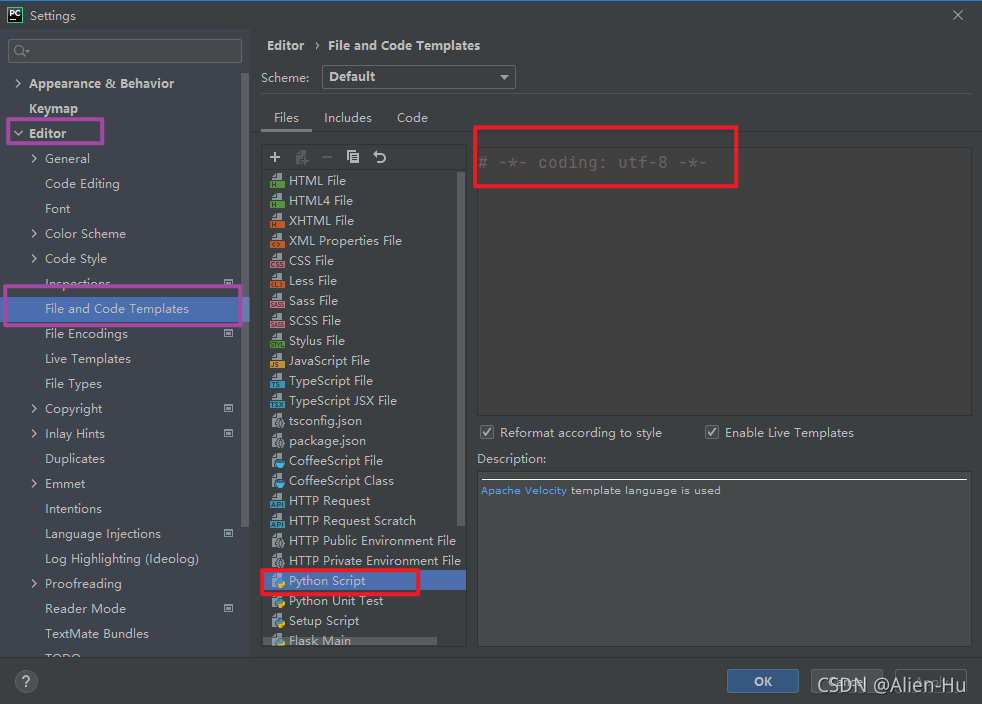
(3)检查一下数据库字段中的排序规则
utf8-bin 是大小写敏感
utf8_general_ci 表示不区分大小写 (一般使用这个模式)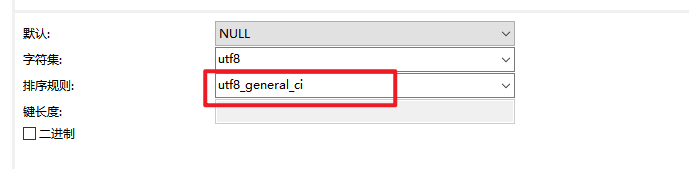
1.意外的收获,惊讶的发现
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
name = "你好, Alien"
name2 = "你好Alien"
print name2, name
print (name2, name)
print name2
你好Alien 你好, Alien
('\xe4\xbd\xa0\xe5\xa5\xbdAlien', '\xe4\xbd\xa0\xe5\xa5\xbd, Alien') # 最NB的是,带个括号打印,居然是乱码
你好Alien
2.注定有些文本很难解析decode,怎么搞?
夜路走多了,总会遇到写妖魔鬼怪,怎么试都解决不了!
b'{"m_strategy_execution_price": 6.066980440315375, "m_strategy_state": 3, "m_strategy_asset": 0.0, "m_strategy_ordered_asset": 1022656.29, "m_strategy_market_price": 0.0, "m_strategy_type": 4818, "m_client_strategy_id": 110900033, "m_strategy_price_diff": -1518.302897856544, "m_strategy_asset_diff": -557891.2899999999, "m_strategy_qty": 1540000, "m_strategy_execution_qty": 168561, "m_strategy_execution_asset": 1022656.29, "m_xtp_strategy_id": 1744072474645, "error_id": 0, "m_strategy_ordered_qty": 168561, "error_msg": "600863\xe6\x89\xa7\xe8\xa1\x8cT0\xe4\xba\xa4\xe6\x98\x9377000\xe8\x82\xa1\xef\xbc\x9b600777\xe6\x89\xa7\xe8\xa1\x8cT0\xe4\xba\xa4\xe6\x98\x9377000\xe8\x82\xa1\xef\xbc\x9b601015\xe6\x89\xa7\xe8\xa1\x8cT0\xe4\xba\xa4\xe6\x98\x9377000\xe8\x82\xa1\xef\xbc\x9b600956\xe6\x89\xa7\xe8\xa1\x8cT0\xe4\xba\xa4\xe6\x98\x9377000\xe8\x82\xa1\xef\xbc", "m_strategy_cancelled_qty": 24539, "m_strategy_unclosed_qty": -168561}'
init_str = b'{"m_strategy_execution_price": 6.066980440315375, "m_strategy_state": 3, "m_strategy_asset": 0.0, "m_strategy_ordered_asset": 1022656.29, "m_strategy_market_price": 0.0, "m_strategy_type": 4818, "m_client_strategy_id": 110900033, "m_strategy_price_diff": -1518.302897856544, "m_strategy_asset_diff": -557891.2899999999, "m_strategy_qty": 1540000, "m_strategy_execution_qty": 168561, "m_strategy_execution_asset": 1022656.29, "m_xtp_strategy_id": 1744072474645, "error_id": 0, "m_strategy_ordered_qty": 168561, "error_msg": "600863\xe6\x89\xa7\xe8\xa1\x8cT0\xe4\xba\xa4\xe6\x98\x9377000\xe8\x82\xa1\xef\xbc\x9b600777\xe6\x89\xa7\xe8\xa1\x8cT0\xe4\xba\xa4\xe6\x98\x9377000\xe8\x82\xa1\xef\xbc\x9b601015\xe6\x89\xa7\xe8\xa1\x8cT0\xe4\xba\xa4\xe6\x98\x9377000\xe8\x82\xa1\xef\xbc\x9b600956\xe6\x89\xa7\xe8\xa1\x8cT0\xe4\xba\xa4\xe6\x98\x9377000\xe8\x82\xa1\xef\xbc", "m_strategy_cancelled_qty": 24539, "m_strategy_unclosed_qty": -168561}'
# 尝试了N次失败之后,懵逼的你估计也不知道怎么解码了
str_001 = init_str.decode("utf8")
print(str_001)
str_002 = init_str.decode("gbk")
print(str_002)
str_003 = init_str.decode("gb2312")
print(str_003)
str_004 = bytes.decode(init_str)
print(str_004)
...
...
# 此处省略N种方法
- 躺平方法如下:
# 添加一个ignore,解码不了的字符就忽略
str_666 = init_str.decode("utf8", "ignore")
print(str_666)
{"m_strategy_execution_price": 6.066980440315375, "m_strategy_state": 3, "m_strategy_asset": 0.0, "m_strategy_ordered_asset": 1022656.29, "m_strategy_market_price": 0.0, "m_strategy_type": 4818, "m_client_strategy_id": 110900033, "m_strategy_price_diff": -1518.302897856544, "m_strategy_asset_diff": -557891.2899999999, "m_strategy_qty": 1540000, "m_strategy_execution_qty": 168561, "m_strategy_execution_asset": 1022656.29, "m_xtp_strategy_id": 1744072474645, "error_id": 0, "m_strategy_ordered_qty": 168561, "error_msg": "600863执行T0交易77000股;600777执行T0交易77000股;601015执行T0交易77000股;600956执行T0交易77000股", "m_strategy_cancelled_qty": 24539, "m_strategy_unclosed_qty": -168561}
3. 打印(print)列表、字典居然不显示中文(默认unicode编码)
(1)打印列表的时候
my_list = ["alien", "乾坤未定,你我皆黑马!","hello,world!"]
print my_list
# 显示效果如下
['alien', '\xe4\xb9\xbe\xe5\x9d\xa4\xe6\x9c\xaa\xe5\xae\x9a\xef\xbc\x8c\xe4\xbd\xa0\xe6\x88\x91\xe7\x9a\x86\xe9\xbb\x91\xe9\xa9\xac\xef\xbc\x81', 'hello,world!']
(2)打印字典的时候
my_dict = {"name": "alien", "slogan": "乾坤未定,你我皆黑马!", "project": "hello,world!"}
print my_dict
# 显示效果如下
{'project': 'hello,world!', 'slogan': '\xe4\xb9\xbe\xe5\x9d\xa4\xe6\x9c\xaa\xe5\xae\x9a\xef\xbc\x8c\xe4\xbd\xa0\xe6\x88\x91\xe7\x9a\x86\xe9\xbb\x91\xe9\xa9\xac\xef\xbc\x81', 'name': 'alien'}
(3)使用照妖镜,让它现出原形!
my_list = ["alien", "乾坤未定,你我皆黑马!","hello,world!"]
my_dict = {"name": "alien", "slogan": "乾坤未定,你我皆黑马!", "project": "hello,world!"}
print "{}".format(my_dict).decode("string-escape")
print str(my_dict).decode("string-escape")
print("\n")
print "{}".format(my_list).decode("string-escape")
print str(my_list).decode("string-escape")
{'project': 'hello,world!', 'slogan': '乾坤未定,你我皆黑马!', 'name': 'alien'}
{'project': 'hello,world!', 'slogan': '乾坤未定,你我皆黑马!', 'name': 'alien'}
['alien', '乾坤未定,你我皆黑马!', 'hello,world!']
['alien', '乾坤未定,你我皆黑马!', 'hello,world!']
4.UnicodeDecodeError: ‘utf8’ codec can’t decode byte 0xcd in position 124: invalid continuation byte
(1)json.dumps-------报错
re_dict = {
'error_msg': '510110.SH\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 510060.SH\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 510090.SH\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 510120.SH\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 510130.S\xcd\x04I\x93]\xda',
'm_xtp_strategy_id': 1155673948691L, 'm_strategy_state': 8, 'error_id': -1, 'm_strategy_type': 5001,
'm_client_strategy_id': 111500189}
str_ok = json.dumps(re_dict) # 报错
str_ok = json.dumps(re_dict, ensure_ascii=False) # 正常序列化
(2)json.loads-------报错
str_dict = '{"m_strategy_type": 5001, "m_client_strategy_id": 111500189, "m_strategy_state": 8, "m_xtp_strategy_id": 1155673948691, "error_id": -1, "error_msg": "510110.SH\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 510060.SH\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 510090.SH\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 510120.SH\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 510130.S\xcd\\u0004I\x93]\xda"}'
dict_ok = json.loads(str_dict) # 报错
dict_decode = str_dict.decode("utf8", "ignore") # 需要先解码,忽略异常符号
dict_ok = json.loads(dict_decode) # 最终才能解析出字典
5.各种情况乱码的解析
(1) 带 \u 的乱码
error_msg = "510120\u6682\u4e0d\u652f\u6301T0\u4ea4\u6613"
print error_msg.encode('utf-8').decode('unicode_escape')
# 打印结果:
# 510120暂不支持T0交易
(2) 带\x 的乱码
error_msg = "159919.SZ\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 159976.S\xb1\x84@\xffR\xf6"
print error_msg.decode('string_escape')
# 打印结果
# 159919.SZ不支持,已跳过 159976.S��@�R�
此处虽然打印正常,但是出现了乱码,是个很大的隐患!!!
(3) 特殊字符 � 的处理(\xef\xbf\xbd)
如果原始字符串带一些乱码,如果不处理,中间进行数据的时候很容易出现各种编码问题。
例如:
- UnicodeDecodeError
- ‘ascii’ codec can’t decode byte
- ‘utf8’ codec can’t decode byte
error_msg = '159919.SZ\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 159976.S\xb1\x84@\xffR\xf6'
text = unicode(error_msg, encoding="utf8", errors="replace")
error_msg_result = ''
for single_str in text:
num = ord(single_str)
print type(single_str), single_str, num
if num not in [65533, 64, 82]:
error_msg_result += single_str
print error_msg_result
<type 'unicode'> 1 49
<type 'unicode'> 5 53
<type 'unicode'> 9 57
<type 'unicode'> 9 57
<type 'unicode'> 1 49
<type 'unicode'> 9 57
<type 'unicode'> . 46
<type 'unicode'> S 83
<type 'unicode'> Z 90
<type 'unicode'> 不 19981
<type 'unicode'> 支 25903
<type 'unicode'> 持 25345
<type 'unicode'> , 44
<type 'unicode'> 已 24050
<type 'unicode'> 跳 36339
<type 'unicode'> 过 36807
<type 'unicode'> 32
<type 'unicode'> 1 49
<type 'unicode'> 5 53
<type 'unicode'> 9 57
<type 'unicode'> 9 57
<type 'unicode'> 7 55
<type 'unicode'> 6 54
<type 'unicode'> . 46
<type 'unicode'> S 83
<type 'unicode'> � 65533
<type 'unicode'> � 65533
<type 'unicode'> @ 64
<type 'unicode'> � 65533
<type 'unicode'> R 82
<type 'unicode'> � 65533
# 需要内容,过滤掉特殊字符了
159919.SZ不支持,已跳过 159976.S
- ord这个函数,可以将每个字符,解码出来ascii的编码序号,通过序号我们可以将特殊字符串,直接都过滤掉,然后再组合即可!

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)