
大模型之DPO
这个loss同样用 Reference模型来计算KL散度,以免训练出来的模型偏离 SFT后的模型太远。研究引入身份偏好优化(IPO),它为 DPO 损失添加了正则化项,使人们能够训练模型收敛,而无需提前停止等技巧。实验的感觉是不如PPO、可能的原因是没有很好的调参,也可能是因为PPO pipeline环节引入了较多的人工经验。这么设计、意味着训练样本构造batch时,要将一个对话的样本放在一个ba
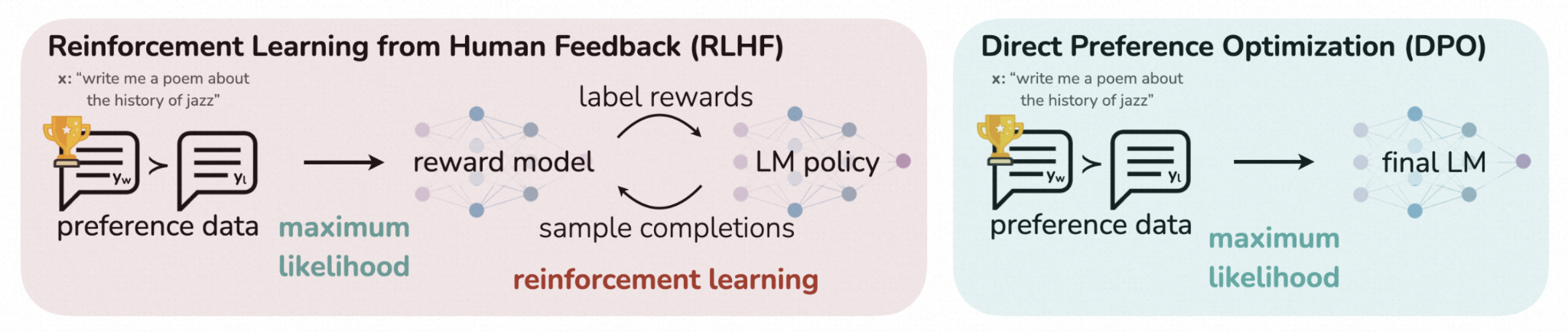
PPO存在的不足:pipeline较长、需要训练RM模型得到回报分数;训练阶段需要加载4个模型,消耗显存,且需要频繁采样、计算量大。
DPO的实现:直接优化 LM 来对齐人类偏好,无需建模 reward model 和强化学习阶段。基于 RL 的目标函数可以通过优化二分 cross entropy 目标来优化。
DPO loss 表达为如下形式:

这个loss同样用 Reference模型来计算KL散度,以免训练出来的模型偏离 SFT后的模型太远。主要作用是增加 喜好数据y_w的概率,降低非喜好数据 y_l的概率。
DPO 的一个缺点是它往往会很快过拟合偏好数据集。研究引入身份偏好优化(IPO),它为 DPO 损失添加了正则化项,使人们能够训练模型收敛,而无需提前停止等技巧。
实验的感觉是不如PPO、可能的原因是没有很好的调参,也可能是因为PPO pipeline环节引入了较多的人工经验。
DPO训练数据示例:
AI-ModelScope/hh_rlhf_cn
数据示例:
{"context": [{"role": "human", "text": "我应该租房子还是租公寓?"}],
"chosen": {"role": "assistant", "text": "我不确定。 你能告诉我更多关于你在想的是什么房子或公寓吗? 你为什么要考虑买房子?"},
"rejected": {"role": "assistant", "text": "我不确定你更喜欢哪个? 似乎两者都是选择。"}}
RM:reward model
模型训练的tricks:
1、用排序来替代打分,降低标准的成本,获得更多的训练数据。
2、排序不限于两两排序,也可以是 A>B>C>D。对于这种4个样本排序的训练数据,loss可以设计成:
loss = r(A) - r(B) + r(A) - r(C) + r(A) - r(D) + r(B) - r(C) + ... + r(C) - r(D)
loss = -loss
这么设计、意味着训练样本构造batch时,要将一个对话的样本放在一个batch里面,可以最大化训练效果。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)